 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Image similarity using Deep CNN and Curriculum Learning
Jul 13, 2018

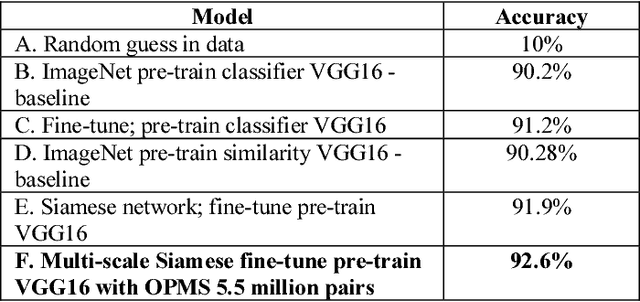
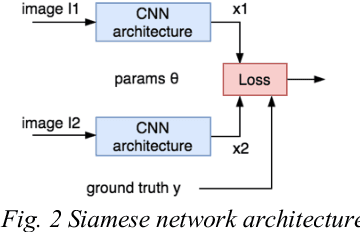
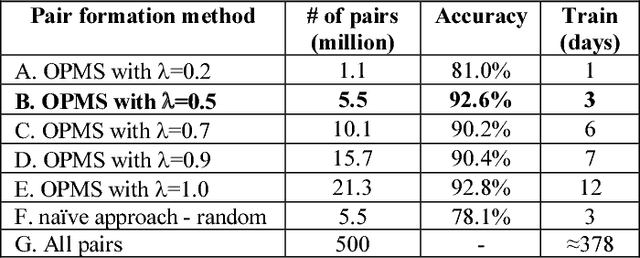
Image similarity involves fetching similar looking images given a reference image. Our solution called SimNet, is a deep siamese network which is trained on pairs of positive and negative images using a novel online pair mining strategy inspired by Curriculum learning. We also created a multi-scale CNN, where the final image embedding is a joint representation of top as well as lower layer embedding's. We go on to show that this multi-scale siamese network is better at capturing fine grained image similarities than traditional CNN's.
Imbalance-Aware Self-Supervised Learning for 3D Radiomic Representations
Mar 06, 2021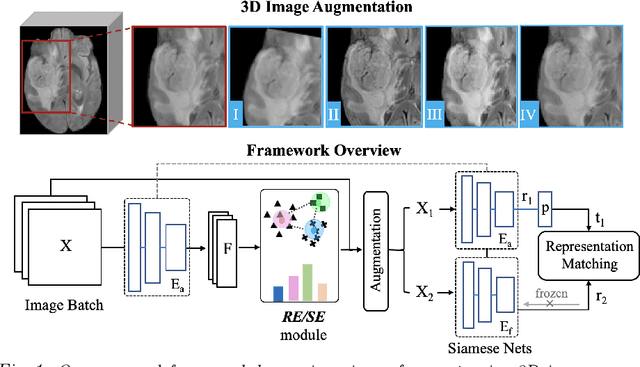

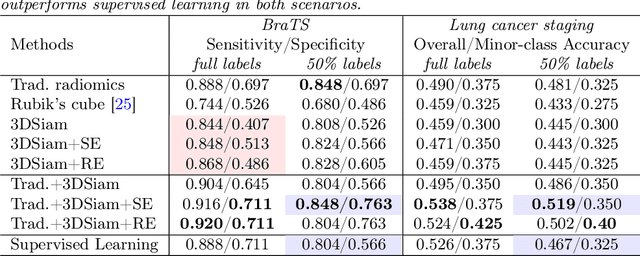
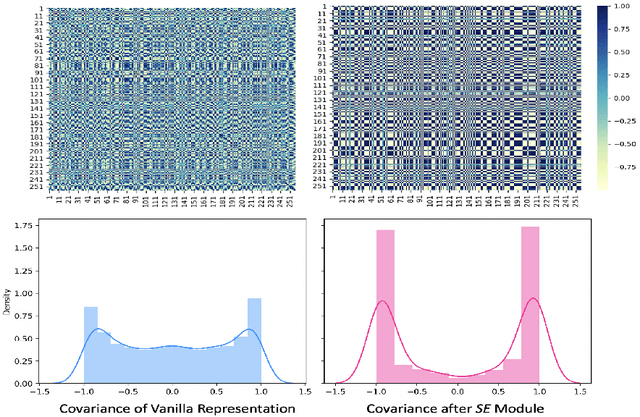
Radiomic representations can quantify properties of regions of interest in medical image data. Classically, they account for pre-defined statistics of shape, texture, and other low-level image features. Alternatively, deep learning-based representations are derived from supervised learning but require expensive annotations from experts and often suffer from overfitting and data imbalance issues. In this work, we address the challenge of learning representations of 3D medical images for an effective quantification under data imbalance. We propose a \emph{self-supervised} representation learning framework to learn high-level features of 3D volumes as a complement to existing radiomics features. Specifically, we demonstrate how to learn image representations in a self-supervised fashion using a 3D Siamese network. More importantly, we deal with data imbalance by exploiting two unsupervised strategies: a) sample re-weighting, and b) balancing the composition of training batches. When combining our learned self-supervised feature with traditional radiomics, we show significant improvement in brain tumor classification and lung cancer staging tasks covering MRI and CT imaging modalities.
AutoML Segmentation for 3D Medical Image Data: Contribution to the MSD Challenge 2018
May 20, 2020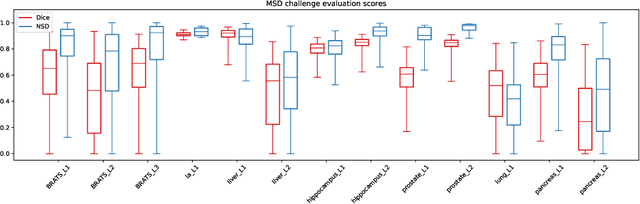
Fueled by recent advances in machine learning, there has been tremendous progress in the field of semantic segmentation for the medical image computing community. However, developed algorithms are often optimized and validated by hand based on one task only. In combination with small datasets, interpreting the generalizability of the results is often difficult. The Medical Segmentation Decathlon challenge addresses this problem, and aims to facilitate development of generalizable 3D semantic segmentation algorithms that require no manual parametrization. Such an algorithm was developed and is presented in this paper. It consists of a 3D convolutional neural network with encoder-decoder architecture employing residual-connections, skip-connections and multi-level generation of predictions. It works on anisotropic voxel-geometries and has anisotropic depth, i.e., the number of downsampling steps is a task-specific parameter. These depths are automatically inferred for each task prior to training. By combining this flexible architecture with on-the-fly data augmentation and little-to-no pre-- or postprocessing, promising results could be achieved. The code developed for this challenge will be available online after the final deadline at: https://github.com/ORippler/MSD_2018
Confidence-based Out-of-Distribution Detection: A Comparative Study and Analysis
Jul 06, 2021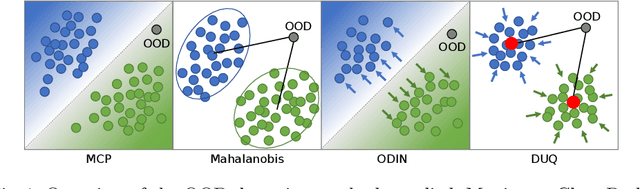
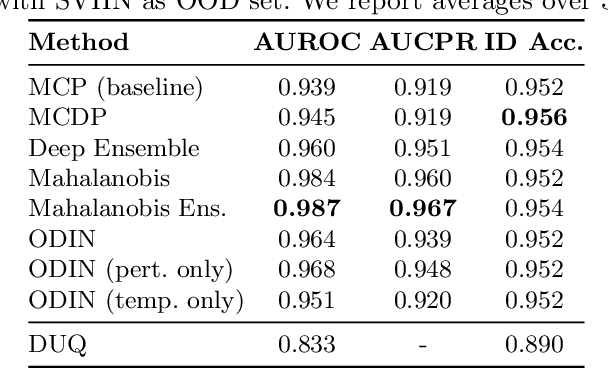
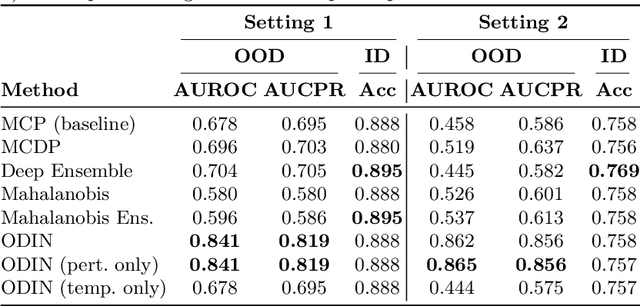
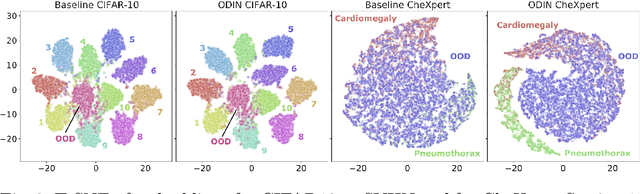
Image classification models deployed in the real world may receive inputs outside the intended data distribution. For critical applications such as clinical decision making, it is important that a model can detect such out-of-distribution (OOD) inputs and express its uncertainty. In this work, we assess the capability of various state-of-the-art approaches for confidence-based OOD detection through a comparative study and in-depth analysis. First, we leverage a computer vision benchmark to reproduce and compare multiple OOD detection methods. We then evaluate their capabilities on the challenging task of disease classification using chest X-rays. Our study shows that high performance in a computer vision task does not directly translate to accuracy in a medical imaging task. We analyse factors that affect performance of the methods between the two tasks. Our results provide useful insights for developing the next generation of OOD detection methods.
Compressing Deep ODE-Nets using Basis Function Expansions
Jun 21, 2021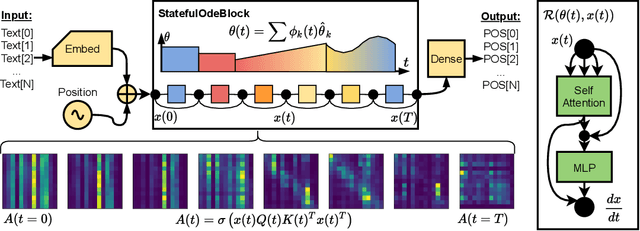

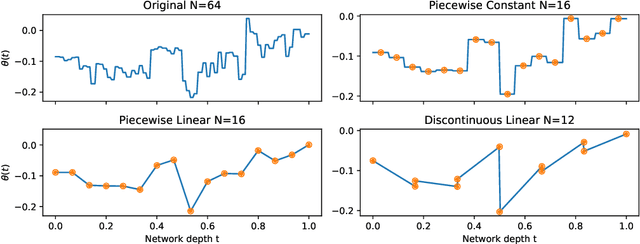
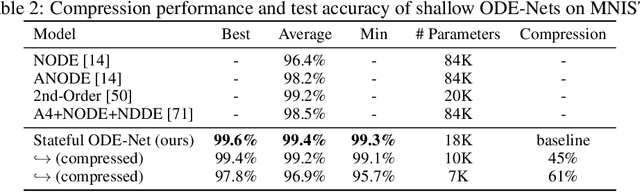
The recently-introduced class of ordinary differential equation networks (ODE-Nets) establishes a fruitful connection between deep learning and dynamical systems. In this work, we reconsider formulations of the weights as continuous-depth functions using linear combinations of basis functions. This perspective allows us to compress the weights through a change of basis, without retraining, while maintaining near state-of-the-art performance. In turn, both inference time and the memory footprint are reduced, enabling quick and rigorous adaptation between computational environments. Furthermore, our framework enables meaningful continuous-in-time batch normalization layers using function projections. The performance of basis function compression is demonstrated by applying continuous-depth models to (a) image classification tasks using convolutional units and (b) sentence-tagging tasks using transformer encoder units.
Separating Skills and Concepts for Novel Visual Question Answering
Jul 19, 2021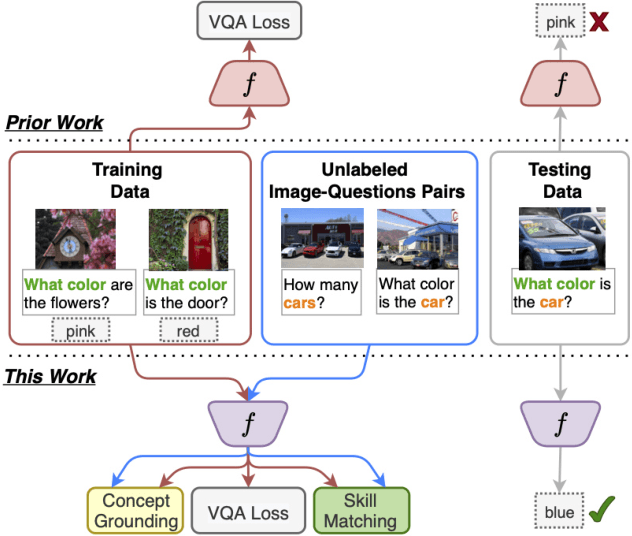
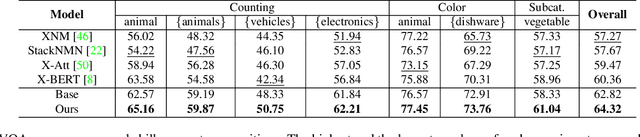
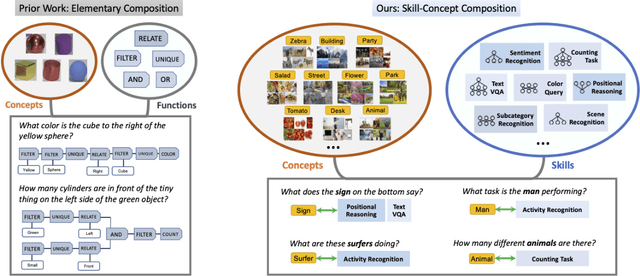
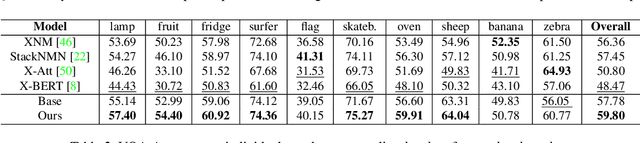
Generalization to out-of-distribution data has been a problem for Visual Question Answering (VQA) models. To measure generalization to novel questions, we propose to separate them into "skills" and "concepts". "Skills" are visual tasks, such as counting or attribute recognition, and are applied to "concepts" mentioned in the question, such as objects and people. VQA methods should be able to compose skills and concepts in novel ways, regardless of whether the specific composition has been seen in training, yet we demonstrate that existing models have much to improve upon towards handling new compositions. We present a novel method for learning to compose skills and concepts that separates these two factors implicitly within a model by learning grounded concept representations and disentangling the encoding of skills from that of concepts. We enforce these properties with a novel contrastive learning procedure that does not rely on external annotations and can be learned from unlabeled image-question pairs. Experiments demonstrate the effectiveness of our approach for improving compositional and grounding performance.
Just Train Twice: Improving Group Robustness without Training Group Information
Jul 19, 2021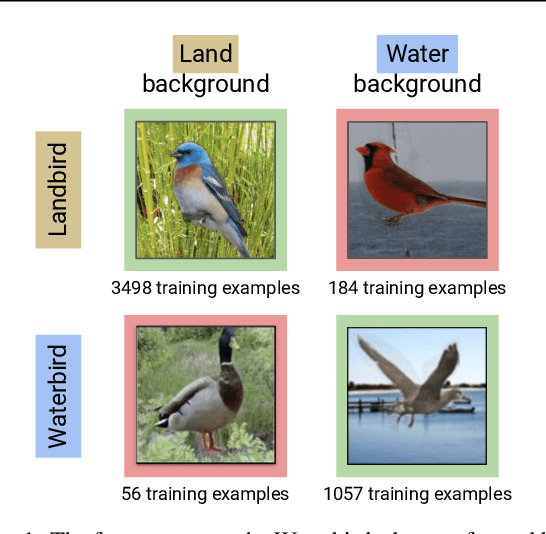
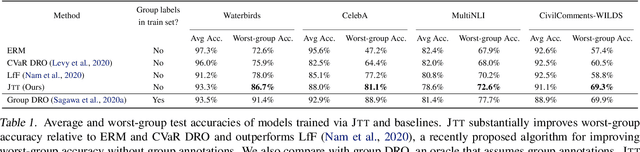

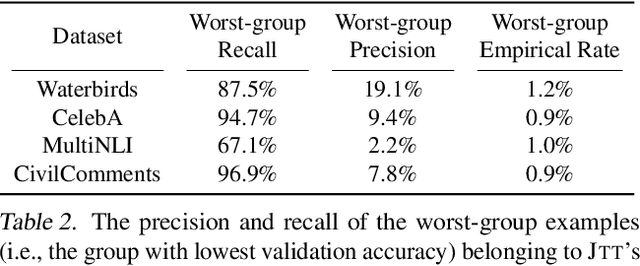
Standard training via empirical risk minimization (ERM) can produce models that achieve high accuracy on average but low accuracy on certain groups, especially in the presence of spurious correlations between the input and label. Prior approaches that achieve high worst-group accuracy, like group distributionally robust optimization (group DRO) require expensive group annotations for each training point, whereas approaches that do not use such group annotations typically achieve unsatisfactory worst-group accuracy. In this paper, we propose a simple two-stage approach, JTT, that first trains a standard ERM model for several epochs, and then trains a second model that upweights the training examples that the first model misclassified. Intuitively, this upweights examples from groups on which standard ERM models perform poorly, leading to improved worst-group performance. Averaged over four image classification and natural language processing tasks with spurious correlations, JTT closes 75% of the gap in worst-group accuracy between standard ERM and group DRO, while only requiring group annotations on a small validation set in order to tune hyperparameters.
Foreground-Aware Stylization and Consensus Pseudo-Labeling for Domain Adaptation of First-Person Hand Segmentation
Jul 11, 2021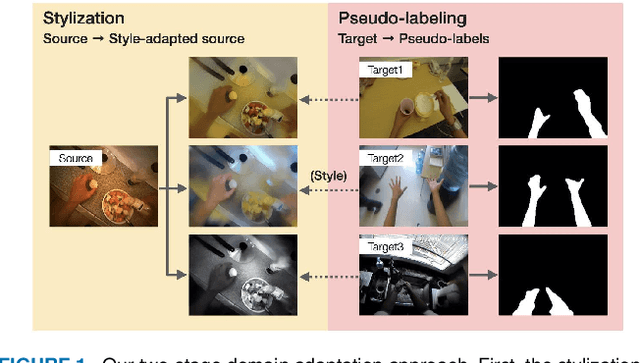
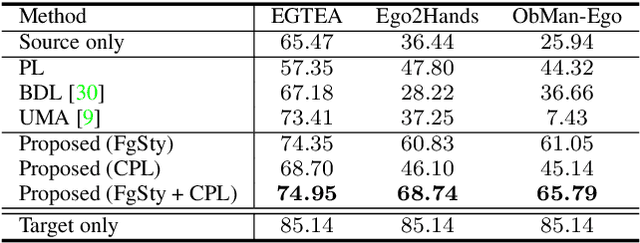


Hand segmentation is a crucial task in first-person vision. Since first-person images exhibit strong bias in appearance among different environments, adapting a pre-trained segmentation model to a new domain is required in hand segmentation. Here, we focus on appearance gaps for hand regions and backgrounds separately. We propose (i) foreground-aware image stylization and (ii) consensus pseudo-labeling for domain adaptation of hand segmentation. We stylize source images independently for the foreground and background using target images as style. To resolve the domain shift that the stylization has not addressed, we apply careful pseudo-labeling by taking a consensus between the models trained on the source and stylized source images. We validated our method on domain adaptation of hand segmentation from real and simulation images. Our method achieved state-of-the-art performance in both settings. We also demonstrated promising results in challenging multi-target domain adaptation and domain generalization settings. Code is available at https://github.com/ut-vision/FgSty-CPL.
Plug-and-Play Quantum Adaptive Denoiser for Deconvolving Poisson Noisy Images
Jul 01, 2021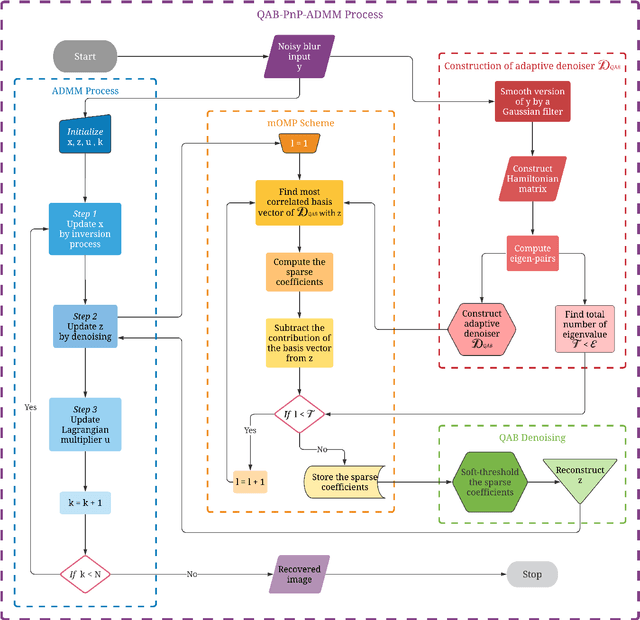

A new Plug-and-Play (PnP) alternating direction of multipliers (ADMM) scheme is proposed in this paper, by embedding a recently introduced adaptive denoiser using the Schroedinger equation's solutions of quantum physics. The potential of the proposed model is studied for Poisson image deconvolution, which is a common problem occurring in number of imaging applications, such as, for example, limited photon acquisition or X-ray computed tomography. Numerical results show the efficiency and good adaptability of the proposed scheme compared to recent state-of-the-art techniques, for both high and low signal-to-noise ratio scenarios. This performance gain regardless of the amount of noise affecting the observations is explained by the flexibility of the embedded quantum denoiser constructed without anticipating any prior statistics about the noise, which is one of the main advantages of this method.
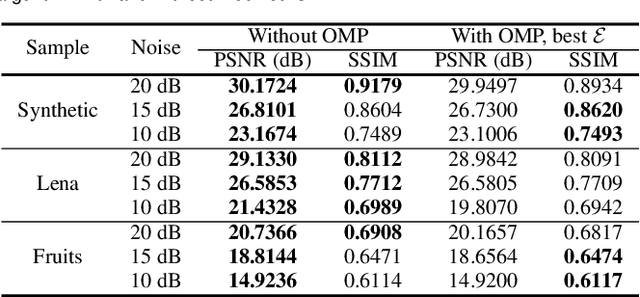
Weighted Fuzzy-Based PSNR for Watermarking
Jan 21, 2021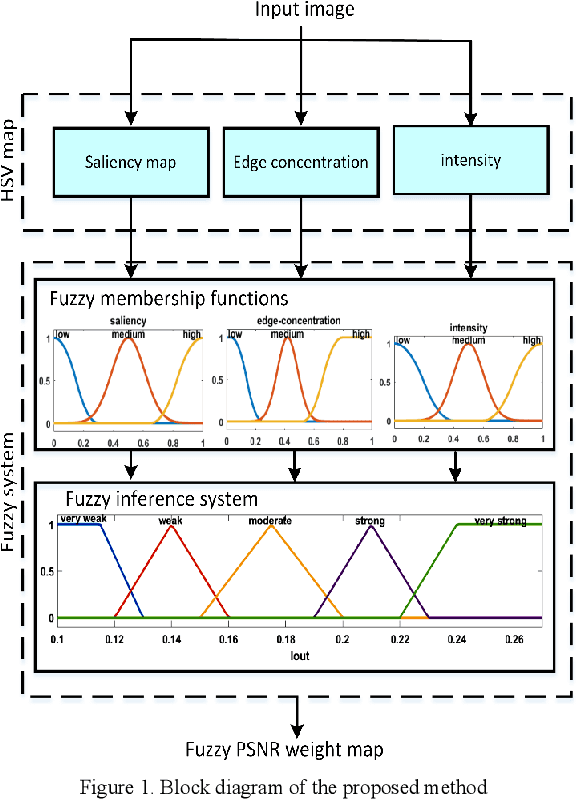


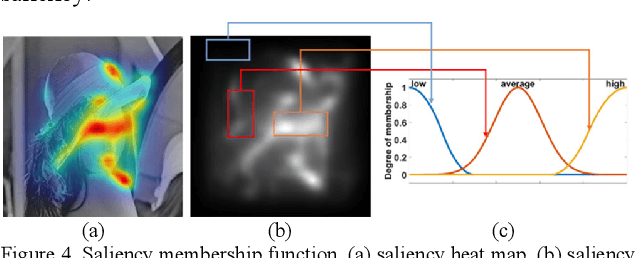
One of the problems of conventional visual quality evaluation criteria such as PSNR and MSE is the lack of appropriate standards based on the human visual system (HVS). They are calculated based on the difference of the corresponding pixels in the original and manipulated image. Hence, they practically do not provide a correct understanding of the image quality. Watermarking is an image processing application in which the image's visual quality is an essential criterion for its evaluation. Watermarking requires a criterion based on the HVS that provides more accurate values than conventional measures such as PSNR. This paper proposes a weighted fuzzy-based criterion that tries to find essential parts of an image based on the HVS. Then these parts will have larger weights in computing the final value of PSNR. We compare our results against standard PSNR, and our experiments show considerable consequences.