 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeJust Train Twice: Improving Group Robustness without Training Group Information
Paper and Code
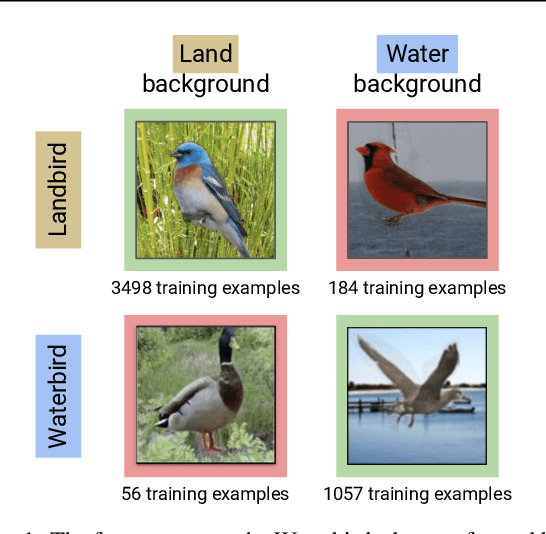
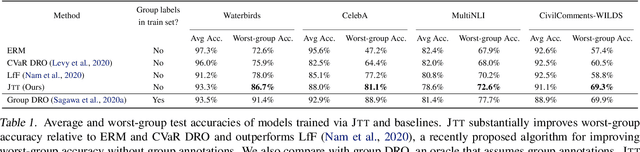

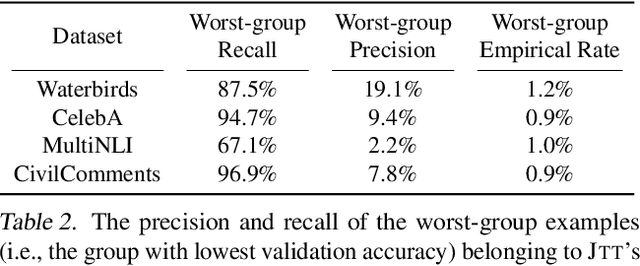
Standard training via empirical risk minimization (ERM) can produce models that achieve high accuracy on average but low accuracy on certain groups, especially in the presence of spurious correlations between the input and label. Prior approaches that achieve high worst-group accuracy, like group distributionally robust optimization (group DRO) require expensive group annotations for each training point, whereas approaches that do not use such group annotations typically achieve unsatisfactory worst-group accuracy. In this paper, we propose a simple two-stage approach, JTT, that first trains a standard ERM model for several epochs, and then trains a second model that upweights the training examples that the first model misclassified. Intuitively, this upweights examples from groups on which standard ERM models perform poorly, leading to improved worst-group performance. Averaged over four image classification and natural language processing tasks with spurious correlations, JTT closes 75% of the gap in worst-group accuracy between standard ERM and group DRO, while only requiring group annotations on a small validation set in order to tune hyperparameters.