 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Parallel mesh reconstruction streams for pose estimation of interacting hands
Apr 25, 2021

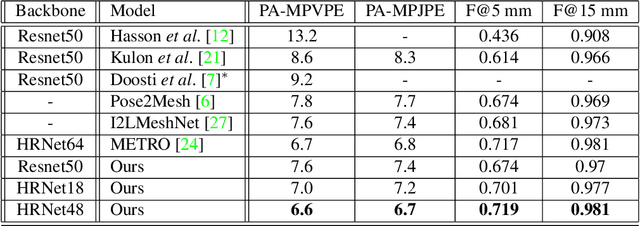
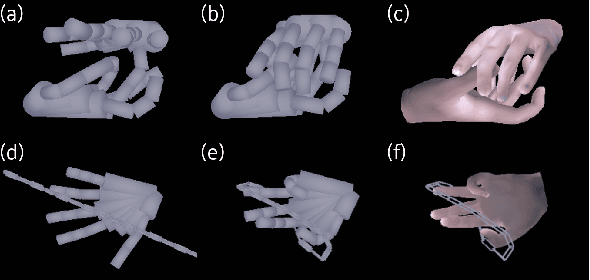
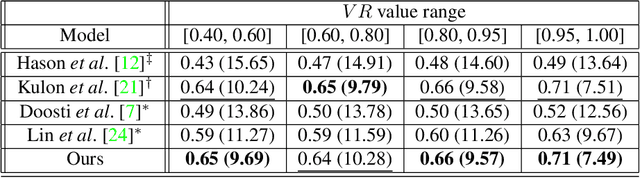
We present a new multi-stream 3D mesh reconstruction network (MSMR-Net) for hand pose estimation from a single RGB image. Our model consists of an image encoder followed by a mesh-convolution decoder composed of connected graph convolution layers. In contrast to previous models that form a single mesh decoding path, our decoder network incorporates multiple cross-resolution trajectories that are executed in parallel. Thus, global and local information are shared to form rich decoding representations at minor additional parameter cost compared to the single trajectory network. We demonstrate the effectiveness of our method in hand-hand and hand-object interaction scenarios at various levels of interaction. To evaluate the former scenario, we propose a method to generate RGB images of closely interacting hands. Moreoever, we suggest a metric to quantify the degree of interaction and show that close hand interactions are particularly challenging. Experimental results show that the MSMR-Net outperforms existing algorithms on the hand-object FreiHAND dataset as well as on our own hand-hand dataset.
Geometry-Guided Street-View Panorama Synthesis from Satellite Imagery
Mar 02, 2021
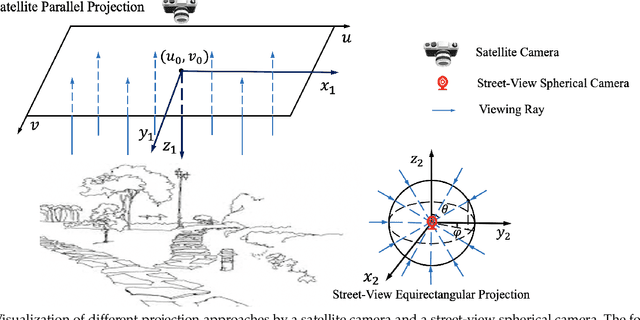
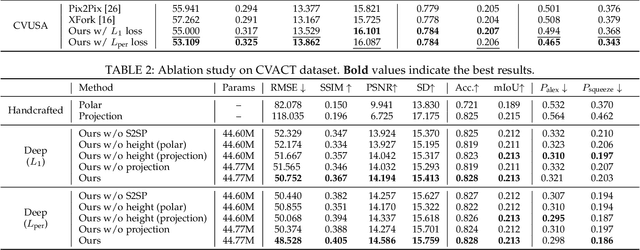
This paper presents a new approach for synthesizing a novel street-view panorama given an overhead satellite image. Taking a small satellite image patch as input, our method generates a Google's omnidirectional street-view type panorama, as if it is captured from the same geographical location as the center of the satellite patch. Existing works tackle this task as an image generation problem which adopts generative adversarial networks to implicitly learn the cross-view transformations, while ignoring the domain relevance. In this paper, we propose to explicitly establish the geometric correspondences between the two-view images so as to facilitate the cross-view transformation learning. Specifically, we observe that when a 3D point in the real world is visible in both views, there is a deterministic mapping between the projected points in the two-view images given the height information of this 3D point. Motivated by this, we develop a novel Satellite to Street-view image Projection (S2SP) module which explicitly establishes such geometric correspondences and projects the satellite images to the street viewpoint. With these projected satellite images as network input, we next employ a generator to synthesize realistic street-view panoramas that are geometrically consistent with the satellite images. Our S2SP module is differentiable and the whole framework is trained in an end-to-end manner. Extensive experimental results on two cross-view benchmark datasets demonstrate that our method generates images that better respect the scene geometry than existing approaches.
Variational Regularized Transmission Refinement for Image Dehazing
Feb 19, 2019



High-quality dehazing performance is highly dependent upon the accurate estimation of transmission map. In this work, the coarse estimation version is first obtained by weightedly fusing two different transmission maps, which are generated from foreground and sky regions, respectively. A hybrid variational model with promoted regularization terms is then proposed to assisting in refining transmission map. The resulting complicated optimization problem is effectively solved via an alternating direction algorithm. The final haze-free image can be effectively obtained according to the refined transmission map and atmospheric scattering model. Our dehazing framework has the capacity of preserving important image details while suppressing undesirable artifacts, even for hazy images with large sky regions. Experiments on both synthetic and realistic images have illustrated that the proposed method is competitive with or even outperforms the state-of-the-art dehazing techniques under different imaging conditions.
Douglas-Quaid -- Open Source Image Matching Library
Aug 12, 2019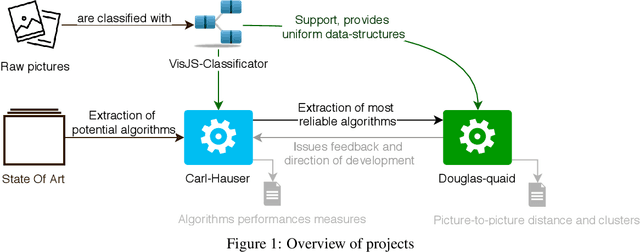
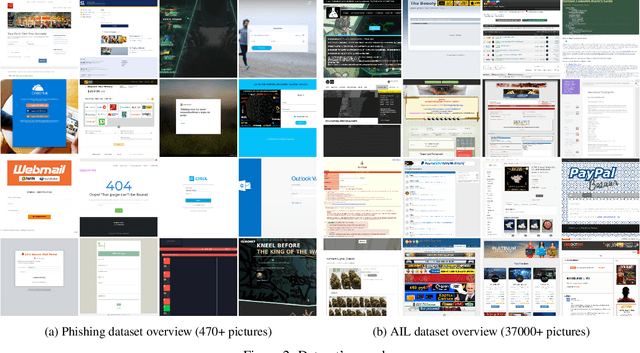
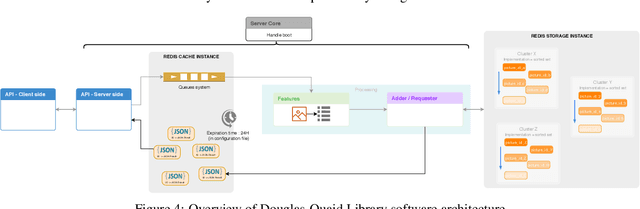
Security analysts need to classify, search and correlate numerous images. Automatic classification tools improve the efficiency of such tasks. However, no open-source and turnkey library was found able to reach this goal. The present paper introduces an Open-Source modular library for the specific cases of visual correlation and Image Matching named Douglas-Quaid. The design of the library, chosen tradeoffs, encountered challenges, envisioned solutions as well as quality and speed results are presented in this paper. We also explore researches directions and future potential developments of the library. Our claim is that even partial automation of screenshots classification would reduce the burden on security teams and that Douglas-Quaid is a step forward in this direction.
Binary Image Features Proposed to Empower Computer Vision
Aug 14, 2018

This literature has proposed three fast and easy computable image features to improve computer vision by offering more human-like vision power. These features are not based on image pixels absolute or relative intensity; neither based on shape or colour. So, no complex pixel by pixel calculation is required. For human eyes, pixel by pixel calculation is like seeing an image with maximum zoom which is done only when a higher level of details is required. Normally, first we look at an image to get an overall idea about it to know whether it deserves further investigation or not. This capacity of getting an idea at a glance is analysed and three basic features are proposed to empower computer vision. Potential of proposed features is tested and established through different medical dataset. Achieved accuracy in classification demonstrates possibilities and potential of the use of the proposed features in image processing.
Optimal Combination of Image Denoisers
May 30, 2018
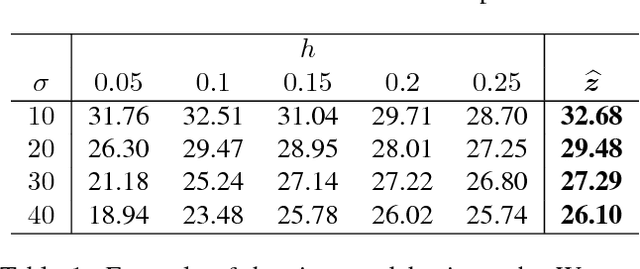
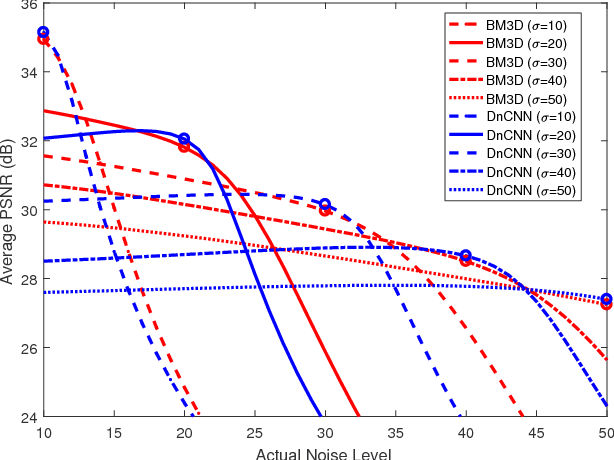

Given a set of image denoisers, each having a different denoising capability, is there a provably optimal way of combining these denoisers to produce an overall better result? An answer to this question is fundamental to designing ensembles of weak estimators for complex scenes. In this paper, we present an optimal procedure leveraging deep neural networks and convex optimization. The proposed framework, called the Consensus Neural Network (CsNet), introduces three new concepts in image denoising: (1) A deep neural network to estimate the mean squared error (MSE) of denoised images without needing the ground truths; (2) A provably optimal procedure to combine the denoised outputs via convex optimization; (3) An image boosting procedure using a deep neural network to improve contrast and to recover lost details of the combined images. Experimental results show that CsNet can consistently improve denoising performance for both deterministic and neural network denoisers.
Separating Skills and Concepts for Novel Visual Question Answering
Jul 19, 2021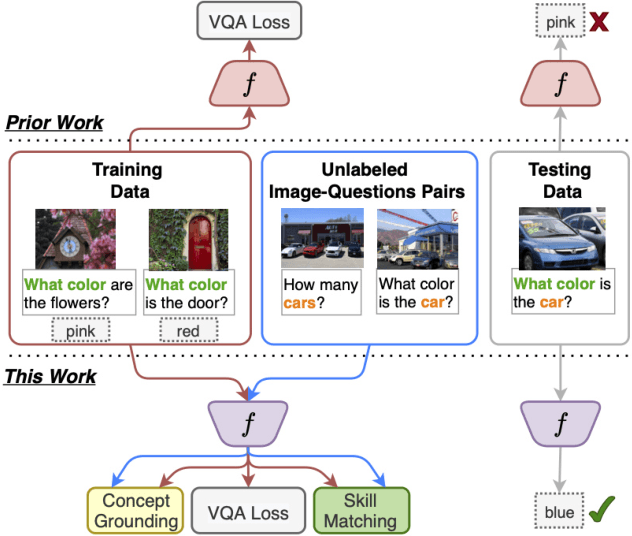
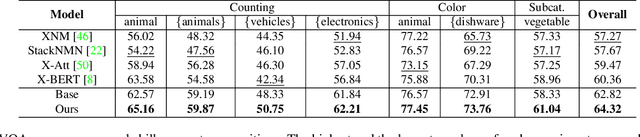
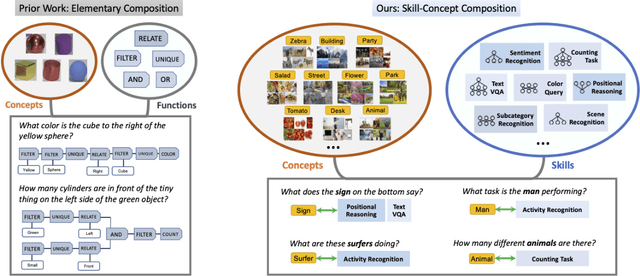
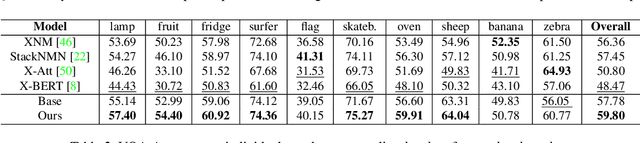
Generalization to out-of-distribution data has been a problem for Visual Question Answering (VQA) models. To measure generalization to novel questions, we propose to separate them into "skills" and "concepts". "Skills" are visual tasks, such as counting or attribute recognition, and are applied to "concepts" mentioned in the question, such as objects and people. VQA methods should be able to compose skills and concepts in novel ways, regardless of whether the specific composition has been seen in training, yet we demonstrate that existing models have much to improve upon towards handling new compositions. We present a novel method for learning to compose skills and concepts that separates these two factors implicitly within a model by learning grounded concept representations and disentangling the encoding of skills from that of concepts. We enforce these properties with a novel contrastive learning procedure that does not rely on external annotations and can be learned from unlabeled image-question pairs. Experiments demonstrate the effectiveness of our approach for improving compositional and grounding performance.
Confidence-based Out-of-Distribution Detection: A Comparative Study and Analysis
Jul 06, 2021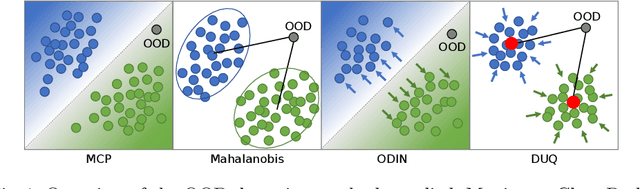
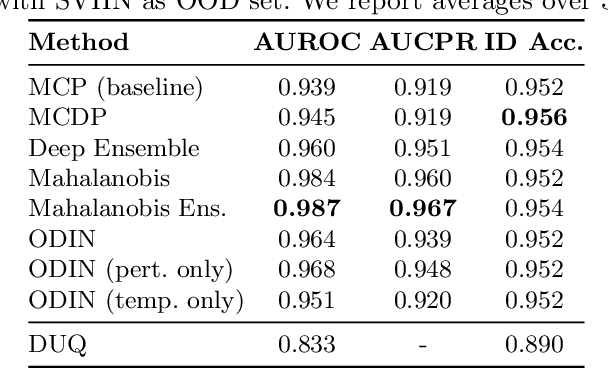
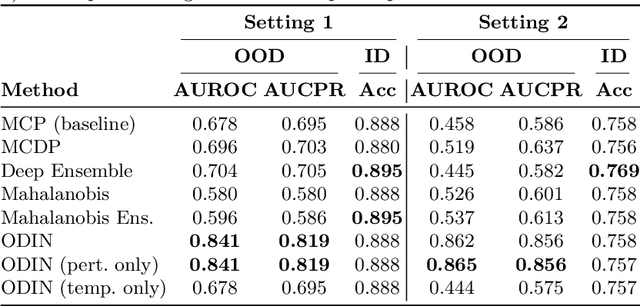
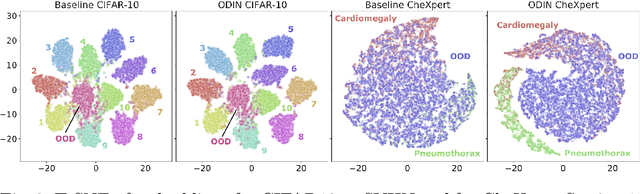
Image classification models deployed in the real world may receive inputs outside the intended data distribution. For critical applications such as clinical decision making, it is important that a model can detect such out-of-distribution (OOD) inputs and express its uncertainty. In this work, we assess the capability of various state-of-the-art approaches for confidence-based OOD detection through a comparative study and in-depth analysis. First, we leverage a computer vision benchmark to reproduce and compare multiple OOD detection methods. We then evaluate their capabilities on the challenging task of disease classification using chest X-rays. Our study shows that high performance in a computer vision task does not directly translate to accuracy in a medical imaging task. We analyse factors that affect performance of the methods between the two tasks. Our results provide useful insights for developing the next generation of OOD detection methods.
Adaptive Morphological Reconstruction for Seeded Image Segmentation
Apr 08, 2019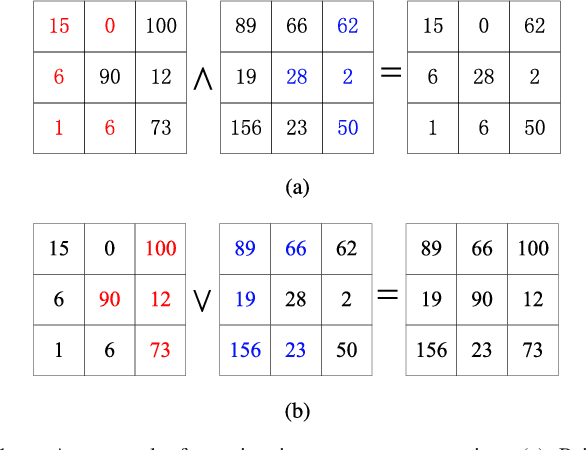
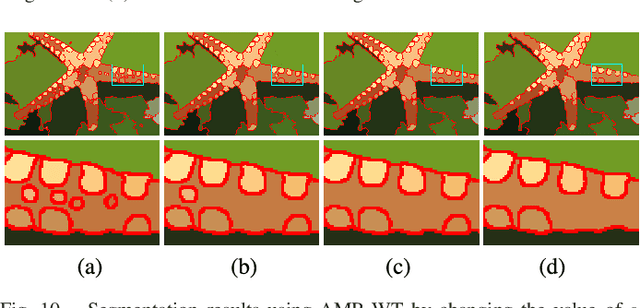
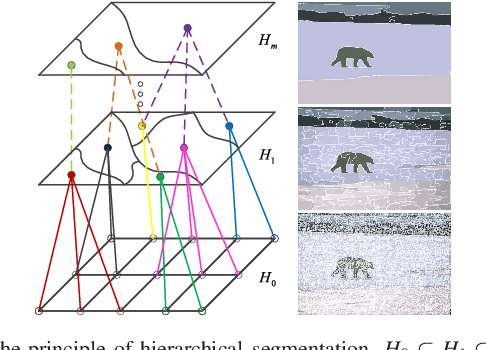

Morphological reconstruction (MR) is often employed by seeded image segmentation algorithms such as watershed transform and power watershed as it is able to filter seeds (regional minima) to reduce over-segmentation. However, MR might mistakenly filter meaningful seeds that are required for generating accurate segmentation and it is also sensitive to the scale because a single-scale structuring element is employed. In this paper, a novel adaptive morphological reconstruction (AMR) operation is proposed that has three advantages. Firstly, AMR can adaptively filter useless seeds while preserving meaningful ones. Secondly, AMR is insensitive to the scale of structuring elements because multiscale structuring elements are employed. Finally, AMR has two attractive properties: monotonic increasingness and convergence that help seeded segmentation algorithms to achieve a hierarchical segmentation. Experiments clearly demonstrate that AMR is useful for improving algorithms of seeded image segmentation and seed-based spectral segmentation. Compared to several state-of-the-art algorithms, the proposed algorithms provide better segmentation results requiring less computing time. Source code is available at https://github.com/SUST-reynole/AMR.
Imbalance-Aware Self-Supervised Learning for 3D Radiomic Representations
Mar 06, 2021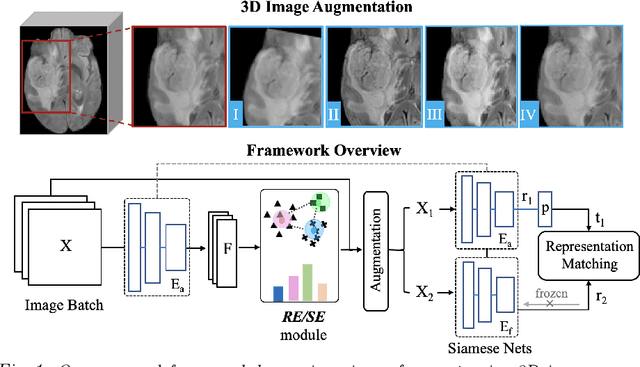

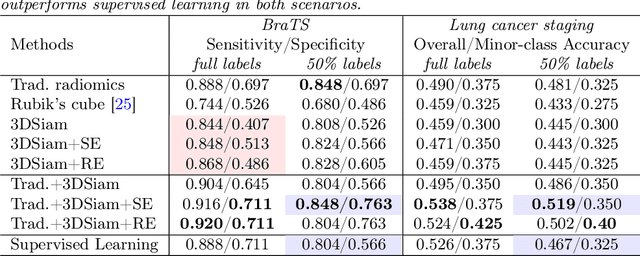
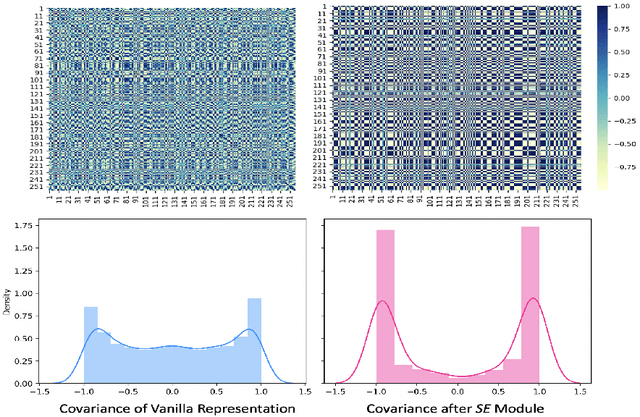
Radiomic representations can quantify properties of regions of interest in medical image data. Classically, they account for pre-defined statistics of shape, texture, and other low-level image features. Alternatively, deep learning-based representations are derived from supervised learning but require expensive annotations from experts and often suffer from overfitting and data imbalance issues. In this work, we address the challenge of learning representations of 3D medical images for an effective quantification under data imbalance. We propose a \emph{self-supervised} representation learning framework to learn high-level features of 3D volumes as a complement to existing radiomics features. Specifically, we demonstrate how to learn image representations in a self-supervised fashion using a 3D Siamese network. More importantly, we deal with data imbalance by exploiting two unsupervised strategies: a) sample re-weighting, and b) balancing the composition of training batches. When combining our learned self-supervised feature with traditional radiomics, we show significant improvement in brain tumor classification and lung cancer staging tasks covering MRI and CT imaging modalities.