 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
NLH: A Blind Pixel-level Non-local Method for Real-world Image Denoising
Jun 17, 2019
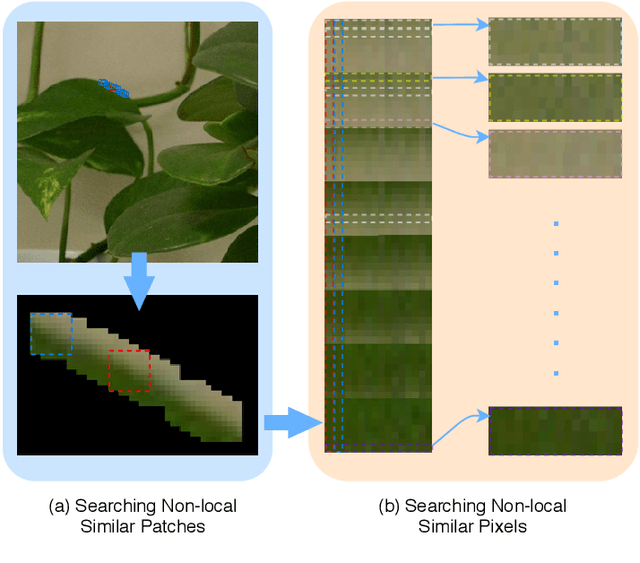
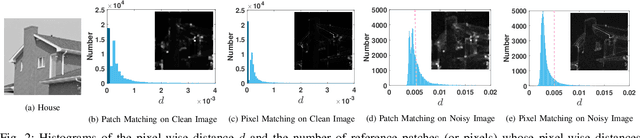
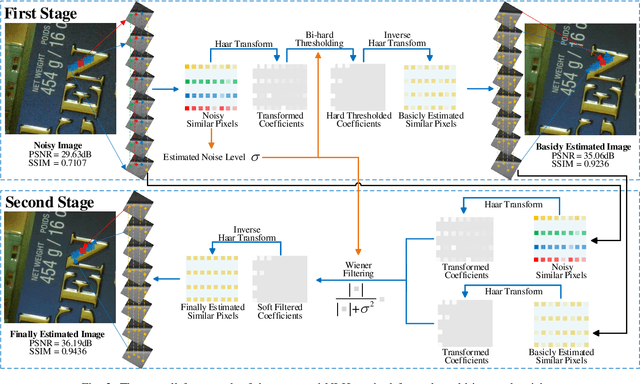

Non-local self similarity (NSS) is a powerful prior of natural images for image denoising. Most of existing denoising methods employ similar patches, which is a patch-level NSS prior. In this paper, we take one step forward by introducing a pixel-level NSS prior, i.e., searching similar pixels across a non-local region. This is motivated by the fact that finding closely similar pixels is more feasible than similar patches in natural images, which can be used to enhance image denoising performance. With the introduced pixel-level NSS prior, we propose an accurate noise level estimation method, and then develop a blind image denoising method based on the lifting Haar transform and Wiener filtering techniques. Experiments on benchmark datasets demonstrate that, the proposed method achieves much better performance than state-of-the-art methods on real-world image denoising. The code will be released.
Image retrieval method based on CNN and dimension reduction
Jan 13, 2019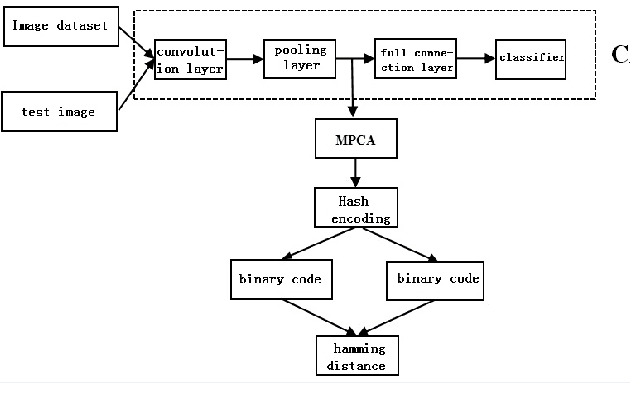

An image retrieval method based on convolution neural network and dimension reduction is proposed in this paper. Convolution neural network is used to extract high-level features of images, and to solve the problem that the extracted feature dimensions are too high and have strong correlation, multilinear principal component analysis is used to reduce the dimension of features. The features after dimension reduction are binary hash coded for fast image retrieval. Experiments show that the method proposed in this paper has better retrieval effect than the retrieval method based on principal component analysis on the e-commerce image datasets.
A Two-Stage Approach to Few-Shot Learning for Image Recognition
Dec 10, 2019
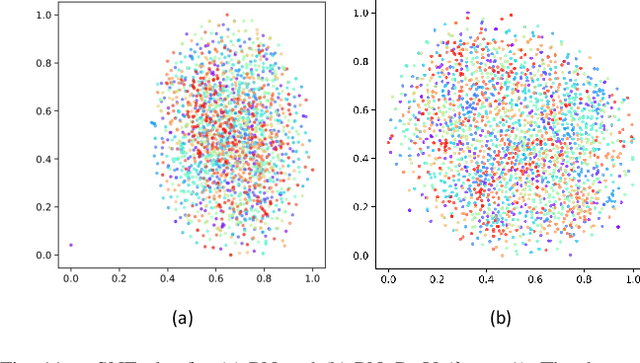
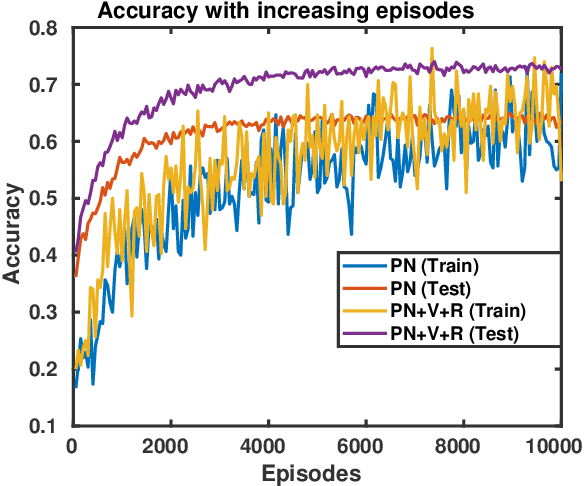
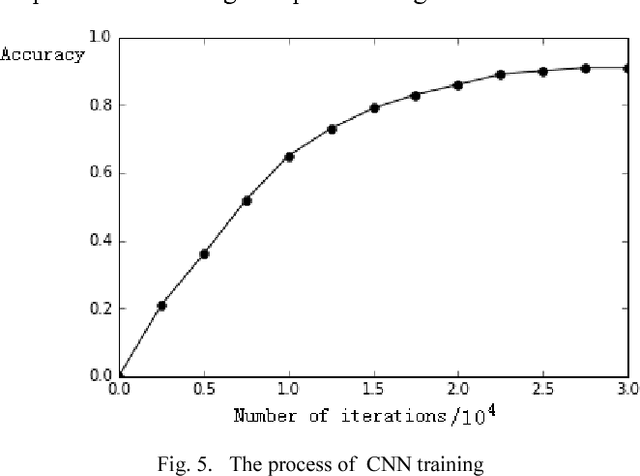
This paper proposes a multi-layer neural network structure for few-shot image recognition of novel categories. The proposed multi-layer neural network architecture encodes transferable knowledge extracted from a large annotated dataset of base categories. This architecture is then applied to novel categories containing only a few samples. The transfer of knowledge is carried out at the feature-extraction and the classification levels distributed across the two training stages. In the first-training stage, we introduce the relative feature to capture the structure of the data as well as obtain a low-dimensional discriminative space. Secondly, we account for the variable variance of different categories by using a network to predict the variance of each class. Classification is then performed by computing the Mahalanobis distance to the mean-class representation in contrast to previous approaches that used the Euclidean distance. In the second-training stage, a category-agnostic mapping is learned from the mean-sample representation to its corresponding class-prototype representation. This is because the mean-sample representation may not accurately represent the novel category prototype. Finally, we evaluate the proposed network structure on four standard few-shot image recognition datasets, where our proposed few-shot learning system produces competitive performance compared to previous work. We also extensively studied and analyzed the contribution of each component of our proposed framework.
Software Based Higher Order Structural Foot Abnormality Detection Using Image Processing
Apr 11, 2019The entire movement of human body undergoes through a periodic process named Gait Cycle. The structure of human foot is the key element to complete the cycle successfully. Abnormality of this foot structure is an alarming form of congenital disorder which results a classification based on the geometry of the human foot print image. Image processing is one of the most efficient way to determine a number of footprint parameter to detect the severeness of disorder. This paper aims to detect the Flatfoot and High Arch foot abnormalities using one of the footprint parameters named Modified Brucken Index by biomedical image processing.
Non-uniform Motion Deblurring with Blurry Component Divided Guidance
Jan 15, 2021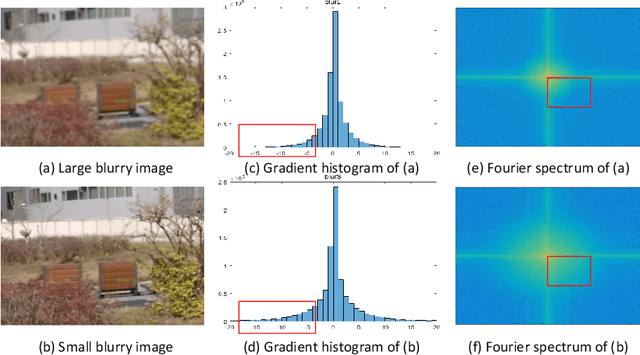
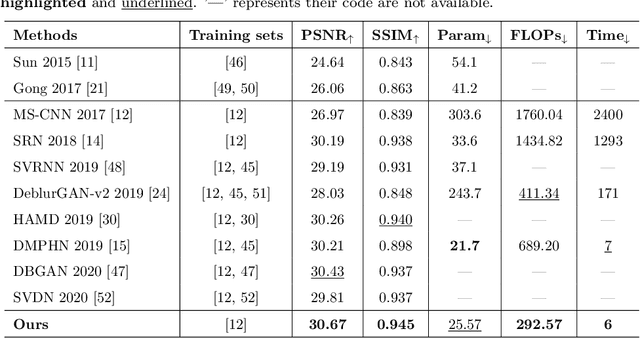


Blind image deblurring is a fundamental and challenging computer vision problem, which aims to recover both the blur kernel and the latent sharp image from only a blurry observation. Despite the superiority of deep learning methods in image deblurring have displayed, there still exists major challenge with various non-uniform motion blur. Previous methods simply take all the image features as the input to the decoder, which handles different degrees (e.g. large blur, small blur) simultaneously, leading to challenges for sharp image generation. To tackle the above problems, we present a deep two-branch network to deal with blurry images via a component divided module, which divides an image into two components based on the representation of blurry degree. Specifically, two component attentive blocks are employed to learn attention maps to exploit useful deblurring feature representations on both large and small blurry regions. Then, the blur-aware features are fed into two-branch reconstruction decoders respectively. In addition, a new feature fusion mechanism, orientation-based feature fusion, is proposed to merge sharp features of the two branches. Both qualitative and quantitative experimental results show that our method performs favorably against the state-of-the-art approaches.
Continual Local Replacement for Few-shot Image Recognition
Jan 23, 2020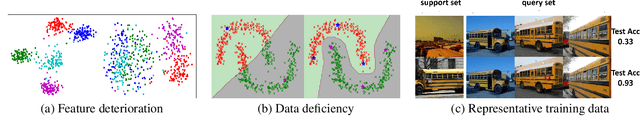
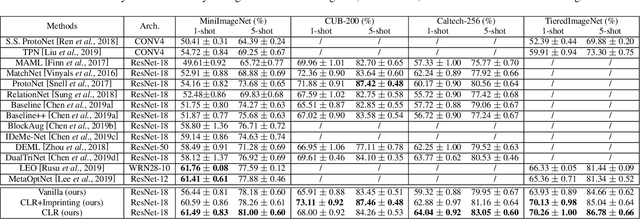

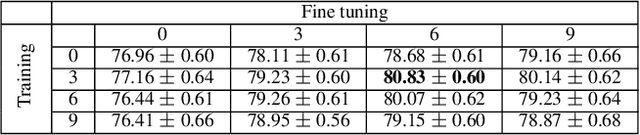
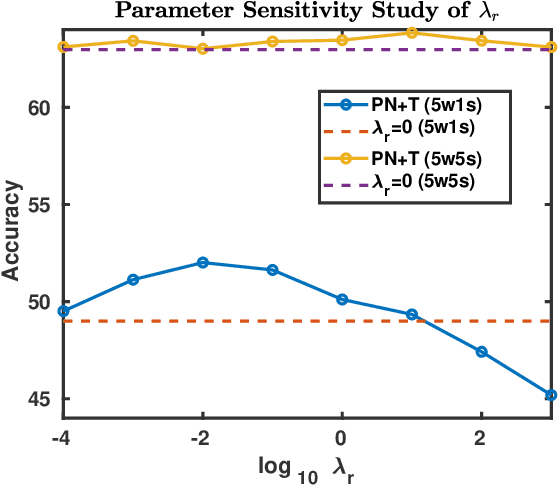
The goal of few-shot learning is to learn a model that can recognize novel classes based on one or few training data. It is challenging mainly due to two aspects: (1) it lacks good feature representation of novel classes; (2) a few labeled data could not accurately represent the true data distribution. In this work, we use a sophisticated network architecture to learn better feature representation and focus on the second issue. A novel continual local replacement strategy is proposed to address the data deficiency problem. It takes advantage of the content in unlabeled images to continually enhance labeled ones. Specifically, a pseudo labeling strategy is adopted to constantly select semantic similar images on the fly. Original labeled images will be locally replaced by the selected images for the next epoch training. In this way, the model can directly learn new semantic information from unlabeled images and the capacity of supervised signals in the embedding space can be significantly enlarged. This allows the model to improve generalization and learn a better decision boundary for classification. Extensive experiments demonstrate that our approach can achieve highly competitive results over existing methods on various few-shot image recognition benchmarks.
Spatial-spectral Hyperspectral Image Classification via Multiple Random Anchor Graphs Ensemble Learning
Mar 25, 2021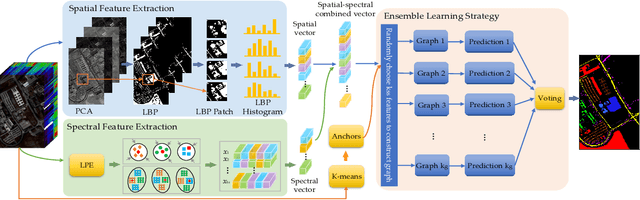
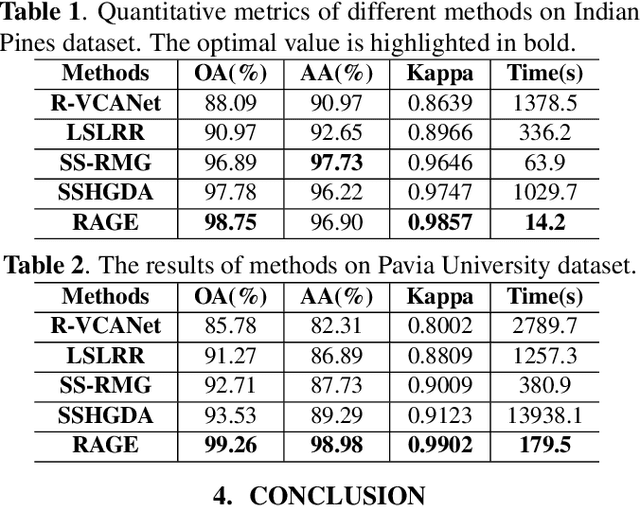
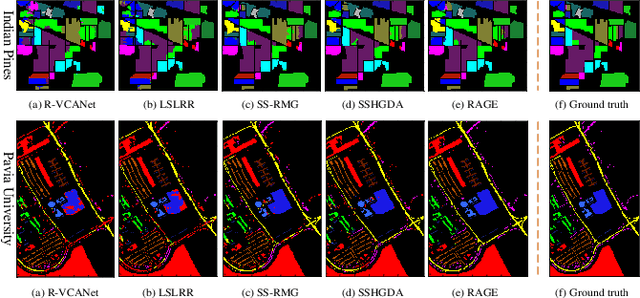
Graph-based semi-supervised learning methods, which deal well with the situation of limited labeled data, have shown dominant performance in practical applications. However, the high dimensionality of hyperspectral images (HSI) makes it hard to construct the pairwise adjacent graph. Besides, the fine spatial features that help improve the discriminability of the model are often overlooked. To handle the problems, this paper proposes a novel spatial-spectral HSI classification method via multiple random anchor graphs ensemble learning (RAGE). Firstly, the local binary pattern is adopted to extract the more descriptive features on each selected band, which preserves local structures and subtle changes of a region. Secondly, the adaptive neighbors assignment is introduced in the construction of anchor graph, to reduce the computational complexity. Finally, an ensemble model is built by utilizing multiple anchor graphs, such that the diversity of HSI is learned. Extensive experiments show that RAGE is competitive against the state-of-the-art approaches.
Learning Surrogate Models of Document Image Quality Metrics for Automated Document Image Processing
Dec 11, 2017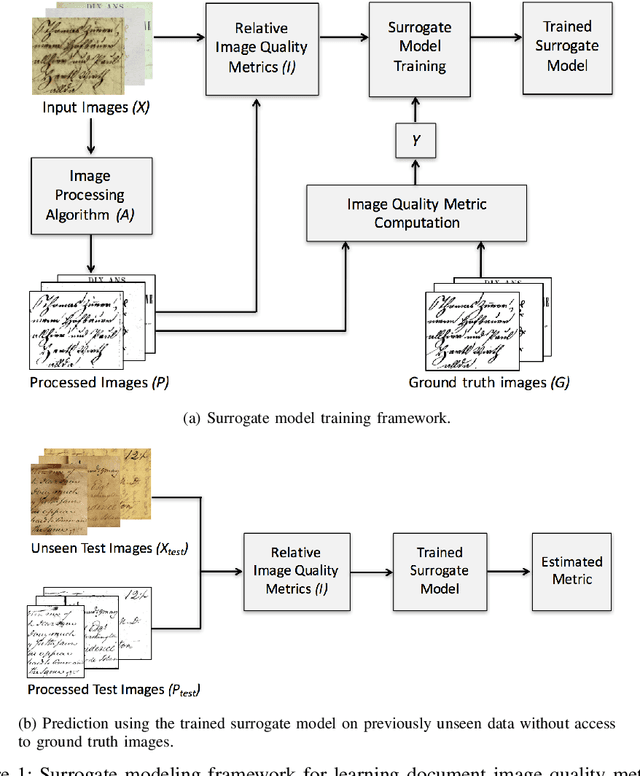
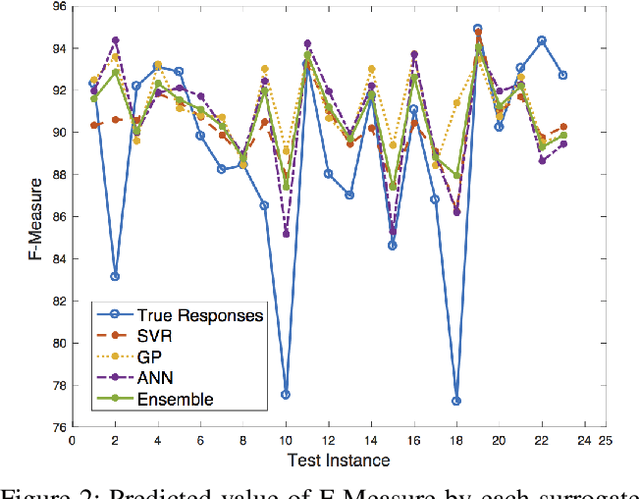


Computation of document image quality metrics often depends upon the availability of a ground truth image corresponding to the document. This limits the applicability of quality metrics in applications such as hyperparameter optimization of image processing algorithms that operate on-the-fly on unseen documents. This work proposes the use of surrogate models to learn the behavior of a given document quality metric on existing datasets where ground truth images are available. The trained surrogate model can later be used to predict the metric value on previously unseen document images without requiring access to ground truth images. The surrogate model is empirically evaluated on the Document Image Binarization Competition (DIBCO) and the Handwritten Document Image Binarization Competition (H-DIBCO) datasets.
Bridging the Domain Gap for Ground-to-Aerial Image Matching
Apr 24, 2019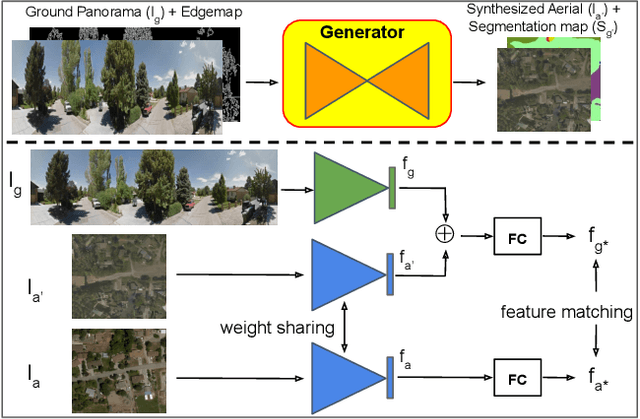
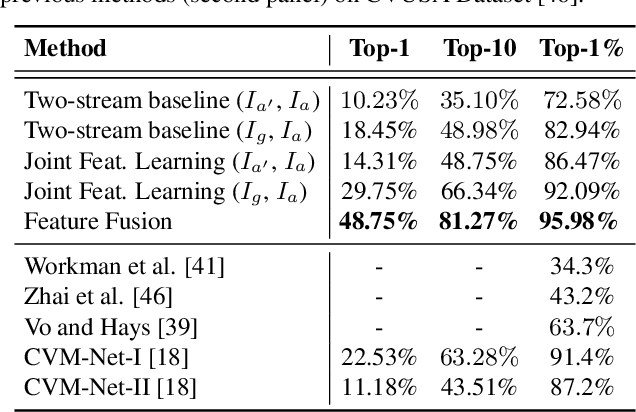
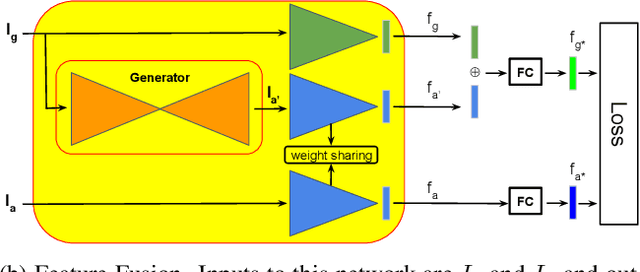
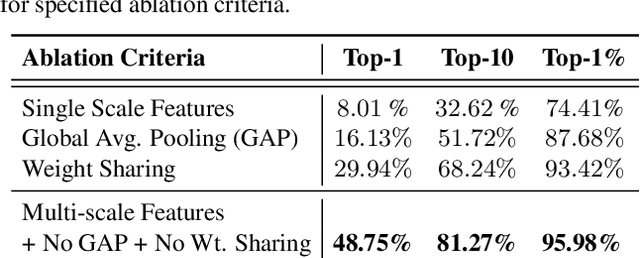
The visual entities in cross-view images exhibit drastic domain changes due to the difference in viewpoints each set of images is captured from. Existing state-of-the-art methods address the problem by learning view-invariant descriptors for the images. We propose a novel method for solving this task by exploiting the generative powers of conditional GANs to synthesize an aerial representation of a ground level panorama and use it to minimize the domain gap between the two views. The synthesized image being from the same view as the target image helps the network to preserve important cues in aerial images following our Joint Feature Learning approach. Our Feature Fusion method combines the complementary features from a synthesized aerial image with the corresponding ground features to obtain a robust query representation. In addition, multi-scale feature aggregation preserves image representations at different feature scales useful for solving this complex task. Experimental results show that our proposed approach performs significantly better than the state-of-the-art methods on the challenging CVUSA dataset in terms of top-1 and top-1% retrieval accuracies. Furthermore, to evaluate the generalization of our method on urban landscapes, we collected a new cross-view localization dataset with geo-reference information.
Membership Inference Attacks on Lottery Ticket Networks
Aug 07, 2021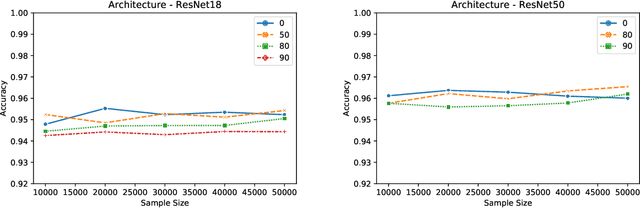
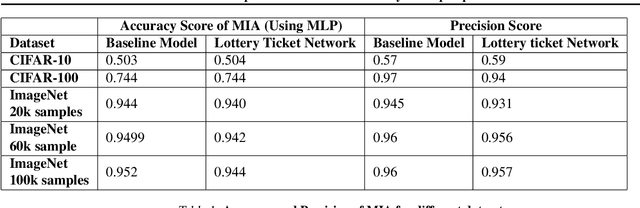
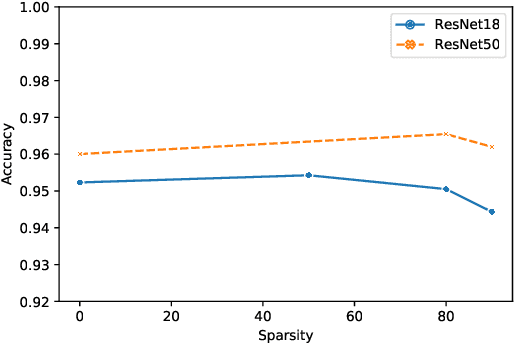
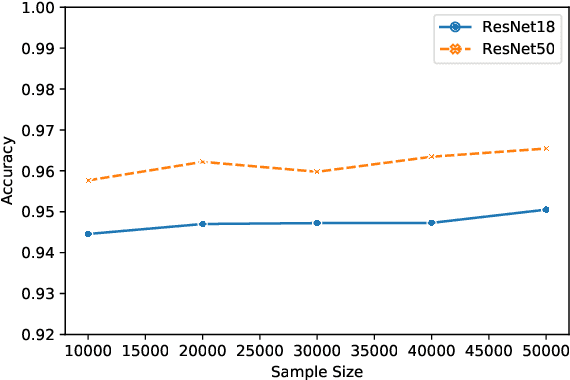
The vulnerability of the Lottery Ticket Hypothesis has not been studied from the purview of Membership Inference Attacks. Through this work, we are the first to empirically show that the lottery ticket networks are equally vulnerable to membership inference attacks. A Membership Inference Attack (MIA) is the process of determining whether a data sample belongs to a training set of a trained model or not. Membership Inference Attacks could leak critical information about the training data that can be used for targeted attacks. Recent deep learning models often have very large memory footprints and a high computational cost associated with training and drawing inferences. Lottery Ticket Hypothesis is used to prune the networks to find smaller sub-networks that at least match the performance of the original model in terms of test accuracy in a similar number of iterations. We used CIFAR-10, CIFAR-100, and ImageNet datasets to perform image classification tasks and observe that the attack accuracies are similar. We also see that the attack accuracy varies directly according to the number of classes in the dataset and the sparsity of the network. We demonstrate that these attacks are transferable across models with high accuracy.