 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Current Advances in Computational Lung Ultrasound Imaging: A Review
Mar 23, 2021
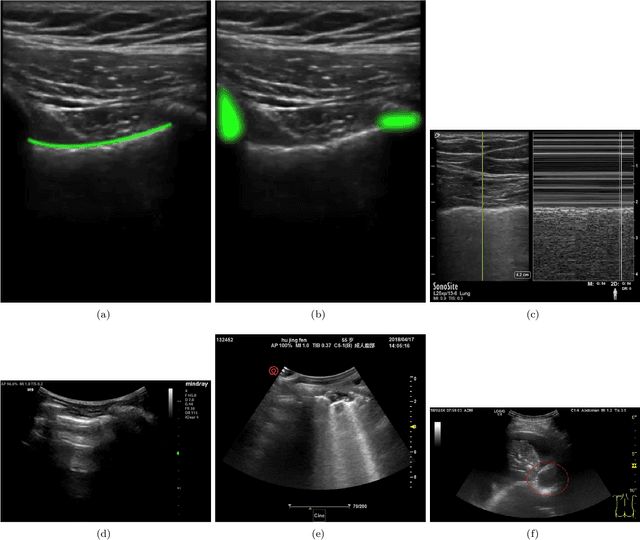
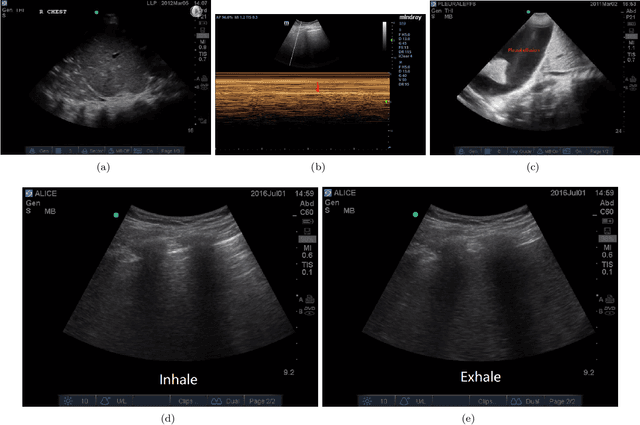
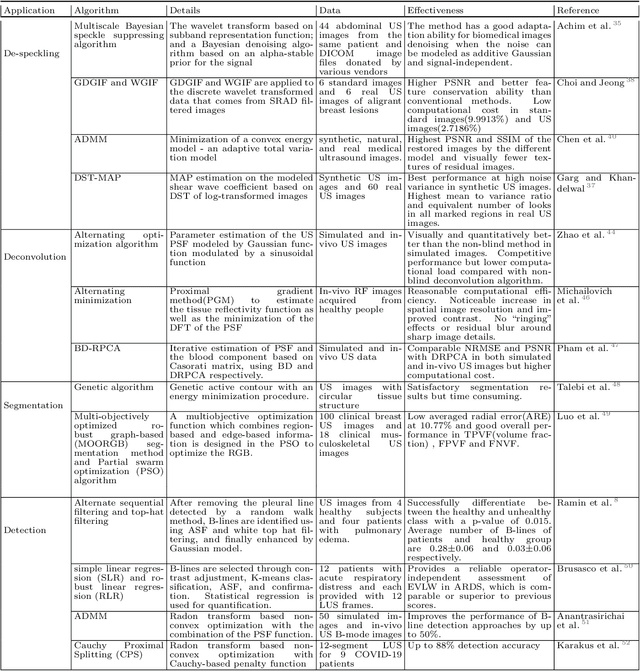
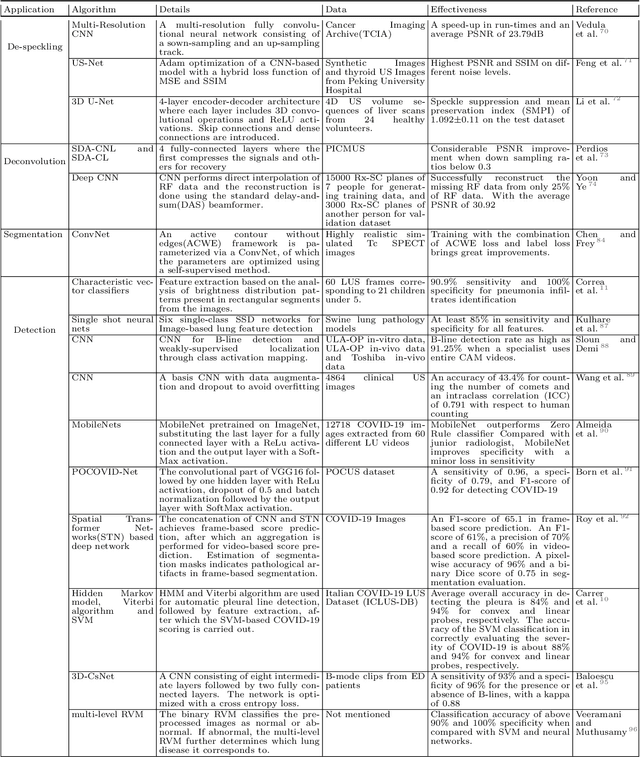
In the field of biomedical imaging, ultrasonography has become increasingly widespread, and an important auxiliary diagnostic tool with unique advantages, such as being non-ionising and often portable. This article reviews the state-of-the-art in medical ultrasound image computing and in particular its application in the examination of the lungs. First, we review the current developments in medical ultrasound technology. We then focus on the characteristics of lung ultrasonography and on its ability to diagnose a variety of diseases through the identification of various artefacts. We review medical ultrasound image processing methods by splitting them into two categories: (1) traditional model-based methods, and (2) data driven methods. For the former, we consider inverse problem based methods by focusing in particular on ultrasound image despeckling, deconvolution, and line artefacts detection. Among the data-driven approaches, we discuss various works based on deep/machine learning, which include various effective network architectures implementing supervised, weakly supervised and unsupervised learning.
A Global Appearance and Local Coding Distortion based Fusion Framework for CNN based Filtering in Video Coding
Jun 24, 2021

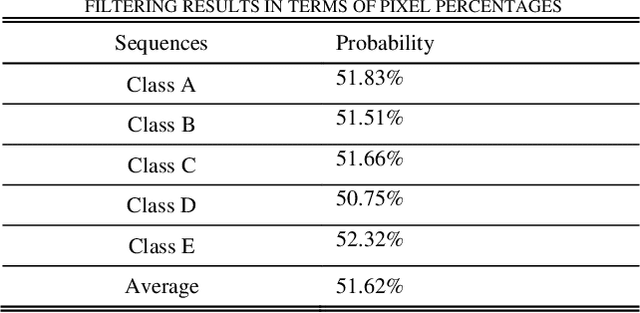
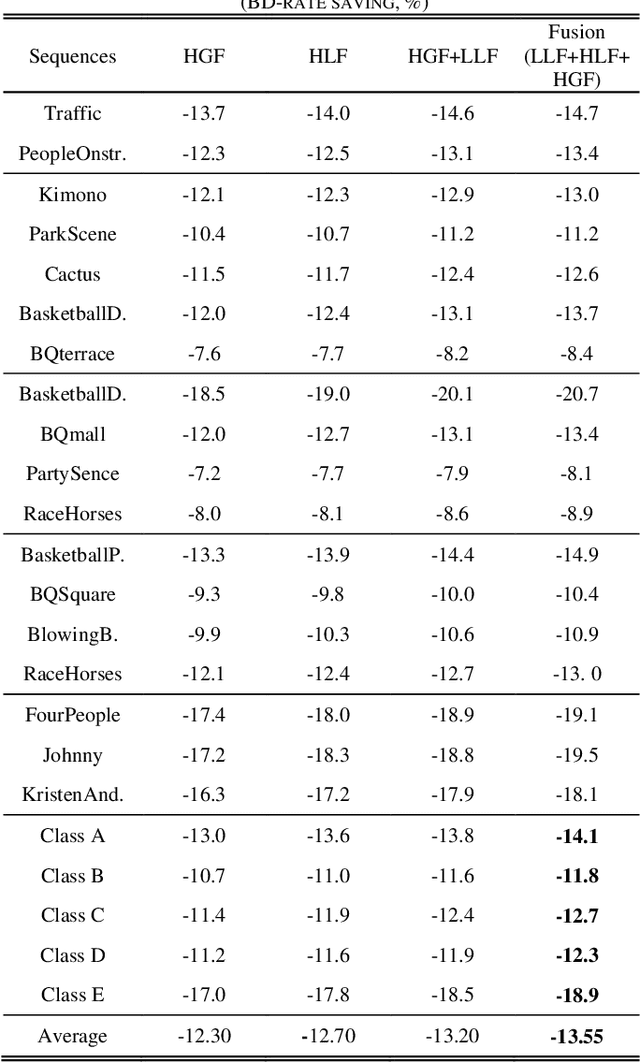
In-loop filtering is used in video coding to process the reconstructed frame in order to remove blocking artifacts. With the development of convolutional neural networks (CNNs), CNNs have been explored for in-loop filtering considering it can be treated as an image de-noising task. However, in addition to being a distorted image, the reconstructed frame is also obtained by a fixed line of block based encoding operations in video coding. It carries coding-unit based coding distortion of some similar characteristics. Therefore, in this paper, we address the filtering problem from two aspects, global appearance restoration for disrupted texture and local coding distortion restoration caused by fixed pipeline of coding. Accordingly, a three-stream global appearance and local coding distortion based fusion network is developed with a high-level global feature stream, a high-level local feature stream and a low-level local feature stream. Ablation study is conducted to validate the necessity of different features, demonstrating that the global features and local features can complement each other in filtering and achieve better performance when combined. To the best of our knowledge, we are the first one that clearly characterizes the video filtering process from the above global appearance and local coding distortion restoration aspects with experimental verification, providing a clear pathway to developing filter techniques. Experimental results demonstrate that the proposed method significantly outperforms the existing single-frame based methods and achieves 13.5%, 11.3%, 11.7% BD-Rate saving on average for AI, LDP and RA configurations, respectively, compared with the HEVC reference software.
Self-Supervised 3D Hand Pose Estimation from monocular RGB via Contrastive Learning
Jun 10, 2021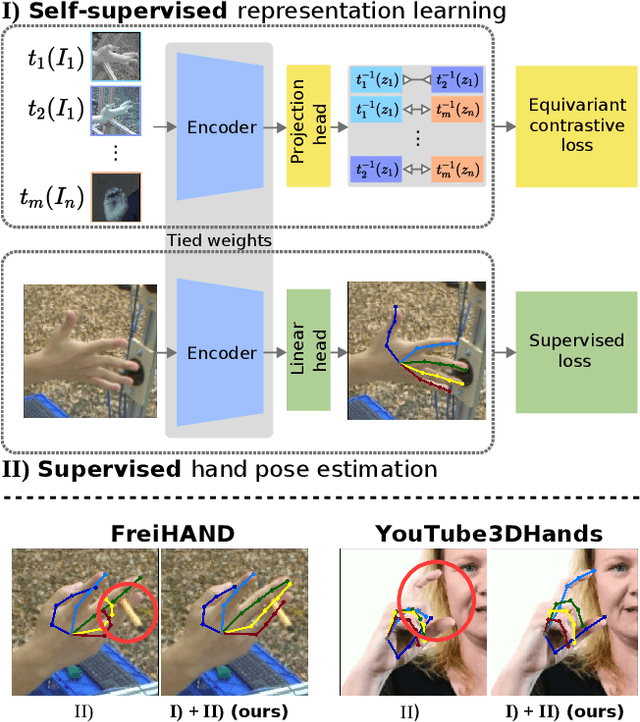
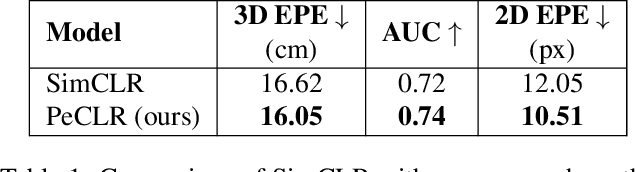
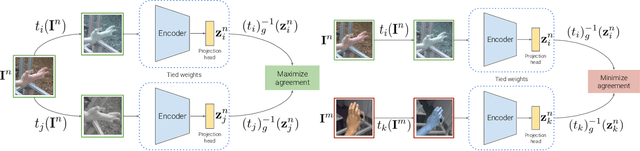
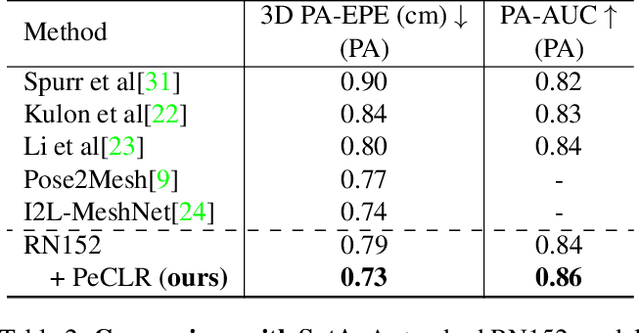
Acquiring accurate 3D annotated data for hand pose estimation is a notoriously difficult problem. This typically requires complex multi-camera setups and controlled conditions, which in turn creates a domain gap that is hard to bridge to fully unconstrained settings. Encouraged by the success of contrastive learning on image classification tasks, we propose a new self-supervised method for the structured regression task of 3D hand pose estimation. Contrastive learning makes use of unlabeled data for the purpose of representation learning via a loss formulation that encourages the learned feature representations to be invariant under any image transformation. For 3D hand pose estimation, it too is desirable to have invariance to appearance transformation such as color jitter. However, the task requires equivariance under affine transformations, such as rotation and translation. To address this issue, we propose an equivariant contrastive objective and demonstrate its effectiveness in the context of 3D hand pose estimation. We experimentally investigate the impact of invariant and equivariant contrastive objectives and show that learning equivariant features leads to better representations for the task of 3D hand pose estimation. Furthermore, we show that a standard ResNet-152, trained on additional unlabeled data, attains an improvement of $7.6\%$ in PA-EPE on FreiHAND and thus achieves state-of-the-art performance without any task specific, specialized architectures.
Perceptually Guided Adversarial Perturbations
Jun 24, 2021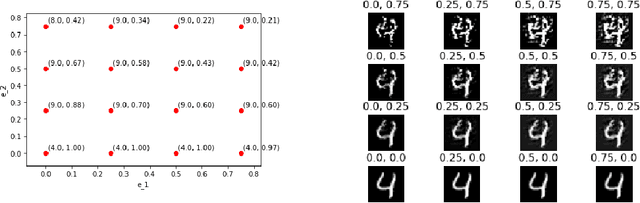

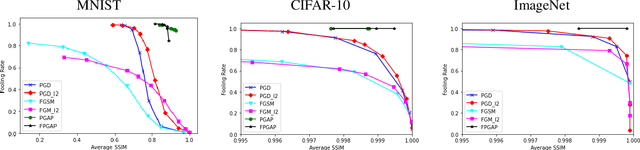
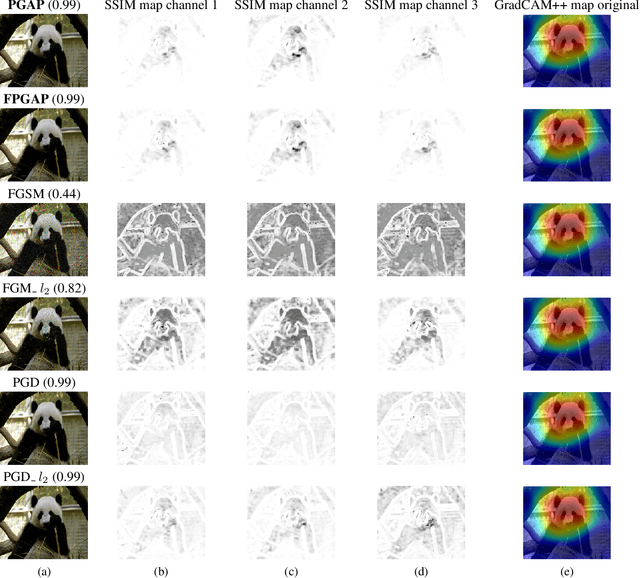
It is well known that carefully crafted imperceptible perturbations can cause state-of-the-art deep learning classification models to misclassify. Understanding and analyzing these adversarial perturbations play a crucial role in the design of robust convolutional neural networks. However, the reasons for the existence of adversarial perturbations and their mechanics are not well understood. In this work, we attempt to systematically answer the following question: do imperceptible adversarial perturbations focus on changing the regions of the image that are important for classification? Most current methods use $l_p$ distance to generate and characterize the imperceptibility of the adversarial perturbations. However, since $l_p$ distances only measure the pixel to pixel distances and do not consider the structure in the image, these methods do not provide a satisfactory answer to the above question. To address this issue, we propose a novel framework for generating adversarial perturbations by explicitly incorporating a ``perceptual quality ball" constraint in our formulation. Specifically, we pose the adversarial example generation problem as a tractable convex optimization problem, with constraints taken from a mathematically amenable variant of the popular SSIM index. We show that the perturbations generated by the proposed method result in a high fooling rate with minimal impact on perceptual quality compared to the norm bounded adversarial perturbations. Further, through SSIM maps, we show that the perceptually guided perturbations introduce changes specifically in the regions that contribute to classification decisions. We use networks trained on MNIST and CIFAR-10 datasets quantitative analysis, and MobileNetV2 trained on the ImageNet dataset for further qualitative analysis.
A comprehensive evaluation of full-reference image quality assessment algorithms on KADID-10k
Jul 03, 2019

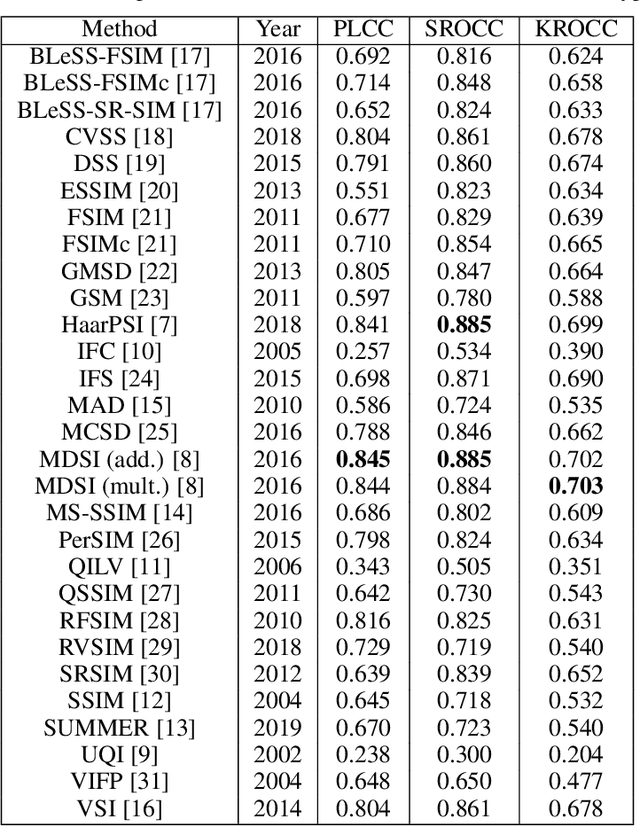
Significant progress has been made in the past decade for full-reference image quality assessment (FR-IQA). However, new large scale image quality databases have been released for evaluating image quality assessment algorithms. In this study, our goal is to give a comprehensive evaluation of state-of-the-art FR-IQA metrics using the recently published KADID-10k database which is largest available one at the moment. Our evaluation results and the associated discussions is very helpful to obtain a clear understanding about the status of state-of-the-art FR-IQA metrics.
Inharmonious Region Localization
Apr 19, 2021
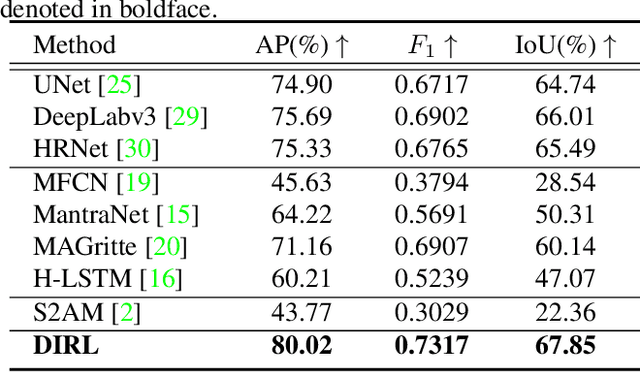
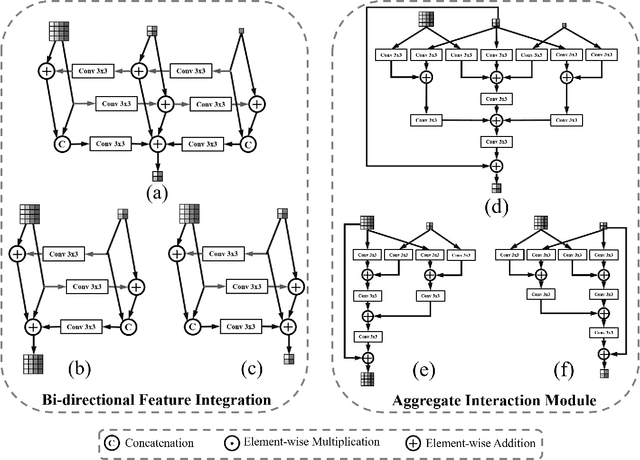
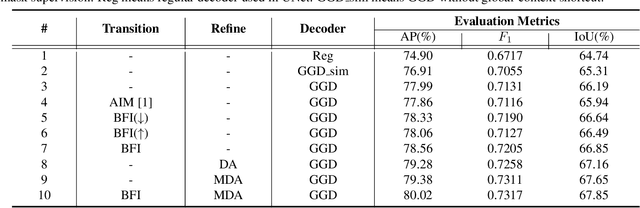
The advance of image editing techniques allows users to create artistic works, but the manipulated regions may be incompatible with the background. Localizing the inharmonious region is an appealing yet challenging task. Realizing that this task requires effective aggregation of multi-scale contextual information and suppression of redundant information, we design novel Bi-directional Feature Integration (BFI) block and Global-context Guided Decoder (GGD) block to fuse multi-scale features in the encoder and decoder respectively. We also employ Mask-guided Dual Attention (MDA) block between the encoder and decoder to suppress the redundant information. Experiments on the image harmonization dataset demonstrate that our method achieves competitive performance for inharmonious region localization. The source code is available at https://github.com/bcmi/DIRL.
A novel text representation which enables image classifiers to perform text classification, applied to name disambiguation
Aug 19, 2019
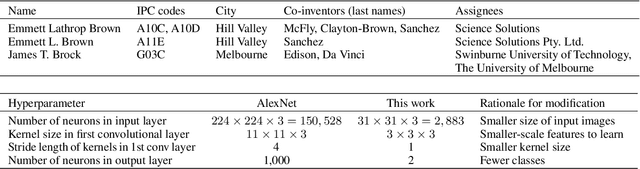


Patent data are often used to study the process of innovation and research, but patent databases lack unique identifiers for individual inventors, making it difficult to study innovation processes at the individual level. Here we introduce an algorithm that performs highly accurate disambiguation of inventors (named entities) in US patent data (F1: 99.09%, precision: 99.41%, recall: 98.76%). The algorithm involves a novel method for converting text-based record data into abstract image representations, in which text from a given pairwise comparison between two inventor name records is converted into a 2D RGB (stacked) image representation. We train an image classification neural network to discriminate between such pairwise comparison images, and then use the trained network to label each pair of records as either matched (same inventor) or non-matched (different inventors). The resulting disambiguation algorithm produces highly accurate results, out-performing other inventor name disambiguation studies on US patent data. Our new text-to-image representation method could potentially be used more broadly for other NLP comparison problems, as it allows image-based processing techniques (e.g. image classification networks) to be applied to text-based comparison problems (such as disambiguation of academic publications, or data linkage problems).
Learning Multi-level Deep Representations for Image Emotion Classification
Sep 25, 2018
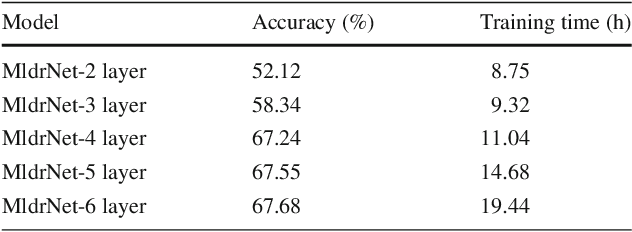

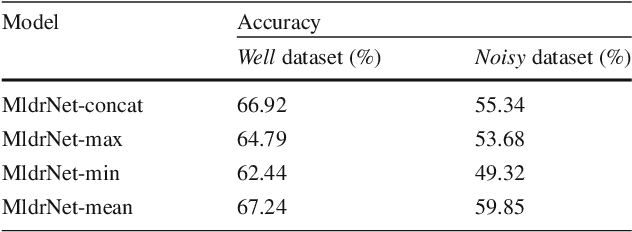
In this paper, we propose a new deep network that learns multi-level deep representations for image emotion classification (MldrNet). Image emotion can be recognized through image semantics, image aesthetics and low-level visual features from both global and local views. Existing image emotion classification works using hand-crafted features or deep features mainly focus on either low-level visual features or semantic-level image representations without taking all factors into consideration. The proposed MldrNet combines deep representations of different levels, i.e. image semantics, image aesthetics, and low-level visual features to effectively classify the emotion types of different kinds of images, such as abstract paintings and web images. Extensive experiments on both Internet images and abstract paintings demonstrate the proposed method outperforms the state-of-the-art methods using deep features or hand-crafted features. The proposed approach also outperforms the state-of-the-art methods with at least 6% performance improvement in terms of overall classification accuracy.
MetH: A family of high-resolution and variable-shape image challenges
Nov 29, 2019
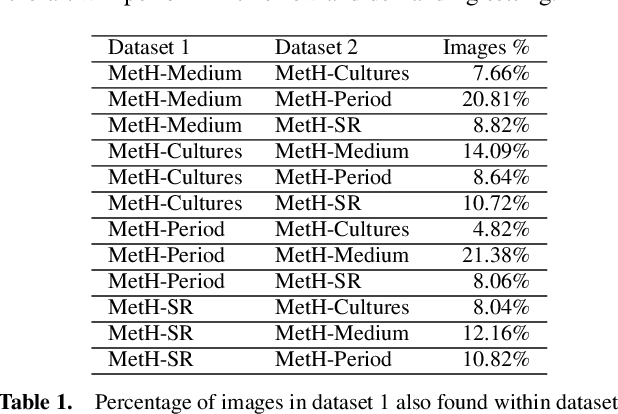
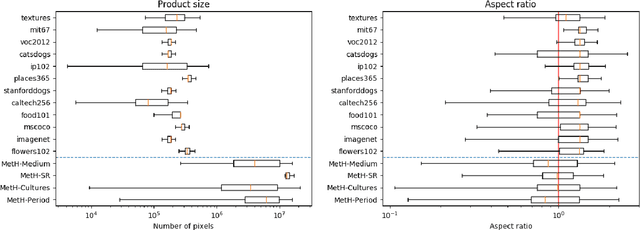
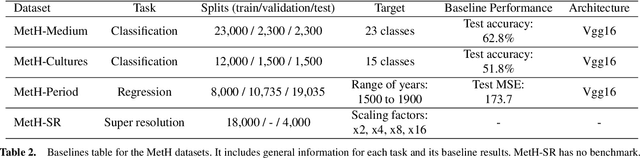
High-resolution and variable-shape images have not yet been properly addressed by the AI community. The approach of down-sampling data often used with convolutional neural networks is sub-optimal for many tasks, and has too many drawbacks to be considered a sustainable alternative. In sight of the increasing importance of problems that can benefit from exploiting high-resolution (HR) and variable-shape, and with the goal of promoting research in that direction, we introduce a new family of datasets (MetH). The four proposed problems include two image classification, one image regression and one super resolution task. Each of these datasets contains thousands of art pieces captured by HR and variable-shape images, labeled by experts at the Metropolitan Museum of Art. We perform an analysis, which shows how the proposed tasks go well beyond current public alternatives in both pixel size and aspect ratio variance. At the same time, the performance obtained by popular architectures on these tasks shows that there is ample room for improvement. To wrap up the relevance of the contribution we review the fields, both in AI and high-performance computing, that could benefit from the proposed challenges.
Event-driven Vision and Control for UAVs on a Neuromorphic Chip
Aug 08, 2021
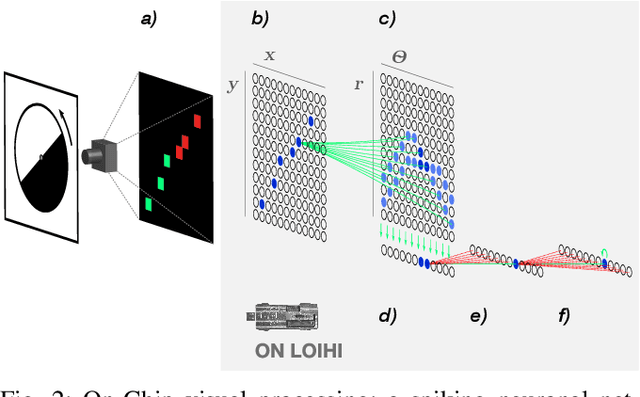
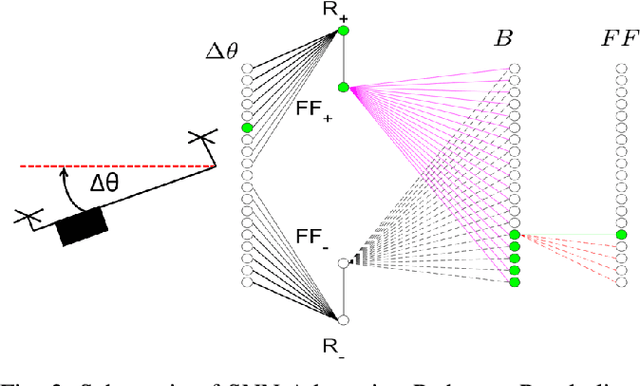
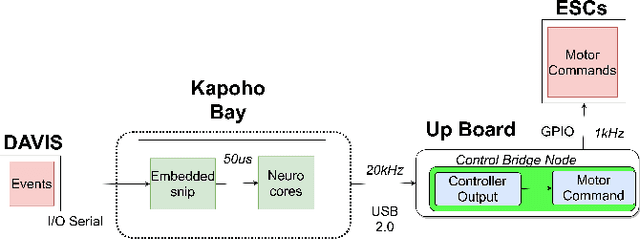
Event-based vision sensors achieve up to three orders of magnitude better speed vs. power consumption trade off in high-speed control of UAVs compared to conventional image sensors. Event-based cameras produce a sparse stream of events that can be processed more efficiently and with a lower latency than images, enabling ultra-fast vision-driven control. Here, we explore how an event-based vision algorithm can be implemented as a spiking neuronal network on a neuromorphic chip and used in a drone controller. We show how seamless integration of event-based perception on chip leads to even faster control rates and lower latency. In addition, we demonstrate how online adaptation of the SNN controller can be realised using on-chip learning. Our spiking neuronal network on chip is the first example of a neuromorphic vision-based controller solving a high-speed UAV control task. The excellent scalability of processing in neuromorphic hardware opens the possibility to solve more challenging visual tasks in the future and integrate visual perception in fast control loops.