 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA novel text representation which enables image classifiers to perform text classification
Paper and Code
Sep 27, 2019
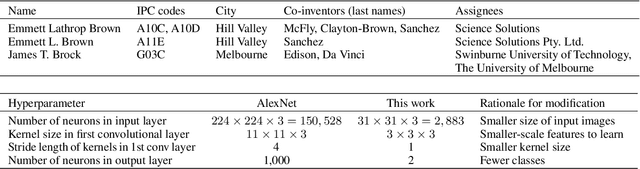


We introduce a novel method for converting text data into abstract image representations, which allows image-based processing techniques (e.g. image classification networks) to be applied to text-based comparison problems. We apply the technique to entity disambiguation of inventor names in US patents. The method involves converting text from each pairwise comparison between two inventor name records into a 2D RGB (stacked) image representation. We then train an image classification neural network to discriminate between such pairwise comparison images, and use the trained network to label each pair of records as either matched (same inventor) or non-matched (different inventors), obtaining highly accurate results (F1: 99.09%, precision: 99.41%, recall: 98.76%). Our new text-to-image representation method could potentially be used more broadly for other NLP comparison problems, such as disambiguation of academic publications, or for problems that require simultaneous classification of both text and images.