 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Face Identification Proficiency Test Designed Using Item Response Theory
Jul 01, 2021
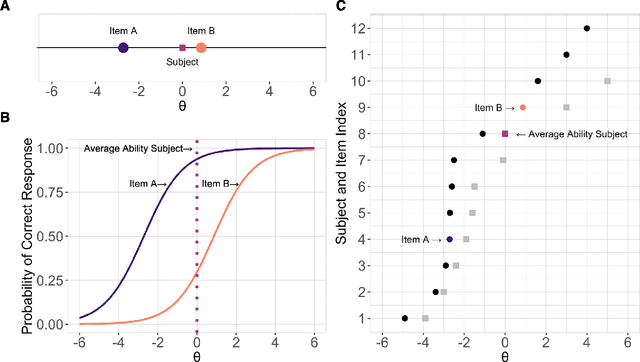
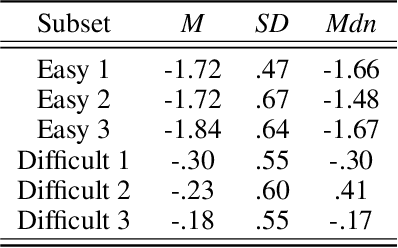
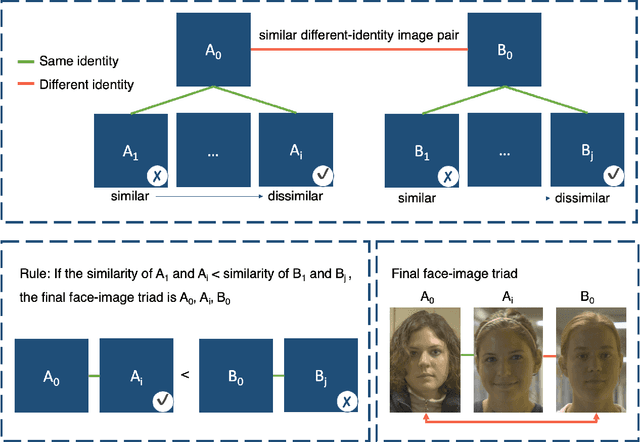
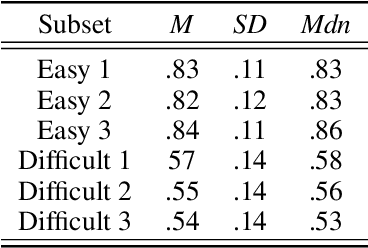
Measures of face identification proficiency are essential to ensure accurate and consistent performance by professional forensic face examiners and others who perform face identification tasks in applied scenarios. Current proficiency tests rely on static sets of stimulus items, and so, cannot be administered validly to the same individual multiple times. To create a proficiency test, a large number of items of "known" difficulty must be assembled. Multiple tests of equal difficulty can be constructed then using subsets of items. Here, we introduce a proficiency test, the Triad Identity Matching (TIM) test, based on stimulus difficulty measures based on Item Response Theory (IRT). Participants view face-image "triads" (N=225) (two images of one identity and one image of a different identity) and select the different identity. In Experiment 1, university students (N=197) showed wide-ranging accuracy on the TIM test. Furthermore, IRT modeling demonstrated that the TIM test produces items of various difficulty levels. In Experiment 2, IRT-based item difficulty measures were used to partition the TIM test into three equally "easy" and three equally "difficult" subsets. Simulation results indicated that the full set, as well as curated subsets, of the TIM items yielded reliable estimates of subject ability. In summary, the TIM test can provide a starting point for developing a framework that is flexible, calibrated, and adaptive to measure proficiency across various ability levels (e.g., professionals or populations with face processing deficits)
Intention Oriented Image Captions with Guiding Objects
Nov 19, 2018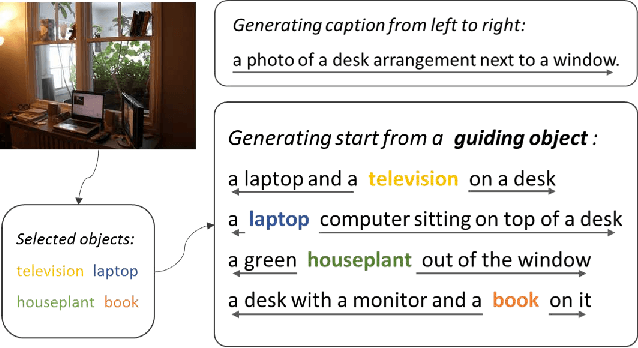
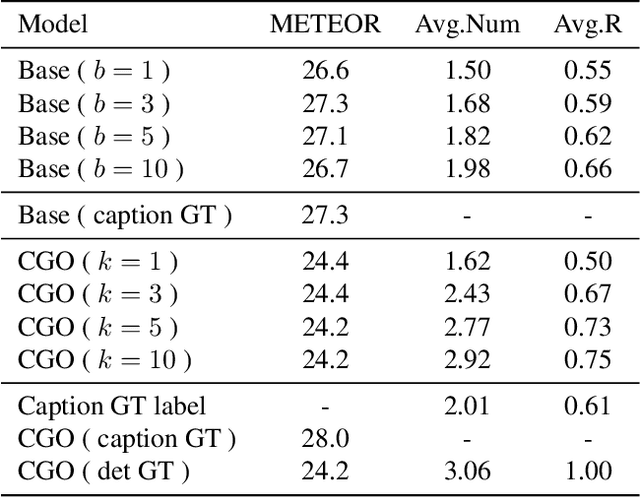
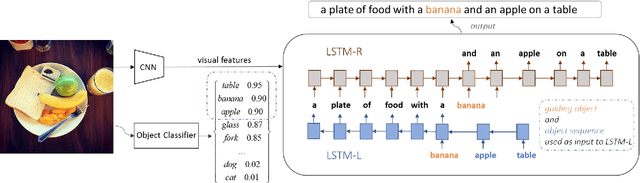
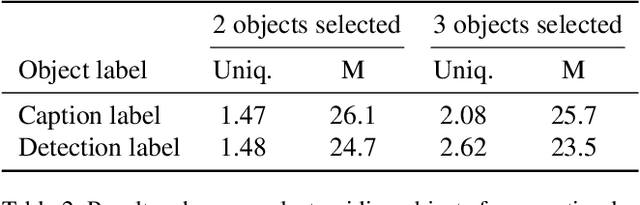
Although existing image caption models can produce promising results using recurrent neural networks (RNNs), it is difficult to guarantee that an object we care about is contained in generated descriptions, for example in the case that the object is inconspicuous in image. Problems become even harder when these objects did not appear in training stage. In this paper, we propose a novel approach for generating image captions with guiding objects (CGO). The CGO constrains the model to involve a human-concerned object, when the object is in the image, in the generated description while maintaining fluency. Instead of generating the sequence from left to right, we start description with a selected object and generate other parts of the sequence based on this object. To achieve this, we design a novel framework combining two LSTMs in opposite directions. We demonstrate the characteristics of our method on MSCOCO to generate descriptions for each detected object in images. With CGO, we can extend the ability of description to the objects being neglected in image caption labels and provide a set of more comprehensive and diverse descriptions for an image. CGO shows obvious advantages when applied to the task of describing novel objects. We show experiment results on both MSCOCO and ImageNet datasets. Evaluations show that our method outperforms the state-of-the-art models in the task with average F1 75.8, leading to better descriptions in terms of both content accuracy and fluency.
Comprehensive Validation of Automated Whole Body Skeletal Muscle, Adipose Tissue, and Bone Segmentation from 3D CT images for Body Composition Analysis: Towards Extended Body Composition
Jun 01, 2021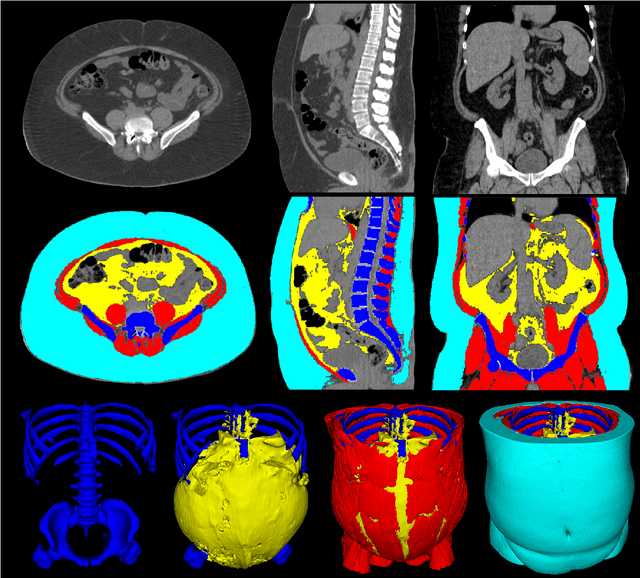

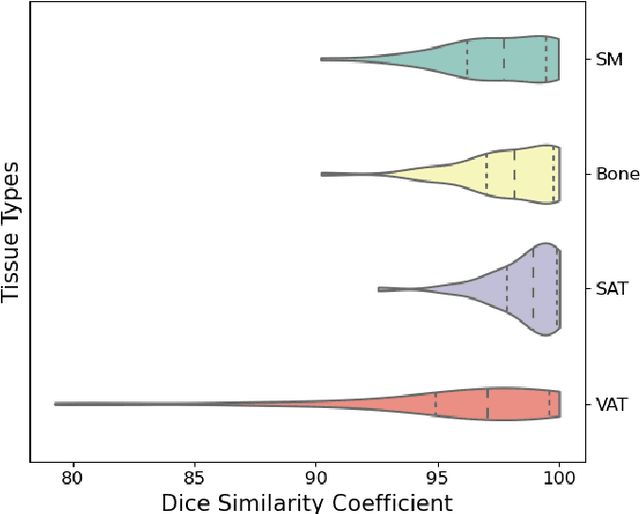
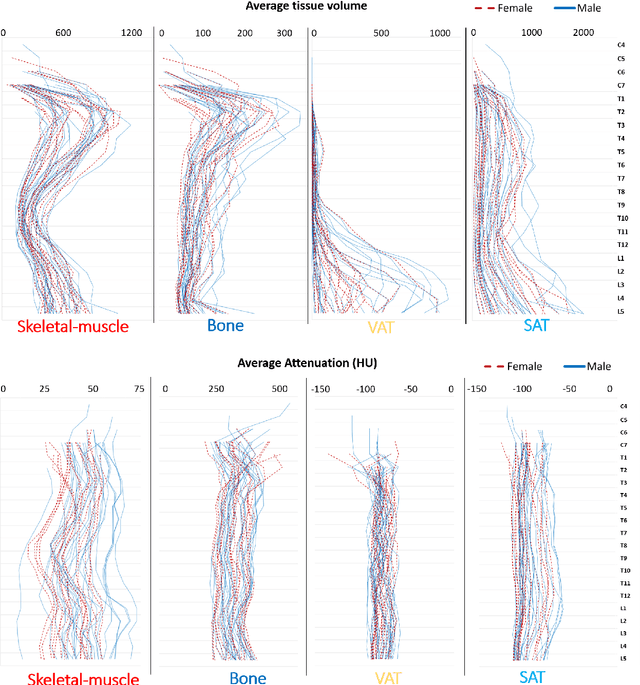
The latest advances in computer-assisted precision medicine are making it feasible to move from population-wide models that are useful to discover aggregate patterns that hold for group-based analysis to patient-specific models that can drive patient-specific decisions with regard to treatment choices, and predictions of outcomes of treatment. Body Composition is recognized as an important driver and risk factor for a wide variety of diseases, as well as a predictor of individual patient-specific clinical outcomes to treatment choices or surgical interventions. 3D CT images are routinely acquired in the oncological worklows and deliver accurate rendering of internal anatomy and therefore can be used opportunistically to assess the amount of skeletal muscle and adipose tissue compartments. Powerful tools of artificial intelligence such as deep learning are making it feasible now to segment the entire 3D image and generate accurate measurements of all internal anatomy. These will enable the overcoming of the severe bottleneck that existed previously, namely, the need for manual segmentation, which was prohibitive to scale to the hundreds of 2D axial slices that made up a 3D volumetric image. Automated tools such as presented here will now enable harvesting whole-body measurements from 3D CT or MRI images, leading to a new era of discovery of the drivers of various diseases based on individual tissue, organ volume, shape, and functional status. These measurements were hitherto unavailable thereby limiting the field to a very small and limited subset. These discoveries and the potential to perform individual image segmentation with high speed and accuracy are likely to lead to the incorporation of these 3D measures into individual specific treatment planning models related to nutrition, aging, chemotoxicity, surgery and survival after the onset of a major disease such as cancer.
Query-based Adversarial Attacks on Graph with Fake Nodes
Sep 27, 2021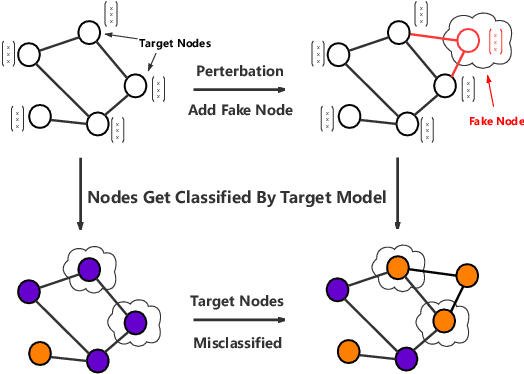
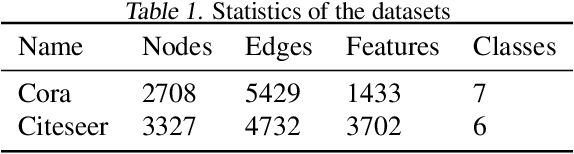
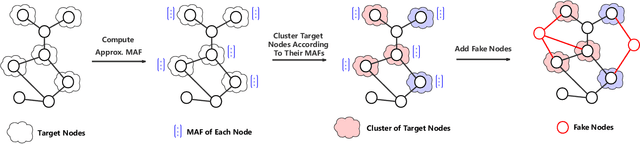
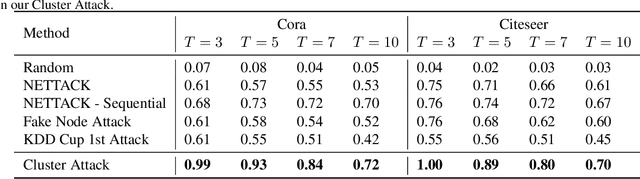
While deep neural networks have achieved great success on the graph analysis, recent works have shown that they are also vulnerable to adversarial attacks where fraudulent users can fool the model with a limited number of queries. Compared with adversarial attacks on image classification, performing adversarial attack on graphs is challenging because of the discrete and non-differential nature of a graph. To address these issues, we proposed Cluster Attack, a novel adversarial attack by introducing a set of fake nodes to the original graph which can mislead the classification on certain victim nodes. Specifically, we query the victim model for each victim node to acquire their most adversarial feature, which is related to how the fake node's feature will affect the victim nodes. We further cluster the victim nodes into several subgroups according to their most adversarial features such that we can reduce the searching space. Moreover, our attack is performed in a practical and unnoticeable manner: (1) We protect the predicted labels of nodes which we are not aimed for from being changed during attack. (2) We attack by introducing fake nodes into the original graph without changing existing links and features. (3) We attack with only partial information about the attacked graph, i.e., by leveraging the information of victim nodes along with their neighbors within $k$-hop instead of the whole graph. (4) We perform attack with a limited number of queries about the predicted scores of the model in a black-box manner, i.e., without model architecture and parameters. Extensive experiments demonstrate the effectiveness of our method in terms of the success rate of attack.
Aesthetic-Driven Image Enhancement by Adversarial Learning
Jul 02, 2018
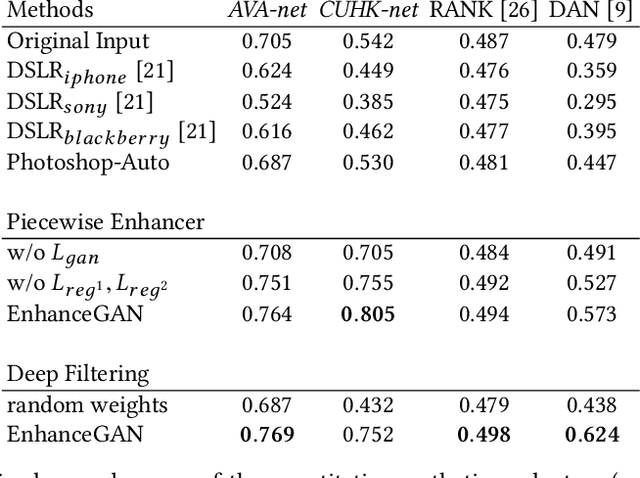
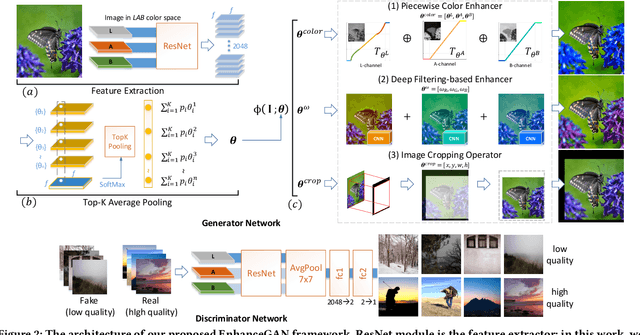
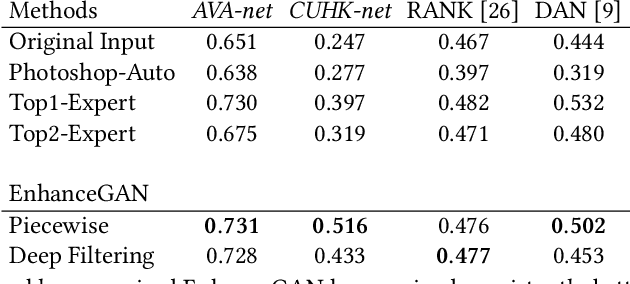
We introduce EnhanceGAN, an adversarial learning based model that performs automatic image enhancement. Traditional image enhancement frameworks typically involve training models in a fully-supervised manner, which require expensive annotations in the form of aligned image pairs. In contrast to these approaches, our proposed EnhanceGAN only requires weak supervision (binary labels on image aesthetic quality) and is able to learn enhancement operators for the task of aesthetic-based image enhancement. In particular, we show the effectiveness of a piecewise color enhancement module trained with weak supervision, and extend the proposed EnhanceGAN framework to learning a deep filtering-based aesthetic enhancer. The full differentiability of our image enhancement operators enables the training of EnhanceGAN in an end-to-end manner. We further demonstrate the capability of EnhanceGAN in learning aesthetic-based image cropping without any groundtruth cropping pairs. Our weakly-supervised EnhanceGAN reports competitive quantitative results on aesthetic-based color enhancement as well as automatic image cropping, and a user study confirms that our image enhancement results are on par with or even preferred over professional enhancement.
P2T: Pyramid Pooling Transformer for Scene Understanding
Jun 24, 2021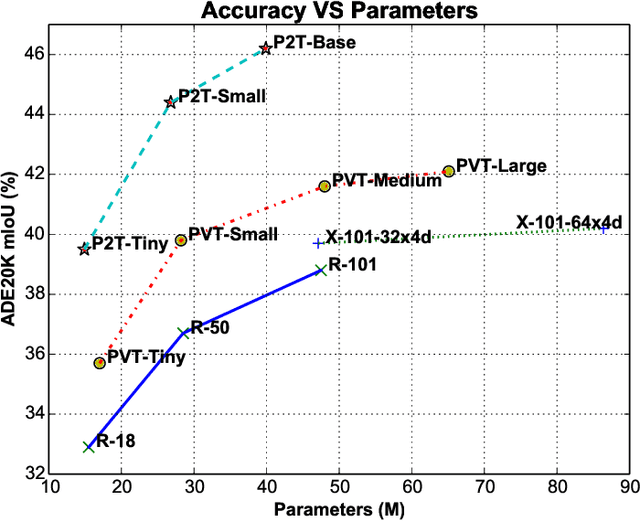
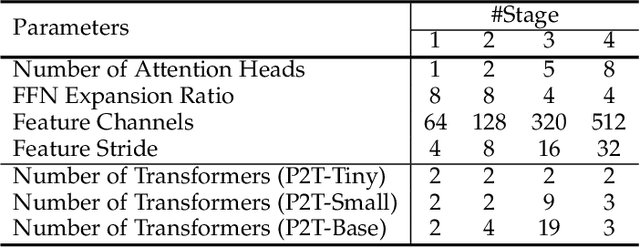
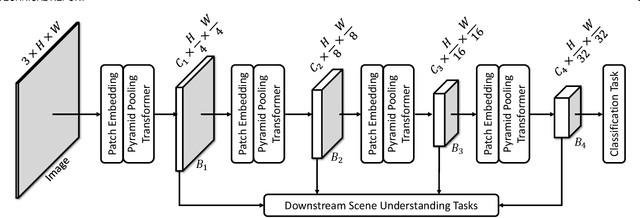
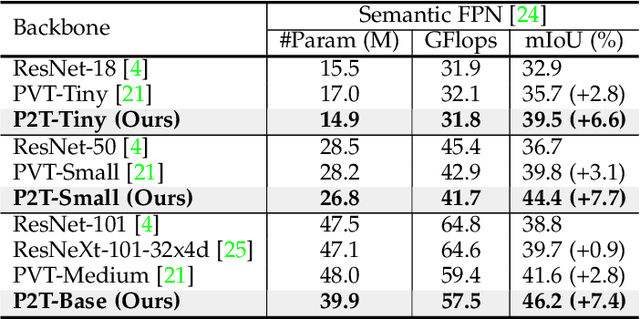
This paper jointly resolves two problems in vision transformer: i) the computation of Multi-Head Self-Attention (MHSA) has high computational/space complexity; ii) recent vision transformer networks are overly tuned for image classification, ignoring the difference between image classification (simple scenarios, more similar to NLP) and downstream scene understanding tasks (complicated scenarios, rich structural and contextual information). To this end, we note that pyramid pooling has been demonstrated to be effective in various vision tasks owing to its powerful context abstraction, and its natural property of spatial invariance is suitable to address the loss of structural information (problem ii)). Hence, we propose to adapt pyramid pooling to MHSA for alleviating its high requirement on computational resources (problem i)). In this way, this pooling-based MHSA can well address the above two problems and is thus flexible and powerful for downstream scene understanding tasks. Plugged with our pooling-based MHSA, we build a downstream-task-oriented transformer network, dubbed Pyramid Pooling Transformer (P2T). Extensive experiments demonstrate that, when applied P2T as the backbone network, it shows substantial superiority in various downstream scene understanding tasks such as semantic segmentation, object detection, instance segmentation, and visual saliency detection, compared to previous CNN- and transformer-based networks. The code will be released at https://github.com/yuhuan-wu/P2T. Note that this technical report will keep updating.
Detection and Captioning with Unseen Object Classes
Aug 13, 2021
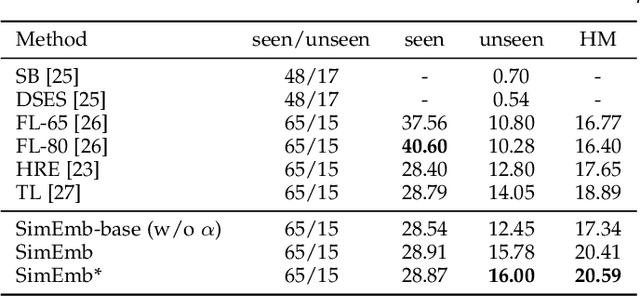
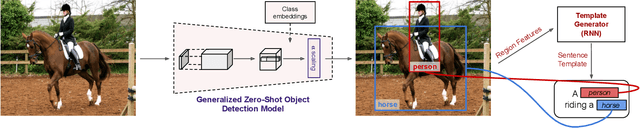
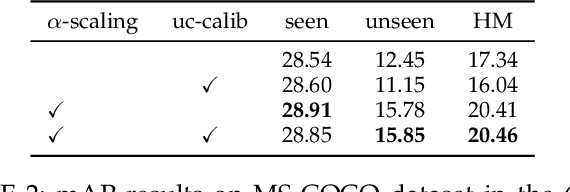
Image caption generation is one of the most challenging problems at the intersection of visual recognition and natural language modeling domains. In this work, we propose and study a practically important variant of this problem where test images may contain visual objects with no corresponding visual or textual training examples. For this problem, we propose a detection-driven approach based on a generalized zero-shot detection model and a template-based sentence generation model. In order to improve the detection component, we jointly define a class-to-class similarity based class representation and a practical score calibration mechanism. We also propose a novel evaluation metric that provides complimentary insights to the captioning outputs, by separately handling the visual and non-visual components of the captions. Our experiments show that the proposed zero-shot detection model obtains state-of-the-art performance on the MS-COCO dataset and the zero-shot captioning approach yields promising results.
Very Compact Clusters with Structural Regularization via Similarity and Connectivity
Jun 09, 2021
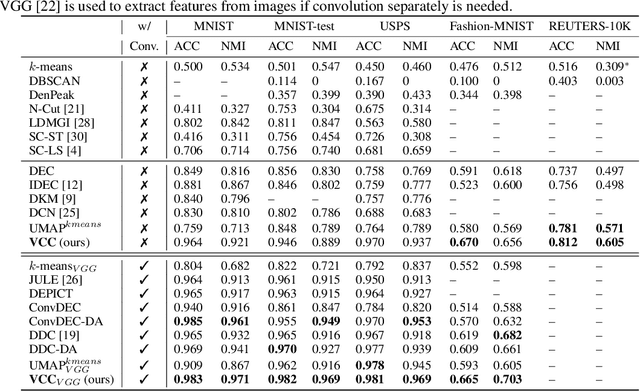
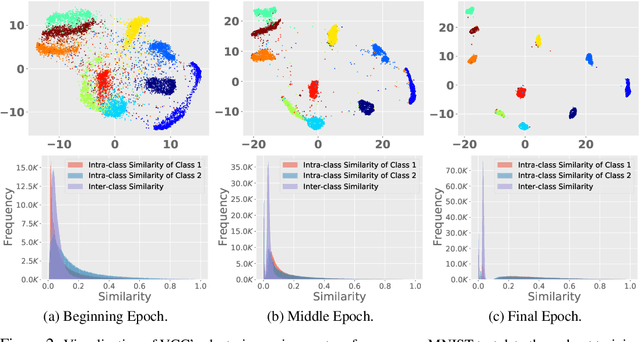
Clustering algorithms have significantly improved along with Deep Neural Networks which provide effective representation of data. Existing methods are built upon deep autoencoder and self-training process that leverages the distribution of cluster assignments of samples. However, as the fundamental objective of the autoencoder is focused on efficient data reconstruction, the learnt space may be sub-optimal for clustering. Moreover, it requires highly effective codes (i.e., representation) of data, otherwise the initial cluster centers often cause stability issues during self-training. Many state-of-the-art clustering algorithms use convolution operation to extract efficient codes but their applications are limited to image data. In this regard, we propose an end-to-end deep clustering algorithm, i.e., Very Compact Clusters (VCC), for the general datasets, which takes advantage of distributions of local relationships of samples near the boundary of clusters, so that they can be properly separated and pulled to cluster centers to form compact clusters. Experimental results on various datasets illustrate that our proposed approach achieves better clustering performance over most of the state-of-the-art clustering methods, and the data embeddings learned by VCC without convolution for image data are even comparable with specialized convolutional methods.
Unsupervised Person Image Generation with Semantic Parsing Transformation
Apr 18, 2019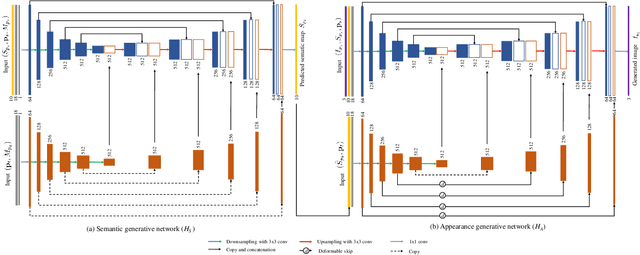

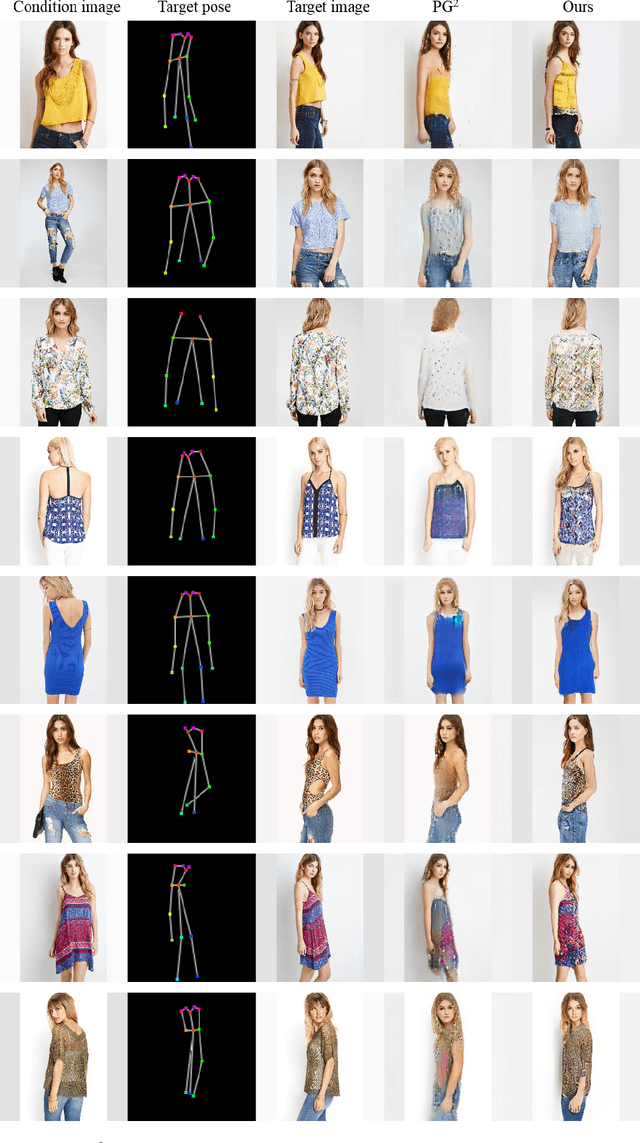
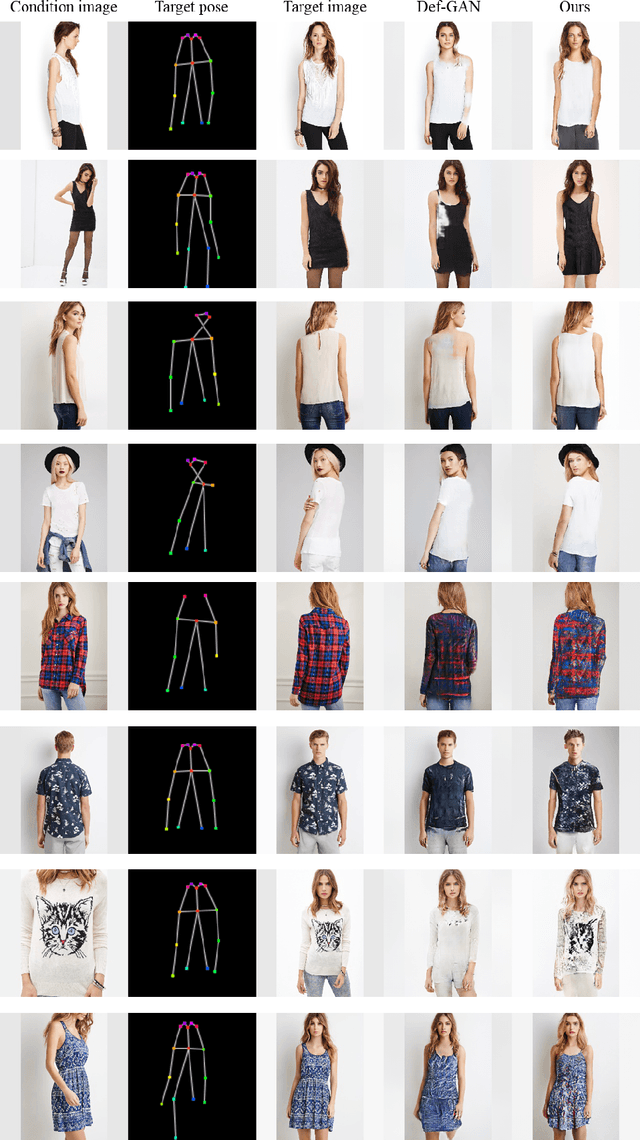
In this paper, we address unsupervised pose-guided person image generation, which is known challenging due to non-rigid deformation. Unlike previous methods learning a rock-hard direct mapping between human bodies, we propose a new pathway to decompose the hard mapping into two more accessible subtasks, namely, semantic parsing transformation and appearance generation. Firstly, a semantic generative network is proposed to transform between semantic parsing maps, in order to simplify the non-rigid deformation learning. Secondly, an appearance generative network learns to synthesize semantic-aware textures. Thirdly, we demonstrate that training our framework in an end-to-end manner further refines the semantic maps and final results accordingly. Our method is generalizable to other semantic-aware person image generation tasks, eg, clothing texture transfer and controlled image manipulation. Experimental results demonstrate the superiority of our method on DeepFashion and Market-1501 datasets, especially in keeping the clothing attributes and better body shapes.
Multi-Path Learnable Wavelet Neural Network for Image Classification
Aug 26, 2019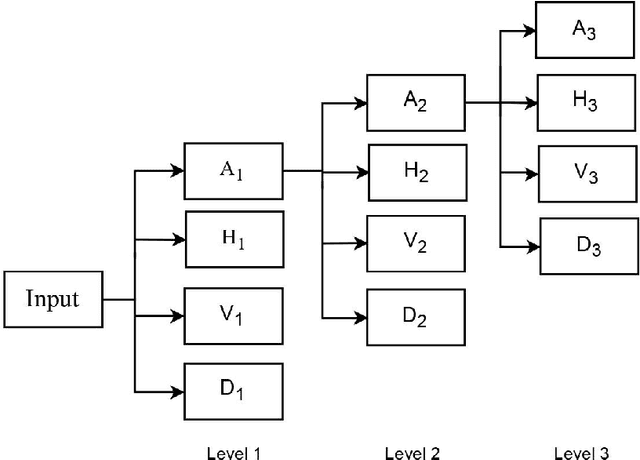
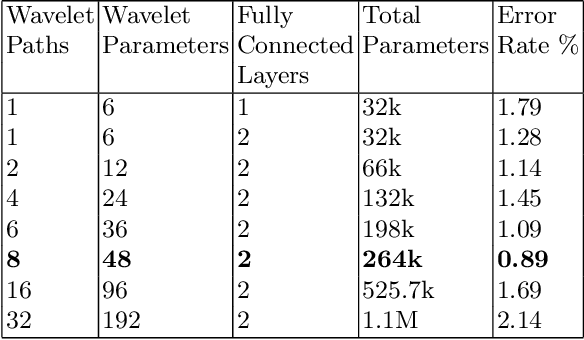
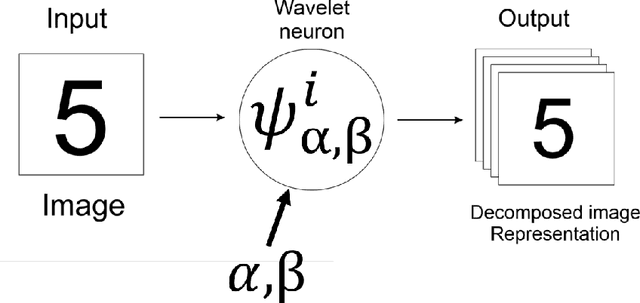
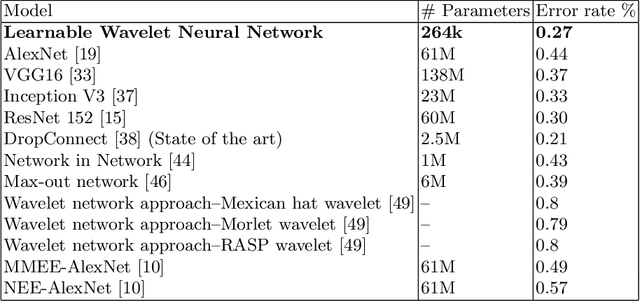
Despite the remarkable success of deep learning in pattern recognition, deep network models face the problem of training a large number of parameters. In this paper, we propose and evaluate a novel multi-path wavelet neural network architecture for image classification with far less number of trainable parameters. The model architecture consists of a multi-path layout with several levels of wavelet decompositions performed in parallel followed by fully connected layers. These decomposition operations comprise wavelet neurons with learnable parameters, which are updated during the training phase using the back-propagation algorithm. We evaluate the performance of the introduced network using common image datasets without data augmentation except for SVHN and compare the results with influential deep learning models. Our findings support the possibility of reducing the number of parameters significantly in deep neural networks without compromising its accuracy.