 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnsupervised Person Image Generation with Semantic Parsing Transformation
Paper and Code
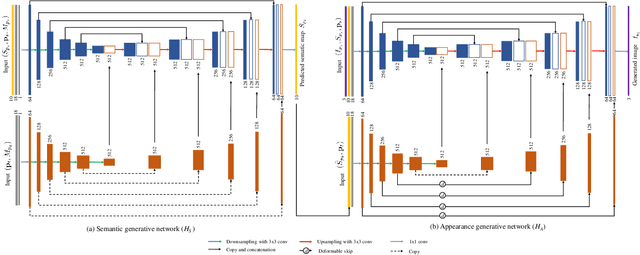

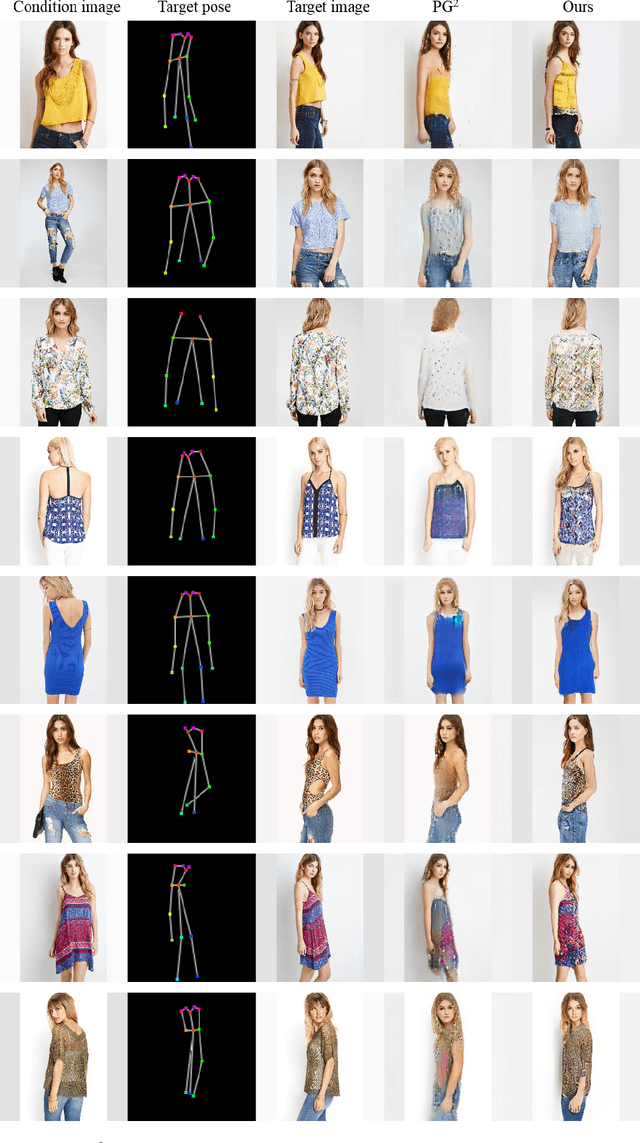
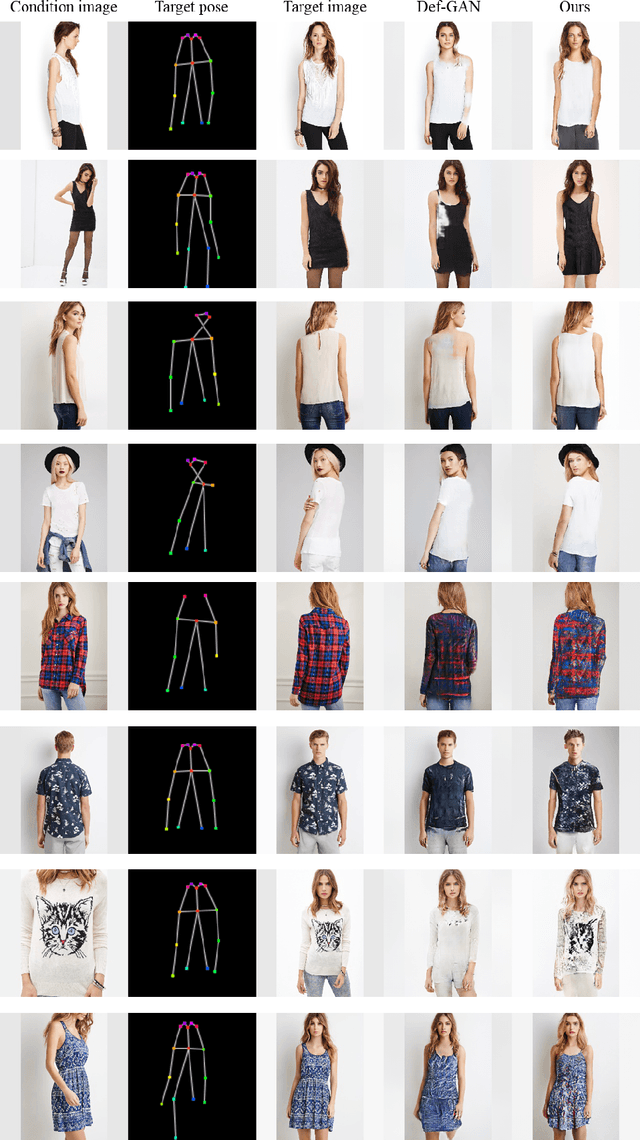
In this paper, we address unsupervised pose-guided person image generation, which is known challenging due to non-rigid deformation. Unlike previous methods learning a rock-hard direct mapping between human bodies, we propose a new pathway to decompose the hard mapping into two more accessible subtasks, namely, semantic parsing transformation and appearance generation. Firstly, a semantic generative network is proposed to transform between semantic parsing maps, in order to simplify the non-rigid deformation learning. Secondly, an appearance generative network learns to synthesize semantic-aware textures. Thirdly, we demonstrate that training our framework in an end-to-end manner further refines the semantic maps and final results accordingly. Our method is generalizable to other semantic-aware person image generation tasks, eg, clothing texture transfer and controlled image manipulation. Experimental results demonstrate the superiority of our method on DeepFashion and Market-1501 datasets, especially in keeping the clothing attributes and better body shapes.