 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Multi-Scale Hypergraph for High-Order Brain Connectivity Analysis
Jun 02, 2026Understanding complex interactions between brain regions is critical for early neurodegenerative disease classification such as Alzheimer's Disease (AD) and Parkinson's Disease (PD). While graph-based models are widely used to analyze brain networks, most existing approaches primarily focus on pairwise interactions between directly connected nodes, limiting their ability to capture higher-order dependencies across multiple regions. Although hypergraph-based methods have been proposed to model higher-order relations, many rely on predefined hyperedges or restrict learning to hyperedge weights, reducing flexibility and limiting their capacity to capture multi-resolution structural patterns. In this regard, we introduce an adaptive multi-scale hyperedge learning framework, i.e., MuHL, which constructs hierarchical node features and dynamically learns high-order interactions through continuous hyperedge construction over multi-resolution graph signals. Extensive experiments on multiple brain network benchmarks demonstrate that MuHL consistently improves disease classification performance across different stages, and further identifies key regions of interest (ROIs) and their group-wise interactions from the learned hyperedges that are associated with disease progression, highlighting its potential as a powerful tool for brain network analysis in neurodegenerative disorders.
Multi-Modal Graph Neural Network with Transformer-Guided Adaptive Diffusion for Preclinical Alzheimer Classification
Jun 02, 2026The graphical representation of the brain offers critical insights into diagnosing and prognosing neurodegenerative disease via relationships between regions of interest (ROIs). Despite recent emergence of various Graph Neural Networks (GNNs) to effectively capture the relational information, there remain inherent limitations in interpreting the brain networks. Specifically, convolutional approaches ineffectively aggregate information from distant neighborhoods, while attention-based methods exhibit deficiencies in capturing node-centric information, particularly in retaining critical characteristics from pivotal nodes. These shortcomings reveal challenges for identifying disease-specific variation from diverse features from different modalities. In this regard, we propose an integrated framework guiding diffusion process at each node by a downstream transformer where both short- and long-range properties of graphs are aggregated via diffusion-kernel and multi-head attention respectively. We demonstrate the superiority of our model by improving performance of pre-clinical Alzheimer's disease (AD) classification with various modalities. Also, our model adeptly identifies key ROIs that are closely associated with the preclinical stages of AD, marking a significant potential for early diagnosis and prevision of the disease.
Convex Distance Operator Transport: A Convex and Geometry-Preserving Formulation
Jun 01, 2026We introduce Convex Distance Operator Transport (CDOT), the first convex optimal transport framework that aligns distributions across heterogeneous domains by jointly preserving feature correspondence and intrinsic geometric structure. Specifically, CDOT employs an operator-based regularization that aligns aggregated distance structures by introducing distance and conditional expectation operators. Consequently, the proposed regularization improves the robustness to local geometric variations. We further prove that the resulting CDOT discrepancy is a valid pseudometric on the space of attributed compact metric-measure spaces. In addition, we characterize the relationship between CDOT and Gromov--Wasserstein (GW) through a new notion of dispersion gap, formally elucidating the geometric source of non-convexity in GW compared to the convexity of CDOT. In the finite-sample regime, we derive a non-asymptotic risk bound decomposed into optimization and statistical errors, establishing risk consistency under a globally convergent Frank--Wolfe algorithm. Experiments on synthetic point clouds, brain connectomes, and graph classification benchmarks demonstrate better performance over existing methods, with stable and reliable behavior in practice.
PR-MaGIC: Prompt Refinement Via Mask Decoder Gradient Flow For In-Context Segmentation
Apr 13, 2026Visual Foundation Models (VFMs) such as the Segment Anything Model (SAM) have significantly advanced broad use of image segmentation. However, SAM and its variants necessitate substantial manual effort for prompt generation and additional training for specific applications. Recent approaches address these limitations by integrating SAM into in-context (one/few shot) segmentation, enabling auto-prompting through semantic alignment between query and support images. Despite these efforts, they still generate sub-optimal prompts that degrade segmentation quality due to visual inconsistencies between support and query images. To tackle this limitation, we introduce PR-MaGIC (Prompt Refinement via Mask Decoder Gradient Flow for In-Context Segmentation), a training-free test-time framework that refines prompts via gradient flow derived from SAM's mask decoder. PR-MaGIC seamlessly integrates into in-context segmentation frameworks, being theoretically grounded yet practically stabilized through a simple top-1 selection strategy that ensures robust performance across samples. Extensive evaluations demonstrate that PR-MaGIC consistently improves segmentation quality across various benchmarks, effectively mitigating inadequate prompts without requiring additional training or architectural modifications.
Targeted Unlearning Using Perturbed Sign Gradient Methods With Applications On Medical Images
May 28, 2025Machine unlearning aims to remove the influence of specific training samples from a trained model without full retraining. While prior work has largely focused on privacy-motivated settings, we recast unlearning as a general-purpose tool for post-deployment model revision. Specifically, we focus on utilizing unlearning in clinical contexts where data shifts, device deprecation, and policy changes are common. To this end, we propose a bilevel optimization formulation of boundary-based unlearning that can be solved using iterative algorithms. We provide convergence guarantees when first-order algorithms are used to unlearn. Our method introduces tunable loss design for controlling the forgetting-retention tradeoff and supports novel model composition strategies that merge the strengths of distinct unlearning runs. Across benchmark and real-world clinical imaging datasets, our approach outperforms baselines on both forgetting and retention metrics, including scenarios involving imaging devices and anatomical outliers. This work establishes machine unlearning as a modular, practical alternative to retraining for real-world model maintenance in clinical applications.
Improving Sound Source Localization with Joint Slot Attention on Image and Audio
Apr 21, 2025



Sound source localization (SSL) is the task of locating the source of sound within an image. Due to the lack of localization labels, the de facto standard in SSL has been to represent an image and audio as a single embedding vector each, and use them to learn SSL via contrastive learning. To this end, previous work samples one of local image features as the image embedding and aggregates all local audio features to obtain the audio embedding, which is far from optimal due to the presence of noise and background irrelevant to the actual target in the input. We present a novel SSL method that addresses this chronic issue by joint slot attention on image and audio. To be specific, two slots competitively attend image and audio features to decompose them into target and off-target representations, and only target representations of image and audio are used for contrastive learning. Also, we introduce cross-modal attention matching to further align local features of image and audio. Our method achieved the best in almost all settings on three public benchmarks for SSL, and substantially outperformed all the prior work in cross-modal retrieval.
OCL: Ordinal Contrastive Learning for Imputating Features with Progressive Labels
Mar 03, 2025Accurately discriminating progressive stages of Alzheimer's Disease (AD) is crucial for early diagnosis and prevention. It often involves multiple imaging modalities to understand the complex pathology of AD, however, acquiring a complete set of images is challenging due to high cost and burden for subjects. In the end, missing data become inevitable which lead to limited sample-size and decrease in precision in downstream analyses. To tackle this challenge, we introduce a holistic imaging feature imputation method that enables to leverage diverse imaging features while retaining all subjects. The proposed method comprises two networks: 1) An encoder to extract modality-independent embeddings and 2) A decoder to reconstruct the original measures conditioned on their imaging modalities. The encoder includes a novel {\em ordinal contrastive loss}, which aligns samples in the embedding space according to the progression of AD. We also maximize modality-wise coherence of embeddings within each subject, in conjunction with domain adversarial training algorithms, to further enhance alignment between different imaging modalities. The proposed method promotes our holistic imaging feature imputation across various modalities in the shared embedding space. In the experiments, we show that our networks deliver favorable results for statistical analysis and classification against imputation baselines with Alzheimer's Disease Neuroimaging Initiative (ADNI) study.
Modality-Agnostic Style Transfer for Holistic Feature Imputation
Mar 03, 2025



Characterizing a preclinical stage of Alzheimer's Disease (AD) via single imaging is difficult as its early symptoms are quite subtle. Therefore, many neuroimaging studies are curated with various imaging modalities, e.g., MRI and PET, however, it is often challenging to acquire all of them from all subjects and missing data become inevitable. In this regards, in this paper, we propose a framework that generates unobserved imaging measures for specific subjects using their existing measures, thereby reducing the need for additional examinations. Our framework transfers modality-specific style while preserving AD-specific content. This is done by domain adversarial training that preserves modality-agnostic but AD-specific information, while a generative adversarial network adds an indistinguishable modality-specific style. Our proposed framework is evaluated on the Alzheimer's Disease Neuroimaging Initiative (ADNI) study and compared with other imputation methods in terms of generated data quality. Small average Cohen's $d$ $< 0.19$ between our generated measures and real ones suggests that the synthetic data are practically usable regardless of their modality type.
Learning Covariance-Based Multi-Scale Representation of Neuroimaging Measures for Alzheimer Classification
Mar 03, 2025



Stacking excessive layers in DNN results in highly underdetermined system when training samples are limited, which is very common in medical applications. In this regard, we present a framework capable of deriving an efficient high-dimensional space with reasonable increase in model size. This is done by utilizing a transform (i.e., convolution) that leverages scale-space theory with covariance structure. The overall model trains on this transform together with a downstream classifier (i.e., Fully Connected layer) to capture the optimal multi-scale representation of the original data which corresponds to task-specific components in a dual space. Experiments on neuroimaging measures from Alzheimer's Disease Neuroimaging Initiative (ADNI) study show that our model performs better and converges faster than conventional models even when the model size is significantly reduced. The trained model is made interpretable using gradient information over the multi-scale transform to delineate personalized AD-specific regions in the brain.
Machine Learning on Dynamic Functional Connectivity: Promise, Pitfalls, and Interpretations
Sep 17, 2024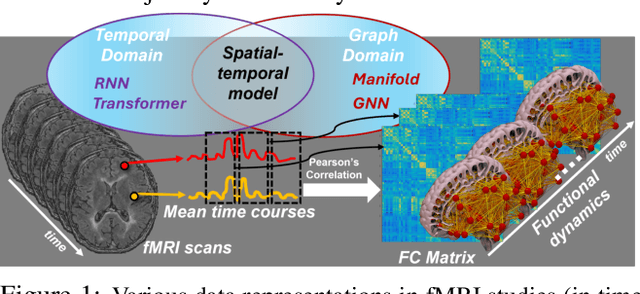
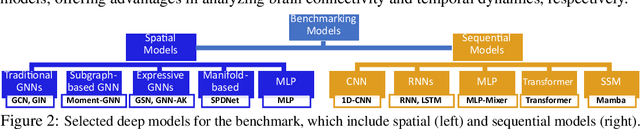


An unprecedented amount of existing functional Magnetic Resonance Imaging (fMRI) data provides a new opportunity to understand the relationship between functional fluctuation and human cognition/behavior using a data-driven approach. To that end, tremendous efforts have been made in machine learning to predict cognitive states from evolving volumetric images of blood-oxygen-level-dependent (BOLD) signals. Due to the complex nature of brain function, however, the evaluation on learning performance and discoveries are not often consistent across current state-of-the-arts (SOTA). By capitalizing on large-scale existing neuroimaging data (34,887 data samples from six public databases), we seek to establish a well-founded empirical guideline for designing deep models for functional neuroimages by linking the methodology underpinning with knowledge from the neuroscience domain. Specifically, we put the spotlight on (1) What is the current SOTA performance in cognitive task recognition and disease diagnosis using fMRI? (2) What are the limitations of current deep models? and (3) What is the general guideline for selecting the suitable machine learning backbone for new neuroimaging applications? We have conducted a comprehensive evaluation and statistical analysis, in various settings, to answer the above outstanding questions.