 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Vision Transformers For Weeds and Crops Classification Of High Resolution UAV Images
Sep 06, 2021

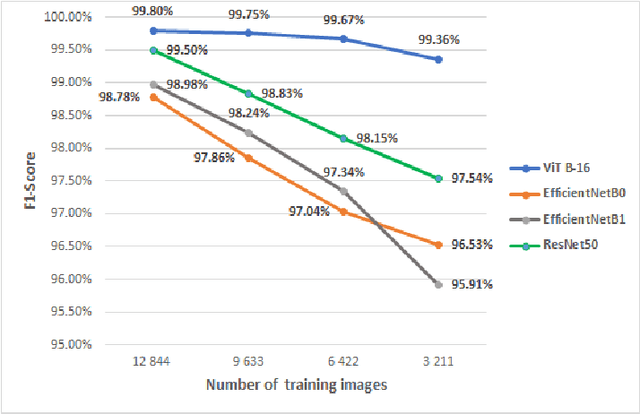
Crop and weed monitoring is an important challenge for agriculture and food production nowadays. Thanks to recent advances in data acquisition and computation technologies, agriculture is evolving to a more smart and precision farming to meet with the high yield and high quality crop production. Classification and recognition in Unmanned Aerial Vehicles (UAV) images are important phases for crop monitoring. Advances in deep learning models relying on Convolutional Neural Network (CNN) have achieved high performances in image classification in the agricultural domain. Despite the success of this architecture, CNN still faces many challenges such as high computation cost, the need of large labelled datasets, ... Natural language processing's transformer architecture can be an alternative approach to deal with CNN's limitations. Making use of the self-attention paradigm, Vision Transformer (ViT) models can achieve competitive or better results without applying any convolution operations. In this paper, we adopt the self-attention mechanism via the ViT models for plant classification of weeds and crops: red beet, off-type beet (green leaves), parsley and spinach. Our experiments show that with small set of labelled training data, ViT models perform better compared to state-of-the-art CNN-based models EfficientNet and ResNet, with a top accuracy of 99.8\% achieved by the ViT model.
Improved Residual Networks for Image and Video Recognition
Apr 10, 2020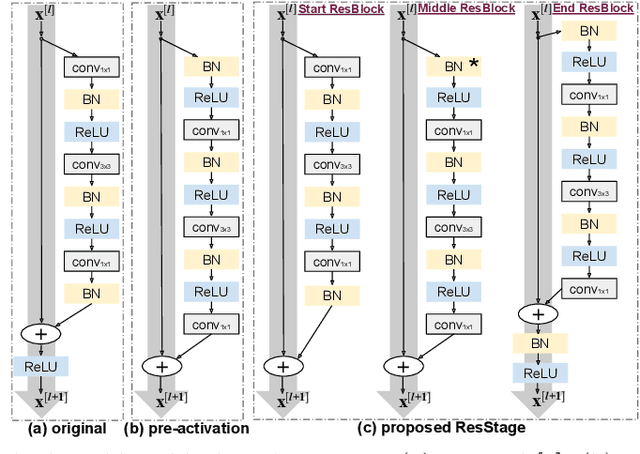
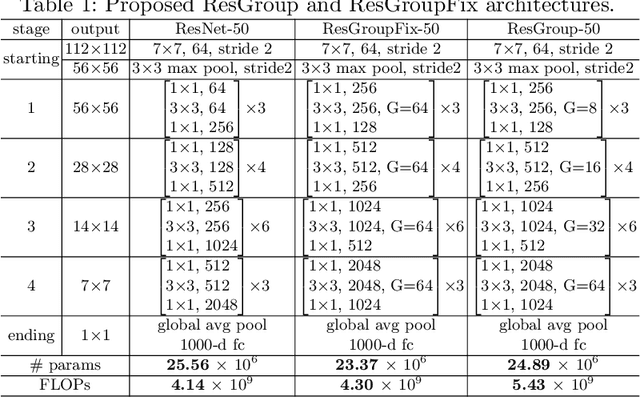
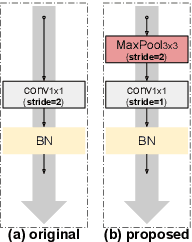
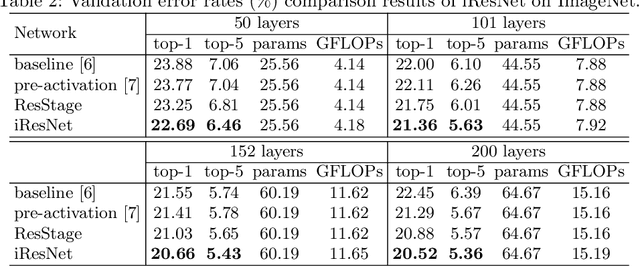
Residual networks (ResNets) represent a powerful type of convolutional neural network (CNN) architecture, widely adopted and used in various tasks. In this work we propose an improved version of ResNets. Our proposed improvements address all three main components of a ResNet: the flow of information through the network layers, the residual building block, and the projection shortcut. We are able to show consistent improvements in accuracy and learning convergence over the baseline. For instance, on ImageNet dataset, using the ResNet with 50 layers, for top-1 accuracy we can report a 1.19% improvement over the baseline in one setting and around 2% boost in another. Importantly, these improvements are obtained without increasing the model complexity. Our proposed approach allows us to train extremely deep networks, while the baseline shows severe optimization issues. We report results on three tasks over six datasets: image classification (ImageNet, CIFAR-10 and CIFAR-100), object detection (COCO) and video action recognition (Kinetics-400 and Something-Something-v2). In the deep learning era, we establish a new milestone for the depth of a CNN. We successfully train a 404-layer deep CNN on the ImageNet dataset and a 3002-layer network on CIFAR-10 and CIFAR-100, while the baseline is not able to converge at such extreme depths. Code is available at: https://github.com/iduta/iresnet
HorNet: A Hierarchical Offshoot Recurrent Network for Improving Person Re-ID via Image Captioning
Aug 14, 2019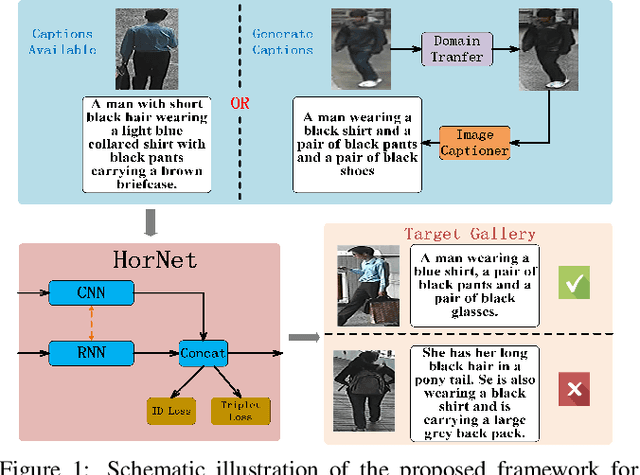
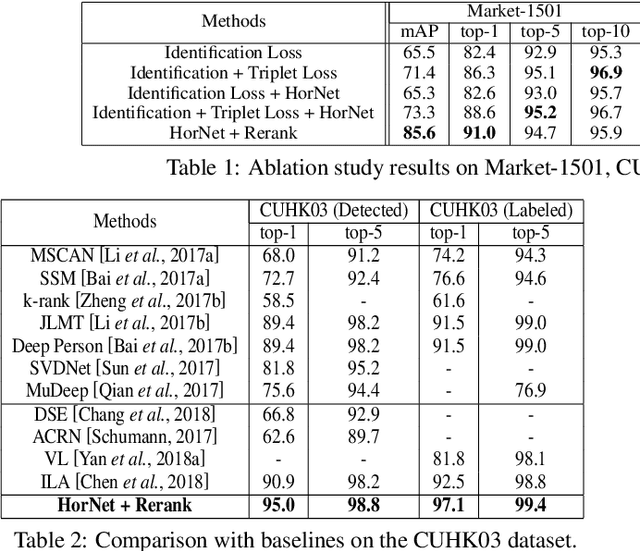
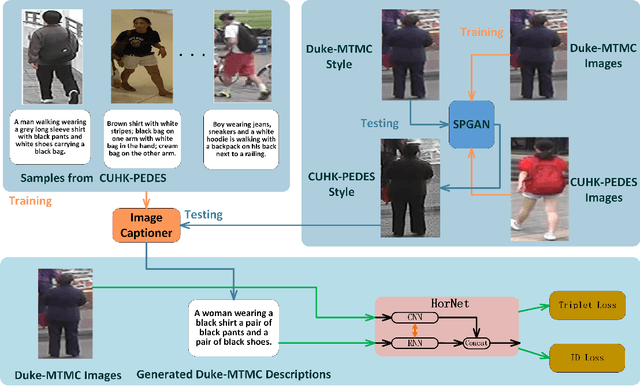
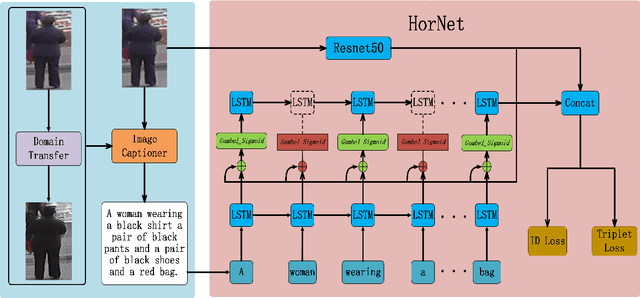
Person re-identification (re-ID) aims to recognize a person-of-interest across different cameras with notable appearance variance. Existing research works focused on the capability and robustness of visual representation. In this paper, instead, we propose a novel hierarchical offshoot recurrent network (HorNet) for improving person re-ID via image captioning. Image captions are semantically richer and more consistent than visual attributes, which could significantly alleviate the variance. We use the similarity preserving generative adversarial network (SPGAN) and an image captioner to fulfill domain transfer and language descriptions generation. Then the proposed HorNet can learn the visual and language representation from both the images and captions jointly, and thus enhance the performance of person re-ID. Extensive experiments are conducted on several benchmark datasets with or without image captions, i.e., CUHK03, Market-1501, and Duke-MTMC, demonstrating the superiority of the proposed method. Our method can generate and extract meaningful image captions while achieving state-of-the-art performance.
Applying Tensor Decomposition to image for Robustness against Adversarial Attack
Mar 05, 2020
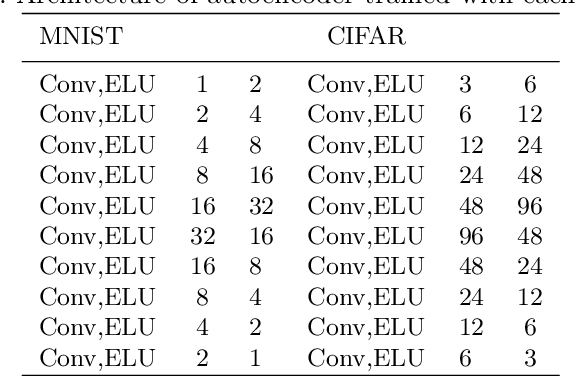
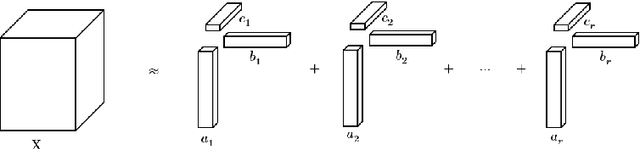
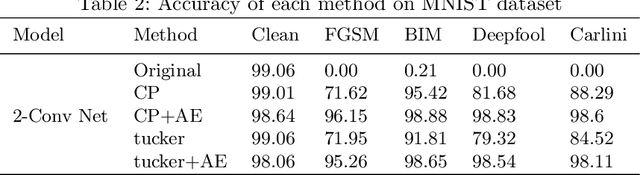
Nowadays the deep learning technology is growing faster and shows dramatic performance in computer vision areas. However, it turns out a deep learning based model is highly vulnerable to some small perturbation called an adversarial attack. It can easily fool the deep learning model by adding small perturbations. On the other hand, tensor decomposition method widely uses for compressing the tensor data, including data matrix, image, etc. In this paper, we suggest combining tensor decomposition for defending the model against adversarial example. We verify this idea is simple and effective to resist adversarial attack. In addition, this method rarely degrades the original performance of clean data. We experiment on MNIST, CIFAR10 and ImageNet data and show our method robust on state-of-the-art attack methods.
Prediction of MRI Hardware Failures based on Image Features using Time Series Classification
Jan 05, 2020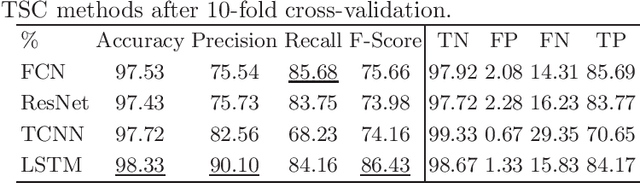
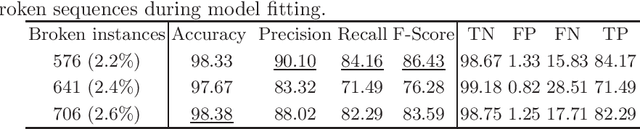
Already before systems malfunction one has to know if hardware components will fail in near future in order to counteract in time. Thus, unplanned downtime is ought to be avoided. In medical imaging, maximizing the system's uptime is crucial for patients' health and healthcare provider's daily business. We aim to predict failures of Head/Neck coils used in Magnetic Resonance Imaging (MRI) by training a statistical model on sequential data collected over time. As image features depend on the coil's condition, their deviations from the normal range already hint to future failure. Thus, we used image features and their variation over time to predict coil damage. After comparison of different time series classification methods we found Long Short Term Memorys (LSTMs) to achieve the highest F-score of 86.43% and to tell with 98.33% accuracy if hardware should be replaced.
Parser-Free Virtual Try-on via Distilling Appearance Flows
Mar 09, 2021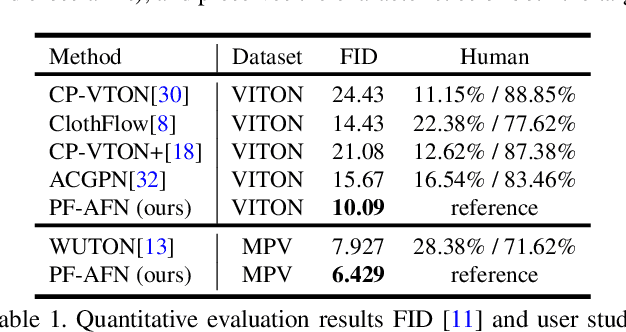
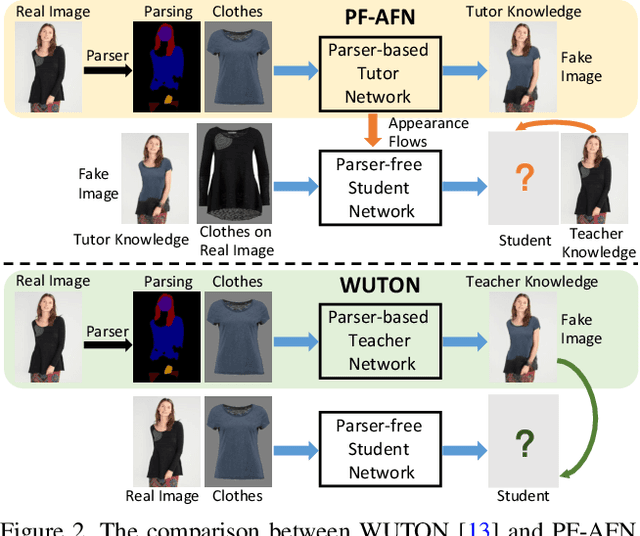

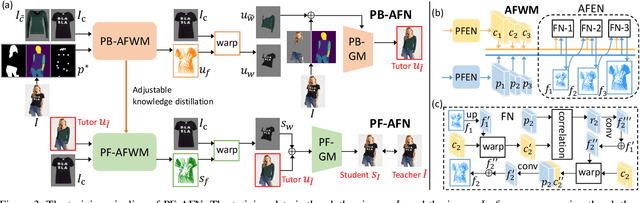
Image virtual try-on aims to fit a garment image (target clothes) to a person image. Prior methods are heavily based on human parsing. However, slightly-wrong segmentation results would lead to unrealistic try-on images with large artifacts. Inaccurate parsing misleads parser-based methods to produce visually unrealistic results where artifacts usually occur. A recent pioneering work employed knowledge distillation to reduce the dependency of human parsing, where the try-on images produced by a parser-based method are used as supervisions to train a "student" network without relying on segmentation, making the student mimic the try-on ability of the parser-based model. However, the image quality of the student is bounded by the parser-based model. To address this problem, we propose a novel approach, "teacher-tutor-student" knowledge distillation, which is able to produce highly photo-realistic images without human parsing, possessing several appealing advantages compared to prior arts. (1) Unlike existing work, our approach treats the fake images produced by the parser-based method as "tutor knowledge", where the artifacts can be corrected by real "teacher knowledge", which is extracted from the real person images in a self-supervised way. (2) Other than using real images as supervisions, we formulate knowledge distillation in the try-on problem as distilling the appearance flows between the person image and the garment image, enabling us to find accurate dense correspondences between them to produce high-quality results. (3) Extensive evaluations show large superiority of our method (see Fig. 1).
Optimal Target Shape for LiDAR Pose Estimation
Sep 06, 2021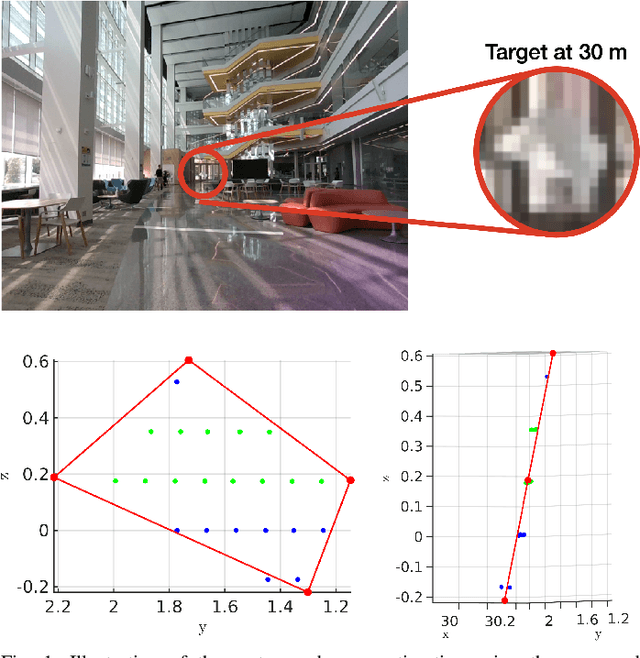
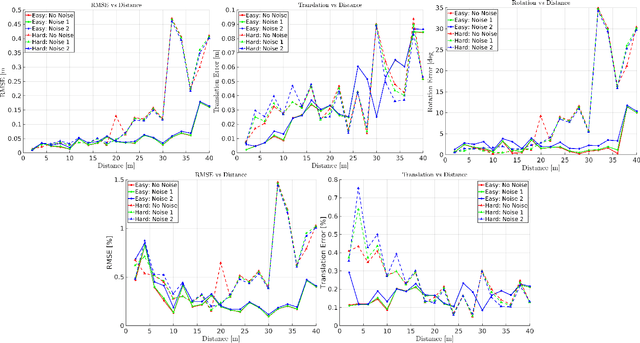

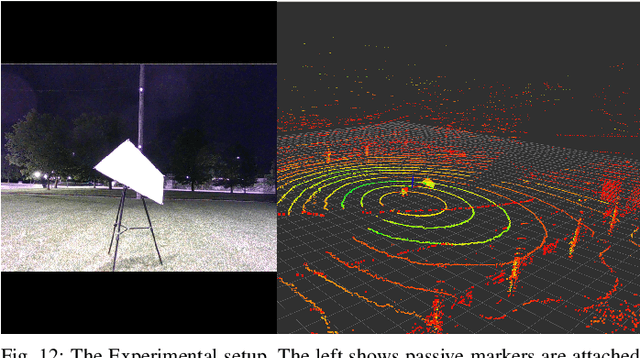
Targets are essential in problems such as object tracking in cluttered or textureless environments, camera (and multi-sensor) calibration tasks, and simultaneous localization and mapping (SLAM). Target shapes for these tasks typically are symmetric (square, rectangular, or circular) and work well for structured, dense sensor data such as pixel arrays (i.e., image). However, symmetric shapes lead to pose ambiguity when using sparse sensor data such as LiDAR point clouds and suffer from the quantization uncertainty of the LiDAR. This paper introduces the concept of optimizing target shape to remove pose ambiguity for LiDAR point clouds. A target is designed to induce large gradients at edge points under rotation and translation relative to the LiDAR to ameliorate the quantization uncertainty associated with point cloud sparseness. Moreover, given a target shape, we present a means that leverages the target's geometry to estimate the target's vertices while globally estimating the pose. Both the simulation and the experimental results (verified by a motion capture system) confirm that by using the optimal shape and the global solver, we achieve centimeter error in translation and a few degrees in rotation even when a partially illuminated target is placed 30 meters away. All the implementations and datasets are available at https://github.com/UMich-BipedLab/optimal_shape_global_pose_estimation.
Relaxing Local Robustness
Jun 11, 2021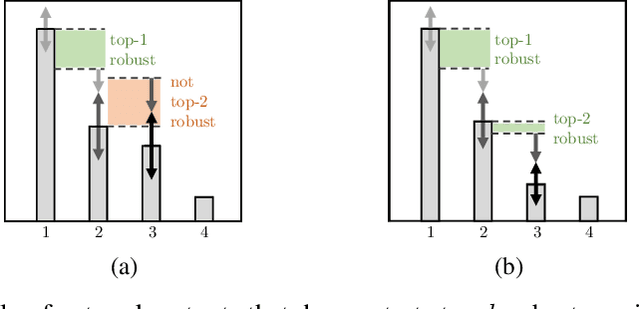
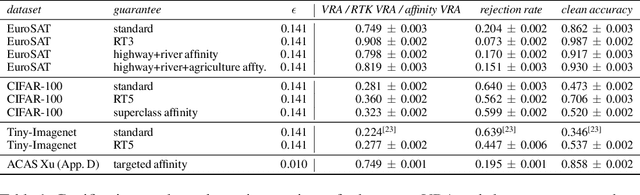


Certifiable local robustness, which rigorously precludes small-norm adversarial examples, has received significant attention as a means of addressing security concerns in deep learning. However, for some classification problems, local robustness is not a natural objective, even in the presence of adversaries; for example, if an image contains two classes of subjects, the correct label for the image may be considered arbitrary between the two, and thus enforcing strict separation between them is unnecessary. In this work, we introduce two relaxed safety properties for classifiers that address this observation: (1) relaxed top-k robustness, which serves as the analogue of top-k accuracy; and (2) affinity robustness, which specifies which sets of labels must be separated by a robustness margin, and which can be $\epsilon$-close in $\ell_p$ space. We show how to construct models that can be efficiently certified against each relaxed robustness property, and trained with very little overhead relative to standard gradient descent. Finally, we demonstrate experimentally that these relaxed variants of robustness are well-suited to several significant classification problems, leading to lower rejection rates and higher certified accuracies than can be obtained when certifying "standard" local robustness.
Deep 3D Mask Volume for View Synthesis of Dynamic Scenes
Aug 30, 2021
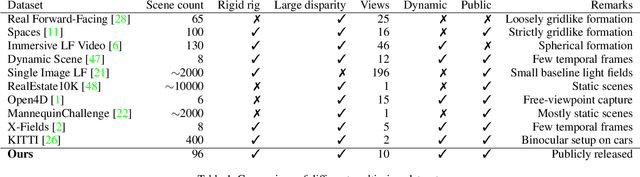


Image view synthesis has seen great success in reconstructing photorealistic visuals, thanks to deep learning and various novel representations. The next key step in immersive virtual experiences is view synthesis of dynamic scenes. However, several challenges exist due to the lack of high-quality training datasets, and the additional time dimension for videos of dynamic scenes. To address this issue, we introduce a multi-view video dataset, captured with a custom 10-camera rig in 120FPS. The dataset contains 96 high-quality scenes showing various visual effects and human interactions in outdoor scenes. We develop a new algorithm, Deep 3D Mask Volume, which enables temporally-stable view extrapolation from binocular videos of dynamic scenes, captured by static cameras. Our algorithm addresses the temporal inconsistency of disocclusions by identifying the error-prone areas with a 3D mask volume, and replaces them with static background observed throughout the video. Our method enables manipulation in 3D space as opposed to simple 2D masks, We demonstrate better temporal stability than frame-by-frame static view synthesis methods, or those that use 2D masks. The resulting view synthesis videos show minimal flickering artifacts and allow for larger translational movements.
GAN Based Image Deblurring Using Dark Channel Prior
Feb 28, 2019
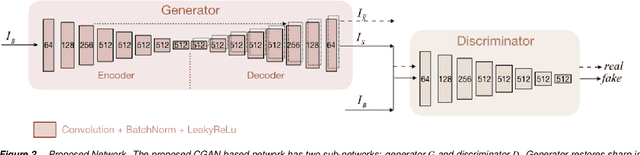

A conditional general adversarial network (GAN) is proposed for image deblurring problem. It is tailored for image deblurring instead of just applying GAN on the deblurring problem. Motivated by that, dark channel prior is carefully picked to be incorporated into the loss function for network training. To make it more compatible with neuron networks, its original indifferentiable form is discarded and L2 norm is adopted instead. On both synthetic datasets and noisy natural images, the proposed network shows improved deblurring performance and robustness to image noise qualitatively and quantitatively. Additionally, compared to the existing end-to-end deblurring networks, our network structure is light-weight, which ensures less training and testing time.