 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Excavating the Potential Capacity of Self-Supervised Monocular Depth Estimation
Sep 26, 2021

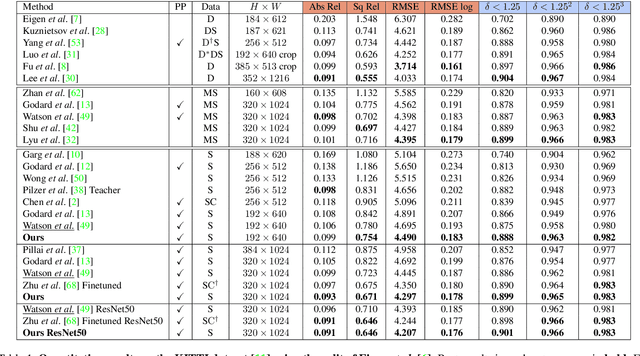
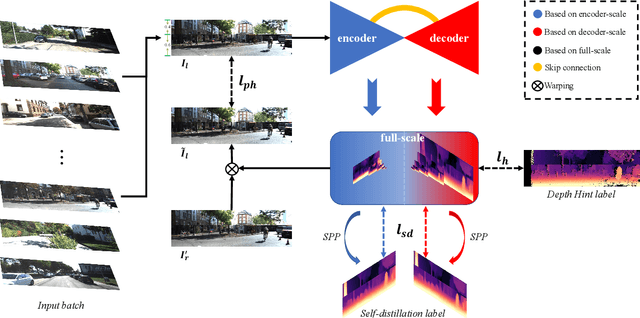
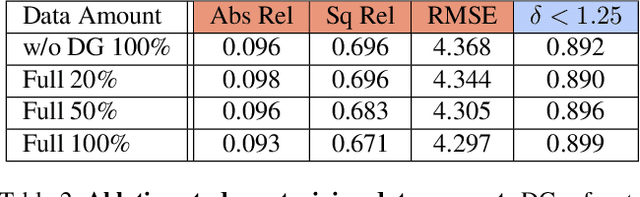
Self-supervised methods play an increasingly important role in monocular depth estimation due to their great potential and low annotation cost. To close the gap with supervised methods, recent works take advantage of extra constraints, e.g., semantic segmentation. However, these methods will inevitably increase the burden on the model. In this paper, we show theoretical and empirical evidence that the potential capacity of self-supervised monocular depth estimation can be excavated without increasing this cost. In particular, we propose (1) a novel data augmentation approach called data grafting, which forces the model to explore more cues to infer depth besides the vertical image position, (2) an exploratory self-distillation loss, which is supervised by the self-distillation label generated by our new post-processing method - selective post-processing, and (3) the full-scale network, designed to endow the encoder with the specialization of depth estimation task and enhance the representational power of the model. Extensive experiments show that our contributions can bring significant performance improvement to the baseline with even less computational overhead, and our model, named EPCDepth, surpasses the previous state-of-the-art methods even those supervised by additional constraints.
Venc Design and Velocity Estimation for Phase Contrast MRI
Sep 26, 2021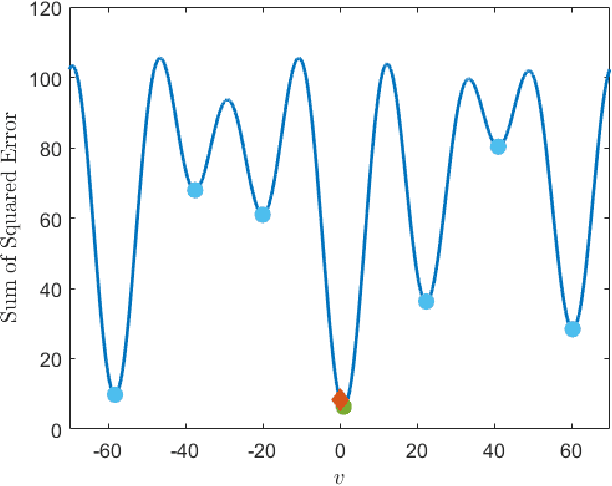
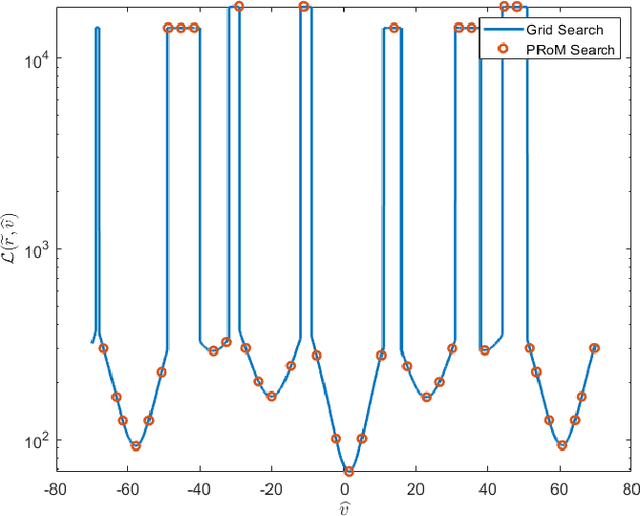
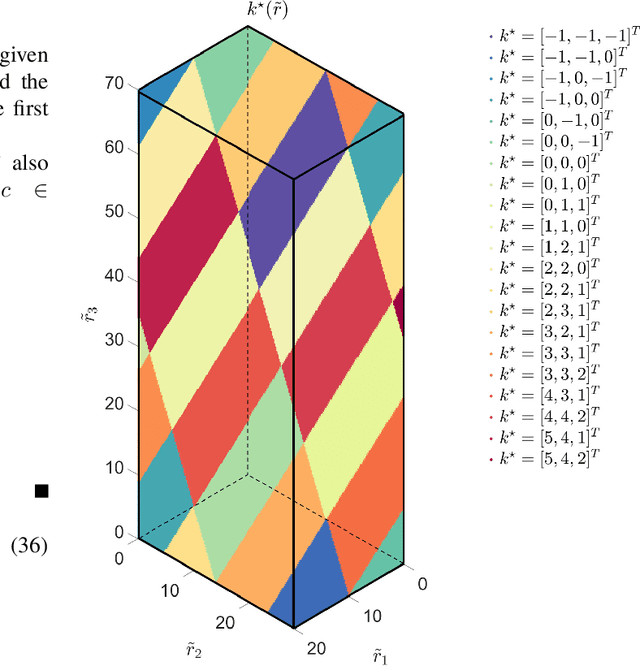

In phase-contrast magnetic resonance imaging (PC-MRI), the velocity of spins at a voxel is encoded in the image phase. The strength of the velocity encoding (venc) gradient offers a trade-off between the velocity-to-noise ratio (VNR) and the extent of phase aliasing. In the three-point encoding employed in traditional dual-venc acquisition, two velocity-encoded acquisitions are acquired along with a third velocity-compensated measurement; their phase differences result in an unaliased high-venc measurement used to unwrap the less noisy low-venc measurement. Alternatively, the velocity may be more accurately estimated by jointly processing all three potentially wrapped phase differences. We present a fast, grid-free approximate maximum likelihood estimator, Phase Recovery from Multiple Wrapped Measurements (PRoM), for solving a noisy set of congruence equations with correlated noise. PRoM is applied to three-point acquisition for estimating velocity. The proposed approach can significantly expand the range of correctly unwrapped velocities compared to the traditional dual-venc method, while also providing improvement in velocity-to-noise ratio. Moreover, its closed-form expressions for the probability distribution of the estimated velocity enable the optimized design of acquisition.
Exploiting the Intrinsic Neighborhood Structure for Source-free Domain Adaptation
Oct 08, 2021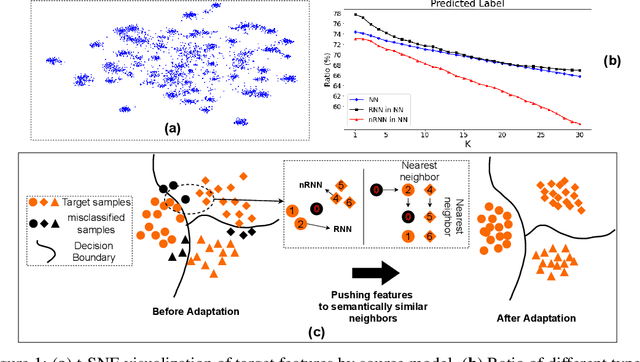
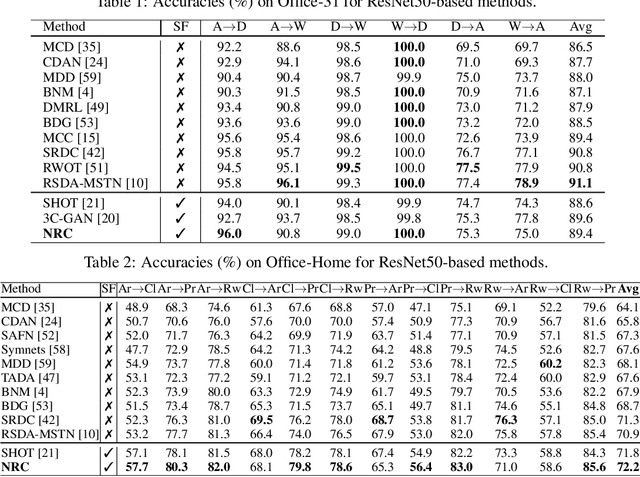
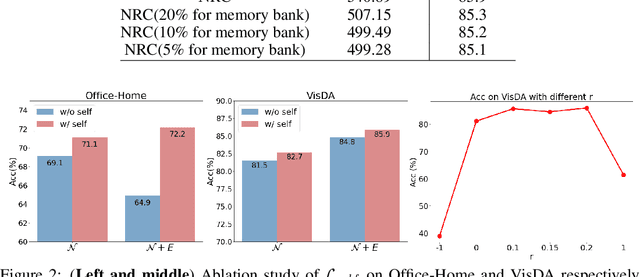
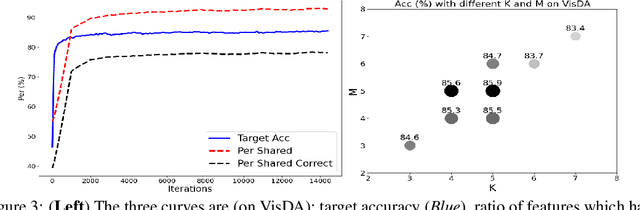
Domain adaptation (DA) aims to alleviate the domain shift between source domain and target domain. Most DA methods require access to the source data, but often that is not possible (e.g. due to data privacy or intellectual property). In this paper, we address the challenging source-free domain adaptation (SFDA) problem, where the source pretrained model is adapted to the target domain in the absence of source data. Our method is based on the observation that target data, which might no longer align with the source domain classifier, still forms clear clusters. We capture this intrinsic structure by defining local affinity of the target data, and encourage label consistency among data with high local affinity. We observe that higher affinity should be assigned to reciprocal neighbors, and propose a self regularization loss to decrease the negative impact of noisy neighbors. Furthermore, to aggregate information with more context, we consider expanded neighborhoods with small affinity values. In the experimental results we verify that the inherent structure of the target features is an important source of information for domain adaptation. We demonstrate that this local structure can be efficiently captured by considering the local neighbors, the reciprocal neighbors, and the expanded neighborhood. Finally, we achieve state-of-the-art performance on several 2D image and 3D point cloud recognition datasets. Code is available in https://github.com/Albert0147/SFDA_neighbors.
A Random CNN Sees Objects: One Inductive Bias of CNN and Its Applications
Jun 17, 2021
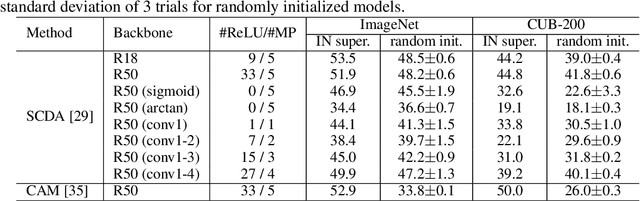
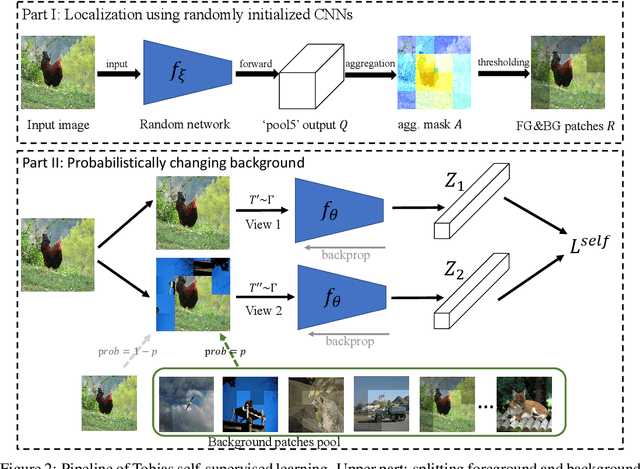
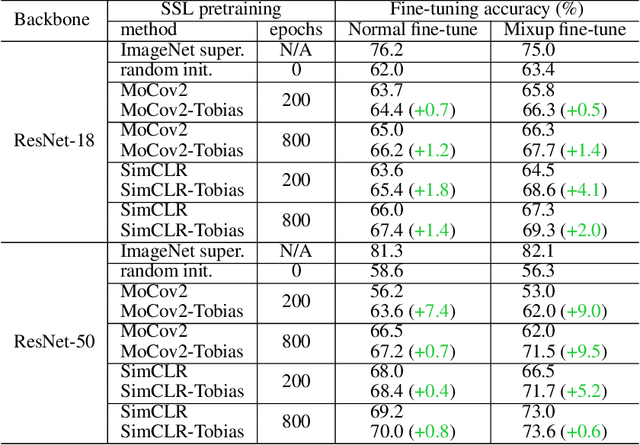
This paper starts by revealing a surprising finding: without any learning, a randomly initialized CNN can localize objects surprisingly well. That is, a CNN has an inductive bias to naturally focus on objects, named as Tobias (``The object is at sight'') in this paper. This empirical inductive bias is further analyzed and successfully applied to self-supervised learning. A CNN is encouraged to learn representations that focus on the foreground object, by transforming every image into various versions with different backgrounds, where the foreground and background separation is guided by Tobias. Experimental results show that the proposed Tobias significantly improves downstream tasks, especially for object detection. This paper also shows that Tobias has consistent improvements on training sets of different sizes, and is more resilient to changes in image augmentations. Our codes will be available at https://github.com/CupidJay/Tobias.
A Novel Pixel-Averaging Technique for Extracting Training Data from a Single Image, Used in ML-Based Image Enlargement
Mar 25, 2019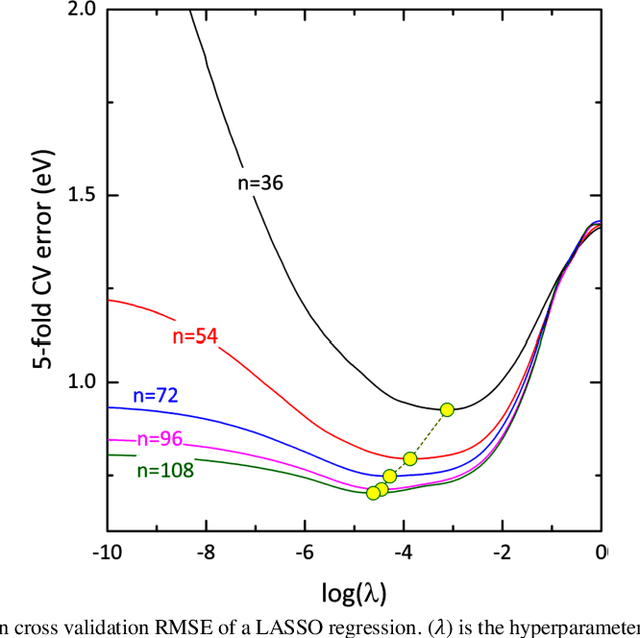
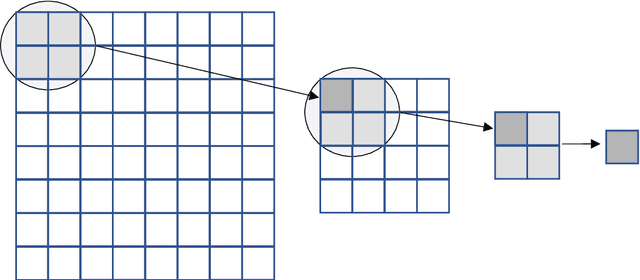
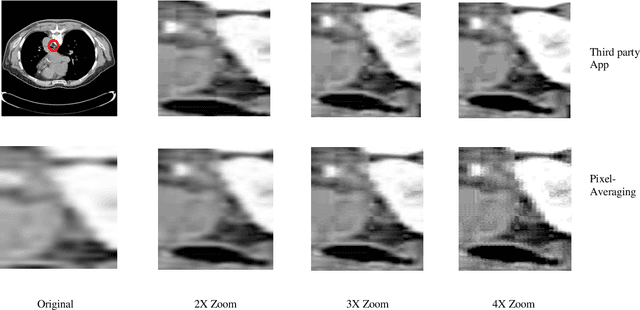
Size of the training dataset is an important factor in the performance of a machine learning algorithms and tools used in medical image processing are not exceptions. Machine learning tools normally require a decent amount of training data before they could efficiently predict a target. For image processing and computer vision, the number of images determines the validity and reliability of the training set. Medical images in some cases, suffer from poor quality and inadequate quantity required for a suitable training set. The proposed algorithm in this research obviates the need for large or even small image datasets used in machine learning based image enlargement techniques by extracting the required data from a single image. The extracted data was then introduced to a decision tree regressor for upscaling greyscale medical images at different zoom levels. Results from the algorithm are relatively acceptable compared to third-party applications and promising for future research. This technique could be tailored to the requirements of other machine learning tools and the results may be improved by further tweaking of the tools hyperparameters.
Multimodal Transformer with Multi-View Visual Representation for Image Captioning
May 20, 2019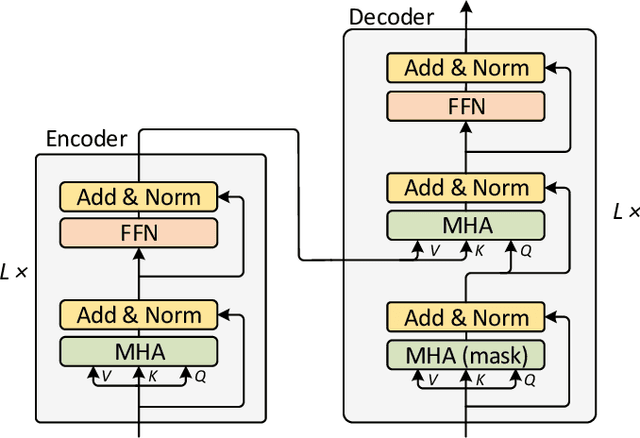
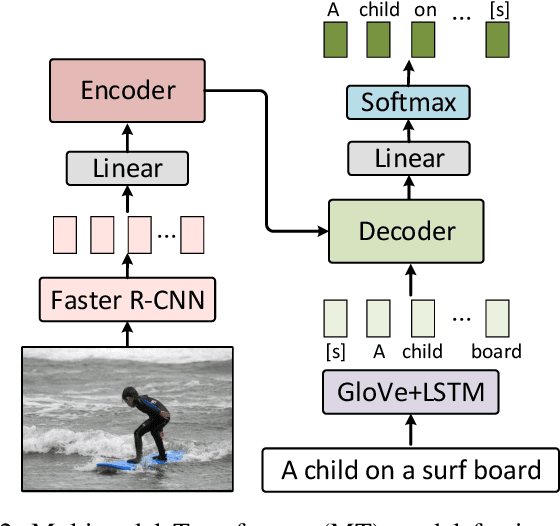

Image captioning aims to automatically generate a natural language description of a given image, and most state-of-the-art models have adopted an encoder-decoder framework. The framework consists of a convolution neural network (CNN)-based image encoder that extracts region-based visual features from the input image, and an recurrent neural network (RNN)-based caption decoder that generates the output caption words based on the visual features with the attention mechanism. Despite the success of existing studies, current methods only model the co-attention that characterizes the inter-modal interactions while neglecting the self-attention that characterizes the intra-modal interactions. Inspired by the success of the Transformer model in machine translation, here we extend it to a Multimodal Transformer (MT) model for image captioning. Compared to existing image captioning approaches, the MT model simultaneously captures intra- and inter-modal interactions in a unified attention block. Due to the in-depth modular composition of such attention blocks, the MT model can perform complex multimodal reasoning and output accurate captions. Moreover, to further improve the image captioning performance, multi-view visual features are seamlessly introduced into the MT model. We quantitatively and qualitatively evaluate our approach using the benchmark MSCOCO image captioning dataset and conduct extensive ablation studies to investigate the reasons behind its effectiveness. The experimental results show that our method significantly outperforms the previous state-of-the-art methods. With an ensemble of seven models, our solution ranks the 1st place on the real-time leaderboard of the MSCOCO image captioning challenge at the time of the writing of this paper.
Real World Robustness from Systematic Noise
Sep 02, 2021
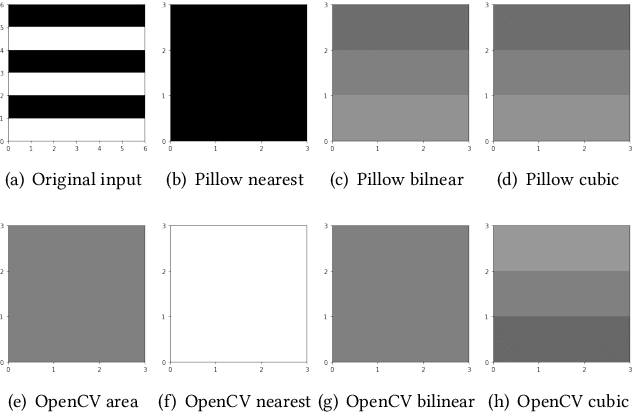
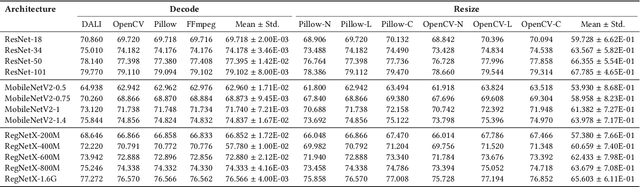
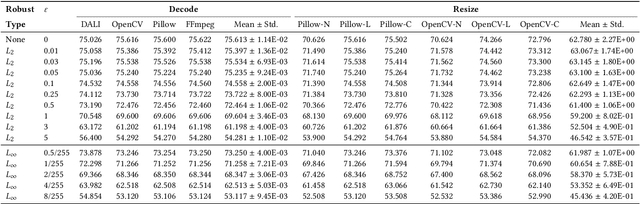
Systematic error, which is not determined by chance, often refers to the inaccuracy (involving either the observation or measurement process) inherent to a system. In this paper, we exhibit some long-neglected but frequent-happening adversarial examples caused by systematic error. More specifically, we find the trained neural network classifier can be fooled by inconsistent implementations of image decoding and resize. This tiny difference between these implementations often causes an accuracy drop from training to deployment. To benchmark these real-world adversarial examples, we propose ImageNet-S dataset, which enables researchers to measure a classifier's robustness to systematic error. For example, we find a normal ResNet-50 trained on ImageNet can have 1%-5% accuracy difference due to the systematic error. Together our evaluation and dataset may aid future work toward real-world robustness and practical generalization.
Indoor image representation by high-level semantic features
Jul 11, 2019
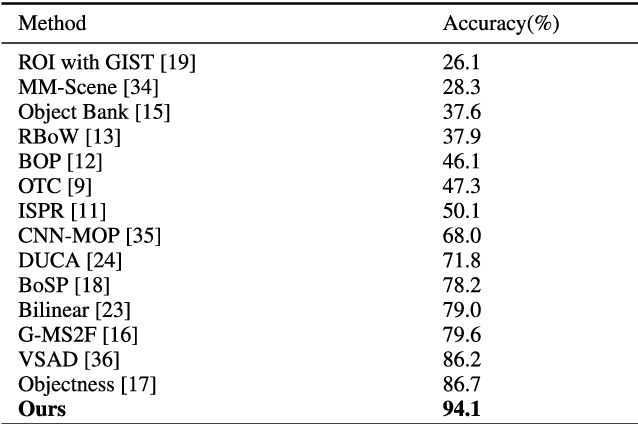

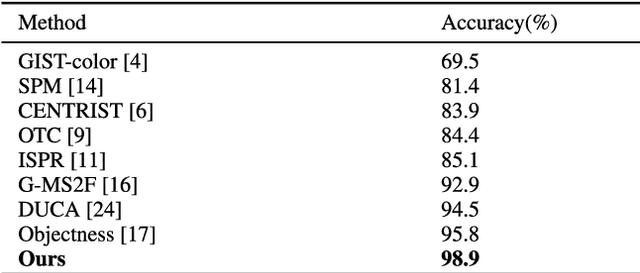
Indoor image features extraction is a fundamental problem in multiple fields such as image processing, pattern recognition, robotics and so on. Nevertheless, most of the existing feature extraction methods, which extract features based on pixels, color, shape/object parts or objects on images, suffer from limited capabilities in describing semantic information (e.g., object association). These techniques, therefore, involve undesired classification performance. To tackle this issue, we propose the notion of high-level semantic features and design four steps to extract them. Specifically, we first construct the objects pattern dictionary through extracting raw objects in the images, and then retrieve and extract semantic objects from the objects pattern dictionary. We finally extract our high-level semantic features based on the calculated probability and del parameter. Experiments on three publicly available datasets (MIT-67, Scene15 and NYU V1) show that our feature extraction approach outperforms state-of-the-art feature extraction methods for indoor image classification, given a lower dimension of our features than those methods.
SAFIN: Arbitrary Style Transfer With Self-Attentive Factorized Instance Normalization
May 13, 2021


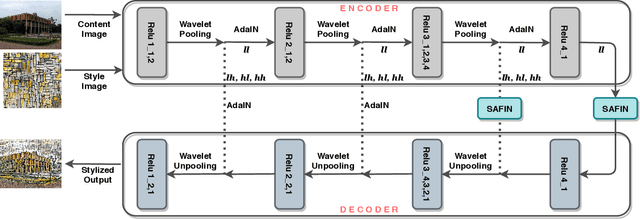
Artistic style transfer aims to transfer the style characteristics of one image onto another image while retaining its content. Existing approaches commonly leverage various normalization techniques, although these face limitations in adequately transferring diverse textures to different spatial locations. Self-Attention-based approaches have tackled this issue with partial success but suffer from unwanted artifacts. Motivated by these observations, this paper aims to combine the best of both worlds: self-attention and normalization. That yields a new plug-and-play module that we nameSelf-Attentive Fac-torized Instance Normalization(SAFIN). SAFIN is essentially a spatially adaptive normalization module whose parameters are inferred through attention on the content and style image. We demonstrate that plugging SAFIN into the base network of another state-of-the-art method results in enhanced stylization. We also develop a novel base network composed of Wavelet Transform for multi-scale style transfer, which when combined with SAFIN, produces visually appealing results with lesser unwanted textures.
Universal Weakly Supervised Segmentation by Pixel-to-Segment Contrastive Learning
May 11, 2021
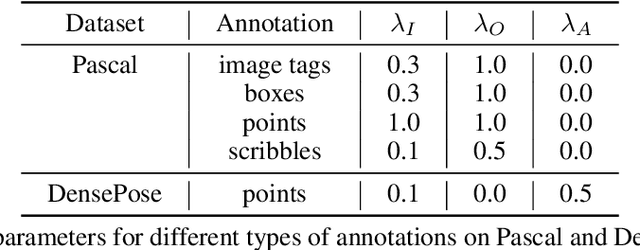
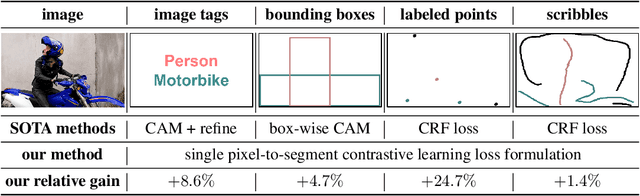
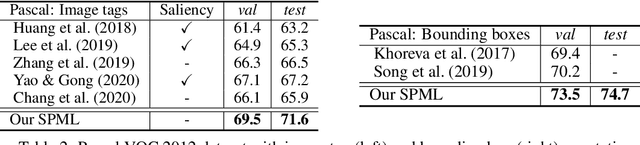
Weakly supervised segmentation requires assigning a label to every pixel based on training instances with partial annotations such as image-level tags, object bounding boxes, labeled points and scribbles. This task is challenging, as coarse annotations (tags, boxes) lack precise pixel localization whereas sparse annotations (points, scribbles) lack broad region coverage. Existing methods tackle these two types of weak supervision differently: Class activation maps are used to localize coarse labels and iteratively refine the segmentation model, whereas conditional random fields are used to propagate sparse labels to the entire image. We formulate weakly supervised segmentation as a semi-supervised metric learning problem, where pixels of the same (different) semantics need to be mapped to the same (distinctive) features. We propose 4 types of contrastive relationships between pixels and segments in the feature space, capturing low-level image similarity, semantic annotation, co-occurrence, and feature affinity They act as priors; the pixel-wise feature can be learned from training images with any partial annotations in a data-driven fashion. In particular, unlabeled pixels in training images participate not only in data-driven grouping within each image, but also in discriminative feature learning within and across images. We deliver a universal weakly supervised segmenter with significant gains on Pascal VOC and DensePose. Our code is publicly available at https://github.com/twke18/SPML.