 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Learned Image Downscaling for Upscaling using Content Adaptive Resampler
Jul 22, 2019
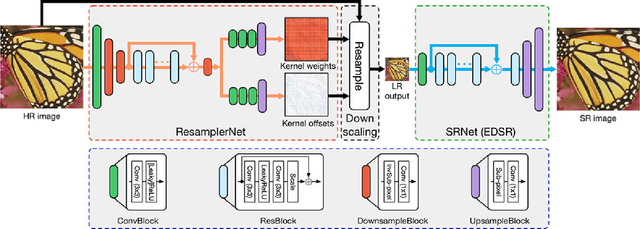
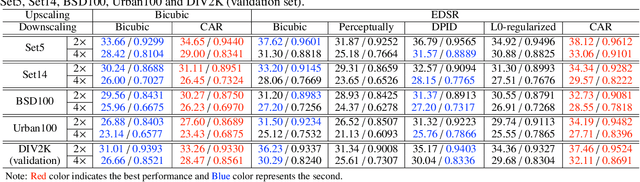
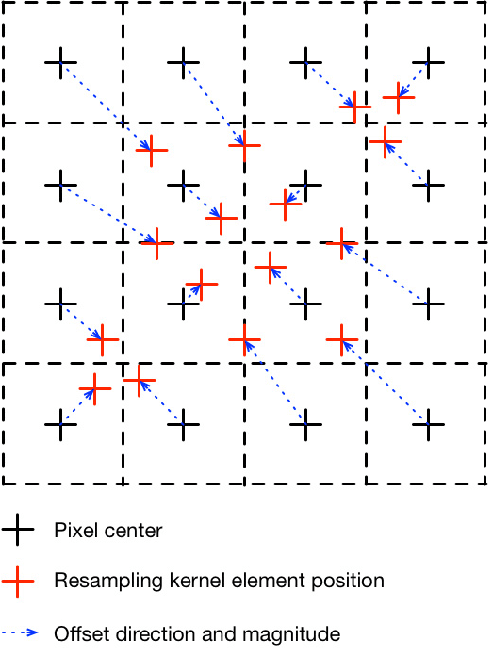
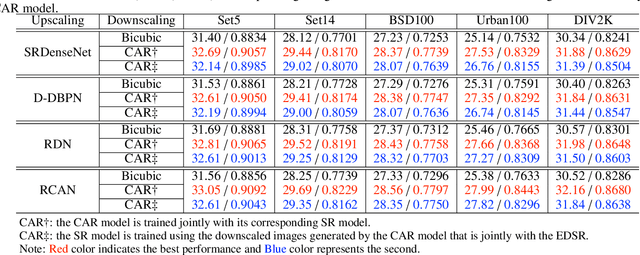
Deep convolutional neural network based image super-resolution (SR) models have shown superior performance in recovering the underlying high resolution (HR) images from low resolution (LR) images obtained from the predefined downscaling methods. In this paper we propose a learned image downscaling method based on content adaptive resampler (CAR) with consideration on the upscaling process. The proposed resampler network generates content adaptive image resampling kernels that are applied to the original HR input to generate pixels on the downscaled image. Moreover, a differentiable upscaling (SR) module is employed to upscale the LR result into its underlying HR counterpart. By back-propagating the reconstruction error down to the original HR input across the entire framework to adjust model parameters, the proposed framework achieves a new state-of-the-art SR performance through upscaling guided image resamplers which adaptively preserve detailed information that is essential to the upscaling. Experimental results indicate that the quality of the generated LR image is comparable to that of the traditional interpolation based method, but the significant SR performance gain is achieved by deep SR models trained jointly with the CAR model. The code is publicly available on: URL https://github.com/sunwj/CAR.
Efficient Real-Time Image Recognition Using Collaborative Swarm of UAVs and Convolutional Networks
Jul 09, 2021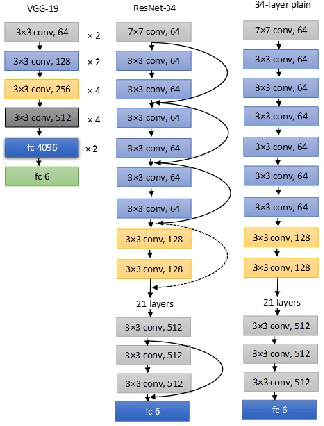
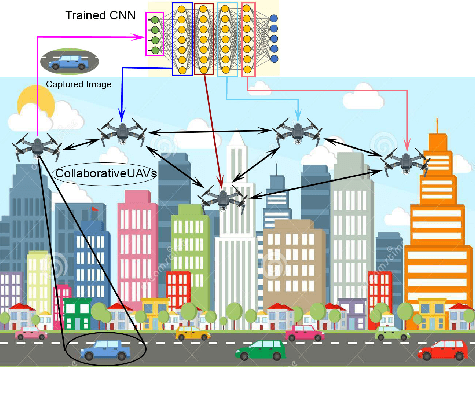
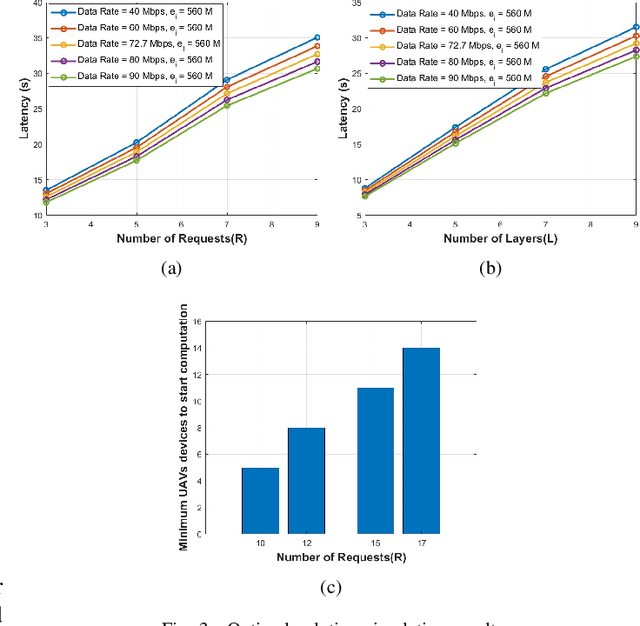
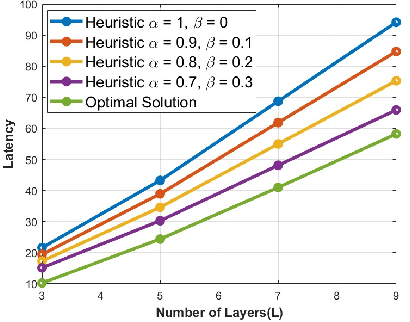
Unmanned Aerial Vehicles (UAVs) have recently attracted significant attention due to their outstanding ability to be used in different sectors and serve in difficult and dangerous areas. Moreover, the advancements in computer vision and artificial intelligence have increased the use of UAVs in various applications and solutions, such as forest fires detection and borders monitoring. However, using deep neural networks (DNNs) with UAVs introduces several challenges of processing deeper networks and complex models, which restricts their on-board computation. In this work, we present a strategy aiming at distributing inference requests to a swarm of resource-constrained UAVs that classifies captured images on-board and finds the minimum decision-making latency. We formulate the model as an optimization problem that minimizes the latency between acquiring images and making the final decisions. The formulated optimization solution is an NP-hard problem. Hence it is not adequate for online resource allocation. Therefore, we introduce an online heuristic solution, namely DistInference, to find the layers placement strategy that gives the best latency among the available UAVs. The proposed approach is general enough to be used for different low decision-latency applications as well as for all CNN types organized into the pipeline of layers (e.g., VGG) or based on residual blocks (e.g., ResNet).
Toward a Visual Concept Vocabulary for GAN Latent Space
Oct 08, 2021
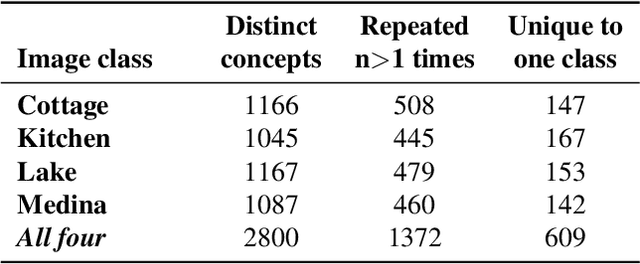

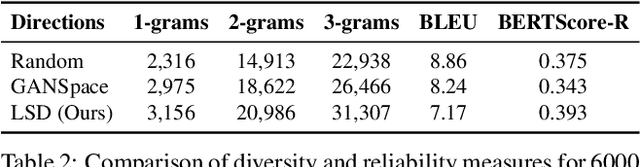
A large body of recent work has identified transformations in the latent spaces of generative adversarial networks (GANs) that consistently and interpretably transform generated images. But existing techniques for identifying these transformations rely on either a fixed vocabulary of pre-specified visual concepts, or on unsupervised disentanglement techniques whose alignment with human judgments about perceptual salience is unknown. This paper introduces a new method for building open-ended vocabularies of primitive visual concepts represented in a GAN's latent space. Our approach is built from three components: (1) automatic identification of perceptually salient directions based on their layer selectivity; (2) human annotation of these directions with free-form, compositional natural language descriptions; and (3) decomposition of these annotations into a visual concept vocabulary, consisting of distilled directions labeled with single words. Experiments show that concepts learned with our approach are reliable and composable -- generalizing across classes, contexts, and observers, and enabling fine-grained manipulation of image style and content.
Capsules for Biomedical Image Segmentation
Apr 09, 2020
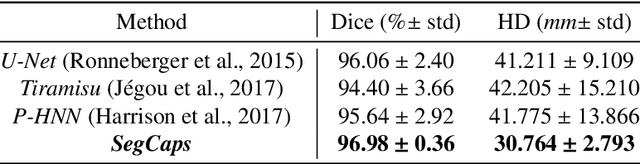
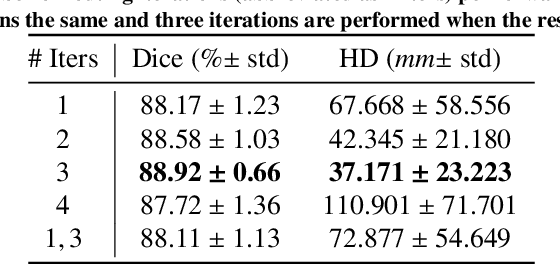

Our work expands the use of capsule networks to the task of object segmentation for the first time in the literature. This is made possible via the introduction of locally-constrained routing and transformation matrix sharing, which reduces the parameter/memory burden and allows for the segmentation of objects at large resolutions. To compensate for the loss of global information in constraining the routing, we propose the concept of "deconvolutional" capsules to create a deep encoder-decoder style network, called SegCaps. We extend the masked reconstruction regularization to the task of segmentation and perform thorough ablation experiments on each component of our method. The proposed convolutional-deconvolutional capsule network, SegCaps, shows state-of-the-art results while using a fraction of the parameters of popular segmentation networks. To validate our proposed method, we perform the largest-scale study in pathological lung segmentation in the literature, where we conduct experiments across five extremely challenging datasets, containing both clinical and pre-clinical subjects, and nearly 2000 computed-tomography scans. Our newly developed segmentation platform outperforms other methods across all datasets while utilizing 95% fewer parameters than the popular U-Net for biomedical image segmentation. We also provide proof-of-concept results on thin, tree-like structures in retinal imagery as well as demonstrate capsules' handling of rotations/reflections on natural images.
Image-Adaptive GAN based Reconstruction
Jun 12, 2019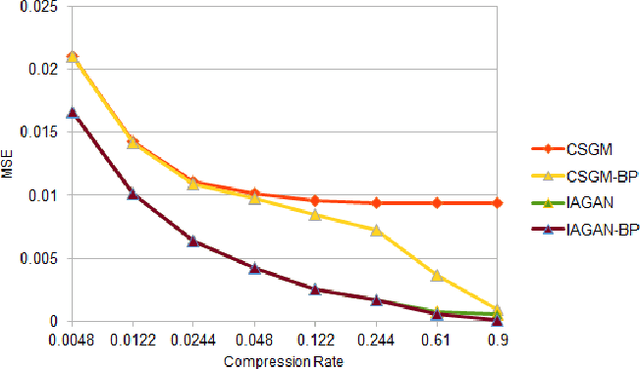



In the recent years, there has been a significant improvement in the quality of samples produced by (deep) generative models such as variational auto-encoders and generative adversarial networks. However, the representation capabilities of these methods still do not capture the full distribution for complex classes of images, such as human faces. This deficiency has been clearly observed in previous works that use pre-trained generative models to solve imaging inverse problems. In this paper, we suggest to mitigate the limited representation capabilities of generators by making them image-adaptive and enforcing compliance of the restoration with the observations via back-projections. We empirically demonstrate the advantages of our proposed approach for image super-resolution and compressed sensing
Recurrent Variational Network: A Deep Learning Inverse Problem Solver applied to the task of Accelerated MRI Reconstruction
Nov 18, 2021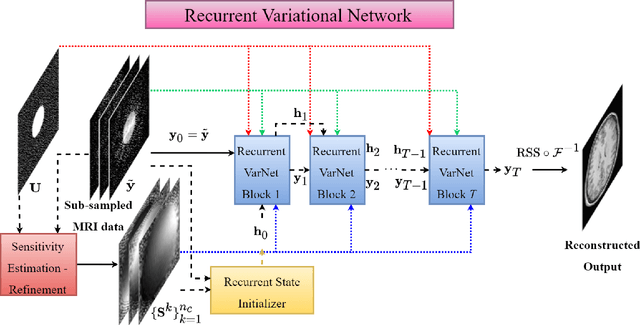
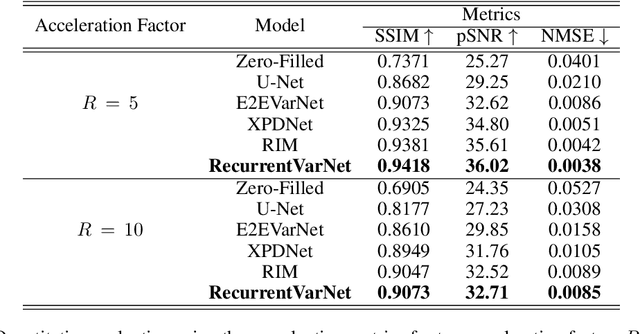
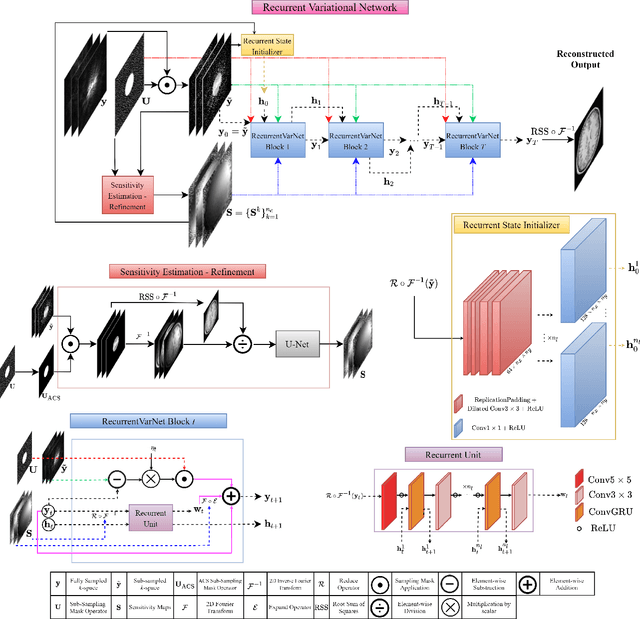

Magnetic Resonance Imaging can produce detailed images of the anatomy and physiology of the human body that can assist doctors in diagnosing and treating pathologies such as tumours. However, MRI suffers from very long acquisition times that make it susceptible to patient motion artifacts and limit its potential to deliver dynamic treatments. Conventional approaches such as Parallel Imaging and Compressed Sensing allow for an increase in MRI acquisition speed by reconstructing MR images by acquiring less MRI data using multiple receiver coils. Recent advancements in Deep Learning combined with Parallel Imaging and Compressed Sensing techniques have the potential to produce high-fidelity reconstructions from highly accelerated MRI data. In this work we present a novel Deep Learning-based Inverse Problem solver applied to the task of accelerated MRI reconstruction, called Recurrent Variational Network (RecurrentVarNet) by exploiting the properties of Convolution Recurrent Networks and unrolled algorithms for solving Inverse Problems. The RecurrentVarNet consists of multiple blocks, each responsible for one unrolled iteration of the gradient descent optimization algorithm for solving inverse problems. Contrary to traditional approaches, the optimization steps are performed in the observation domain ($k$-space) instead of the image domain. Each recurrent block of RecurrentVarNet refines the observed $k$-space and is comprised of a data consistency term and a recurrent unit which takes as input a learned hidden state and the prediction of the previous block. Our proposed method achieves new state of the art qualitative and quantitative reconstruction results on 5-fold and 10-fold accelerated data from a public multi-channel brain dataset, outperforming previous conventional and deep learning-based approaches. We will release all models code and baselines on our public repository.
Partial supervision for the FeTA challenge 2021
Nov 03, 2021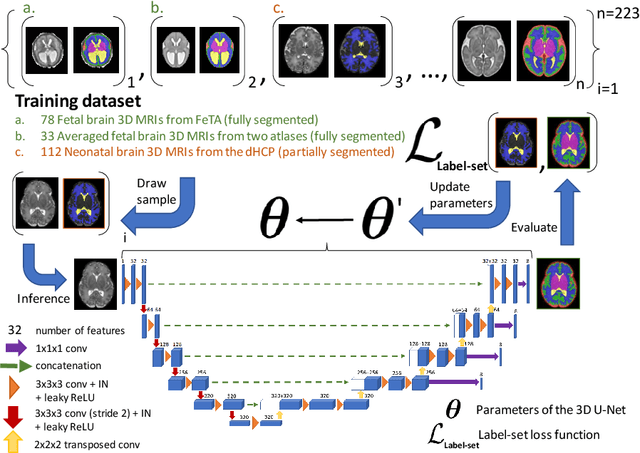
This paper describes our method for our participation in the FeTA challenge2021 (team name: TRABIT). The performance of convolutional neural networks for medical image segmentation is thought to correlate positively with the number of training data. The FeTA challenge does not restrict participants to using only the provided training data but also allows for using other publicly available sources. Yet, open access fetal brain data remains limited. An advantageous strategy could thus be to expand the training data to cover broader perinatal brain imaging sources. Perinatal brain MRIs, other than the FeTA challenge data, that are currently publicly available, span normal and pathological fetal atlases as well as neonatal scans. However, perinatal brain MRIs segmented in different datasets typically come with different annotation protocols. This makes it challenging to combine those datasets to train a deep neural network. We recently proposed a family of loss functions, the label-set loss functions, for partially supervised learning. Label-set loss functions allow to train deep neural networks with partially segmented images, i.e. segmentations in which some classes may be grouped into super-classes. We propose to use label-set loss functions to improve the segmentation performance of a state-of-the-art deep learning pipeline for multi-class fetal brain segmentation by merging several publicly available datasets. To promote generalisability, our approach does not introduce any additional hyper-parameters tuning.
Logical Activation Functions: Logit-space equivalents of Boolean Operators
Oct 22, 2021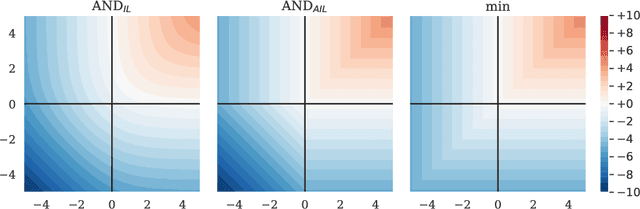
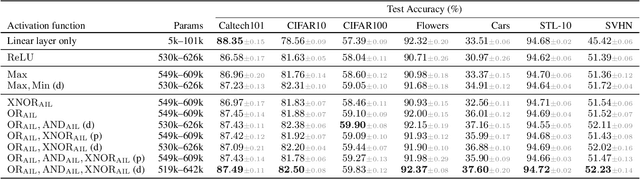
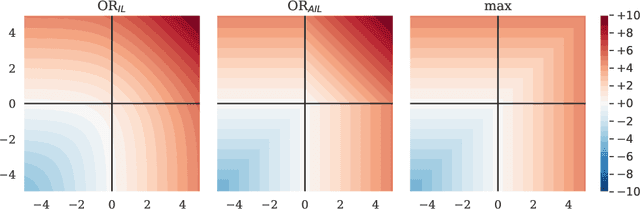

Neuronal representations within artificial neural networks are commonly understood as logits, representing the log-odds score of presence (versus absence) of features within the stimulus. Under this interpretation, we can derive the probability $P(x_0 \land x_1)$ that a pair of independent features are both present in the stimulus from their logits. By converting the resulting probability back into a logit, we obtain a logit-space equivalent of the AND operation. However, since this function involves taking multiple exponents and logarithms, it is not well suited to be directly used within neural networks. We thus constructed an efficient approximation named $\text{AND}_\text{AIL}$ (the AND operator Approximate for Independent Logits) utilizing only comparison and addition operations, which can be deployed as an activation function in neural networks. Like MaxOut, $\text{AND}_\text{AIL}$ is a generalization of ReLU to two-dimensions. Additionally, we constructed efficient approximations of the logit-space equivalents to the OR and XNOR operators. We deployed these new activation functions, both in isolation and in conjunction, and demonstrated their effectiveness on a variety of tasks including image classification, transfer learning, abstract reasoning, and compositional zero-shot learning.
Cleaning Dirty Books: Post-OCR Processing for Previously Scanned Texts
Oct 22, 2021
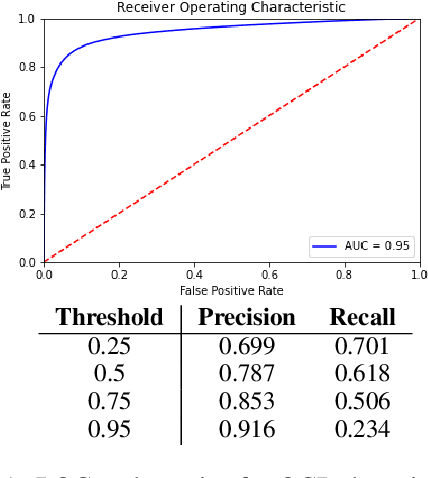
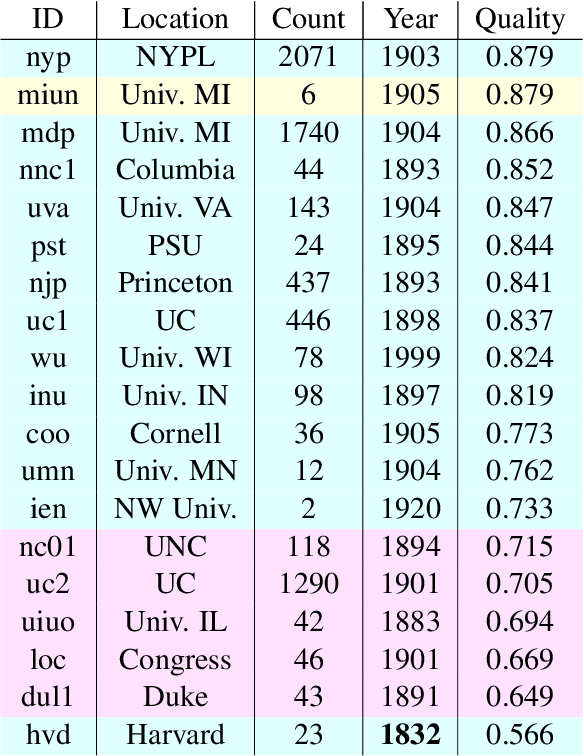
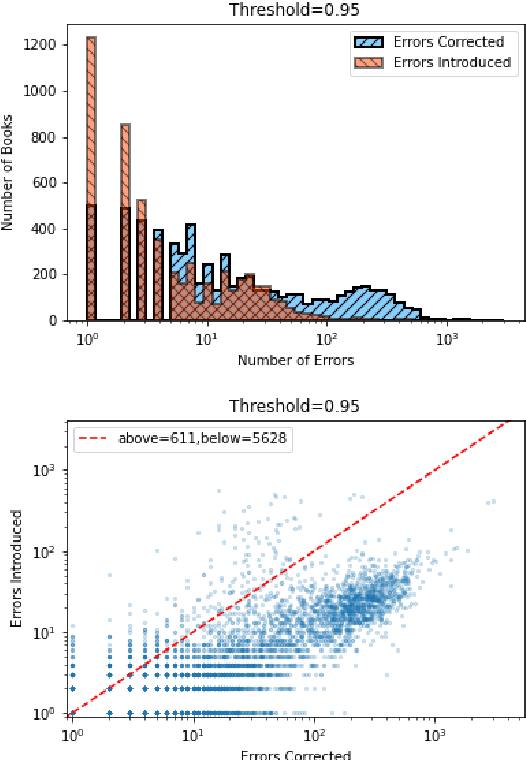
Substantial amounts of work are required to clean large collections of digitized books for NLP analysis, both because of the presence of errors in the scanned text and the presence of duplicate volumes in the corpora. In this paper, we consider the issue of deduplication in the presence of optical character recognition (OCR) errors. We present methods to handle these errors, evaluated on a collection of 19,347 texts from the Project Gutenberg dataset and 96,635 texts from the HathiTrust Library. We demonstrate that improvements in language models now enable the detection and correction of OCR errors without consideration of the scanning image itself. The inconsistencies found by aligning pairs of scans of the same underlying work provides training data to build models for detecting and correcting errors. We identify the canonical version for each of 17,136 repeatedly-scanned books from 58,808 scans. Finally, we investigate methods to detect and correct errors in single-copy texts. We show that on average, our method corrects over six times as many errors as it introduces. We also provide interesting analysis on the relation between scanning quality and other factors such as location and publication year.
Neural Network Pruning Through Constrained Reinforcement Learning
Oct 28, 2021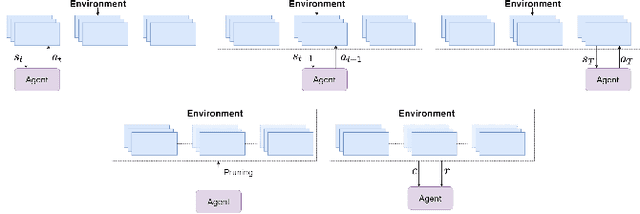
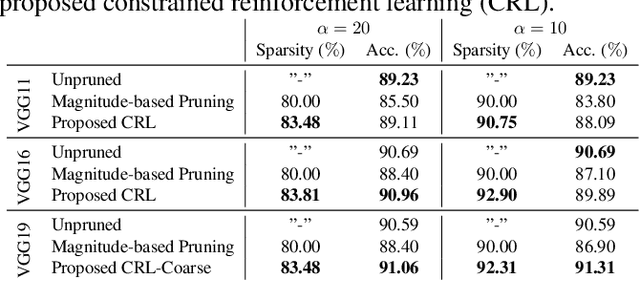
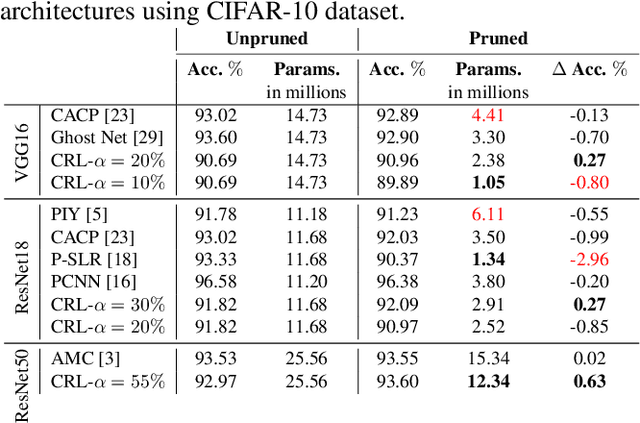
Network pruning reduces the size of neural networks by removing (pruning) neurons such that the performance drop is minimal. Traditional pruning approaches focus on designing metrics to quantify the usefulness of a neuron which is often quite tedious and sub-optimal. More recent approaches have instead focused on training auxiliary networks to automatically learn how useful each neuron is however, they often do not take computational limitations into account. In this work, we propose a general methodology for pruning neural networks. Our proposed methodology can prune neural networks to respect pre-defined computational budgets on arbitrary, possibly non-differentiable, functions. Furthermore, we only assume the ability to be able to evaluate these functions for different inputs, and hence they do not need to be fully specified beforehand. We achieve this by proposing a novel pruning strategy via constrained reinforcement learning algorithms. We prove the effectiveness of our approach via comparison with state-of-the-art methods on standard image classification datasets. Specifically, we reduce 83-92.90 of total parameters on various variants of VGG while achieving comparable or better performance than that of original networks. We also achieved 75.09 reduction in parameters on ResNet18 without incurring any loss in accuracy.