 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
The Effect of Data Ordering in Image Classification
Jan 08, 2020

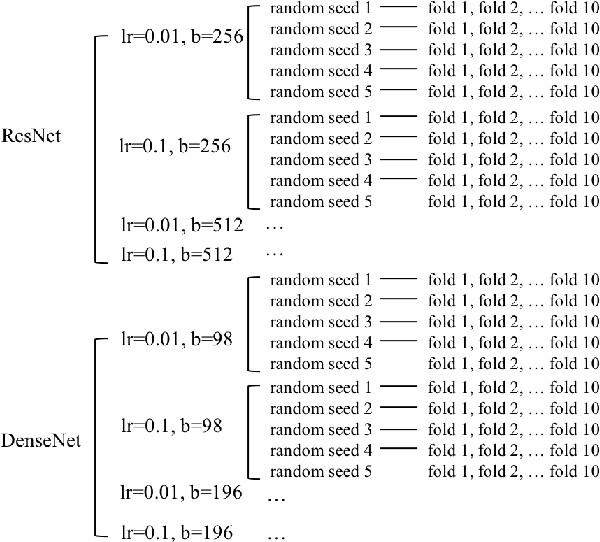
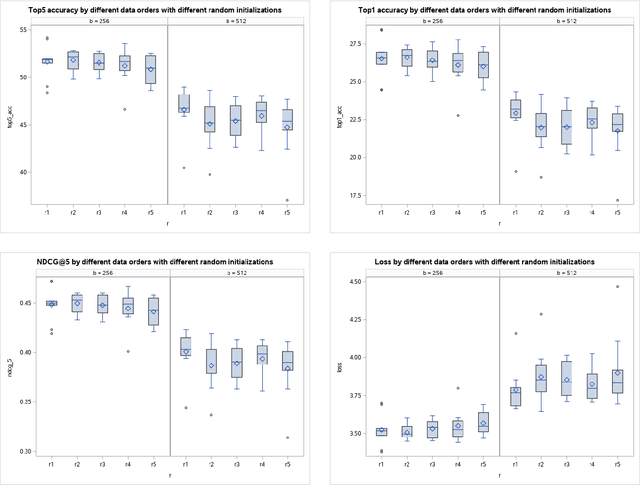
The success stories from deep learning models increase every day spanning different tasks from image classification to natural language understanding. With the increasing popularity of these models, scientists spend more and more time finding the optimal parameters and best model architectures for their tasks. In this paper, we focus on the ingredient that feeds these machines: the data. We hypothesize that the data ordering affects how well a model performs. To that end, we conduct experiments on an image classification task using ImageNet dataset and show that some data orderings are better than others in terms of obtaining higher classification accuracies. Experimental results show that independent of model architecture, learning rate and batch size, ordering of the data significantly affects the outcome. We show these findings using different metrics: NDCG, accuracy @ 1 and accuracy @ 5. Our goal here is to show that not only parameters and model architectures but also the data ordering has a say in obtaining better results.
MimicGAN: Robust Projection onto Image Manifolds with Corruption Mimicking
Dec 16, 2019
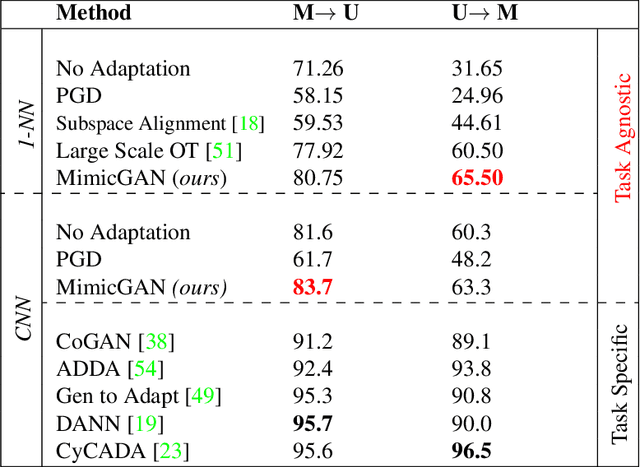
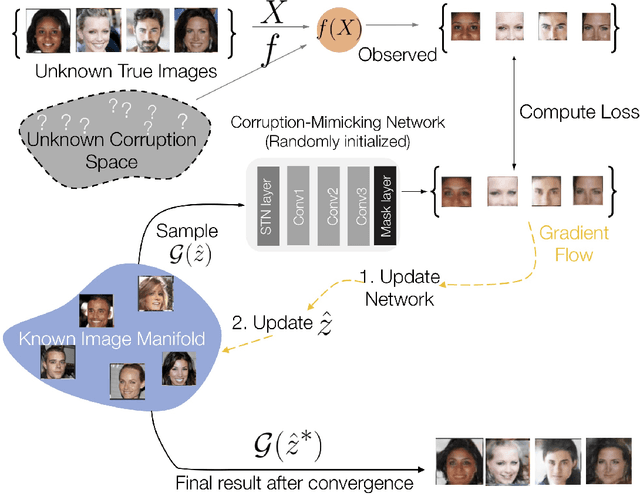
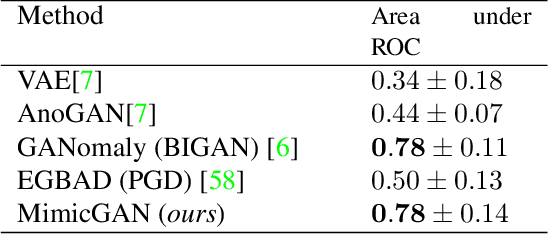
In the past few years, generative models like Generative Adversarial Networks (GANs) have dramatically advanced our ability to represent and parameterize high-dimensional, non-linear image manifolds. As a result, they have been widely adopted across a variety of applications, ranging from challenging inverse problems like image completion, to being used as a prior in problems such as anomaly detection and adversarial defense. A recurring theme in many of these applications is the notion of projecting an image observation onto the manifold that is inferred by the generator. In this context, Projected Gradient Descent (PGD) has been the most popular approach, which essentially searches for a latent representation with the goal of minimizing discrepancy between a generated image and the given observation. However, PGD is an extremely brittle optimization technique that fails to identify the right projection when the observation is corrupted, even by a small amount. Unfortunately, such corruptions are common in the real world, for example arbitrary images with unknown crops, rotations, missing pixels, or other kinds of distribution shifts requiring a more robust projection technique. In this paper we propose corruption-mimicking, a new strategy that utilizes a surrogate network to approximate the unknown corruption directly at test time, without the need for additional supervision or data augmentation. The proposed projection technique significantly improves the robustness of PGD under a wide variety of corruptions, thereby enabling a more effective use of GANs in real-world applications. More importantly, we show that our approach produces state-of-the-art performance in several GAN-based applications -- anomaly detection, domain adaptation, and adversarial defense, that rely on an accurate projection.
Label noise in segmentation networks : mitigation must deal with bias
Jul 05, 2021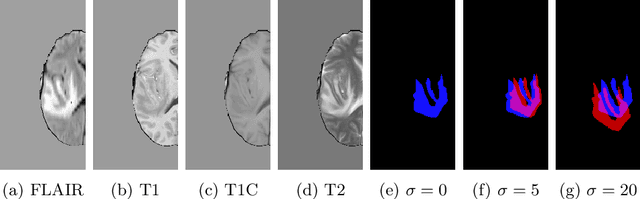
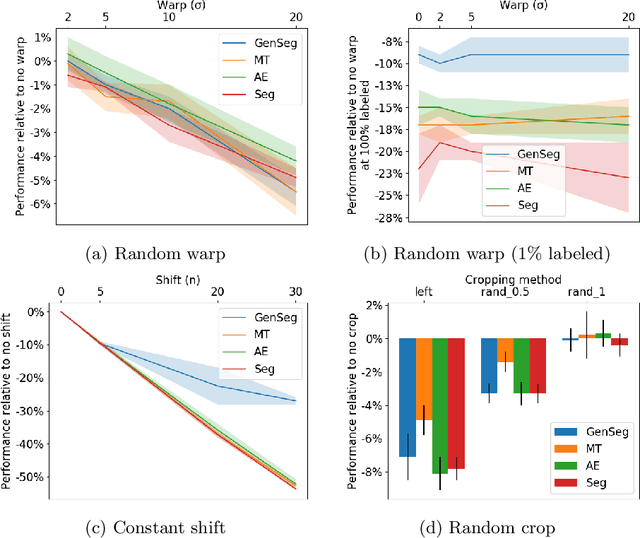
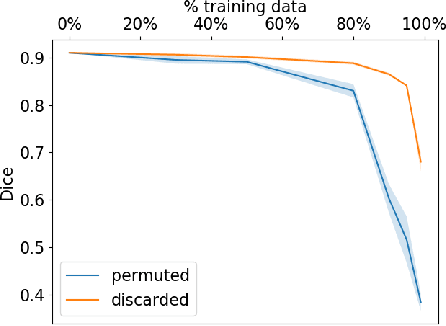
Imperfect labels limit the quality of predictions learned by deep neural networks. This is particularly relevant in medical image segmentation, where reference annotations are difficult to collect and vary significantly even across expert annotators. Prior work on mitigating label noise focused on simple models of mostly uniform noise. In this work, we explore biased and unbiased errors artificially introduced to brain tumour annotations on MRI data. We found that supervised and semi-supervised segmentation methods are robust or fairly robust to unbiased errors but sensitive to biased errors. It is therefore important to identify the sorts of errors expected in medical image labels and especially mitigate the biased errors.
Classification of PS and ABS Black Plastics for WEEE Recycling Applications
Oct 20, 2021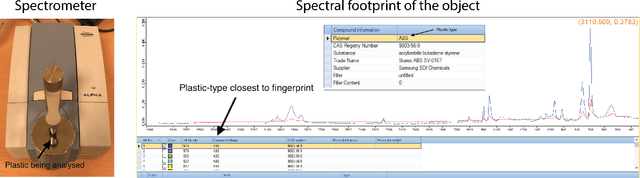
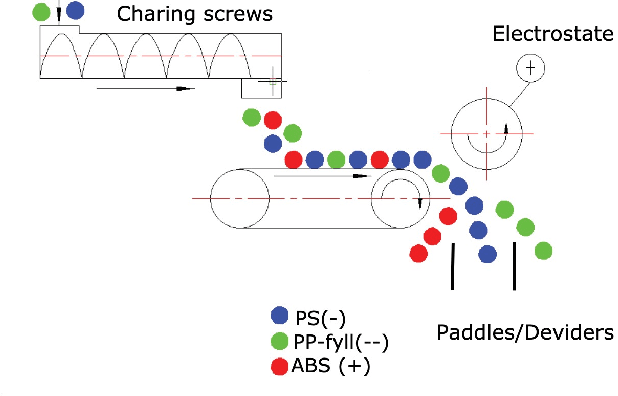


Pollution and climate change are some of the biggest challenges that humanity is facing. In such a context, efficient recycling is a crucial tool for a sustainable future. This work is aimed at creating a system that can classify different types of plastics by using picture analysis, in particular, black plastics of the type Polystyrene (PS) and Acrylonitrile Butadiene Styrene (ABS). They are two common plastics from Waste from Electrical and Electronic Equipment (WEEE). For this purpose, a Convolutional Neural Network has been tested and retrained, obtaining a validation accuracy of 95%. Using a separate test set, average accuracy goes down to 86.6%, but a further look at the results shows that the ABS type is correctly classified 100% of the time, so it is the PS type that accumulates all the errors. Overall, this demonstrates the feasibility of classifying black plastics using CNN machine learning techniques. It is believed that if a more diverse and extensive image dataset becomes available, a system with higher reliability that generalizes well could be developed using the proposed methodology.
Zero-Reference Deep Curve Estimation for Low-Light Image Enhancement
Jan 19, 2020
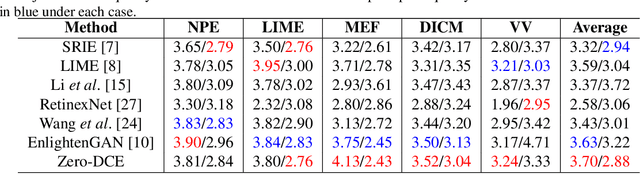
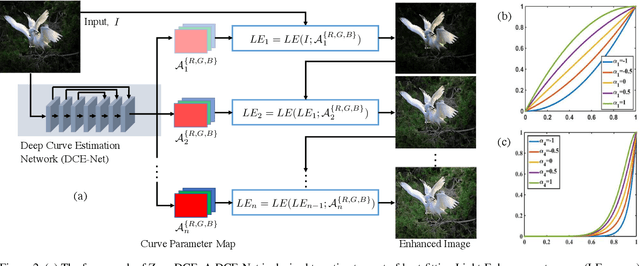
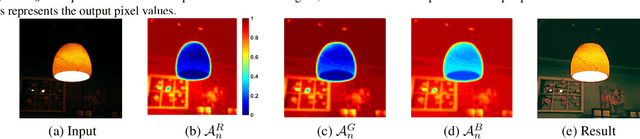
The paper presents a novel method, Zero-Reference Deep Curve Estimation (Zero-DCE), which formulates light enhancement as a task of image-specific curve estimation with a deep network. Our method trains a lightweight deep network, DCE-Net, to estimate pixel-wise and high-order curves for dynamic range adjustment of a given image. The curve estimation is specially designed, considering pixel value range, monotonicity, and differentiability. Zero-DCE is appealing in its relaxed assumption on reference images, i.e., it does not require any paired or unpaired data during training. This is achieved through a set of carefully formulated non-reference loss functions, which implicitly measure the enhancement quality and drive the learning of the network. Our method is efficient as image enhancement can be achieved by an intuitive and simple nonlinear curve mapping. Despite its simplicity, we show that it generalizes well to diverse lighting conditions. Extensive experiments on various benchmarks demonstrate the advantages of our method over state-of-the-art methods qualitatively and quantitatively. Furthermore, the potential benefits of our Zero-DCE to face detection in the dark are discussed. Code and model will be available at https://github.com/Li-Chongyi/Zero-DCE.
Smooth head tracking for virtual reality applications
Oct 27, 2021
In this work, we propose a new head-tracking solution for human-machine real-time interaction with virtual 3D environments. This solution leverages RGBD data to compute virtual camera pose according to the movements of the user's head. The process starts with the extraction of a set of facial features from the images delivered by the sensor. Such features are matched against their respective counterparts in a reference image for the computation of the current head pose. Afterwards, a prediction approach is used to guess the most likely next head move (final pose). Pythagorean Hodograph interpolation is then adapted to determine the path and local frames taken between the two poses. The result is a smooth head trajectory that serves as an input to set the camera in virtual scenes according to the user's gaze. The resulting motion model has the advantage of being: continuous in time, it adapts to any frame rate of rendering; it is ergonomic, as it frees the user from wearing tracking markers; it is smooth and free from rendering jerks; and it is also torsion and curvature minimizing as it produces a path with minimum bending energy.
* 8 pages, 1 figure
End-to-End Adaptive Monte Carlo Denoising and Super-Resolution
Aug 16, 2021
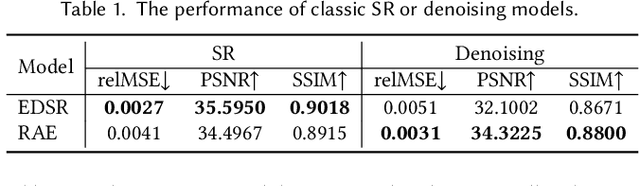
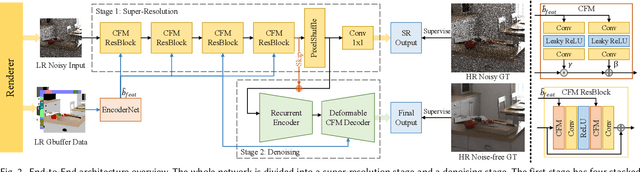
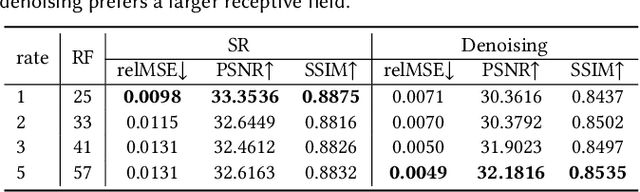
The classic Monte Carlo path tracing can achieve high quality rendering at the cost of heavy computation. Recent works make use of deep neural networks to accelerate this process, by improving either low-resolution or fewer-sample rendering with super-resolution or denoising neural networks in post-processing. However, denoising and super-resolution have only been considered separately in previous work. We show in this work that Monte Carlo path tracing can be further accelerated by joint super-resolution and denoising (SRD) in post-processing. This new type of joint filtering allows only a low-resolution and fewer-sample (thus noisy) image to be rendered by path tracing, which is then fed into a deep neural network to produce a high-resolution and clean image. The main contribution of this work is a new end-to-end network architecture, specifically designed for the SRD task. It contains two cascaded stages with shared components. We discover that denoising and super-resolution require very different receptive fields, a key insight that leads to the introduction of deformable convolution into the network design. Extensive experiments show that the proposed method outperforms previous methods and their variants adopted for the SRD task.
Exploring Multi-Scale Feature Propagation and Communication for Image Super Resolution
Aug 14, 2020

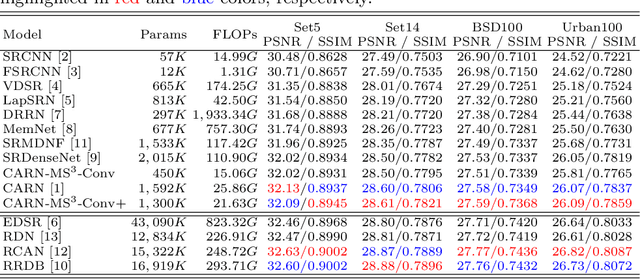
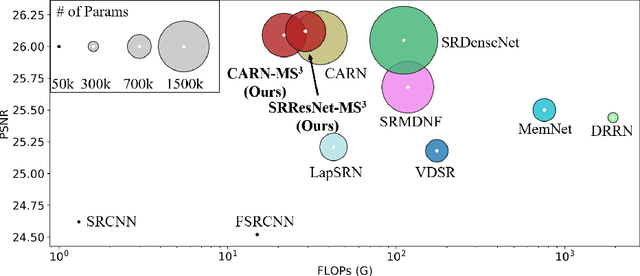
Multi-scale techniques have achieved great success in a wide range of computer vision tasks. However, while this technique is incorporated in existing works, there still lacks a comprehensive investigation on variants of multi-scale convolution in image super resolution. In this work, we present a unified formulation over widely-used multi-scale structures. With this framework, we systematically explore the two factors of multi-scale convolution -- feature propagation and cross-scale communication. Based on the investigation, we propose a generic and efficient multi-scale convolution unit -- Multi-Scale cross-Scale Share-weights convolution (MS$^3$-Conv). Extensive experiments demonstrate that the proposed MS$^3$-Conv can achieve better SR performance than the standard convolution with less parameters and computational cost. Beyond quantitative analysis, we comprehensively study the visual quality, which shows that MS$^3$-Conv behave better to recover high-frequency details.
Copy and Paste method based on Pose for Re-identification
Jul 23, 2021


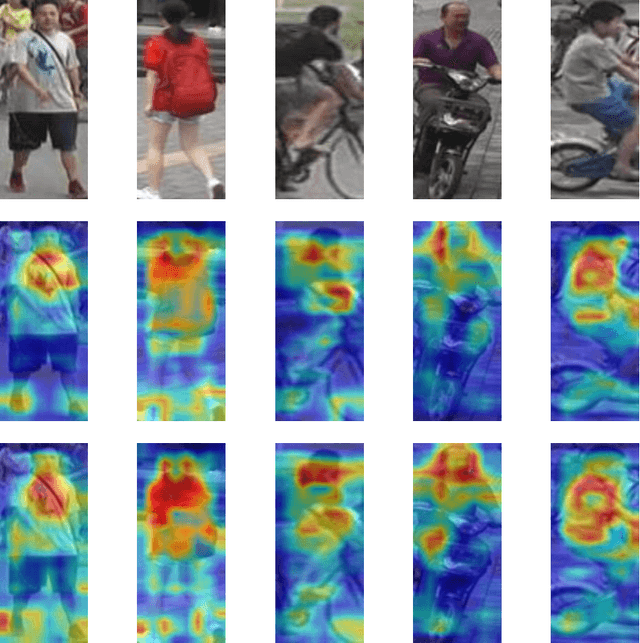
Re-identification (ReID) aims at matching objects in surveillance cameras with different viewpoints. It's developing very fast, but there is no processing method for the ReID task in multiple scenarios at this stage. However, this dose happen all the time in real life, such as the security scenarios. This paper explores a new scenario of Re-identification, which differs in perspective, background, and pose(walking or cycling). Obviously, ordinary ReID processing methods cannot handle this scenario well. As we all know, the best way to deal with that it is to introduce image datasets in this scanario, But this one is very expensive. To solve this problem, this paper proposes a simple and effective way to generate images in some new scenario, which is named Copy and Paste method based on Pose(CPP). The CPP is a method based on key point detection, using copy and paste, to composite a new semantic image dataset in two different semantic image datasets. Such as, we can use pedestrians and bicycles to generate some images that shows the same person rides on different bicycles. The CPP is suitable for ReID tasks in new scenarios and it outperforms state-of-the-art on the original datasets in original ReID tasks. Specifically, it can also have better generalization performance for third-party public datasets. Code and Datasets which composited by the CPP will be available in the future.
Online Multi-Granularity Distillation for GAN Compression
Aug 16, 2021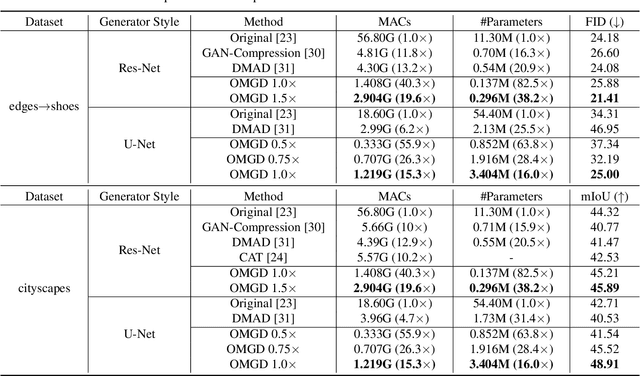
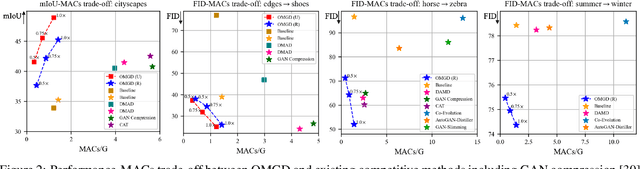
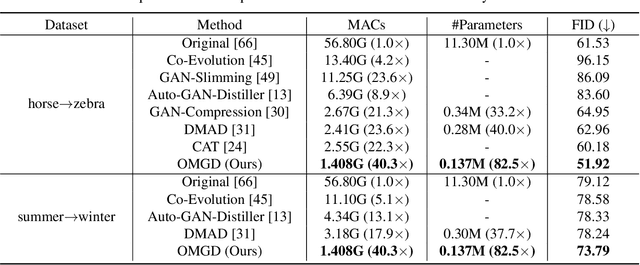
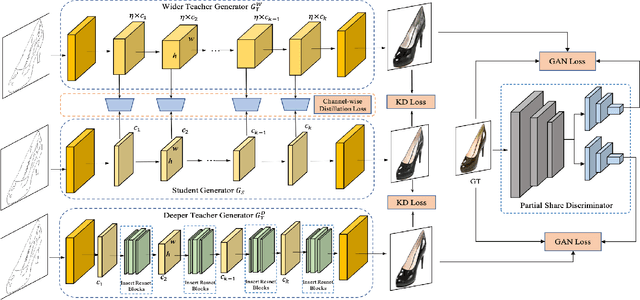
Generative Adversarial Networks (GANs) have witnessed prevailing success in yielding outstanding images, however, they are burdensome to deploy on resource-constrained devices due to ponderous computational costs and hulking memory usage. Although recent efforts on compressing GANs have acquired remarkable results, they still exist potential model redundancies and can be further compressed. To solve this issue, we propose a novel online multi-granularity distillation (OMGD) scheme to obtain lightweight GANs, which contributes to generating high-fidelity images with low computational demands. We offer the first attempt to popularize single-stage online distillation for GAN-oriented compression, where the progressively promoted teacher generator helps to refine the discriminator-free based student generator. Complementary teacher generators and network layers provide comprehensive and multi-granularity concepts to enhance visual fidelity from diverse dimensions. Experimental results on four benchmark datasets demonstrate that OMGD successes to compress 40x MACs and 82.5X parameters on Pix2Pix and CycleGAN, without loss of image quality. It reveals that OMGD provides a feasible solution for the deployment of real-time image translation on resource-constrained devices. Our code and models are made public at: https://github.com/bytedance/OMGD.