 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Effect of Data Ordering in Image Classification
Paper and Code
Jan 08, 2020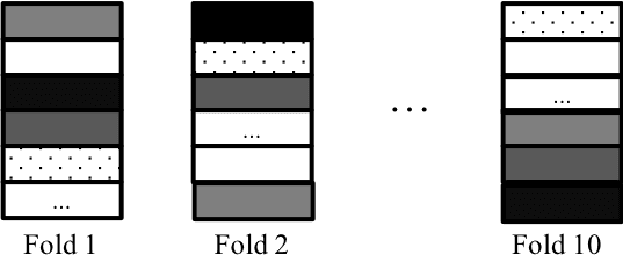

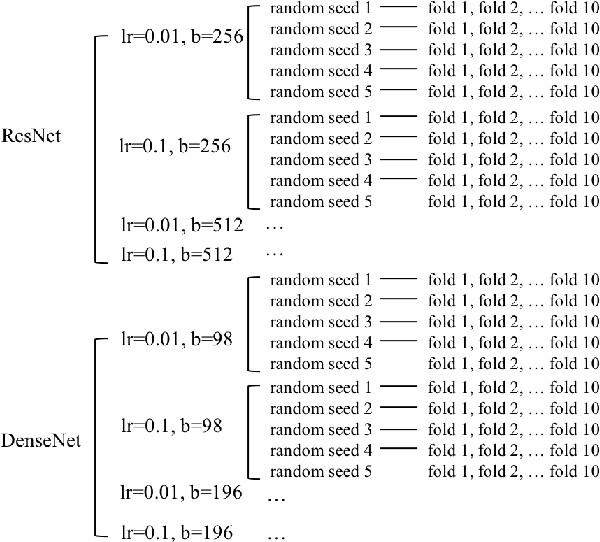
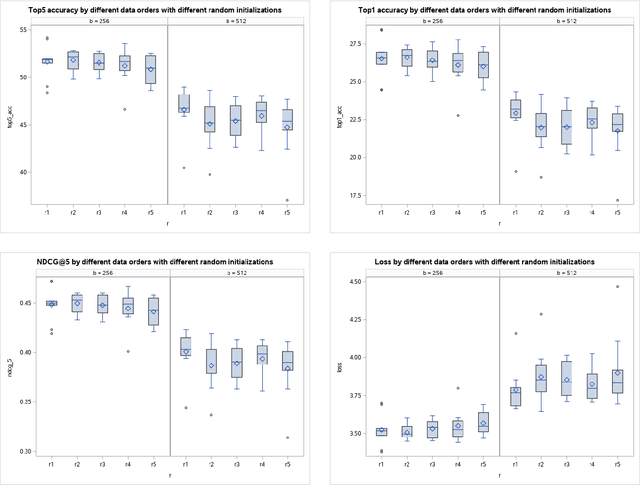
The success stories from deep learning models increase every day spanning different tasks from image classification to natural language understanding. With the increasing popularity of these models, scientists spend more and more time finding the optimal parameters and best model architectures for their tasks. In this paper, we focus on the ingredient that feeds these machines: the data. We hypothesize that the data ordering affects how well a model performs. To that end, we conduct experiments on an image classification task using ImageNet dataset and show that some data orderings are better than others in terms of obtaining higher classification accuracies. Experimental results show that independent of model architecture, learning rate and batch size, ordering of the data significantly affects the outcome. We show these findings using different metrics: NDCG, accuracy @ 1 and accuracy @ 5. Our goal here is to show that not only parameters and model architectures but also the data ordering has a say in obtaining better results.