 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Zero-Shot Certified Defense against Adversarial Patches with Vision Transformers
Nov 19, 2021
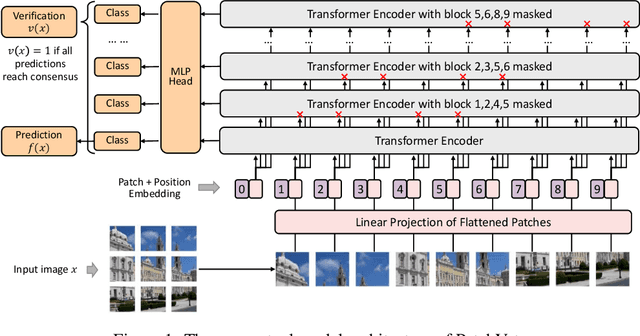
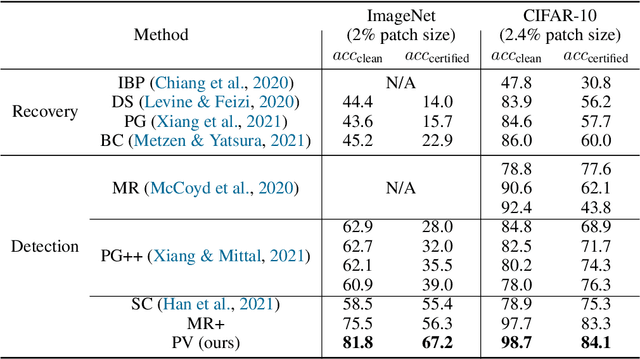
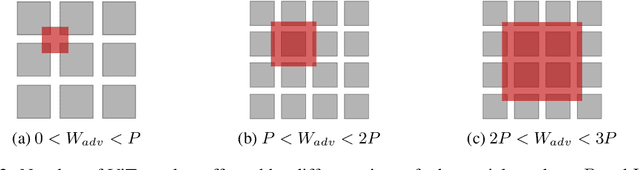
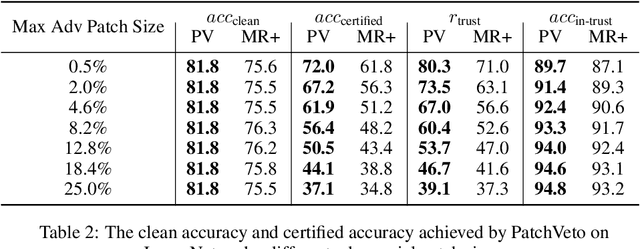
Adversarial patch attack aims to fool a machine learning model by arbitrarily modifying pixels within a restricted region of an input image. Such attacks are a major threat to models deployed in the physical world, as they can be easily realized by presenting a customized object in the camera view. Defending against such attacks is challenging due to the arbitrariness of patches, and existing provable defenses suffer from poor certified accuracy. In this paper, we propose PatchVeto, a zero-shot certified defense against adversarial patches based on Vision Transformer (ViT) models. Rather than training a robust model to resist adversarial patches which may inevitably sacrifice accuracy, PatchVeto reuses a pretrained ViT model without any additional training, which can achieve high accuracy on clean inputs while detecting adversarial patched inputs by simply manipulating the attention map of ViT. Specifically, each input is tested by voting over multiple inferences with different attention masks, where at least one inference is guaranteed to exclude the adversarial patch. The prediction is certifiably robust if all masked inferences reach consensus, which ensures that any adversarial patch would be detected with no false negative. Extensive experiments have shown that PatchVeto is able to achieve high certified accuracy (e.g. 67.1% on ImageNet for 2%-pixel adversarial patches), significantly outperforming state-of-the-art methods. The clean accuracy is the same as vanilla ViT models (81.8% on ImageNet) since the model parameters are directly reused. Meanwhile, our method can flexibly handle different adversarial patch sizes by simply changing the masking strategy.
Brick-by-Brick: Combinatorial Construction with Deep Reinforcement Learning
Oct 29, 2021
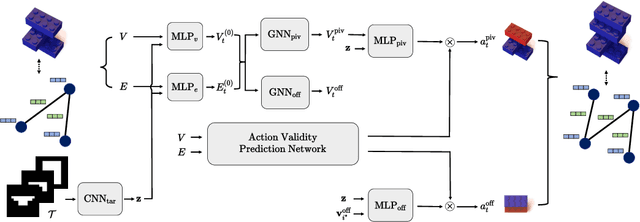
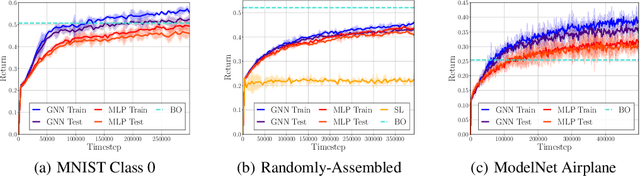
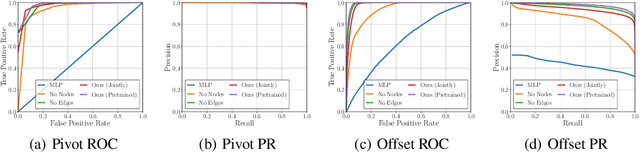
Discovering a solution in a combinatorial space is prevalent in many real-world problems but it is also challenging due to diverse complex constraints and the vast number of possible combinations. To address such a problem, we introduce a novel formulation, combinatorial construction, which requires a building agent to assemble unit primitives (i.e., LEGO bricks) sequentially -- every connection between two bricks must follow a fixed rule, while no bricks mutually overlap. To construct a target object, we provide incomplete knowledge about the desired target (i.e., 2D images) instead of exact and explicit volumetric information to the agent. This problem requires a comprehensive understanding of partial information and long-term planning to append a brick sequentially, which leads us to employ reinforcement learning. The approach has to consider a variable-sized action space where a large number of invalid actions, which would cause overlap between bricks, exist. To resolve these issues, our model, dubbed Brick-by-Brick, adopts an action validity prediction network that efficiently filters invalid actions for an actor-critic network. We demonstrate that the proposed method successfully learns to construct an unseen object conditioned on a single image or multiple views of a target object.
Creating User Interface Mock-ups from High-Level Text Descriptions with Deep-Learning Models
Oct 14, 2021

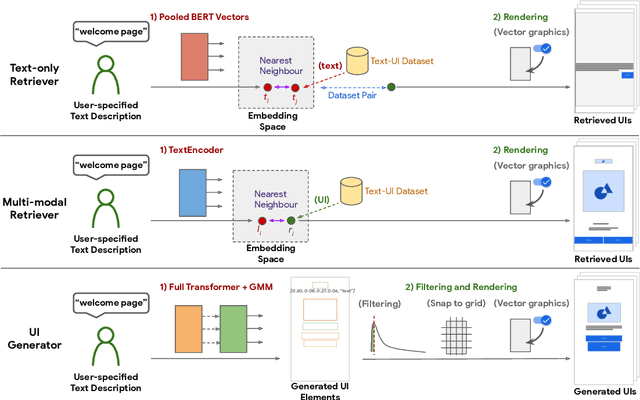
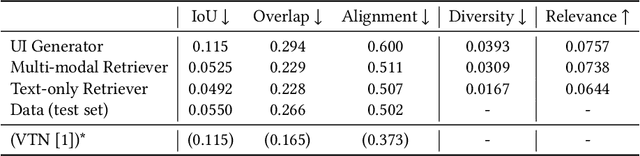
The design process of user interfaces (UIs) often begins with articulating high-level design goals. Translating these high-level design goals into concrete design mock-ups, however, requires extensive effort and UI design expertise. To facilitate this process for app designers and developers, we introduce three deep-learning techniques to create low-fidelity UI mock-ups from a natural language phrase that describes the high-level design goal (e.g. "pop up displaying an image and other options"). In particular, we contribute two retrieval-based methods and one generative method, as well as pre-processing and post-processing techniques to ensure the quality of the created UI mock-ups. We quantitatively and qualitatively compare and contrast each method's ability in suggesting coherent, diverse and relevant UI design mock-ups. We further evaluate these methods with 15 professional UI designers and practitioners to understand each method's advantages and disadvantages. The designers responded positively to the potential of these methods for assisting the design process.
HYPER-SNN: Towards Energy-efficient Quantized Deep Spiking Neural Networks for Hyperspectral Image Classification
Jul 28, 2021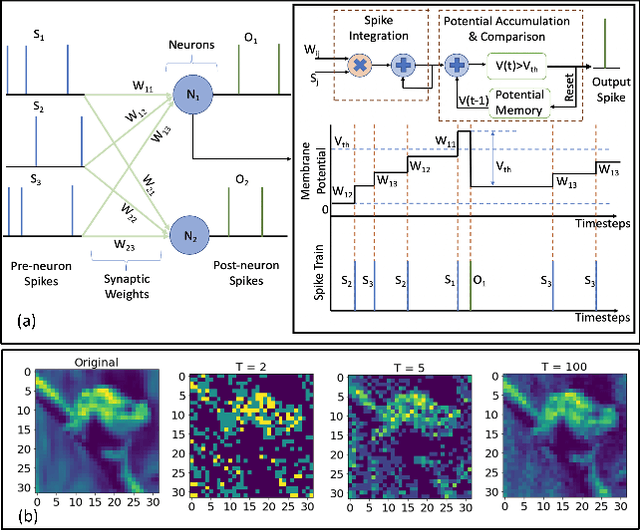
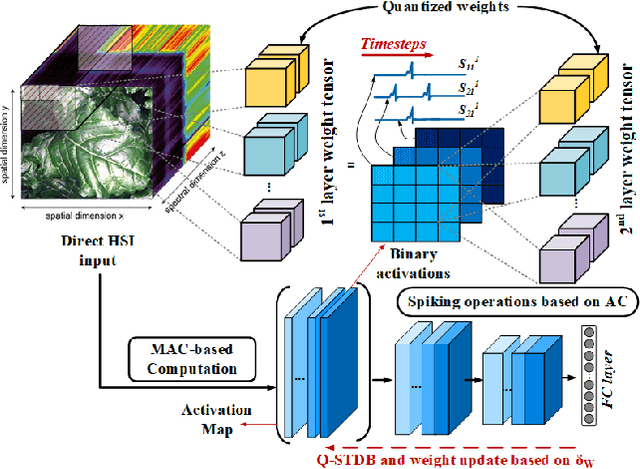
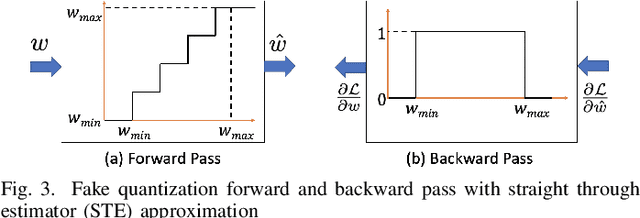
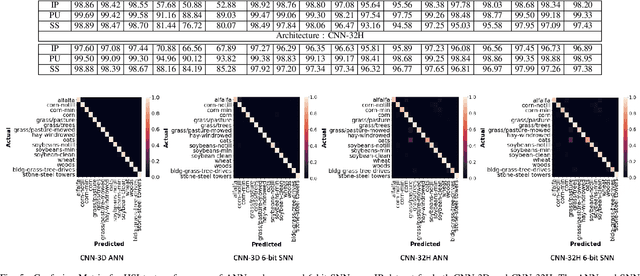
Hyper spectral images (HSI) provide rich spectral and spatial information across a series of contiguous spectral bands. However, the accurate processing of the spectral and spatial correlation between the bands requires the use of energy-expensive 3-D Convolutional Neural Networks (CNNs). To address this challenge, we propose the use of Spiking Neural Networks (SNNs) that are generated from iso-architecture CNNs and trained with quantization-aware gradient descent to optimize their weights, membrane leak, and firing thresholds. During both training and inference, the analog pixel values of a HSI are directly applied to the input layer of the SNN without the need to convert to a spike-train. The reduced latency of our training technique combined with high activation sparsity yields significant improvements in computational efficiency. We evaluate our proposal using three HSI datasets on a 3-D and a 3-D/2-D hybrid convolutional architecture. We achieve overall accuracy, average accuracy, and kappa coefficient of 98.68%, 98.34%, and 98.20% respectively with 5 time steps (inference latency) and 6-bit weight quantization on the Indian Pines dataset. In particular, our models achieved accuracies similar to state-of-the-art (SOTA) with 560.6 and 44.8 times less compute energy on average over three HSI datasets than an iso-architecture full-precision and 6-bit quantized CNN, respectively.
Perceptually Motivated Method for Image Inpainting Comparison
Jul 14, 2019


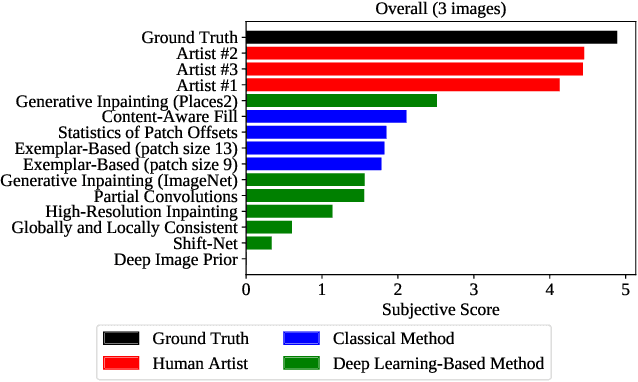
The field of automatic image inpainting has progressed rapidly in recent years, but no one has yet proposed a standard method of evaluating algorithms. This absence is due to the problem's challenging nature: image-inpainting algorithms strive for realism in the resulting images, but realism is a subjective concept intrinsic to human perception. Existing objective image-quality metrics provide a poor approximation of what humans consider more or less realistic. To improve the situation and to better organize both prior and future research in this field, we conducted a subjective comparison of nine state-of-the-art inpainting algorithms and propose objective quality metrics that exhibit high correlation with the results of our comparison.
Scenes and Surroundings: Scene Graph Generation using Relation Transformer
Jul 12, 2021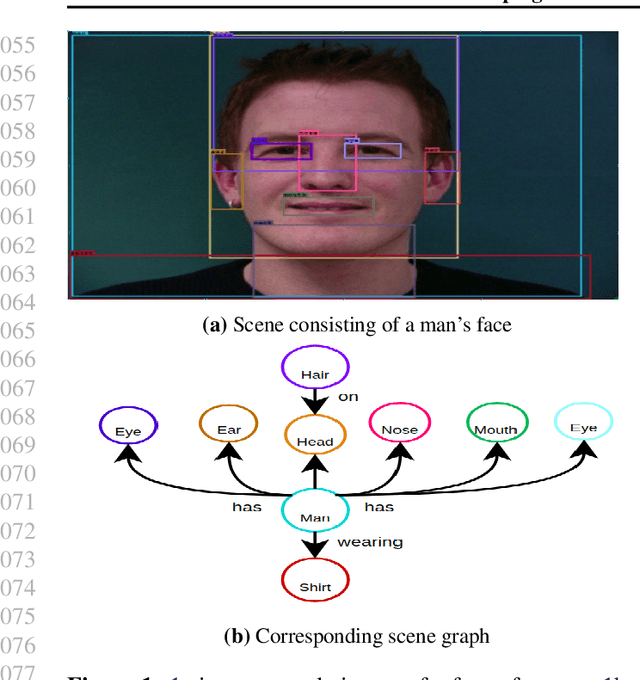
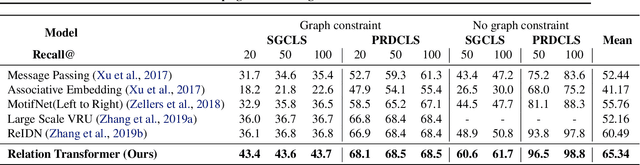
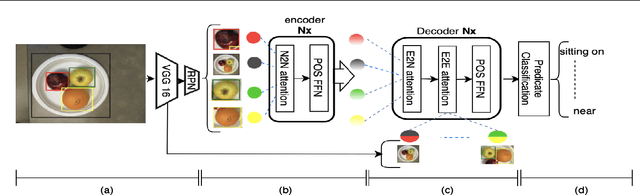
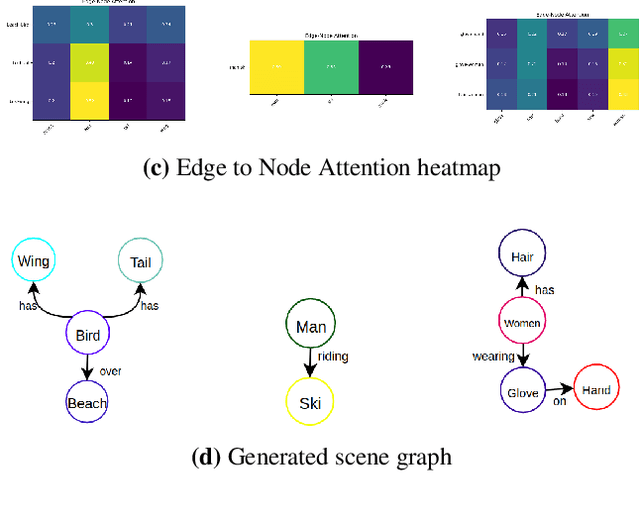
Identifying objects in an image and their mutual relationships as a scene graph leads to a deep understanding of image content. Despite the recent advancement in deep learning, the detection and labeling of visual object relationships remain a challenging task. This work proposes a novel local-context aware architecture named relation transformer, which exploits complex global objects to object and object to edge (relation) interactions. Our hierarchical multi-head attention-based approach efficiently captures contextual dependencies between objects and predicts their relationships. In comparison to state-of-the-art approaches, we have achieved an overall mean \textbf{4.85\%} improvement and a new benchmark across all the scene graph generation tasks on the Visual Genome dataset.
Interactive Analysis of CNN Robustness
Oct 14, 2021
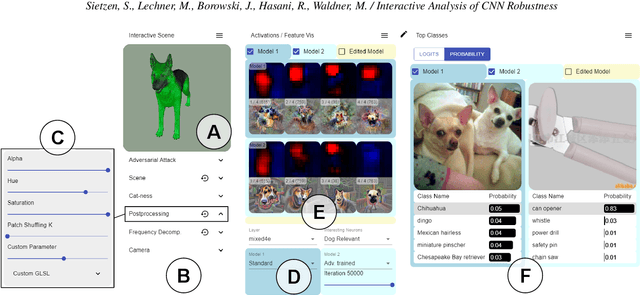

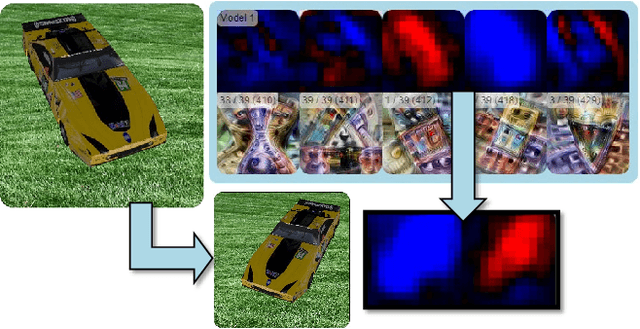
While convolutional neural networks (CNNs) have found wide adoption as state-of-the-art models for image-related tasks, their predictions are often highly sensitive to small input perturbations, which the human vision is robust against. This paper presents Perturber, a web-based application that allows users to instantaneously explore how CNN activations and predictions evolve when a 3D input scene is interactively perturbed. Perturber offers a large variety of scene modifications, such as camera controls, lighting and shading effects, background modifications, object morphing, as well as adversarial attacks, to facilitate the discovery of potential vulnerabilities. Fine-tuned model versions can be directly compared for qualitative evaluation of their robustness. Case studies with machine learning experts have shown that Perturber helps users to quickly generate hypotheses about model vulnerabilities and to qualitatively compare model behavior. Using quantitative analyses, we could replicate users' insights with other CNN architectures and input images, yielding new insights about the vulnerability of adversarially trained models.
CAR-Net: Unsupervised Co-Attention Guided Registration Network for Joint Registration and Structure Learning
Jun 11, 2021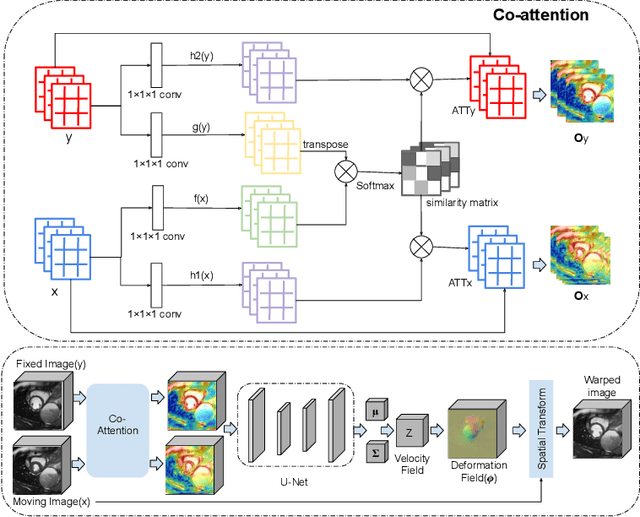
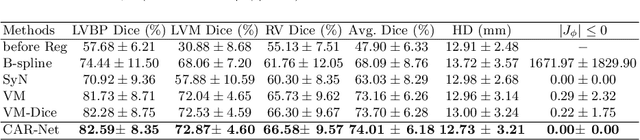
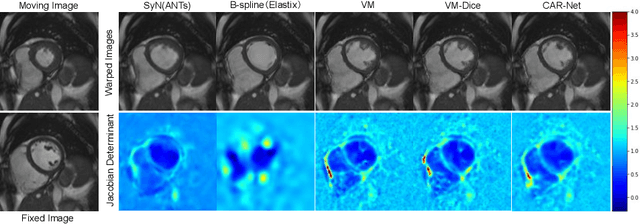
Image registration is a fundamental building block for various applications in medical image analysis. To better explore the correlation between the fixed and moving images and improve registration performance, we propose a novel deep learning network, Co-Attention guided Registration Network (CAR-Net). CAR-Net employs a co-attention block to learn a new representation of the inputs, which drives the registration of the fixed and moving images. Experiments on UK Biobank cardiac cine-magnetic resonance image data demonstrate that CAR-Net obtains higher registration accuracy and smoother deformation fields than state-of-the-art unsupervised registration methods, while achieving comparable or better registration performance than corresponding weakly-supervised variants. In addition, our approach can provide critical structural information of the input fixed and moving images simultaneously in a completely unsupervised manner.
Next-Best-View Estimation based on Deep Reinforcement Learning for Active Object Classification
Oct 14, 2021
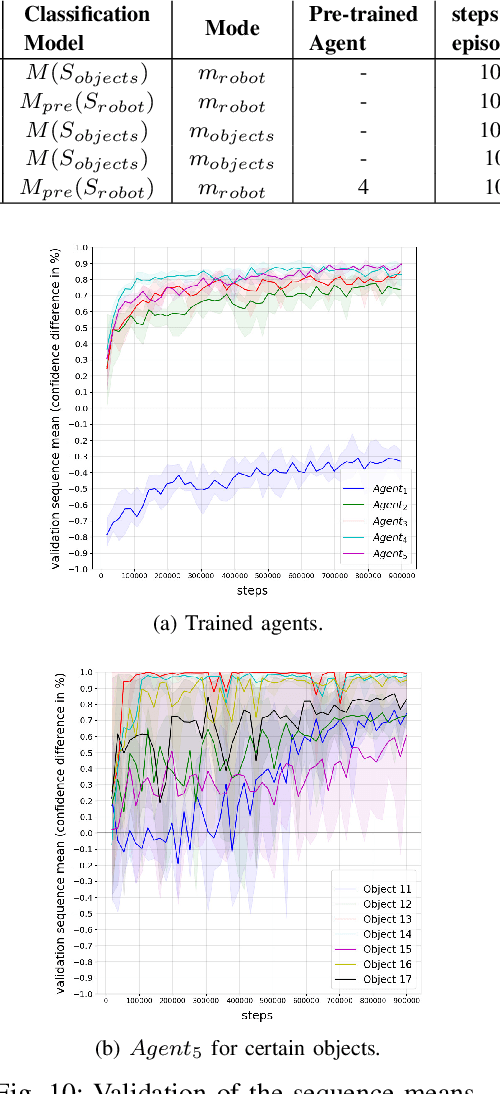
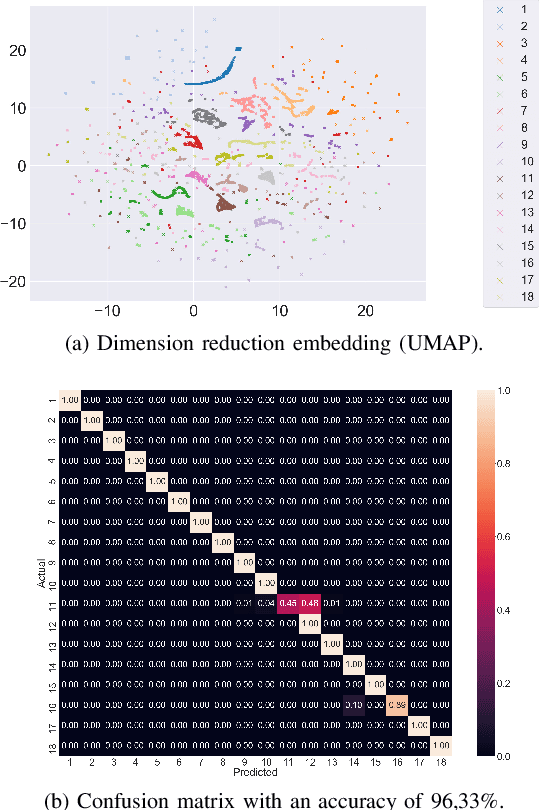
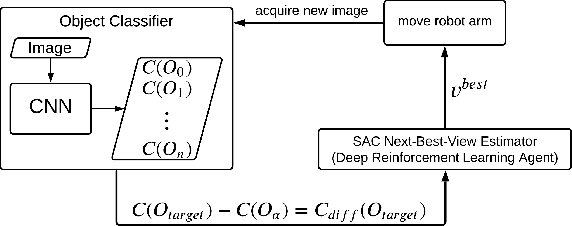
The presentation and analysis of image data from a single viewpoint are often not sufficient to solve a task. Several viewpoints are necessary to obtain more information. The next-best-view problem attempts to find the optimal viewpoint with the greatest information gain for the underlying task. In this work, a robot arm holds an object in its end-effector and searches for a sequence of next-best-view to explicitly identify the object. We use Soft Actor-Critic (SAC), a method of deep reinforcement learning, to learn these next-best-views for a specific set of objects. The evaluation shows that an agent can learn to determine an object pose to which the robot arm should move an object. This leads to a viewpoint that provides a more accurate prediction to distinguish such an object from other objects better. We make the code publicly available for the scientific community and for reproducibility.
Attention-based 3D Object Reconstruction from a Single Image
Aug 11, 2020Recently, learning-based approaches for 3D reconstruction from 2D images have gained popularity due to its modern applications, e.g., 3D printers, autonomous robots, self-driving cars, virtual reality, and augmented reality. The computer vision community has applied a great effort in developing functions to reconstruct the full 3D geometry of objects and scenes. However, to extract image features, they rely on convolutional neural networks, which are ineffective in capturing long-range dependencies. In this paper, we propose to substantially improve Occupancy Networks, a state-of-the-art method for 3D object reconstruction. For such we apply the concept of self-attention within the network's encoder in order to leverage complementary input features rather than those based on local regions, helping the encoder to extract global information. With our approach, we were capable of improving the original work in 5.05% of mesh IoU, 0.83% of Normal Consistency, and more than 10X the Chamfer-L1 distance. We also perform a qualitative study that shows that our approach was able to generate much more consistent meshes, confirming its increased generalization power over the current state-of-the-art.
* 8 pages, 4 figures, 3 tables