 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNTIRE 2026 Challenge on Video Saliency Prediction: Methods and Results
Apr 16, 2026This paper presents an overview of the NTIRE 2026 Challenge on Video Saliency Prediction. The goal of the challenge participants was to develop automatic saliency map prediction methods for the provided video sequences. The novel dataset of 2,000 diverse videos with an open license was prepared for this challenge. The fixations and corresponding saliency maps were collected using crowdsourced mouse tracking and contain viewing data from over 5,000 assessors. Evaluation was performed on a subset of 800 test videos using generally accepted quality metrics. The challenge attracted over 20 teams making submissions, and 7 teams passed the final phase with code review. All data used in this challenge is made publicly available - https://github.com/msu-video-group/NTIRE26_Saliency_Prediction.
NTIRE 2026 Challenge on Robust AI-Generated Image Detection in the Wild
Apr 13, 2026This paper presents an overview of the NTIRE 2026 Challenge on Robust AI-Generated Image Detection in the Wild, held in conjunction with the NTIRE workshop at CVPR 2026. The goal of this challenge was to develop detection models capable of distinguishing real images from generated ones in realistic scenarios: the images are often transformed (cropped, resized, compressed, blurred) for practical usage, and therefore, the detection models should be robust to such transformations. The challenge is based on a novel dataset consisting of 108,750 real and 185,750 AI-generated images from 42 generators comprising a large variety of open-source and closed-source models of various architectures, augmented with 36 image transformations. Methods were evaluated using ROC AUC on the full test set, including both transformed and untransformed images. A total of 511 participants registered, with 20 teams submitting valid final solutions. This report provides a comprehensive overview of the challenge, describes the proposed solutions, and can be used as a valuable reference for researchers and practitioners in increasing the robustness of the detection models to real-world transformations.
Temporally Coherent Person Matting Trained on Fake-Motion Dataset
Sep 10, 2021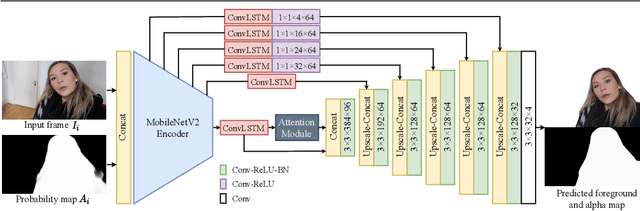
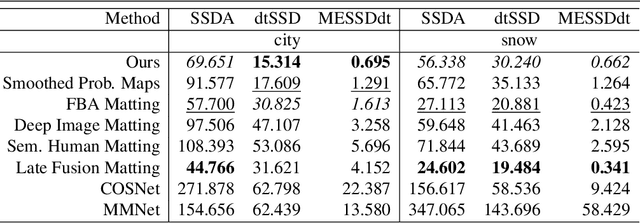
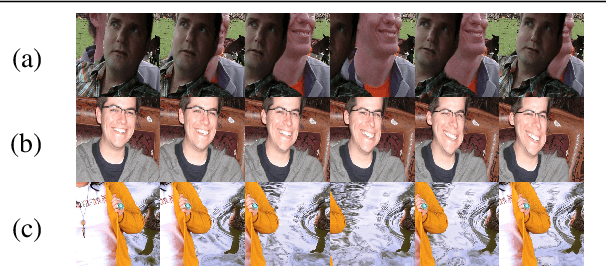
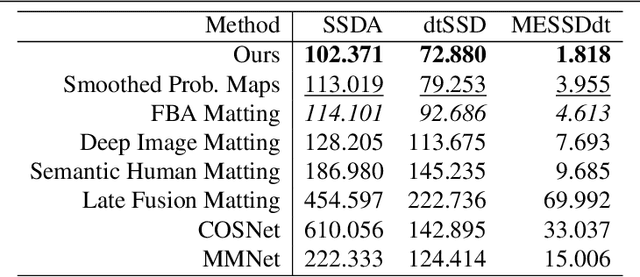
We propose a novel neural-network-based method to perform matting of videos depicting people that does not require additional user input such as trimaps. Our architecture achieves temporal stability of the resulting alpha mattes by using motion-estimation-based smoothing of image-segmentation algorithm outputs, combined with convolutional-LSTM modules on U-Net skip connections. We also propose a fake-motion algorithm that generates training clips for the video-matting network given photos with ground-truth alpha mattes and background videos. We apply random motion to photos and their mattes to simulate movement one would find in real videos and composite the result with the background clips. It lets us train a deep neural network operating on videos in an absence of a large annotated video dataset and provides ground-truth training-clip foreground optical flow for use in loss functions.
Deep Two-Stage High-Resolution Image Inpainting
Apr 27, 2021
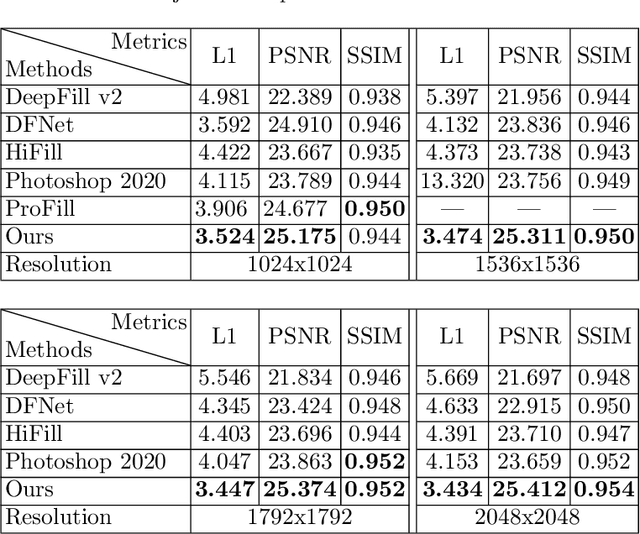
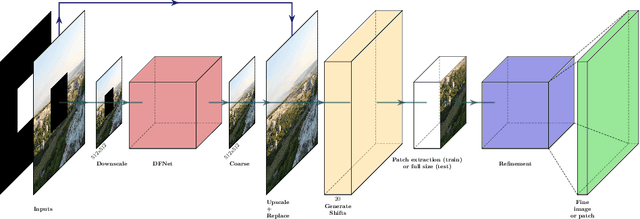
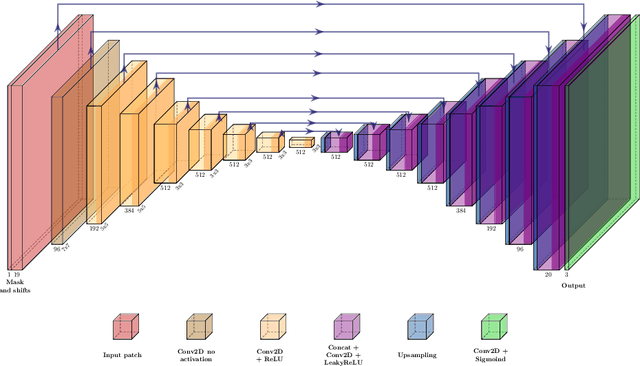
In recent years, the field of image inpainting has developed rapidly, learning based approaches show impressive results in the task of filling missing parts in an image. But most deep methods are strongly tied to the resolution of the images on which they were trained. A slight resolution increase leads to serious artifacts and unsatisfactory filling quality. These methods are therefore unsuitable for interactive image processing. In this article, we propose a method that solves the problem of inpainting arbitrary-size images. We also describe a way to better restore texture fragments in the filled area. For this, we propose to use information from neighboring pixels by shifting the original image in four directions. Moreover, this approach can work with existing inpainting models, making them almost resolution independent without the need for retraining. We also created a GIMP plugin that implements our technique. The plugin, code, and model weights are available at https://github.com/a-mos/High_Resolution_Image_Inpainting.
Perceptually Motivated Method for Image Inpainting Comparison
Jul 14, 2019


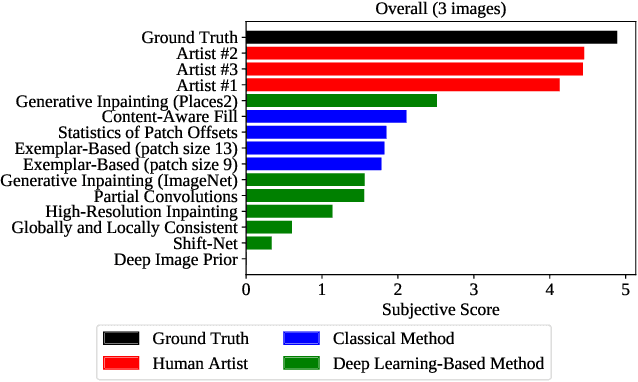
The field of automatic image inpainting has progressed rapidly in recent years, but no one has yet proposed a standard method of evaluating algorithms. This absence is due to the problem's challenging nature: image-inpainting algorithms strive for realism in the resulting images, but realism is a subjective concept intrinsic to human perception. Existing objective image-quality metrics provide a poor approximation of what humans consider more or less realistic. To improve the situation and to better organize both prior and future research in this field, we conducted a subjective comparison of nine state-of-the-art inpainting algorithms and propose objective quality metrics that exhibit high correlation with the results of our comparison.
Improving Video Compression With Deep Visual-Attention Models
Mar 19, 2019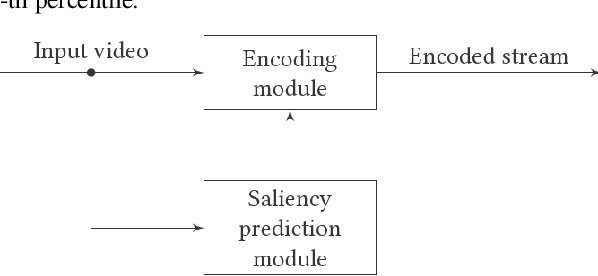
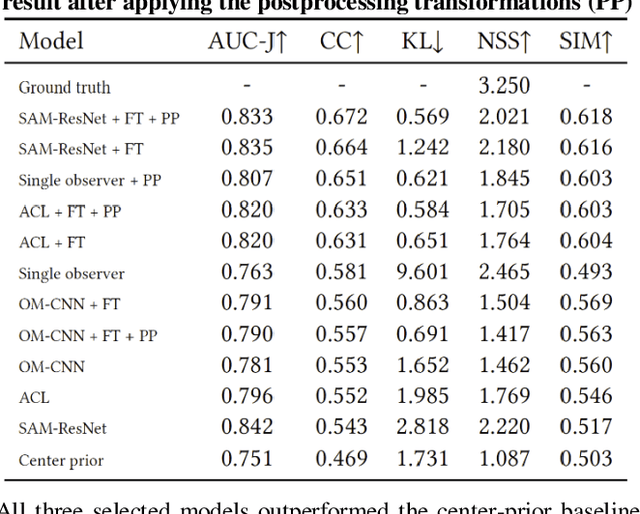

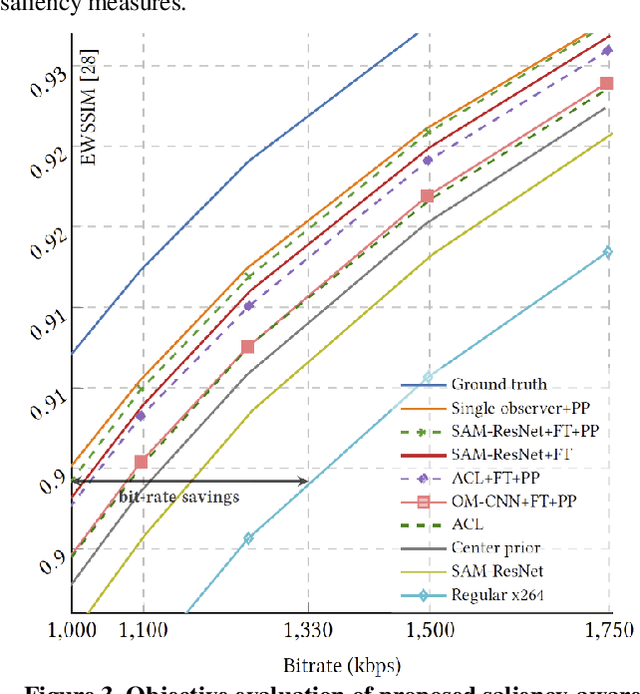
Recent advances in deep learning have markedly improved the quality of visual-attention modelling. In this work we apply these advances to video compression. We propose a compression method that uses a saliency model to adaptively compress frame areas in accordance with their predicted saliency. We selected three state-of-the-art saliency models, adapted them for video compression and analyzed their results. The analysis includes objective evaluation of the models as well as objective and subjective evaluation of the compressed videos. Our method, which is based on the x264 video codec, can produce videos with the same visual quality as regular x264, but it reduces the bitrate by 25% according to the objective evaluation and by 17% according to the subjective one. Also, both the subjective and objective evaluations demonstrate that saliency models can compete with gaze maps for a single observer. Our method can extend to most video bitstream formats and can improve video compression quality without requiring a switch to a new video encoding standard.