 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Evaluation of Deep Learning Topcoders Method for Neuron Individualization in Histological Macaque Brain Section
Nov 10, 2021

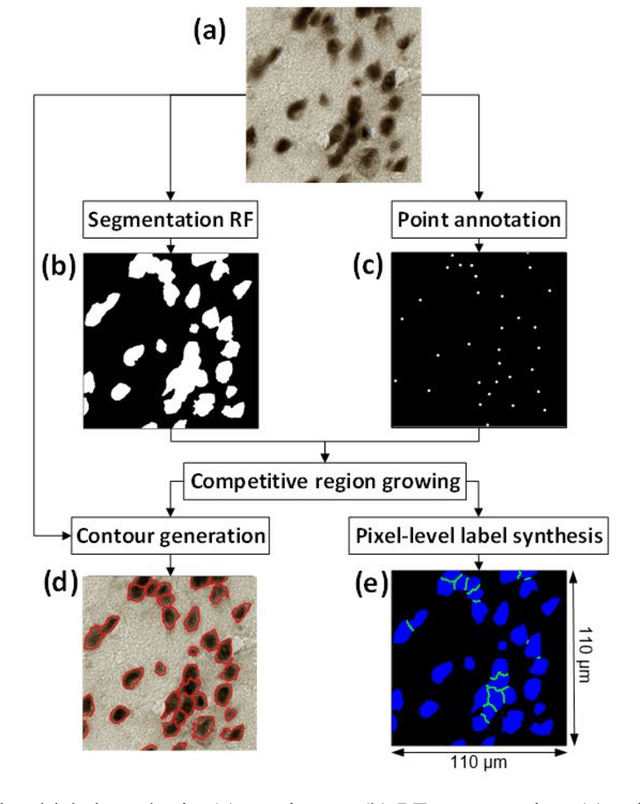

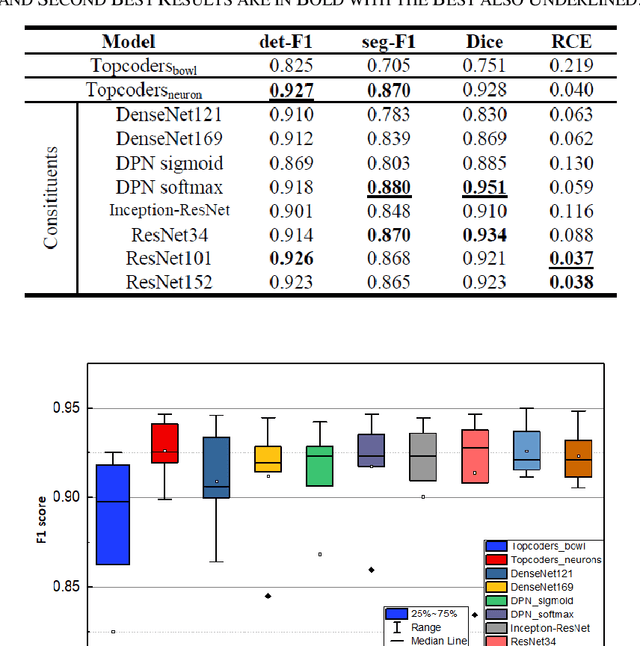
Cell individualization has a vital role in digital pathology image analysis. Deep Learning is considered as an efficient tool for instance segmentation tasks, including cell individualization. However, the precision of the Deep Learning model relies on massive unbiased dataset and manual pixel-level annotations, which is labor intensive. Moreover, most applications of Deep Learning have been developed for processing oncological data. To overcome these challenges, i) we established a pipeline to synthesize pixel-level labels with only point annotations provided; ii) we tested an ensemble Deep Learning algorithm to perform cell individualization on neurological data. Results suggest that the proposed method successfully segments neuronal cells in both object-level and pixel-level, with an average detection accuracy of 0.93.
FICGAN: Facial Identity Controllable GAN for De-identification
Oct 02, 2021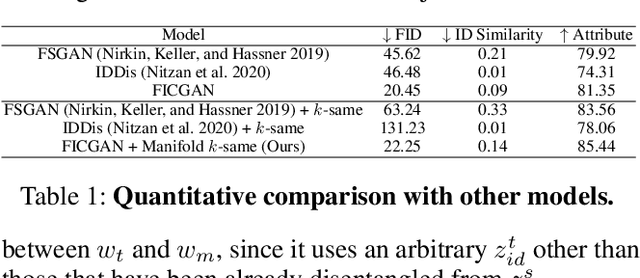
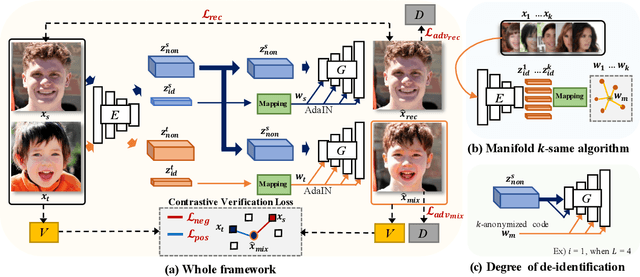


In this work, we present Facial Identity Controllable GAN (FICGAN) for not only generating high-quality de-identified face images with ensured privacy protection, but also detailed controllability on attribute preservation for enhanced data utility. We tackle the less-explored yet desired functionality in face de-identification based on the two factors. First, we focus on the challenging issue to obtain a high level of privacy protection in the de-identification task while uncompromising the image quality. Second, we analyze the facial attributes related to identity and non-identity and explore the trade-off between the degree of face de-identification and preservation of the source attributes for enhanced data utility. Based on the analysis, we develop Facial Identity Controllable GAN (FICGAN), an autoencoder-based conditional generative model that learns to disentangle the identity attributes from non-identity attributes on a face image. By applying the manifold k-same algorithm to satisfy k-anonymity for strengthened security, our method achieves enhanced privacy protection in de-identified face images. Numerous experiments demonstrate that our model outperforms others in various scenarios of face de-identification.
Centroid-UNet: Detecting Centroids in Aerial Images
Dec 13, 2021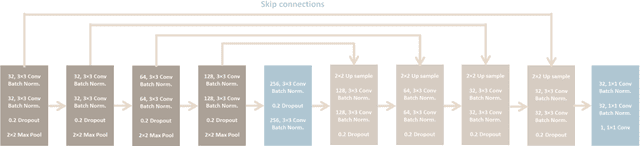
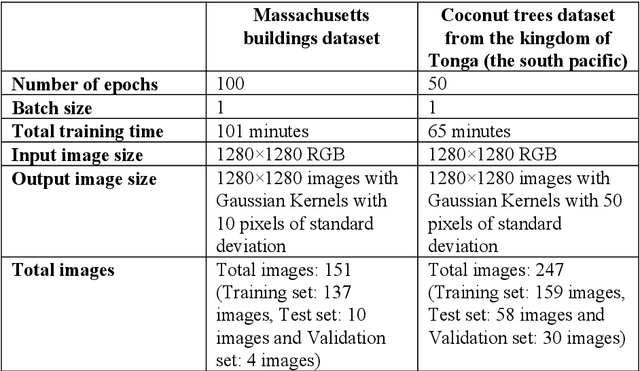

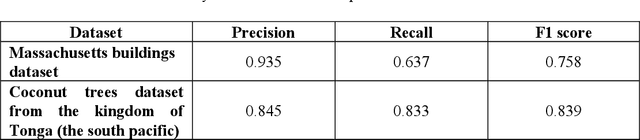
In many applications of aerial/satellite image analysis (remote sensing), the generation of exact shapes of objects is a cumbersome task. In most remote sensing applications such as counting objects requires only location estimation of objects. Hence, locating object centroids in aerial/satellite images is an easy solution for tasks where the object's exact shape is not necessary. Thus, this study focuses on assessing the feasibility of using deep neural networks for locating object centroids in satellite images. Name of our model is Centroid-UNet. The Centroid-UNet model is based on classic U-Net semantic segmentation architecture. We modified and adapted the U-Net semantic segmentation architecture into a centroid detection model preserving the simplicity of the original model. Furthermore, we have tested and evaluated our model with two case studies involving aerial/satellite images. Those two case studies are building centroid detection case study and coconut tree centroid detection case study. Our evaluation results have reached comparably good accuracy compared to other methods, and also offer simplicity. The code and models developed under this study are also available in the Centroid-UNet GitHub repository: https://github.com/gicait/centroid-unet
* Proccedings of the 42nd Asian Conference on Remote Sensing, 2021, Can Tho city, Vietnam
Handwritten Digit Recognition Using Improved Bounding Box Recognition Technique
Nov 10, 2021
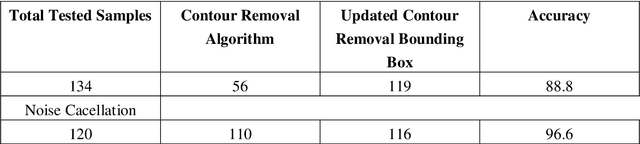
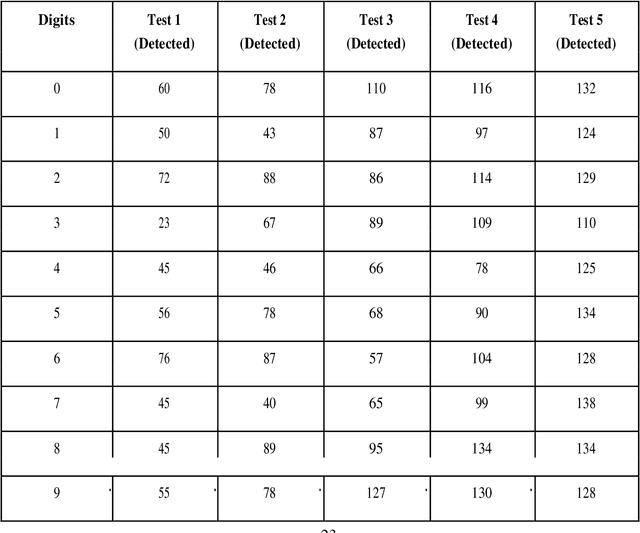
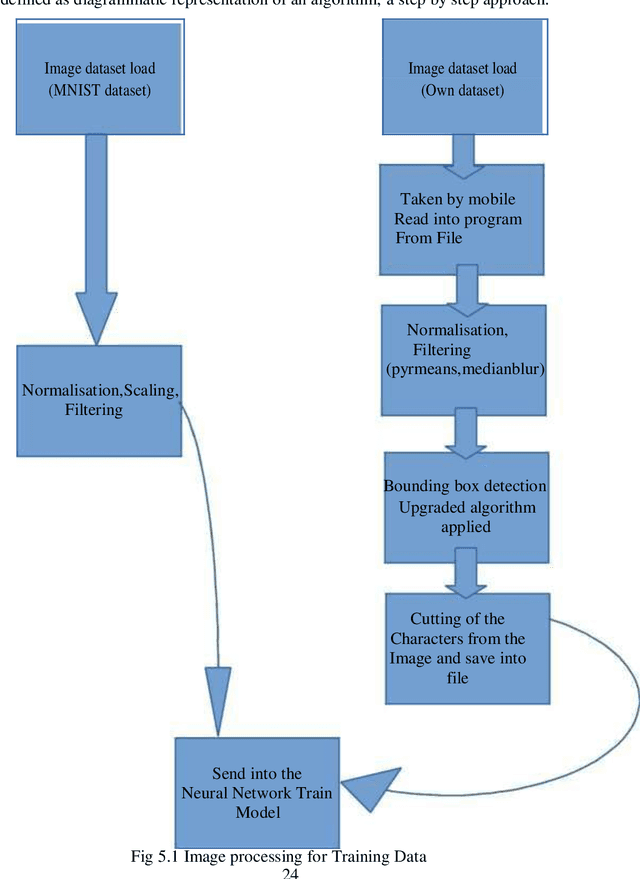
The project comes with the technique of OCR (Optical Character Recognition) which includes various research sides of computer science. The project is to take a picture of a character and process it up to recognize the image of that character like a human brain recognize the various digits. The project contains the deep idea of the Image Processing techniques and the big research area of machine learning and the building block of the machine learning called Neural Network. There are two different parts of the project. Training part comes with the idea of to train a child by giving various sets of similar characters but not the totally same and to say them the output of this is this. Like this idea one has to train the newly built neural network with so many characters. This part contains some new algorithm which is self-created and upgraded as the project need. The testing part contains the testing of a new dataset .This part always comes after the part of the training .At first one has to teach the child how to recognize the character .Then one has to take the test whether he has given right answer or not. If not, one has to train him harder by giving new dataset and new entries. Just like that one has to test the algorithm also. There are many parts of statistical modeling and optimization techniques which come into the project requiring a lot of modeling concept of statistics like optimizer technique and filtering process, that how the mathematics and prediction behind that filtering or the algorithms comes after or which result one actually needs to and ultimately for the prediction of a predictive model creation. Machine learning algorithm is built by concepts of prediction and programming.
Deep Multi-view Image Fusion for Soybean Yield Estimation in Breeding Applications Deep Multi-view Image Fusion for Soybean Yield Estimation in Breeding Applications
Nov 13, 2020
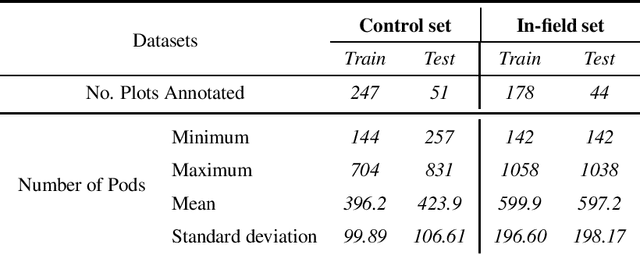
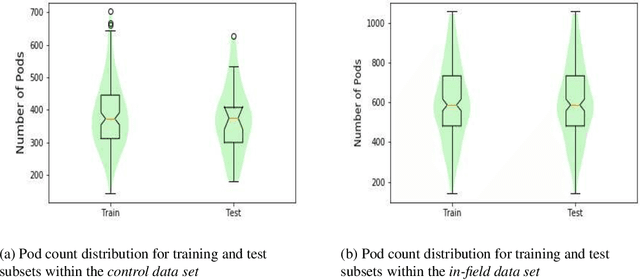
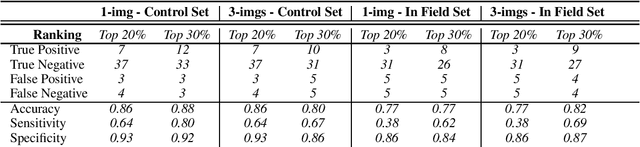
Reliable seed yield estimation is an indispensable step in plant breeding programs geared towards cultivar development in major row crops. The objective of this study is to develop a machine learning (ML) approach adept at soybean [\textit{Glycine max} L. (Merr.)] pod counting to enable genotype seed yield rank prediction from in-field video data collected by a ground robot. To meet this goal, we developed a multi-view image-based yield estimation framework utilizing deep learning architectures. Plant images captured from different angles were fused to estimate the yield and subsequently to rank soybean genotypes for application in breeding decisions. We used data from controlled imaging environment in field, as well as from plant breeding test plots in field to demonstrate the efficacy of our framework via comparing performance with manual pod counting and yield estimation. Our results demonstrate the promise of ML models in making breeding decisions with significant reduction of time and human effort, and opening new breeding methods avenues to develop cultivars.
Learning Fixed Points in Generative Adversarial Networks: From Image-to-Image Translation to Disease Detection and Localization
Aug 29, 2019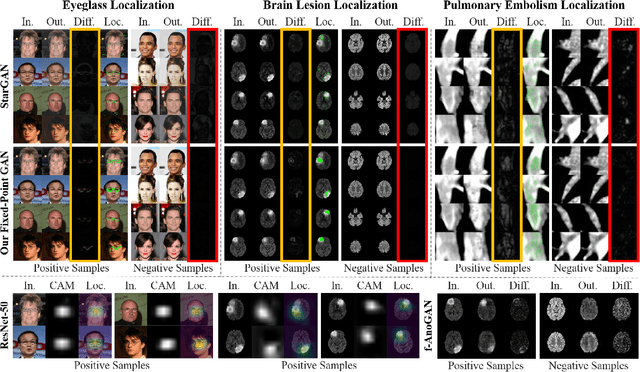

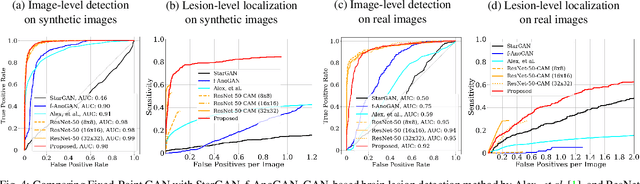
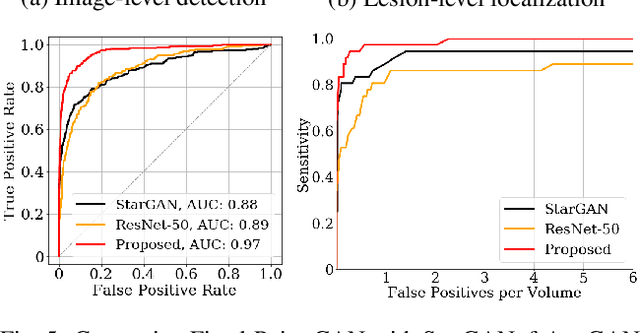
Generative adversarial networks (GANs) have ushered in a revolution in image-to-image translation. The development and proliferation of GANs raises an interesting question: can we train a GAN to remove an object, if present, from an image while otherwise preserving the image? Specifically, can a GAN "virtually heal" anyone by turning his medical image, with an unknown health status (diseased or healthy), into a healthy one, so that diseased regions could be revealed by subtracting those two images? Such a task requires a GAN to identify a minimal subset of target pixels for domain translation, an ability that we call fixed-point translation, which no GAN is equipped with yet. Therefore, we propose a new GAN, called Fixed-Point GAN, trained by (1) supervising same-domain translation through a conditional identity loss, and (2) regularizing cross-domain translation through revised adversarial, domain classification, and cycle consistency loss. Based on fixed-point translation, we further derive a novel framework for disease detection and localization using only image-level annotation. Qualitative and quantitative evaluations demonstrate that the proposed method outperforms the state of the art in multi-domain image-to-image translation and that it surpasses predominant weakly-supervised localization methods in both disease detection and localization. Implementation is available at https://github.com/jlianglab/Fixed-Point-GAN.
Learning Interpretable Concept Groups in CNNs
Sep 21, 2021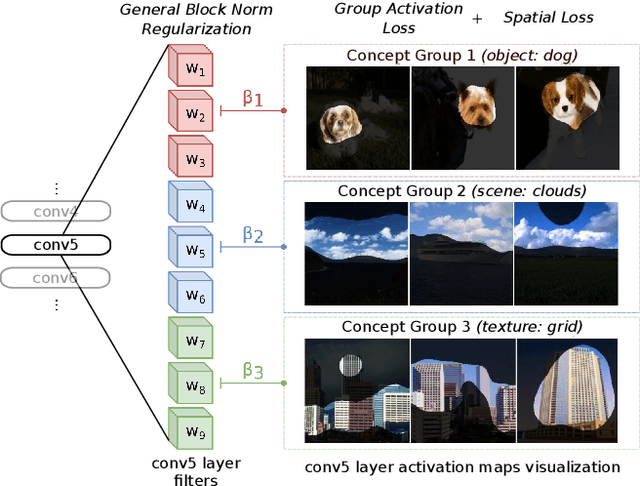
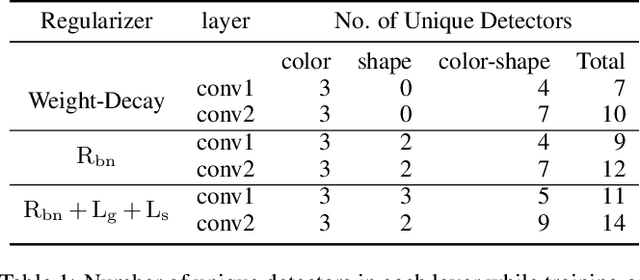
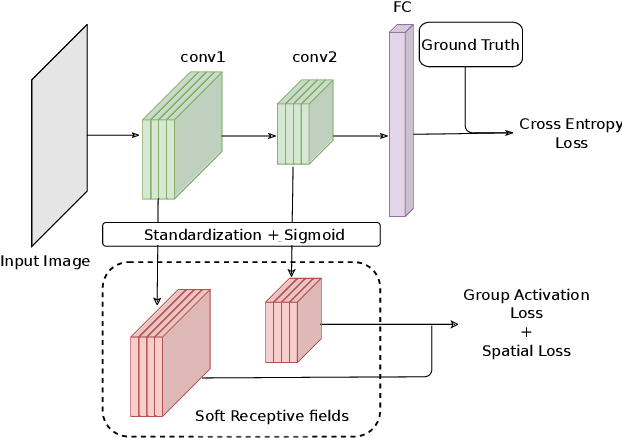
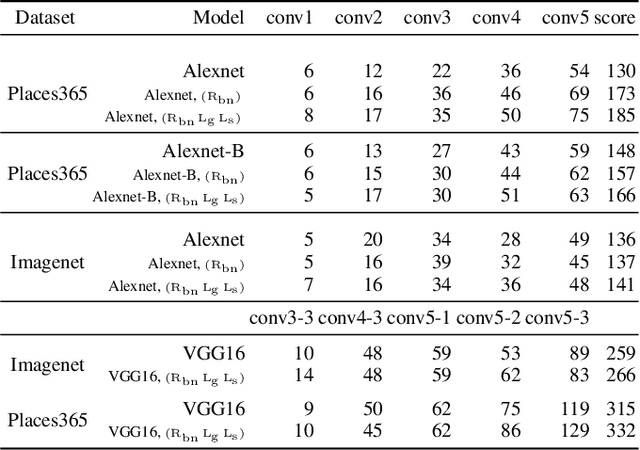
We propose a novel training methodology -- Concept Group Learning (CGL) -- that encourages training of interpretable CNN filters by partitioning filters in each layer into concept groups, each of which is trained to learn a single visual concept. We achieve this through a novel regularization strategy that forces filters in the same group to be active in similar image regions for a given layer. We additionally use a regularizer to encourage a sparse weighting of the concept groups in each layer so that a few concept groups can have greater importance than others. We quantitatively evaluate CGL's model interpretability using standard interpretability evaluation techniques and find that our method increases interpretability scores in most cases. Qualitatively we compare the image regions that are most active under filters learned using CGL versus filters learned without CGL and find that CGL activation regions more strongly concentrate around semantically relevant features.
Spectral Complexity-scaled Generalization Bound of Complex-valued Neural Networks
Dec 07, 2021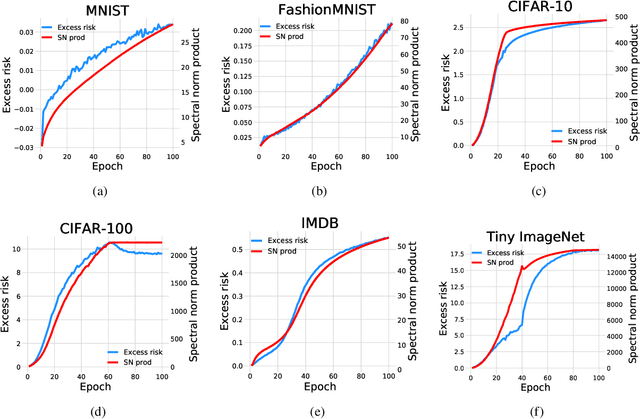
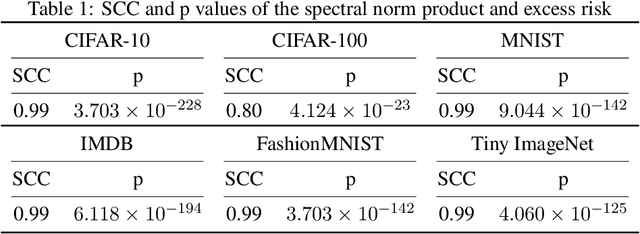
Complex-valued neural networks (CVNNs) have been widely applied to various fields, especially signal processing and image recognition. However, few works focus on the generalization of CVNNs, albeit it is vital to ensure the performance of CVNNs on unseen data. This paper is the first work that proves a generalization bound for the complex-valued neural network. The bound scales with the spectral complexity, the dominant factor of which is the spectral norm product of weight matrices. Further, our work provides a generalization bound for CVNNs when training data is sequential, which is also affected by the spectral complexity. Theoretically, these bounds are derived via Maurey Sparsification Lemma and Dudley Entropy Integral. Empirically, we conduct experiments by training complex-valued convolutional neural networks on different datasets: MNIST, FashionMNIST, CIFAR-10, CIFAR-100, Tiny ImageNet, and IMDB. Spearman's rank-order correlation coefficients and the corresponding p values on these datasets give strong proof that the spectral complexity of the network, measured by the weight matrices spectral norm product, has a statistically significant correlation with the generalization ability.
Contact-Rich Manipulation of a Flexible Object based on Deep Predictive Learning using Vision and Tactility
Dec 13, 2021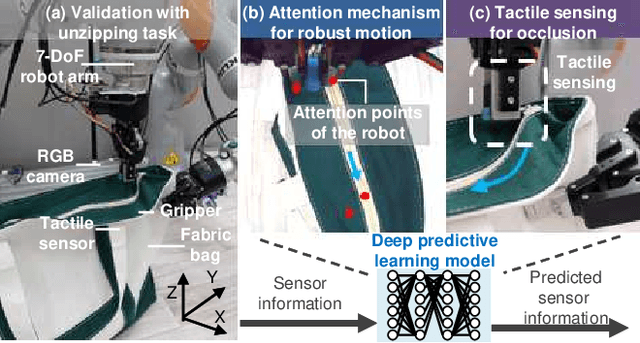
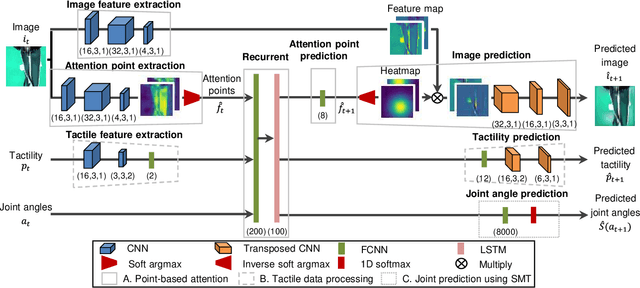

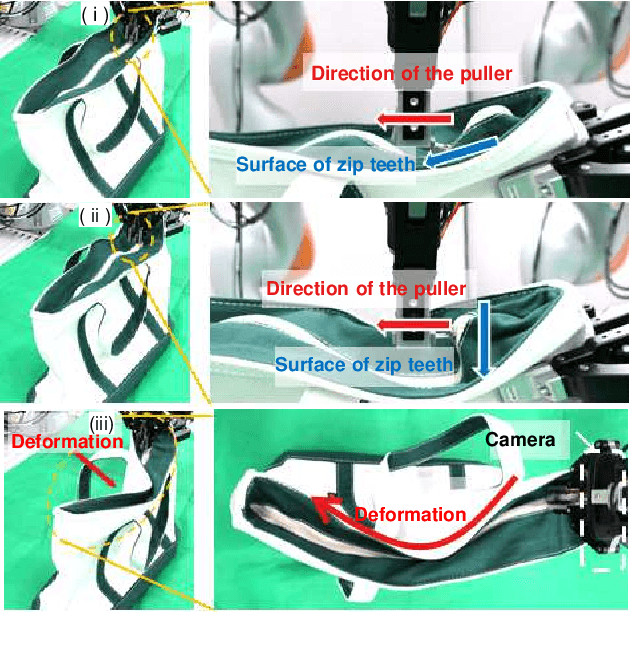
We achieved contact-rich flexible object manipulation, which was difficult to control with vision alone. In the unzipping task we chose as a validation task, the gripper grasps the puller, which hides the bag state such as the direction and amount of deformation behind it, making it difficult to obtain information to perform the task by vision alone. Additionally, the flexible fabric bag state constantly changes during operation, so the robot needs to dynamically respond to the change. However, the appropriate robot behavior for all bag states is difficult to prepare in advance. To solve this problem, we developed a model that can perform contact-rich flexible object manipulation by real-time prediction of vision with tactility. We introduced a point-based attention mechanism for extracting image features, softmax transformation for predicting motions, and convolutional neural network for extracting tactile features. The results of experiments using a real robot arm revealed that our method can realize motions responding to the deformation of the bag while reducing the load on the zipper. Furthermore, using tactility improved the success rate from 56.7% to 93.3% compared with vision alone, demonstrating the effectiveness and high performance of our method.
Deep Level Set for Box-supervised Instance Segmentation in Aerial Images
Dec 07, 2021
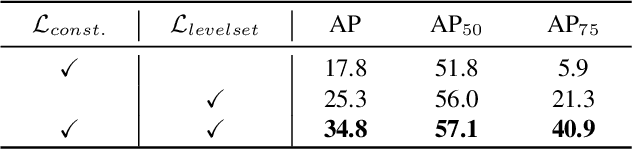
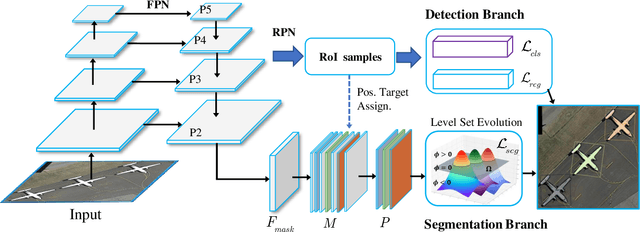
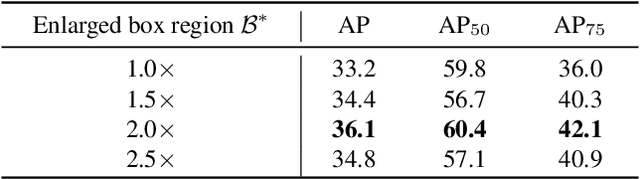
Box-supervised instance segmentation has recently attracted lots of research efforts while little attention is received in aerial image domain. In contrast to the general object collections, aerial objects have large intra-class variances and inter-class similarity with complex background. Moreover, there are many tiny objects in the high-resolution satellite images. This makes the recent pairwise affinity modeling method inevitably to involve the noisy supervision with the inferior results. To tackle these problems, we propose a novel aerial instance segmentation approach, which drives the network to learn a series of level set functions for the aerial objects with only box annotations in an end-to-end fashion. Instead of learning the pairwise affinity, the level set method with the carefully designed energy functions treats the object segmentation as curve evolution, which is able to accurately recover the object's boundaries and prevent the interference from the indistinguishable background and similar objects. The experimental results demonstrate that the proposed approach outperforms the state-of-the-art box-supervised instance segmentation methods. The source code is available at https://github.com/LiWentomng/boxlevelset.