 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLighting-aware Unified Model for Instance Segmentation
May 19, 2026Foundation models like the Segment Anything Model (SAM) demonstrate impressive zero-shot generalization but frequently degrade under diverse real-world illumination, particularly for instance segmentation. In this work, we address this limitation by developing \textit{Lighting Convolutional-Attention (\lca{})}, an adapter module that enhances segmentation robustness without fine-tuning the heavy backbone. \lca{} employs a dual-branch architecture to process RGB features alongside contrast maps, enabling physically motivated sensitivity to structural changes rather than illumination artifacts. We optimize \lca{} through a pairwise training strategy, introducing a targeted loss term that explicitly penalizes discrepancies between clean images and their corresponding illumination variants. To evaluate and support this architecture, we conduct a comprehensive empirical study across multiple existing benchmarks and present a novel Unity-based synthetic dataset specifically designed to accurately replicate complex real-world lighting conditions. Extensive experimental results demonstrate that our approach successfully bridges the domain gap, delivering superior lighting-robust segmentation.
COOPO: Cyclic Offline-Online Policy Optimization Algorithm
May 18, 2026Offline reinforcement learning struggles with distributional shift and constrained performance due to static dataset limitations, while online RL demands prohibitive environment interactions. The recent advent of hybrid offline-to-online methods bridges these domains but suffers from distribution drift during transitions and catastrophic forgetting of offline knowledge. We introduce COOPO (Cyclic Offline-Online Policy Optimization), a generalized framework that repeatedly cycles between constrained offline training and online fine-tuning. Each cycle first anchors the policy to the dataset via KL-regularized advantage-weighted offline updates to minimize distributional shift and then fine-tunes it online using any policy optimization for stable exploration. Crucially, periodically returning to offline training eliminates forgetting and drift while maximizing dataset reuse. The cyclic behavior also helps reduce the online environment interactions. Theoretically, COOPO achieves better online sample efficiency, surpassing pure online RL, with guaranteed monotonic improvement under standard coverage assumptions. Extensive D4RL benchmarks demonstrate COOPO reduces online interactions versus state-of-the-art hybrids while improving final returns, maintaining robustness across diverse offline algorithms and online optimizers. This looped synergy sets new efficiency and performance standards for adaptive RL.
TabQL: In-Context Q-Learning with Tabular Foundation Models
May 18, 2026We propose Tabular Q-Learning (TabQL), a reinforcement learning framework that replaces the conventional parametric Q-network in Deep Q-Learning (DQN) with a tabular foundation model endowed with in-context learning capabilities. The key idea is to represent Q-values through a sequence-to-sequence foundation model operating over a tabularized representation of state-action-Q-value tuples, enabling rapid adaptation from limited online interaction by conditioning on recent experience. TabQL departs from classical DQN by leveraging (i) zero- or few-shot Q-value inference via in-context updates, and (ii) a warm-up phase using standard DQN to bootstrap high-quality context. Particularly, to enhance the context quality, new transitions are generated by executing actions output by TabQL with predicted Q values from DQN. We formalize TabQL, analyze its convergence and sample complexity under mild assumptions, and show that TabQL interpolates between vanilla Q-learning and DQN with in-context learning. Our analysis demonstrates that TabQL achieves improved efficiency compared to DQN by amortizing Bellman updates through in-context learning. Extensive numerical experiments with several benchmarks showcase the effectiveness and efficacy of the proposed TabQL.
LexiSafe: Offline Safe Reinforcement Learning with Lexicographic Safety-Reward Hierarchy
Feb 19, 2026Offline safe reinforcement learning (RL) is increasingly important for cyber-physical systems (CPS), where safety violations during training are unacceptable and only pre-collected data are available. Existing offline safe RL methods typically balance reward-safety tradeoffs through constraint relaxation or joint optimization, but they often lack structural mechanisms to prevent safety drift. We propose LexiSafe, a lexicographic offline RL framework designed to preserve safety-aligned behavior. We first develop LexiSafe-SC, a single-cost formulation for standard offline safe RL, and derive safety-violation and performance-suboptimality bounds that together yield sample-complexity guarantees. We then extend the framework to hierarchical safety requirements with LexiSafe-MC, which supports multiple safety costs and admits its own sample-complexity analysis. Empirically, LexiSafe demonstrates reduced safety violations and improved task performance compared to constrained offline baselines. By unifying lexicographic prioritization with structural bias, LexiSafe offers a practical and theoretically grounded approach for safety-critical CPS decision-making.
LCLA: Language-Conditioned Latent Alignment for Vision-Language Navigation
Feb 07, 2026We propose LCLA (Language-Conditioned Latent Alignment), a framework for vision-language navigation that learns modular perception-action interfaces by aligning sensory observations to a latent representation of an expert policy. The expert is first trained with privileged state information, inducing a latent space sufficient for control, after which its latent interface and action head are frozen. A lightweight adapter is then trained to map raw visual-language observations, via a frozen vision-language model, into the expert's latent space, reducing the problem of visuomotor learning to supervised latent alignment rather than end-to-end policy optimization. This decoupling enforces a stable contract between perception and control, enabling expert behavior to be reused across sensing modalities and environmental variations. We instantiate LCLA and evaluate it on a vision-language indoor navigation task, where aligned latent spaces yield strong in-distribution performance and robust zero-shot generalization to unseen environments, lighting conditions, and viewpoints while remaining lightweight at inference time.
Reinforcement Learning for Autonomous Point-to-Point UAV Navigation
Sep 17, 2025Unmanned Aerial Vehicles (UAVs) are increasingly used in automated inspection, delivery, and navigation tasks that require reliable autonomy. This project develops a reinforcement learning (RL) approach to enable a single UAV to autonomously navigate between predefined points without manual intervention. The drone learns navigation policies through trial-and-error interaction, using a custom reward function that encourages goal-reaching efficiency while penalizing collisions and unsafe behavior. The control system integrates ROS with a Gym-compatible training environment, enabling flexible deployment and testing. After training, the learned policy is deployed on a real UAV platform and evaluated under practical conditions. Results show that the UAV can successfully perform autonomous navigation with minimal human oversight, demonstrating the viability of RL-based control for point-to-point drone operations in real-world scenarios.
ProFusion: 3D Reconstruction of Protein Complex Structures from Multi-view AFM Images
Sep 17, 2025



AI-based in silico methods have improved protein structure prediction but often struggle with large protein complexes (PCs) involving multiple interacting proteins due to missing 3D spatial cues. Experimental techniques like Cryo-EM are accurate but costly and time-consuming. We present ProFusion, a hybrid framework that integrates a deep learning model with Atomic Force Microscopy (AFM), which provides high-resolution height maps from random orientations, naturally yielding multi-view data for 3D reconstruction. However, generating a large-scale AFM imaging data set sufficient to train deep learning models is impractical. Therefore, we developed a virtual AFM framework that simulates the imaging process and generated a dataset of ~542,000 proteins with multi-view synthetic AFM images. We train a conditional diffusion model to synthesize novel views from unposed inputs and an instance-specific Neural Radiance Field (NeRF) model to reconstruct 3D structures. Our reconstructed 3D protein structures achieve an average Chamfer Distance within the AFM imaging resolution, reflecting high structural fidelity. Our method is extensively validated on experimental AFM images of various PCs, demonstrating strong potential for accurate, cost-effective protein complex structure prediction and rapid iterative validation using AFM experiments.
Balancing Utility and Privacy: Dynamically Private SGD with Random Projection
Sep 11, 2025Stochastic optimization is a pivotal enabler in modern machine learning, producing effective models for various tasks. However, several existing works have shown that model parameters and gradient information are susceptible to privacy leakage. Although Differentially Private SGD (DPSGD) addresses privacy concerns, its static noise mechanism impacts the error bounds for model performance. Additionally, with the exponential increase in model parameters, efficient learning of these models using stochastic optimizers has become more challenging. To address these concerns, we introduce the Dynamically Differentially Private Projected SGD (D2P2-SGD) optimizer. In D2P2-SGD, we combine two important ideas: (i) dynamic differential privacy (DDP) with automatic gradient clipping and (ii) random projection with SGD, allowing dynamic adjustment of the tradeoff between utility and privacy of the model. It exhibits provably sub-linear convergence rates across different objective functions, matching the best available rate. The theoretical analysis further suggests that DDP leads to better utility at the cost of privacy, while random projection enables more efficient model learning. Extensive experiments across diverse datasets show that D2P2-SGD remarkably enhances accuracy while maintaining privacy. Our code is available here.
Data-driven Kinematic Modeling in Soft Robots: System Identification and Uncertainty Quantification
Jul 10, 2025

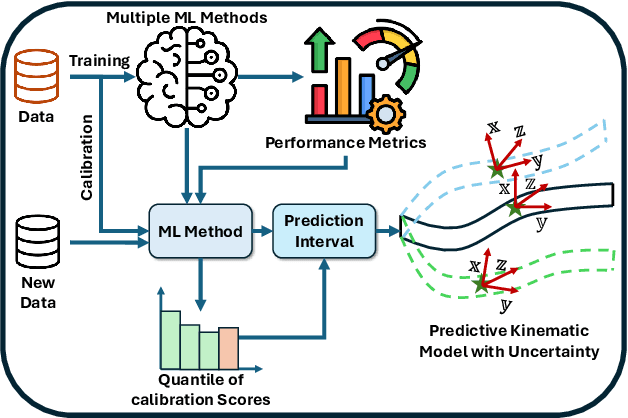

Precise kinematic modeling is critical in calibration and controller design for soft robots, yet remains a challenging issue due to their highly nonlinear and complex behaviors. To tackle the issue, numerous data-driven machine learning approaches have been proposed for modeling nonlinear dynamics. However, these models suffer from prediction uncertainty that can negatively affect modeling accuracy, and uncertainty quantification for kinematic modeling in soft robots is underexplored. In this work, using limited simulation and real-world data, we first investigate multiple linear and nonlinear machine learning models commonly used for kinematic modeling of soft robots. The results reveal that nonlinear ensemble methods exhibit the most robust generalization performance. We then develop a conformal kinematic modeling framework for soft robots by utilizing split conformal prediction to quantify predictive position uncertainty, ensuring distribution-free prediction intervals with a theoretical guarantee.
Can Pretrained Vision-Language Embeddings Alone Guide Robot Navigation?
Jun 17, 2025



Foundation models have revolutionized robotics by providing rich semantic representations without task-specific training. While many approaches integrate pretrained vision-language models (VLMs) with specialized navigation architectures, the fundamental question remains: can these pretrained embeddings alone successfully guide navigation without additional fine-tuning or specialized modules? We present a minimalist framework that decouples this question by training a behavior cloning policy directly on frozen vision-language embeddings from demonstrations collected by a privileged expert. Our approach achieves a 74% success rate in navigation to language-specified targets, compared to 100% for the state-aware expert, though requiring 3.2 times more steps on average. This performance gap reveals that pretrained embeddings effectively support basic language grounding but struggle with long-horizon planning and spatial reasoning. By providing this empirical baseline, we highlight both the capabilities and limitations of using foundation models as drop-in representations for embodied tasks, offering critical insights for robotics researchers facing practical design tradeoffs between system complexity and performance in resource-constrained scenarios. Our code is available at https://github.com/oadamharoon/text2nav