 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Cuid: A new study of perceived image quality and its subjective assessment
Sep 28, 2020
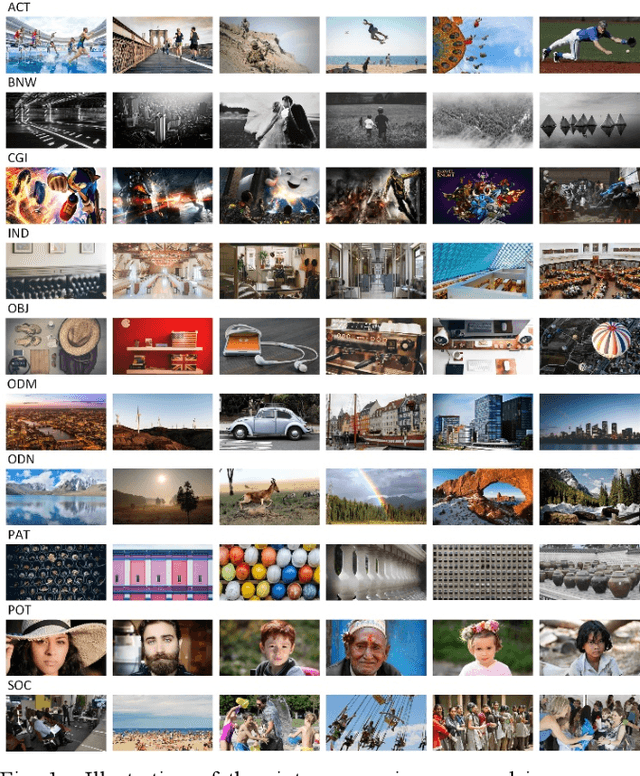


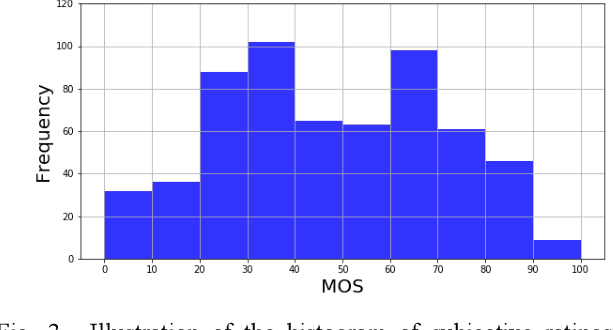
Research on image quality assessment (IQA) remains limited mainly due to our incomplete knowledge about human visual perception. Existing IQA algorithms have been designed or trained with insufficient subjective data with a small degree of stimulus variability. This has led to challenges for those algorithms to handle complexity and diversity of real-world digital content. Perceptual evidence from human subjects serves as a grounding for the development of advanced IQA algorithms. It is thus critical to acquire reliable subjective data with controlled perception experiments that faithfully reflect human behavioural responses to distortions in visual signals. In this paper, we present a new study of image quality perception where subjective ratings were collected in a controlled lab environment. We investigate how quality perception is affected by a combination of different categories of images and different types and levels of distortions. The database will be made publicly available to facilitate calibration and validation of IQA algorithms.
Deep Ultrasound Denoising Without Clean Data
Jan 07, 2022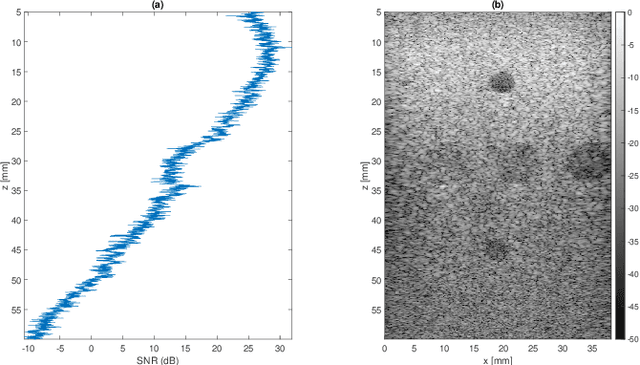
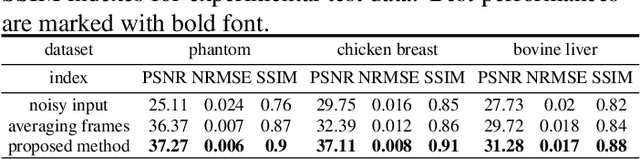

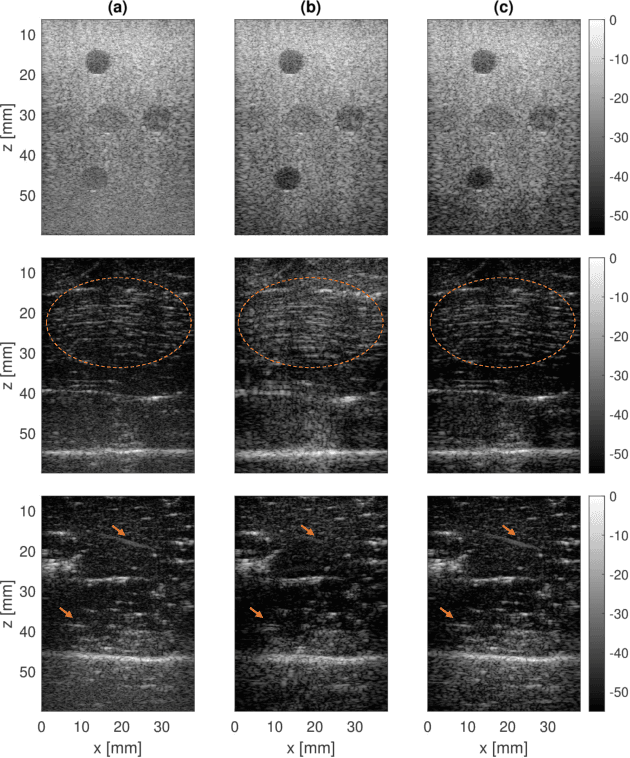
On one hand, the transmitted ultrasound beam gets attenuated as propagates through the tissue. On the other hand, the received Radio-Frequency (RF) data contains an additive Gaussian noise which is brought about by the acquisition card and the sensor noise. These two factors lead to a decreasing Signal to Noise Ratio (SNR) in the RF data with depth, effectively rendering deep regions of B-Mode images highly unreliable. There are three common approaches to mitigate this problem. First, increasing the power of transmitted beam which is limited by safety threshold. Averaging consecutive frames is the second option which not only reduces the framerate but also is not applicable for moving targets. And third, reducing the transmission frequency, which deteriorates spatial resolution. Many deep denoising techniques have been developed, but they often require clean data for training the model, which is usually only available in simulated images. Herein, a deep noise reduction approach is proposed which does not need clean training target. The model is constructed between noisy input-output pairs, and the training process interestingly converges to the clean image that is the average of noisy pairs. Experimental results on real phantom as well as ex vivo data confirm the efficacy of the proposed method for noise cancellation.
Box-Adapt: Domain-Adaptive Medical Image Segmentation using Bounding BoxSupervision
Aug 28, 2021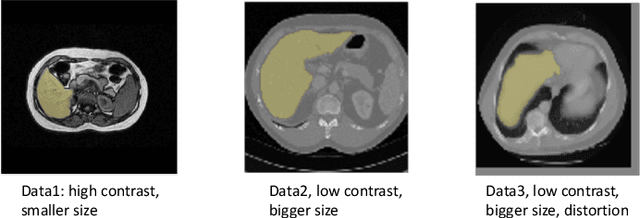

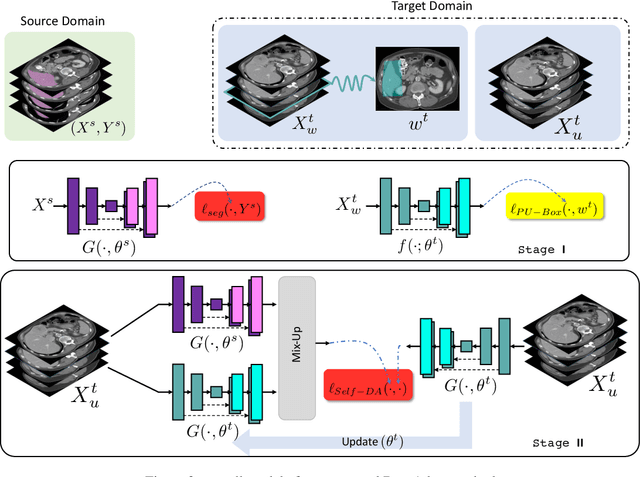
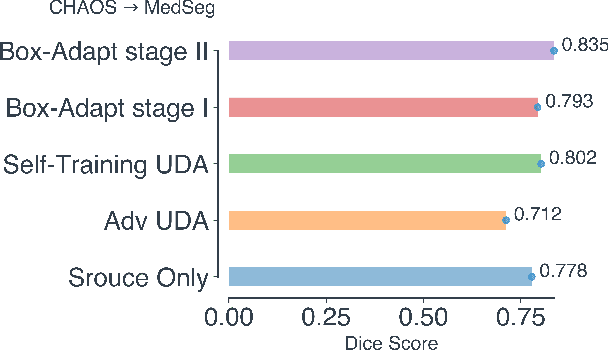
Deep learning has achieved remarkable success in medicalimage segmentation, but it usually requires a large numberof images labeled with fine-grained segmentation masks, andthe annotation of these masks can be very expensive andtime-consuming. Therefore, recent methods try to use un-supervised domain adaptation (UDA) methods to borrow in-formation from labeled data from other datasets (source do-mains) to a new dataset (target domain). However, due tothe absence of labels in the target domain, the performance ofUDA methods is much worse than that of the fully supervisedmethod. In this paper, we propose a weakly supervised do-main adaptation setting, in which we can partially label newdatasets with bounding boxes, which are easier and cheaperto obtain than segmentation masks. Accordingly, we proposea new weakly-supervised domain adaptation method calledBox-Adapt, which fully explores the fine-grained segmenta-tion mask in the source domain and the weak bounding boxin the target domain. Our Box-Adapt is a two-stage methodthat first performs joint training on the source and target do-mains, and then conducts self-training with the pseudo-labelsof the target domain. We demonstrate the effectiveness of ourmethod in the liver segmentation task. Weakly supervised do-main adaptation
TextCaps: a Dataset for Image Captioning with Reading Comprehension
Mar 24, 2020
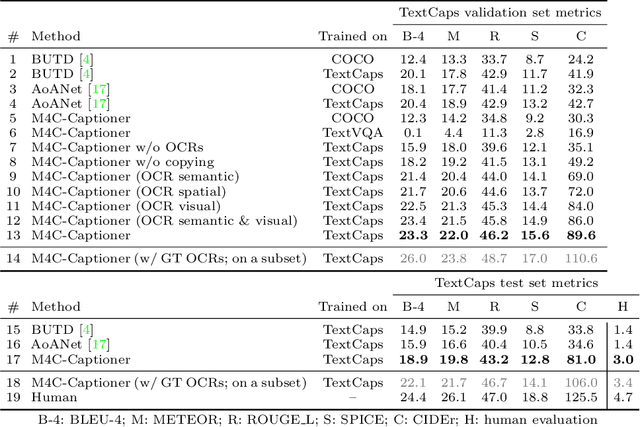

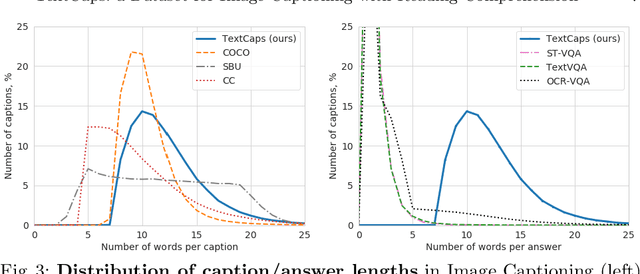
Image descriptions can help visually impaired people to quickly understand the image content. While we made significant progress in automatically describing images and optical character recognition, current approaches are unable to include written text in their descriptions, although text is omnipresent in human environments and frequently critical to understand our surroundings. To study how to comprehend text in the context of an image we collect a novel dataset, TextCaps, with 145k captions for 28k images. Our dataset challenges a model to recognize text, relate it to its visual context, and decide what part of the text to copy or paraphrase, requiring spatial, semantic, and visual reasoning between multiple text tokens and visual entities, such as objects. We study baselines and adapt existing approaches to this new task, which we refer to as image captioning with reading comprehension. Our analysis with automatic and human studies shows that our new TextCaps dataset provides many new technical challenges over previous datasets.
PANet: Perspective-Aware Network with Dynamic Receptive Fields and Self-Distilling Supervision for Crowd Counting
Oct 31, 2021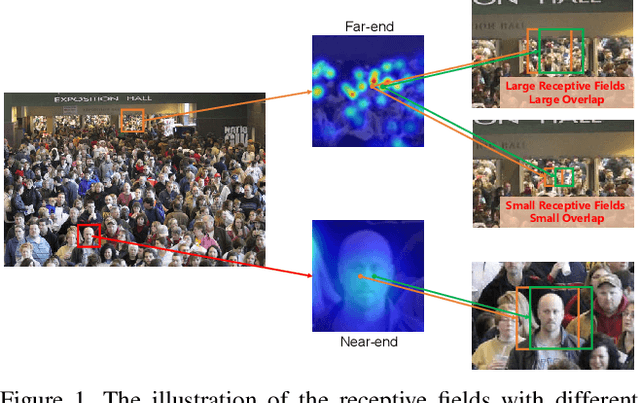
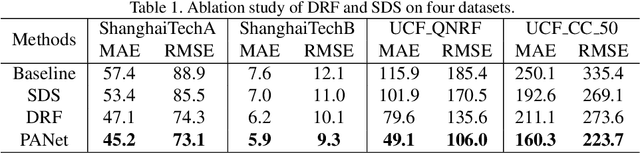
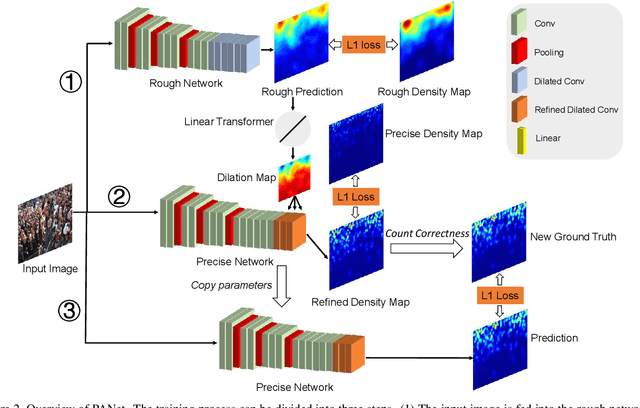

Crowd counting aims to learn the crowd density distributions and estimate the number of objects (e.g. persons) in images. The perspective effect, which significantly influences the distribution of data points, plays an important role in crowd counting. In this paper, we propose a novel perspective-aware approach called PANet to address the perspective problem. Based on the observation that the size of the objects varies greatly in one image due to the perspective effect, we propose the dynamic receptive fields (DRF) framework. The framework is able to adjust the receptive field by the dilated convolution parameters according to the input image, which helps the model to extract more discriminative features for each local region. Different from most previous works which use Gaussian kernels to generate the density map as the supervised information, we propose the self-distilling supervision (SDS) training method. The ground-truth density maps are refined from the first training stage and the perspective information is distilled to the model in the second stage. The experimental results on ShanghaiTech Part_A and Part_B, UCF_QNRF, and UCF_CC_50 datasets demonstrate that our proposed PANet outperforms the state-of-the-art methods by a large margin.
Instance Segmentation for Direct Measurements of Satellites in Metal Powders and Automated Microstructural Characterization from Image Data
Jan 05, 2021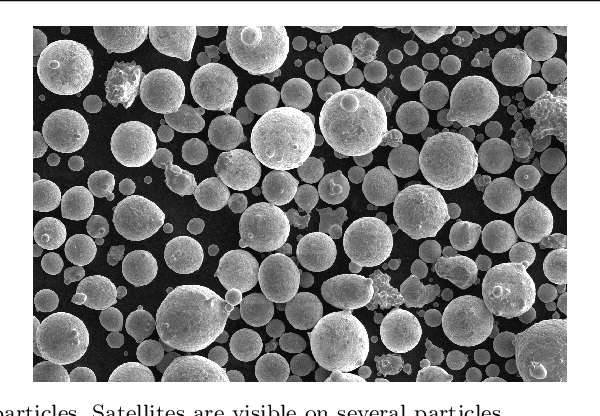
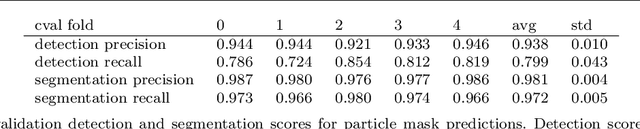


We propose instance segmentation as a useful tool for image analysis in materials science. Instance segmentation is an advanced technique in computer vision which generates individual segmentation masks for every object of interest that is recognized in an image. Using an out-of-the-box implementation of Mask R-CNN, instance segmentation is applied to images of metal powder particles produced through gas atomization. Leveraging transfer learning allows for the analysis to be conducted with a very small training set of labeled images. As well as providing another method for measuring the particle size distribution, we demonstrate the first direct measurements of the satellite content in powder samples. After analyzing the results for the labeled data dataset, the trained model was used to generate measurements for a much larger set of unlabeled images. The resulting particle size measurements showed reasonable agreement with laser scattering measurements. The satellite measurements were self-consistent and showed good agreement with the expected trends for different samples. Finally, we provide a small case study showing how instance segmentation can be used to measure spheroidite content in the UltraHigh Carbon Steel Database, demonstrating the flexibility of the technique.
Multi-Subspace Neural Network for Image Recognition
Jun 17, 2020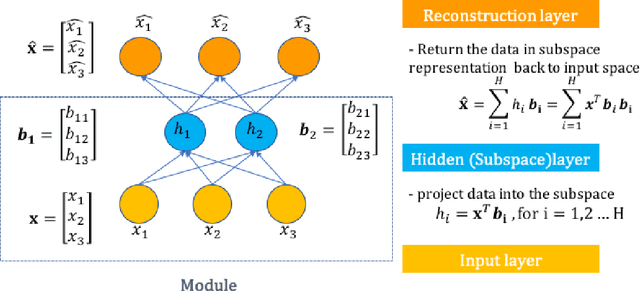
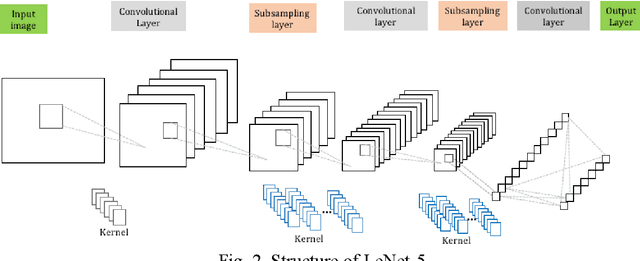
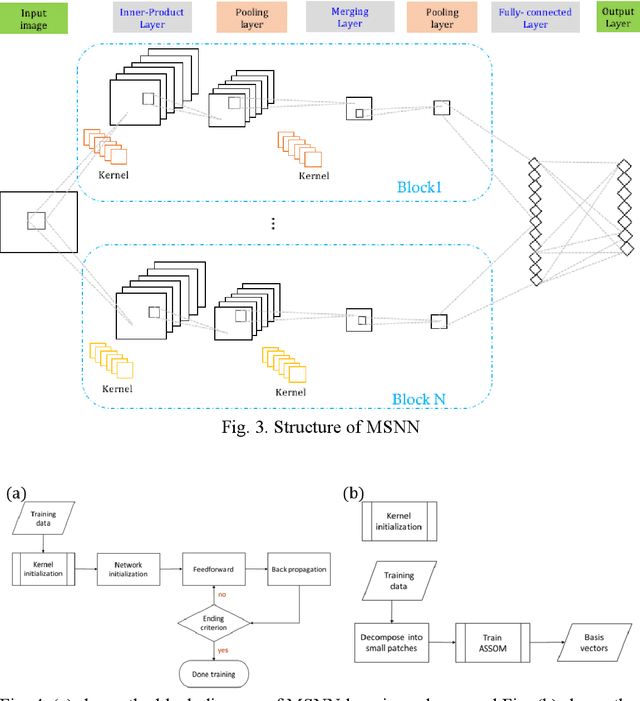
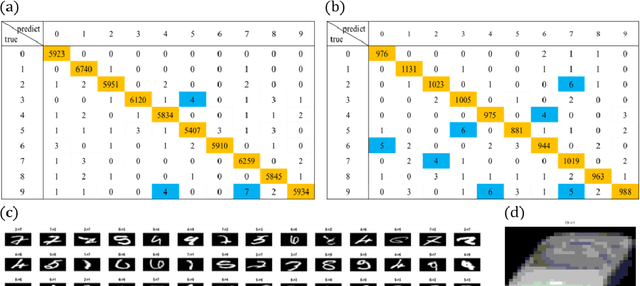
In image classification task, feature extraction is always a big issue. Intra-class variability increases the difficulty in designing the extractors. Furthermore, hand-crafted feature extractor cannot simply adapt new situation. Recently, deep learning has drawn lots of attention on automatically learning features from data. In this study, we proposed multi-subspace neural network (MSNN) which integrates key components of the convolutional neural network (CNN), receptive field, with subspace concept. Associating subspace with the deep network is a novel designing, providing various viewpoints of data. Basis vectors, trained by adaptive subspace self-organization map (ASSOM) span the subspace, serve as a transfer function to access axial components and define the receptive field to extract basic patterns of data without distorting the topology in the visual task. Moreover, the multiple-subspace strategy is implemented as parallel blocks to adapt real-world data and contribute various interpretations of data hoping to be more robust dealing with intra-class variability issues. To this end, handwritten digit and object image datasets (i.e., MNIST and COIL-20) for classification are employed to validate the proposed MSNN architecture. Experimental results show MSNN is competitive to other state-of-the-art approaches.
Video Content Classification using Deep Learning
Nov 27, 2021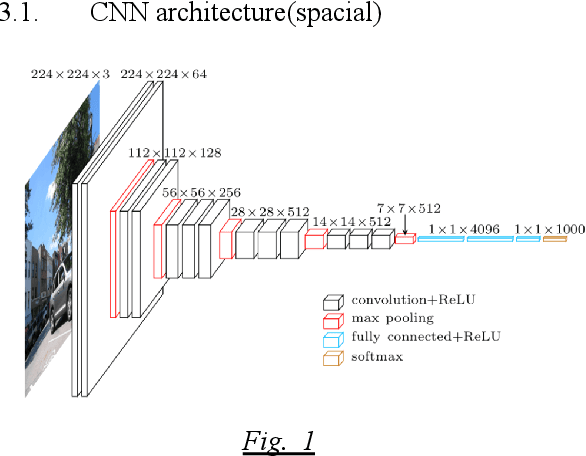

Video content classification is an important research content in computer vision, which is widely used in many fields, such as image and video retrieval, computer vision. This paper presents a model that is a combination of Convolutional Neural Network (CNN) and Recurrent Neural Network (RNN) which develops, trains, and optimizes a deep learning network that can identify the type of video content and classify them into categories such as "Animation, Gaming, natural content, flat content, etc". To enhance the performance of the model novel keyframe extraction method is included to classify only the keyframes, thereby reducing the overall processing time without sacrificing any significant performance.
Dopamine Transporter SPECT Image Classification for Neurodegenerative Parkinsonism via Diffusion Maps and Machine Learning Classifiers
May 07, 2021



Neurodegenerative parkinsonism can be assessed by dopamine transporter single photon emission computed tomography (DaT-SPECT). Although generating images is time consuming, these images can show interobserver variability and they have been visually interpreted by nuclear medicine physicians to date. Accordingly, this study aims to provide an automatic and robust method based on Diffusion Maps and machine learning classifiers to classify the SPECT images into two types, namely Normal and Abnormal DaT-SPECT image groups. In the proposed method, the 3D images of N patients are mapped to an N by N pairwise distance matrix and are visualized in Diffusion Maps coordinates. The images of the training set are embedded into a low-dimensional space by using diffusion maps. Moreover, we use Nystr\"om's out-of-sample extension, which embeds new sample points as the testing set in the reduced space. Testing samples in the embedded space are then classified into two types through the ensemble classifier with Linear Discriminant Analysis (LDA) and voting procedure through twenty-five-fold cross-validation results. The feasibility of the method is demonstrated via Parkinsonism Progression Markers Initiative (PPMI) dataset of 1097 subjects and a clinical cohort from Kaohsiung Chang Gung Memorial Hospital (KCGMH-TW) of 630 patients. We compare performances using Diffusion Maps with those of three alternative manifold methods for dimension reduction, namely Locally Linear Embedding (LLE), Isomorphic Mapping Algorithm (Isomap), and Kernel Principal Component Analysis (Kernel PCA). We also compare results using 2D and 3D CNN methods. The diffusion maps method has an average accuracy of 98% for the PPMI and 90% for the KCGMH-TW dataset with twenty-five fold cross-validation results. It outperforms the other three methods concerning the overall accuracy and the robustness in the training and testing samples.
Are Large-scale Datasets Necessary for Self-Supervised Pre-training?
Dec 20, 2021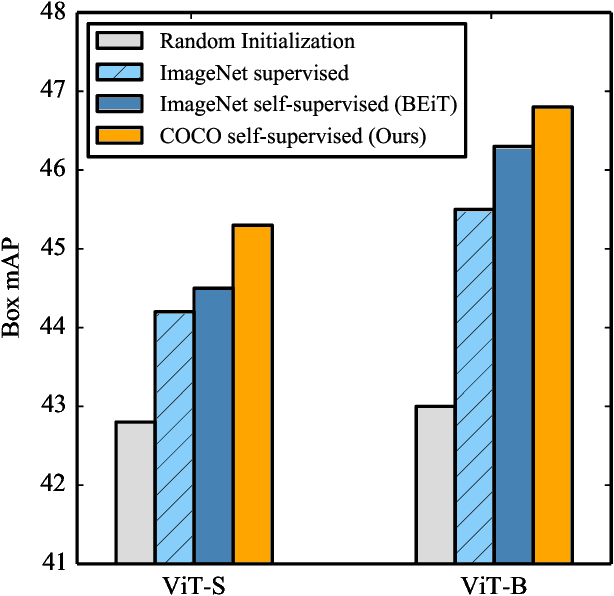
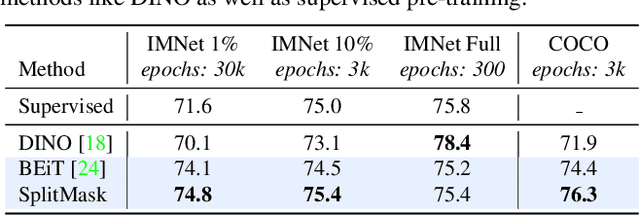
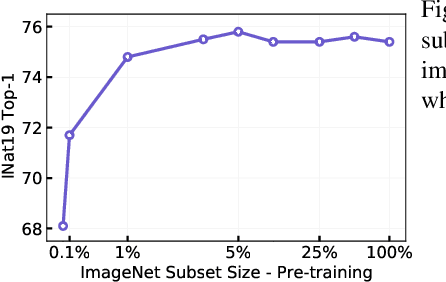

Pre-training models on large scale datasets, like ImageNet, is a standard practice in computer vision. This paradigm is especially effective for tasks with small training sets, for which high-capacity models tend to overfit. In this work, we consider a self-supervised pre-training scenario that only leverages the target task data. We consider datasets, like Stanford Cars, Sketch or COCO, which are order(s) of magnitude smaller than Imagenet. Our study shows that denoising autoencoders, such as BEiT or a variant that we introduce in this paper, are more robust to the type and size of the pre-training data than popular self-supervised methods trained by comparing image embeddings.We obtain competitive performance compared to ImageNet pre-training on a variety of classification datasets, from different domains. On COCO, when pre-training solely using COCO images, the detection and instance segmentation performance surpasses the supervised ImageNet pre-training in a comparable setting.