 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Chest X-Rays Image Classification from beta-Variational Autoencoders Latent Features
Sep 29, 2021
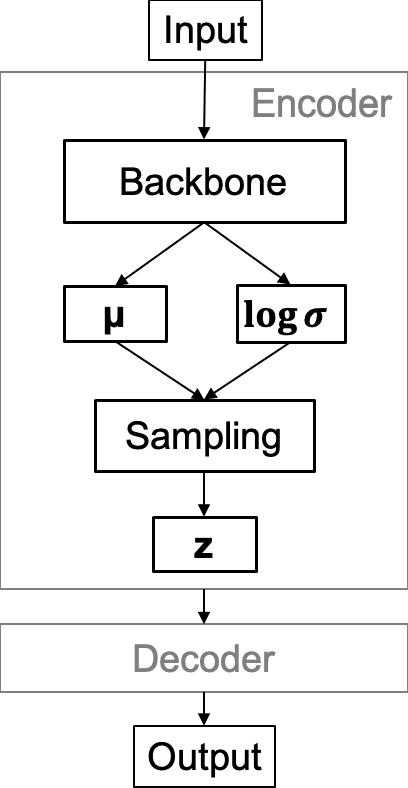
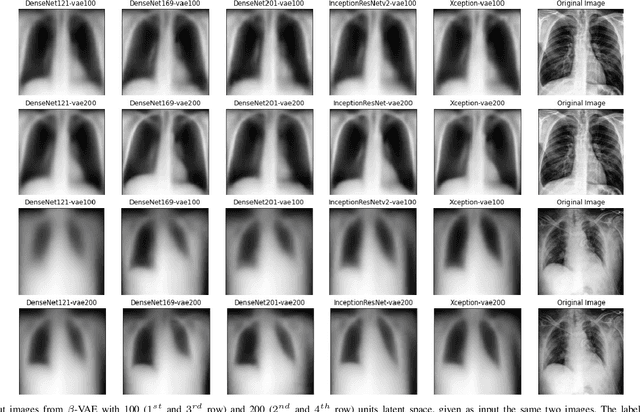
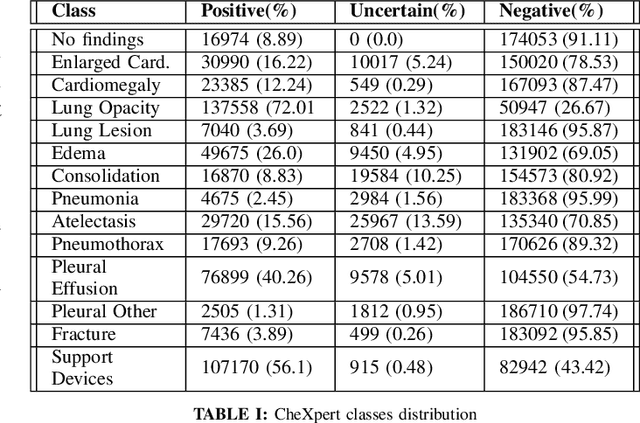
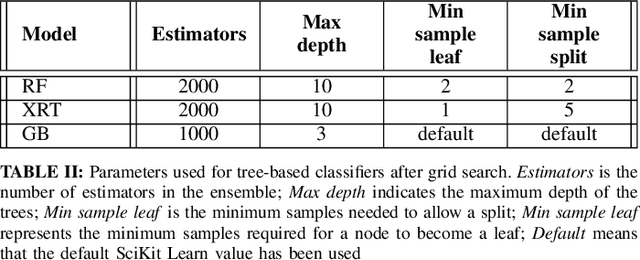
Chest X-Ray (CXR) is one of the most common diagnostic techniques used in everyday clinical practice all around the world. We hereby present a work which intends to investigate and analyse the use of Deep Learning (DL) techniques to extract information from such images and allow to classify them, trying to keep our methodology as general as possible and possibly also usable in a real world scenario without much effort, in the future. To move in this direction, we trained several beta-Variational Autoencoder (beta-VAE) models on the CheXpert dataset, one of the largest publicly available collection of labeled CXR images; from these models, latent features have been extracted and used to train other Machine Learning models, able to classify the original images from the features extracted by the beta-VAE. Lastly, tree-based models have been combined together in ensemblings to improve the results without the necessity of further training or models engineering. Expecting some drop in pure performance with the respect to state of the art classification specific models, we obtained encouraging results, which show the viability of our approach and the usability of the high level features extracted by the autoencoders for classification tasks.
SPA-GAN: Spatial Attention GAN for Image-to-Image Translation
Aug 19, 2019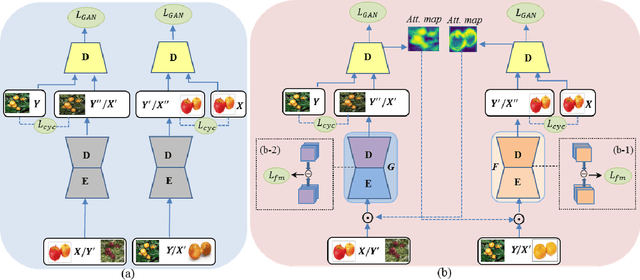



Image-to-image translation is to learn a mapping between images from a source domain and images from a target domain. In this paper, we introduce the attention mechanism directly to the generative adversarial network (GAN) architecture and propose a novel spatial attention GAN model (SPA-GAN) for image-to-image translation tasks. SPA-GAN computes the attention in its discriminator and use it to help the generator focus more on the most discriminative regions between the source and target domains, leading to more realistic output images. We also find it helpful to introduce an additional feature map loss in SPA-GAN training to preserve domain specific features during translation. Compared with existing attention-guided GAN models, SPA-GAN is a lightweight model that does not need additional attention networks or supervision. Qualitative and quantitative comparison against state-of-the-art methods on benchmark datasets demonstrates the superior performance of SPA-GAN.
HMIC: Hierarchical Medical Image Classification, A Deep Learning Approach
Jun 12, 2020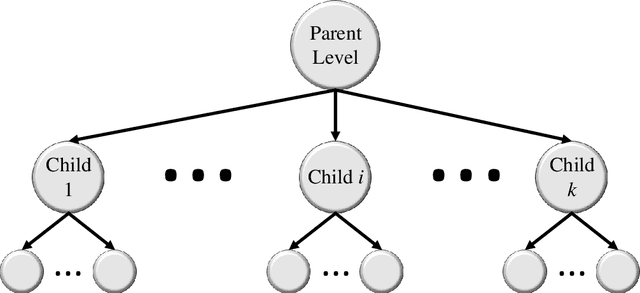
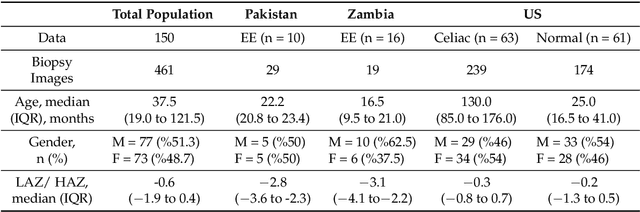
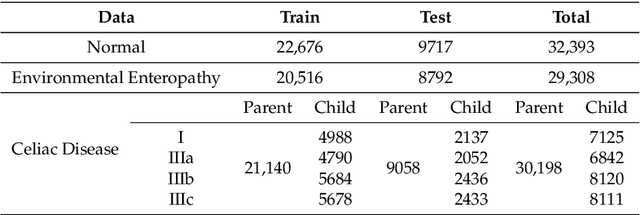
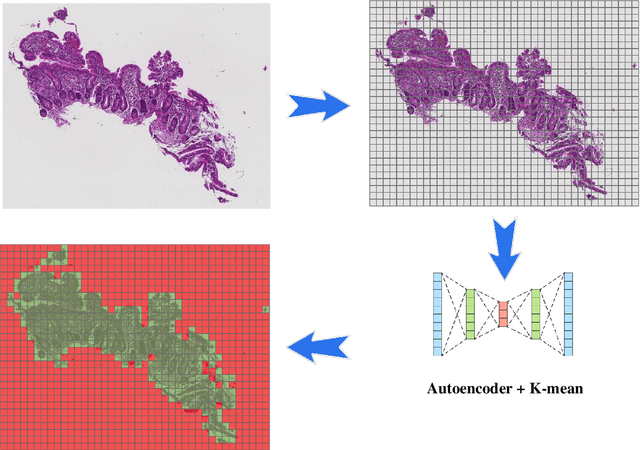
Image classification is central to the big data revolution in medicine. Improved information processing methods for diagnosis and classification of digital medical images have shown to be successful via deep learning approaches. As this field is explored, there are limitations to the performance of traditional supervised classifiers. This paper outlines an approach that is different from the current medical image classification tasks that view the issue as multi-class classification. We performed a hierarchical classification using our Hierarchical Medical Image classification (HMIC) approach. HMIC uses stacks of deep learning models to give particular comprehension at each level of the clinical picture hierarchy. For testing our performance, we use biopsy of the small bowel images that contain three categories in the parent level (Celiac Disease, Environmental Enteropathy, and histologically normal controls). For the child level, Celiac Disease Severity is classified into 4 classes (I, IIIa, IIIb, and IIIC).
Emojich -- zero-shot emoji generation using Russian language: a technical report
Dec 04, 2021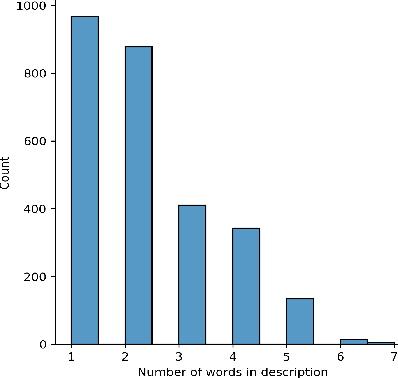
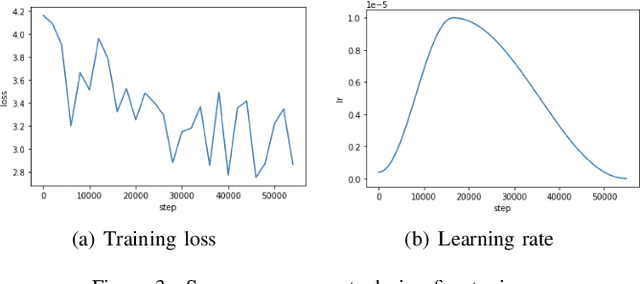

This technical report presents a text-to-image neural network "Emojich" that generates emojis using captions in Russian language as a condition. We aim to keep the generalization ability of a pretrained big model ruDALL-E Malevich (XL) 1.3B parameters at the fine-tuning stage, while giving special style to the images generated. Here are presented some engineering methods, code realization, all hyper-parameters for reproducing results and a Telegram bot where everyone can create their own customized sets of stickers. Also, some newly generated emojis obtained by "Emojich" model are demonstrated.
Generalized Visual Quality Assessment of GAN-Generated Face Images
Jan 28, 2022
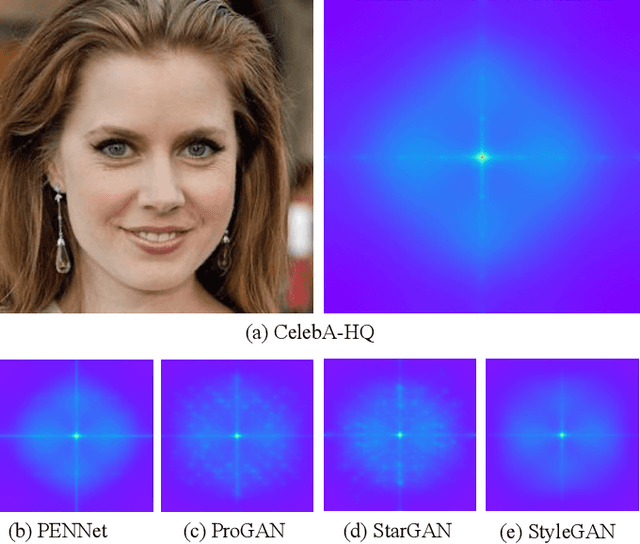
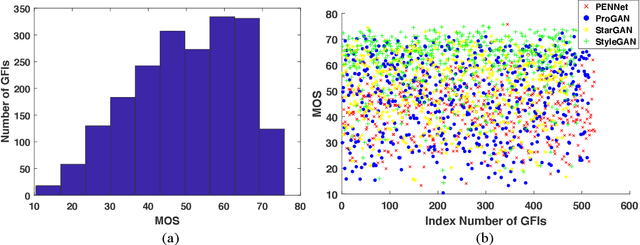
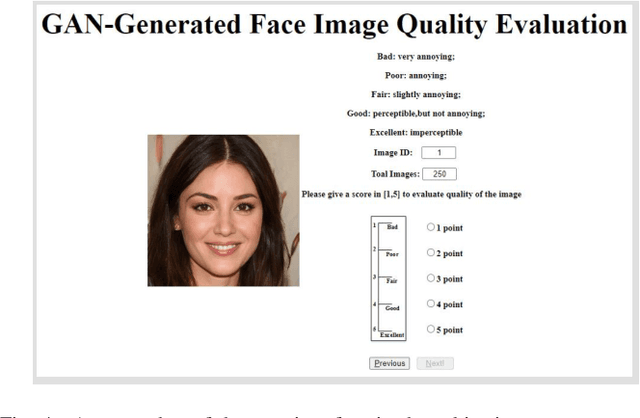
Recent years have witnessed the dramatically increased interest in face generation with generative adversarial networks (GANs). A number of successful GAN algorithms have been developed to produce vivid face images towards different application scenarios. However, little work has been dedicated to automatic quality assessment of such GAN-generated face images (GFIs), even less have been devoted to generalized and robust quality assessment of GFIs generated with unseen GAN model. Herein, we make the first attempt to study the subjective and objective quality towards generalized quality assessment of GFIs. More specifically, we establish a large-scale database consisting of GFIs from four GAN algorithms, the pseudo labels from image quality assessment (IQA) measures, as well as the human opinion scores via subjective testing. Subsequently, we develop a quality assessment model that is able to deliver accurate quality predictions for GFIs from both available and unseen GAN algorithms based on meta-learning. In particular, to learn shared knowledge from GFIs pairs that are born of limited GAN algorithms, we develop the convolutional block attention (CBA) and facial attributes-based analysis (ABA) modules, ensuring that the learned knowledge tends to be consistent with human visual perception. Extensive experiments exhibit that the proposed model achieves better performance compared with the state-of-the-art IQA models, and is capable of retaining the effectiveness when evaluating GFIs from the unseen GAN algorithms.
DeepLPF: Deep Local Parametric Filters for Image Enhancement
Mar 31, 2020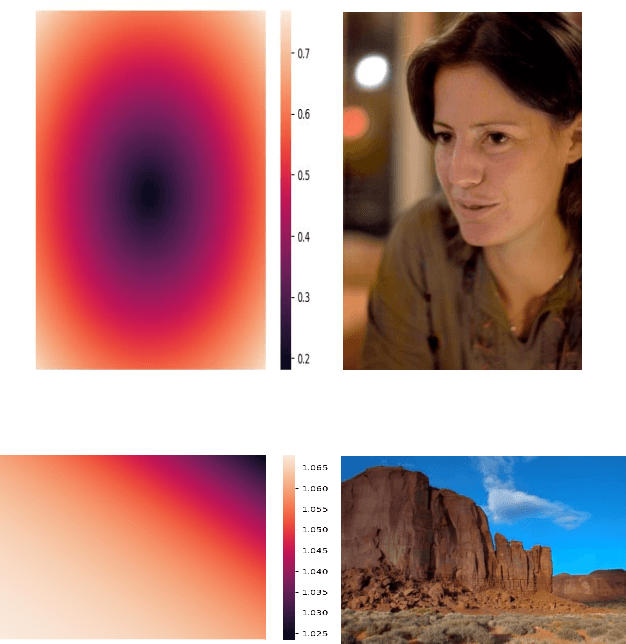


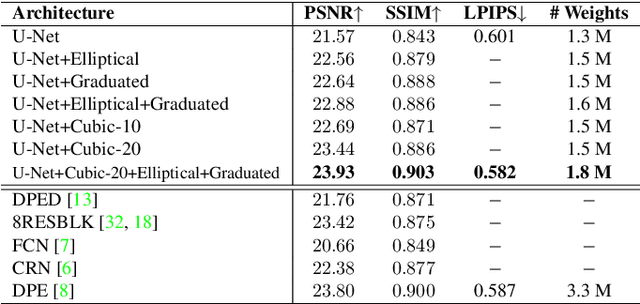
Digital artists often improve the aesthetic quality of digital photographs through manual retouching. Beyond global adjustments, professional image editing programs provide local adjustment tools operating on specific parts of an image. Options include parametric (graduated, radial filters) and unconstrained brush tools. These highly expressive tools enable a diverse set of local image enhancements. However, their use can be time consuming, and requires artistic capability. State-of-the-art automated image enhancement approaches typically focus on learning pixel-level or global enhancements. The former can be noisy and lack interpretability, while the latter can fail to capture fine-grained adjustments. In this paper, we introduce a novel approach to automatically enhance images using learned spatially local filters of three different types (Elliptical Filter, Graduated Filter, Polynomial Filter). We introduce a deep neural network, dubbed Deep Local Parametric Filters (DeepLPF), which regresses the parameters of these spatially localized filters that are then automatically applied to enhance the image. DeepLPF provides a natural form of model regularization and enables interpretable, intuitive adjustments that lead to visually pleasing results. We report on multiple benchmarks and show that DeepLPF produces state-of-the-art performance on two variants of the MIT-Adobe-5K dataset, often using a fraction of the parameters required for competing methods.
Reusing Discriminators for Encoding Towards Unsupervised Image-to-Image Translation
Mar 03, 2020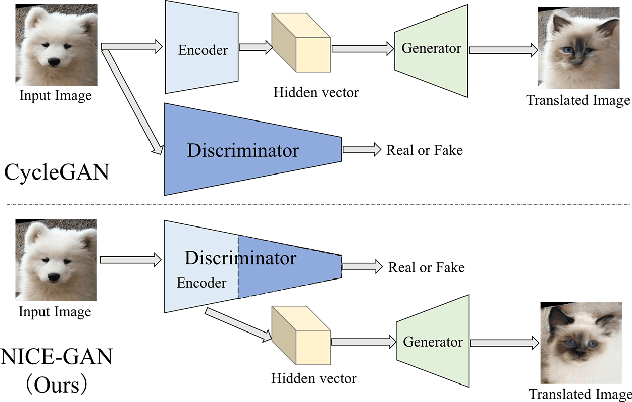
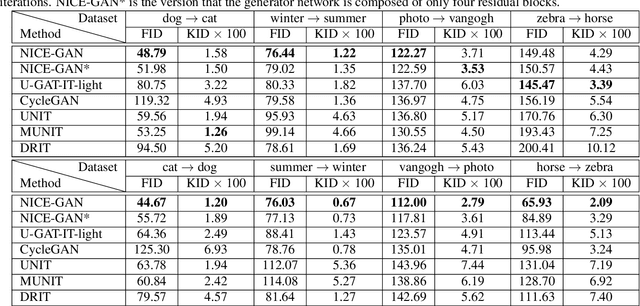
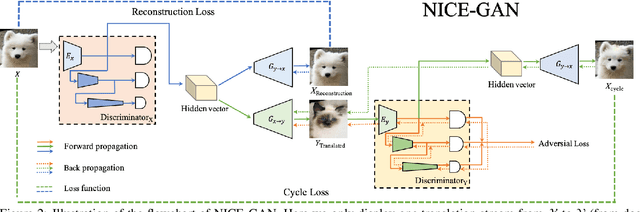
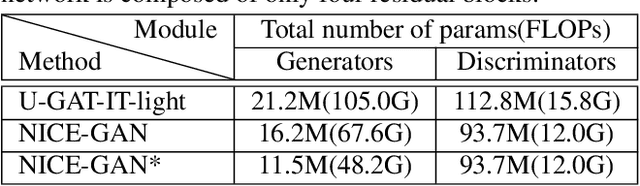
Unsupervised image-to-image translation is a central task in computer vision. Current translation frameworks will abandon the discriminator once the training process is completed. This paper contends a novel role of the discriminator by reusing it for encoding the images of the target domain. The proposed architecture, termed as NICE-GAN, exhibits two advantageous patterns over previous approaches: First, it is more compact since no independent encoding component is required; Second, this plug-in encoder is directly trained by the adversary loss, making it more informative and trained more effectively if a multi-scale discriminator is applied. The main issue in NICE-GAN is the coupling of translation with discrimination along the encoder, which could incur training inconsistency when we play the min-max game via GAN. To tackle this issue, we develop a decoupled training strategy by which the encoder is only trained when maximizing the adversary loss while keeping frozen otherwise. Extensive experiments on four popular benchmarks demonstrate the superior performance of NICE-GAN over state-of-the-art methods in terms of FID, KID, and also human preference. Comprehensive ablation studies are also carried out to isolate the validity of each proposed component. Our codes are available at https://github.com/alpc91/NICE-GAN-pytorch.
Recent Advances and New Guidelines on Hyperspectral and Multispectral Image Fusion
Aug 08, 2020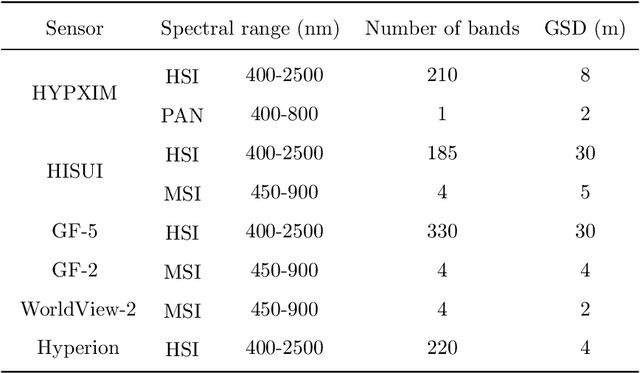
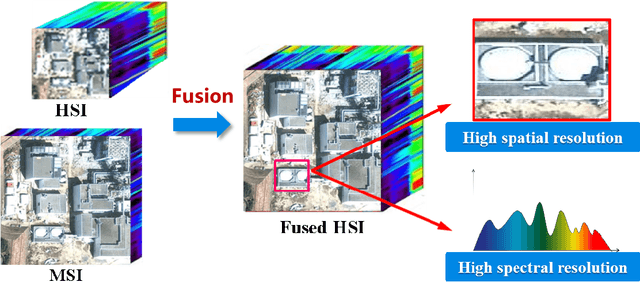
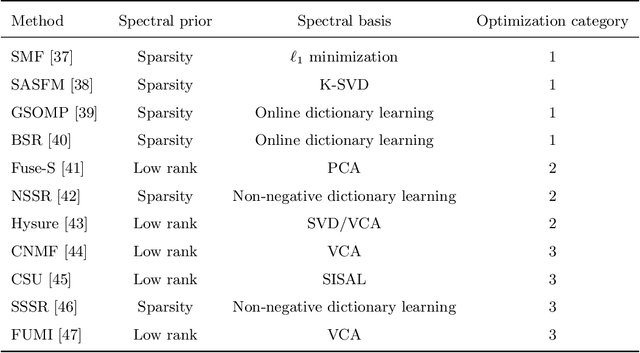
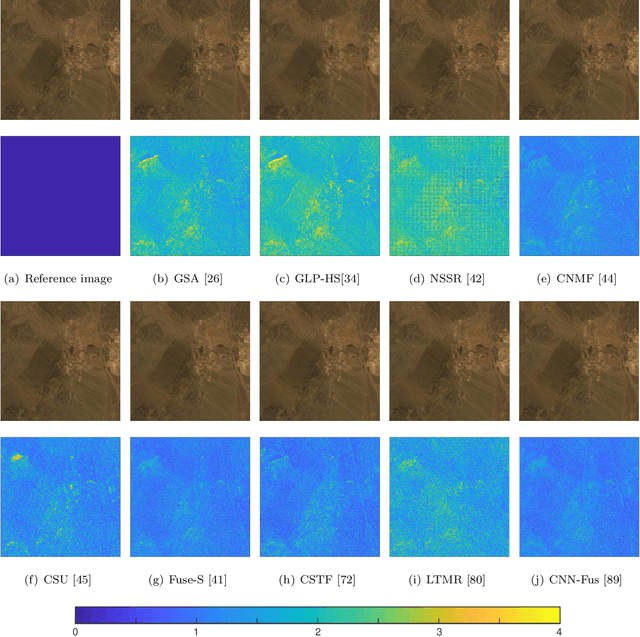
Hyperspectral image (HSI) with high spectral resolution often suffers from low spatial resolution owing to the limitations of imaging sensors. Image fusion is an effective and economical way to enhance the spatial resolution of HSI, which combines HSI with higher spatial resolution multispectral image (MSI) of the same scenario. In the past years, many HSI and MSI fusion algorithms are introduced to obtain high-resolution HSI. However, it lacks a full-scale review for the newly proposed HSI and MSI fusion approaches. To tackle this problem,this work gives a comprehensive review and new guidelines for HSI-MSI fusion. According to the characteristics of HSI-MSI fusion methods, they are categorized as four categories, including pan-sharpening based approaches, matrix factorization based approaches, tensor representation based approaches, and deep convolution neural network based approaches. We make a detailed introduction, discussions, and comparison for the fusion methods in each category. Additionally, the existing challenges and possible future directions for the HSI-MSI fusion are presented.
Hierarchy Parsing for Image Captioning
Sep 10, 2019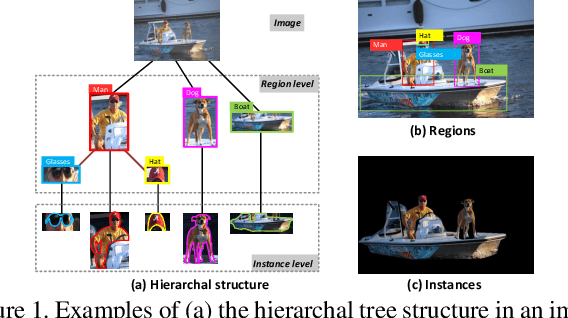
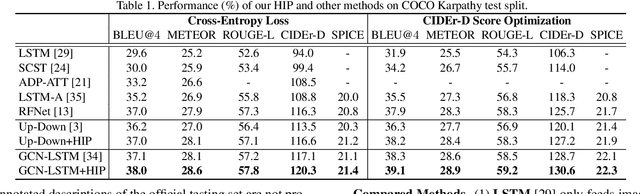
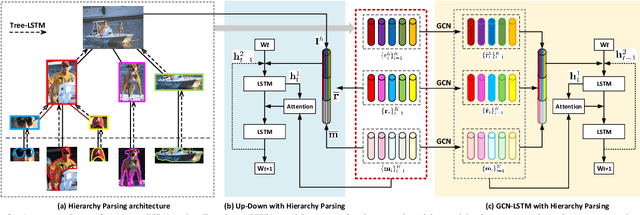
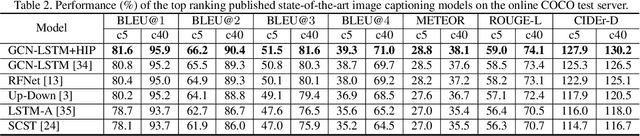
It is always well believed that parsing an image into constituent visual patterns would be helpful for understanding and representing an image. Nevertheless, there has not been evidence in support of the idea on describing an image with a natural-language utterance. In this paper, we introduce a new design to model a hierarchy from instance level (segmentation), region level (detection) to the whole image to delve into a thorough image understanding for captioning. Specifically, we present a HIerarchy Parsing (HIP) architecture that novelly integrates hierarchical structure into image encoder. Technically, an image decomposes into a set of regions and some of the regions are resolved into finer ones. Each region then regresses to an instance, i.e., foreground of the region. Such process naturally builds a hierarchal tree. A tree-structured Long Short-Term Memory (Tree-LSTM) network is then employed to interpret the hierarchal structure and enhance all the instance-level, region-level and image-level features. Our HIP is appealing in view that it is pluggable to any neural captioning models. Extensive experiments on COCO image captioning dataset demonstrate the superiority of HIP. More remarkably, HIP plus a top-down attention-based LSTM decoder increases CIDEr-D performance from 120.1% to 127.2% on COCO Karpathy test split. When further endowing instance-level and region-level features from HIP with semantic relation learnt through Graph Convolutional Networks (GCN), CIDEr-D is boosted up to 130.6%.
Learnable Descent Algorithm for Nonsmooth Nonconvex Image Reconstruction
Jul 22, 2020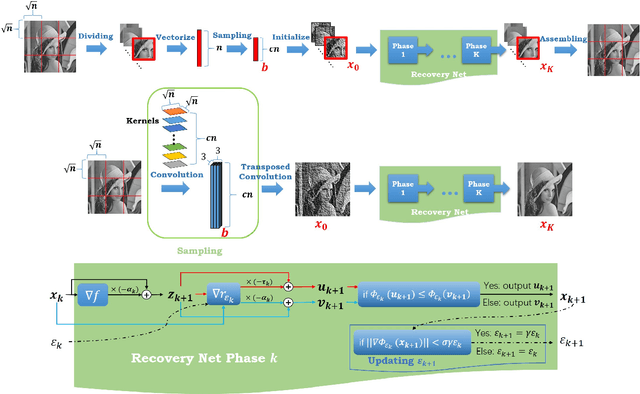
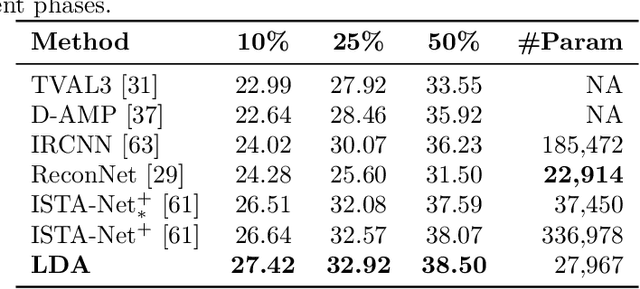
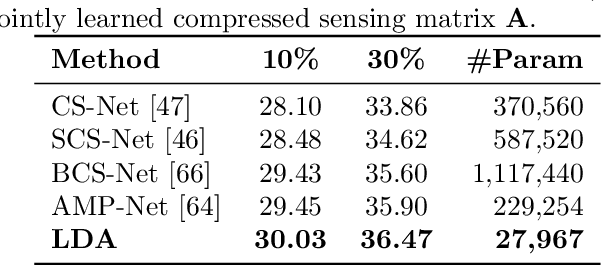

We propose a general learning based framework for solving nonsmooth and nonconvex image reconstruction problems. We model the regularization function as the composition of the $l_{2,1}$ norm and a smooth but nonconvex feature mapping parametrized as a deep convolutional neural network. We develop a provably convergent descent-type algorithm to solve the nonsmooth nonconvex minimization problem by leveraging the Nesterov's smoothing technique and the idea of residual learning, and learn the network parameters such that the outputs of the algorithm match the references in training data. Our method is versatile as one can employ various modern network structures into the regularization, and the resulting network inherits the guaranteed convergence of the algorithm. We also show that the proposed network is parameter-efficient and its performance compares favorably to the state-of-the-art methods in a variety of image reconstruction problems in practice.