 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMaking Time Editable in Video Diffusion Transformers
Jun 08, 2026Modern Diffusion Transformers for video generation provide limited control over the progression of time and the editing of temporal dynamics. We propose a temporal-control methodology that extends a pretrained DiT with explicit time editing, allowing control over motion speed and temporal structure without redesigning the backbone. Its core implementation augments the pretrained model with a lightweight temporal module, preserving the original generative prior while expanding its controllable dynamic range.
Kandinsky 5.0: A Family of Foundation Models for Image and Video Generation
Nov 19, 2025



This report introduces Kandinsky 5.0, a family of state-of-the-art foundation models for high-resolution image and 10-second video synthesis. The framework comprises three core line-up of models: Kandinsky 5.0 Image Lite - a line-up of 6B parameter image generation models, Kandinsky 5.0 Video Lite - a fast and lightweight 2B parameter text-to-video and image-to-video models, and Kandinsky 5.0 Video Pro - 19B parameter models that achieves superior video generation quality. We provide a comprehensive review of the data curation lifecycle - including collection, processing, filtering and clustering - for the multi-stage training pipeline that involves extensive pre-training and incorporates quality-enhancement techniques such as self-supervised fine-tuning (SFT) and reinforcement learning (RL)-based post-training. We also present novel architectural, training, and inference optimizations that enable Kandinsky 5.0 to achieve high generation speeds and state-of-the-art performance across various tasks, as demonstrated by human evaluation. As a large-scale, publicly available generative framework, Kandinsky 5.0 leverages the full potential of its pre-training and subsequent stages to be adapted for a wide range of generative applications. We hope that this report, together with the release of our open-source code and training checkpoints, will substantially advance the development and accessibility of high-quality generative models for the research community.
$ abla$NABLA: Neighborhood Adaptive Block-Level Attention
Jul 17, 2025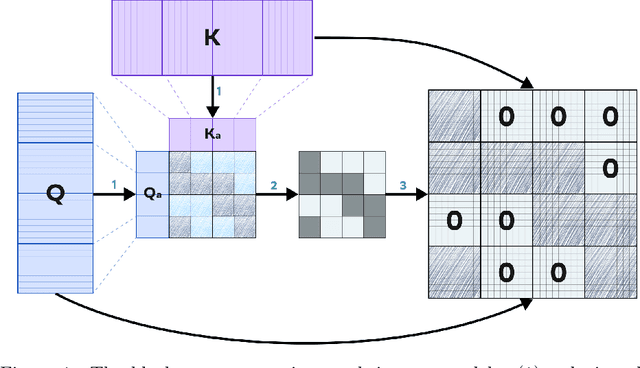
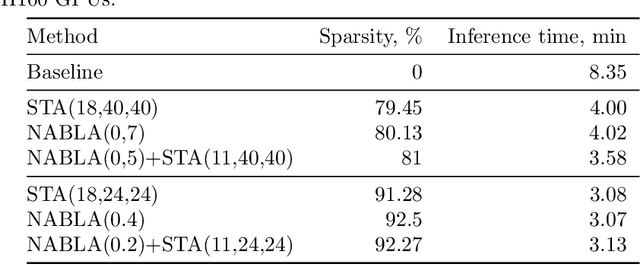
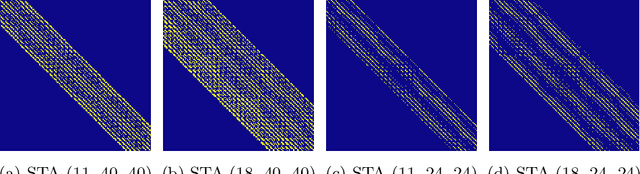
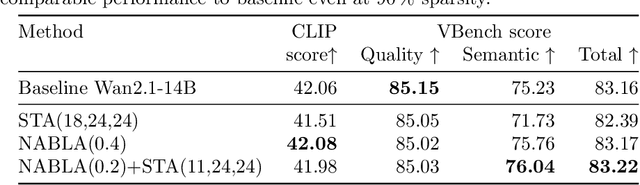
Recent progress in transformer-based architectures has demonstrated remarkable success in video generation tasks. However, the quadratic complexity of full attention mechanisms remains a critical bottleneck, particularly for high-resolution and long-duration video sequences. In this paper, we propose NABLA, a novel Neighborhood Adaptive Block-Level Attention mechanism that dynamically adapts to sparsity patterns in video diffusion transformers (DiTs). By leveraging block-wise attention with adaptive sparsity-driven threshold, NABLA reduces computational overhead while preserving generative quality. Our method does not require custom low-level operator design and can be seamlessly integrated with PyTorch's Flex Attention operator. Experiments demonstrate that NABLA achieves up to 2.7x faster training and inference compared to baseline almost without compromising quantitative metrics (CLIP score, VBench score, human evaluation score) and visual quality drop. The code and model weights are available here: https://github.com/gen-ai-team/Wan2.1-NABLA
VIVAT: Virtuous Improving VAE Training through Artifact Mitigation
Jun 09, 2025



Variational Autoencoders (VAEs) remain a cornerstone of generative computer vision, yet their training is often plagued by artifacts that degrade reconstruction and generation quality. This paper introduces VIVAT, a systematic approach to mitigating common artifacts in KL-VAE training without requiring radical architectural changes. We present a detailed taxonomy of five prevalent artifacts - color shift, grid patterns, blur, corner and droplet artifacts - and analyze their root causes. Through straightforward modifications, including adjustments to loss weights, padding strategies, and the integration of Spatially Conditional Normalization, we demonstrate significant improvements in VAE performance. Our method achieves state-of-the-art results in image reconstruction metrics (PSNR and SSIM) across multiple benchmarks and enhances text-to-image generation quality, as evidenced by superior CLIP scores. By preserving the simplicity of the KL-VAE framework while addressing its practical challenges, VIVAT offers actionable insights for researchers and practitioners aiming to optimize VAE training.
CRAFT: Cultural Russian-Oriented Dataset Adaptation for Focused Text-to-Image Generation
May 07, 2025Despite the fact that popular text-to-image generation models cope well with international and general cultural queries, they have a significant knowledge gap regarding individual cultures. This is due to the content of existing large training datasets collected on the Internet, which are predominantly based on Western European or American popular culture. Meanwhile, the lack of cultural adaptation of the model can lead to incorrect results, a decrease in the generation quality, and the spread of stereotypes and offensive content. In an effort to address this issue, we examine the concept of cultural code and recognize the critical importance of its understanding by modern image generation models, an issue that has not been sufficiently addressed in the research community to date. We propose the methodology for collecting and processing the data necessary to form a dataset based on the cultural code, in particular the Russian one. We explore how the collected data affects the quality of generations in the national domain and analyze the effectiveness of our approach using the Kandinsky 3.1 text-to-image model. Human evaluation results demonstrate an increase in the level of awareness of Russian culture in the model.
* This is arxiv version of the paper which was accepted for the Doklady Mathematics Journal in 2024
GHOST 2.0: generative high-fidelity one shot transfer of heads
Feb 26, 2025



While the task of face swapping has recently gained attention in the research community, a related problem of head swapping remains largely unexplored. In addition to skin color transfer, head swap poses extra challenges, such as the need to preserve structural information of the whole head during synthesis and inpaint gaps between swapped head and background. In this paper, we address these concerns with GHOST 2.0, which consists of two problem-specific modules. First, we introduce enhanced Aligner model for head reenactment, which preserves identity information at multiple scales and is robust to extreme pose variations. Secondly, we use a Blender module that seamlessly integrates the reenacted head into the target background by transferring skin color and inpainting mismatched regions. Both modules outperform the baselines on the corresponding tasks, allowing to achieve state of the art results in head swapping. We also tackle complex cases, such as large difference in hair styles of source and target. Code is available at https://github.com/ai-forever/ghost-2.0
RusCode: Russian Cultural Code Benchmark for Text-to-Image Generation
Feb 11, 2025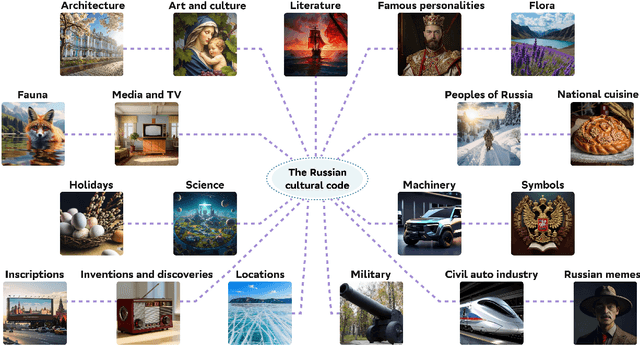
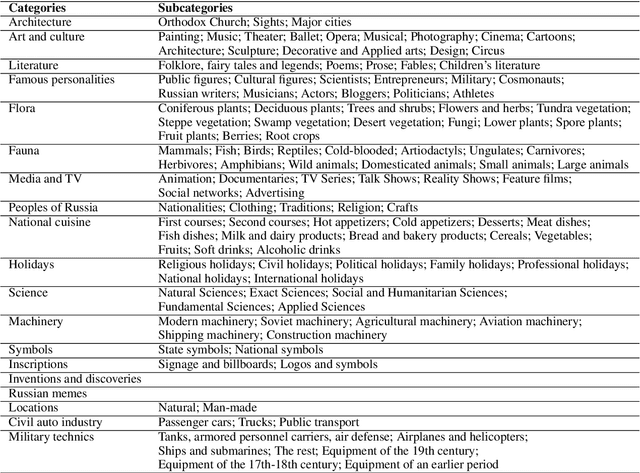
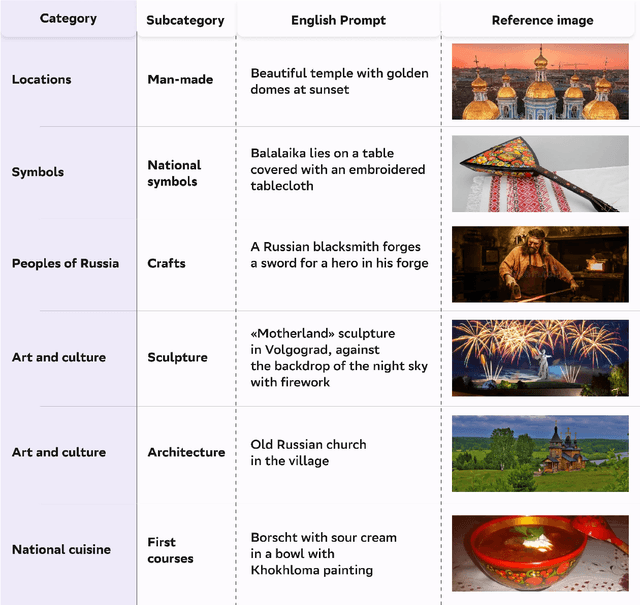
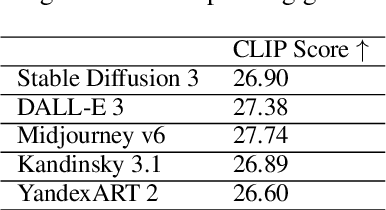
Text-to-image generation models have gained popularity among users around the world. However, many of these models exhibit a strong bias toward English-speaking cultures, ignoring or misrepresenting the unique characteristics of other language groups, countries, and nationalities. The lack of cultural awareness can reduce the generation quality and lead to undesirable consequences such as unintentional insult, and the spread of prejudice. In contrast to the field of natural language processing, cultural awareness in computer vision has not been explored as extensively. In this paper, we strive to reduce this gap. We propose a RusCode benchmark for evaluating the quality of text-to-image generation containing elements of the Russian cultural code. To do this, we form a list of 19 categories that best represent the features of Russian visual culture. Our final dataset consists of 1250 text prompts in Russian and their translations into English. The prompts cover a wide range of topics, including complex concepts from art, popular culture, folk traditions, famous people's names, natural objects, scientific achievements, etc. We present the results of a human evaluation of the side-by-side comparison of Russian visual concepts representations using popular generative models.
Unleashing the power of novel conditional generative approaches for new materials discovery
Nov 05, 2024



For a very long time, computational approaches to the design of new materials have relied on an iterative process of finding a candidate material and modeling its properties. AI has played a crucial role in this regard, helping to accelerate the discovery and optimization of crystal properties and structures through advanced computational methodologies and data-driven approaches. To address the problem of new materials design and fasten the process of new materials search, we have applied latest generative approaches to the problem of crystal structure design, trying to solve the inverse problem: by given properties generate a structure that satisfies them without utilizing supercomputer powers. In our work we propose two approaches: 1) conditional structure modification: optimization of the stability of an arbitrary atomic configuration, using the energy difference between the most energetically favorable structure and all its less stable polymorphs and 2) conditional structure generation. We used a representation for materials that includes the following information: lattice, atom coordinates, atom types, chemical features, space group and formation energy of the structure. The loss function was optimized to take into account the periodic boundary conditions of crystal structures. We have applied Diffusion models approach, Flow matching, usual Autoencoder (AE) and compared the results of the models and approaches. As a metric for the study, physical PyMatGen matcher was employed: we compare target structure with generated one using default tolerances. So far, our modifier and generator produce structures with needed properties with accuracy 41% and 82% respectively. To prove the offered methodology efficiency, inference have been carried out, resulting in several potentially new structures with formation energy below the AFLOW-derived convex hulls.
Kandinsky 3: Text-to-Image Synthesis for Multifunctional Generative Framework
Oct 28, 2024



Text-to-image (T2I) diffusion models are popular for introducing image manipulation methods, such as editing, image fusion, inpainting, etc. At the same time, image-to-video (I2V) and text-to-video (T2V) models are also built on top of T2I models. We present Kandinsky 3, a novel T2I model based on latent diffusion, achieving a high level of quality and photorealism. The key feature of the new architecture is the simplicity and efficiency of its adaptation for many types of generation tasks. We extend the base T2I model for various applications and create a multifunctional generation system that includes text-guided inpainting/outpainting, image fusion, text-image fusion, image variations generation, I2V and T2V generation. We also present a distilled version of the T2I model, evaluating inference in 4 steps of the reverse process without reducing image quality and 3 times faster than the base model. We deployed a user-friendly demo system in which all the features can be tested in the public domain. Additionally, we released the source code and checkpoints for the Kandinsky 3 and extended models. Human evaluations show that Kandinsky 3 demonstrates one of the highest quality scores among open source generation systems.
Your Transformer is Secretly Linear
May 19, 2024



This paper reveals a novel linear characteristic exclusive to transformer decoders, including models such as GPT, LLaMA, OPT, BLOOM and others. We analyze embedding transformations between sequential layers, uncovering a near-perfect linear relationship (Procrustes similarity score of 0.99). However, linearity decreases when the residual component is removed due to a consistently low output norm of the transformer layer. Our experiments show that removing or linearly approximating some of the most linear blocks of transformers does not affect significantly the loss or model performance. Moreover, in our pretraining experiments on smaller models we introduce a cosine-similarity-based regularization, aimed at reducing layer linearity. This regularization improves performance metrics on benchmarks like Tiny Stories and SuperGLUE and as well successfully decreases the linearity of the models. This study challenges the existing understanding of transformer architectures, suggesting that their operation may be more linear than previously assumed.