 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDemocratizing Machine Translation with OPUS-MT
Dec 04, 2022This paper presents the OPUS ecosystem with a focus on the development of open machine translation models and tools, and their integration into end-user applications, development platforms and professional workflows. We discuss our on-going mission of increasing language coverage and translation quality, and also describe on-going work on the development of modular translation models and speed-optimized compact solutions for real-time translation on regular desktops and small devices.
RuCLIP -- new models and experiments: a technical report
Feb 22, 2022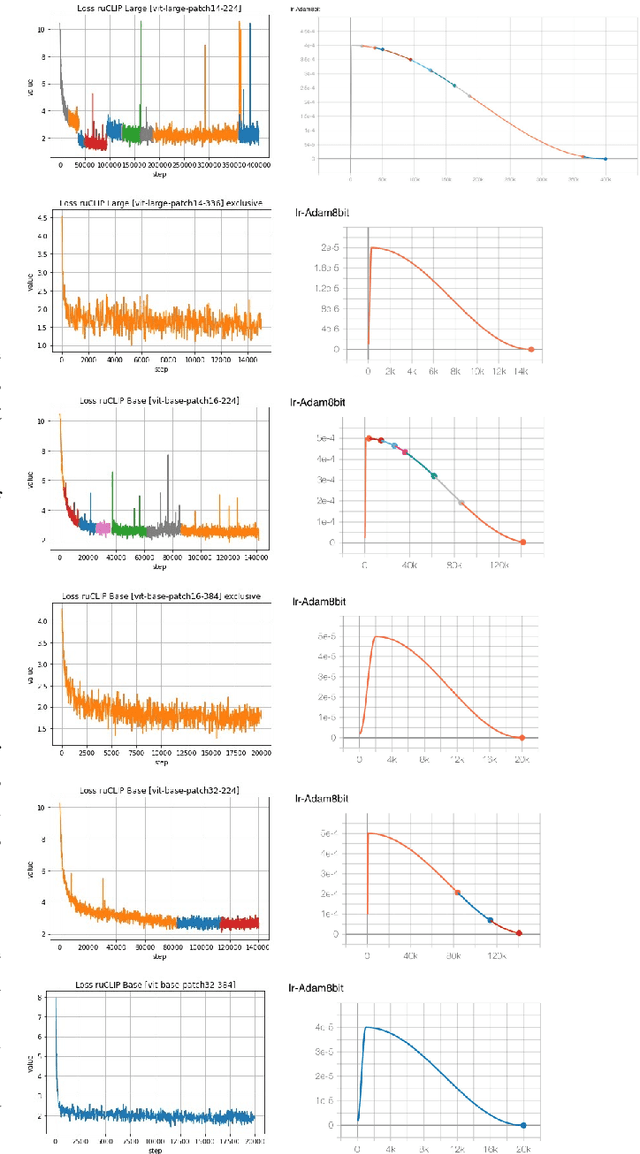
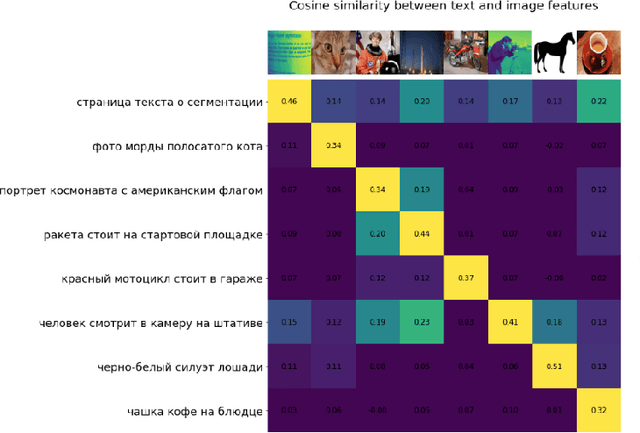
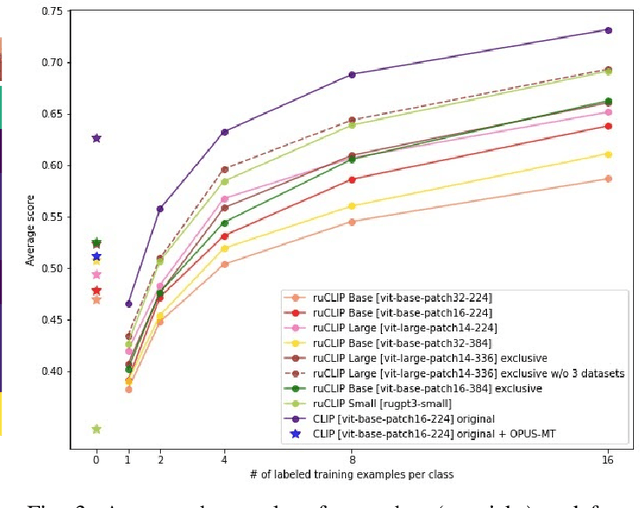
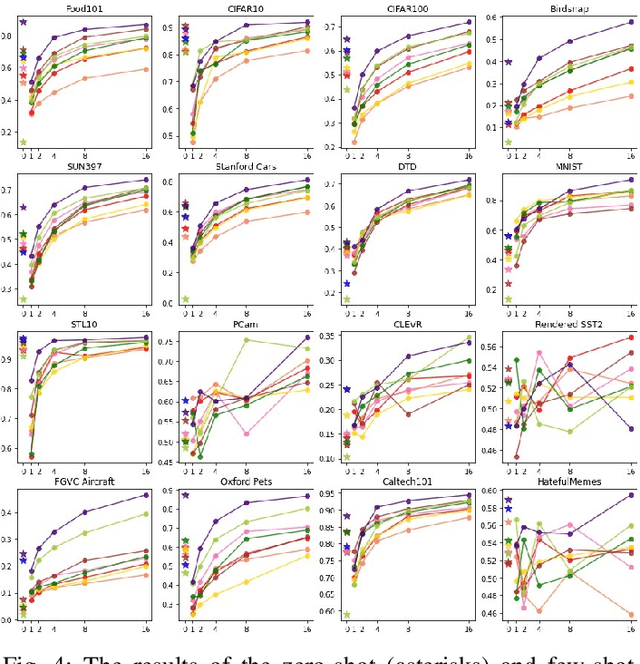
In the report we propose six new implementations of ruCLIP model trained on our 240M pairs. The accuracy results are compared with original CLIP model with Ru-En translation (OPUS-MT) on 16 datasets from different domains. Our best implementations outperform CLIP + OPUS-MT solution on most of the datasets in few-show and zero-shot tasks. In the report we briefly describe the implementations and concentrate on the conducted experiments. Inference execution time comparison is also presented in the report.
Emojich -- zero-shot emoji generation using Russian language: a technical report
Dec 04, 2021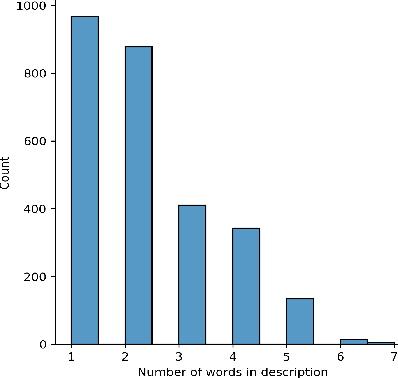
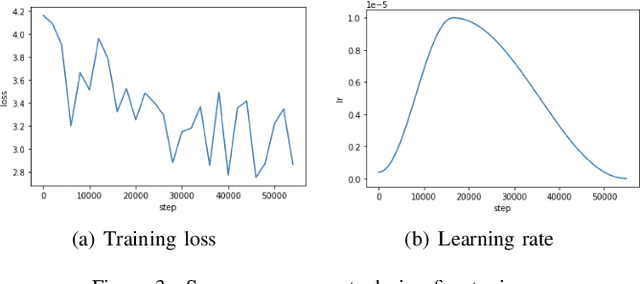

This technical report presents a text-to-image neural network "Emojich" that generates emojis using captions in Russian language as a condition. We aim to keep the generalization ability of a pretrained big model ruDALL-E Malevich (XL) 1.3B parameters at the fine-tuning stage, while giving special style to the images generated. Here are presented some engineering methods, code realization, all hyper-parameters for reproducing results and a Telegram bot where everyone can create their own customized sets of stickers. Also, some newly generated emojis obtained by "Emojich" model are demonstrated.
Many Heads but One Brain: an Overview of Fusion Brain Challenge on AI Journey 2021
Nov 22, 2021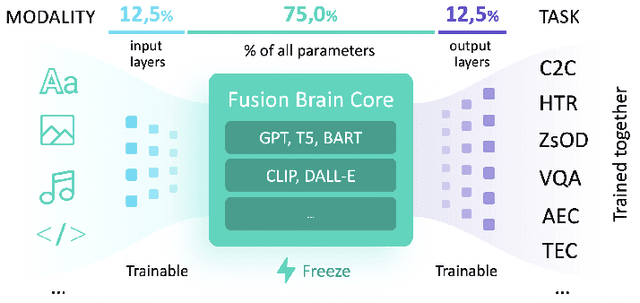
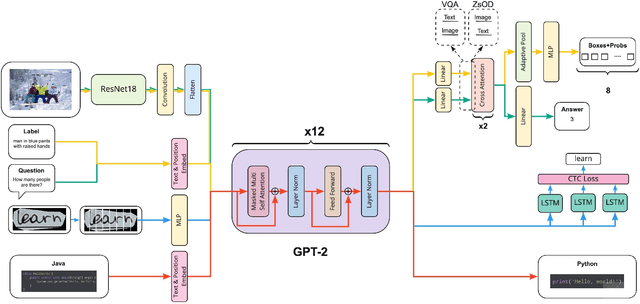
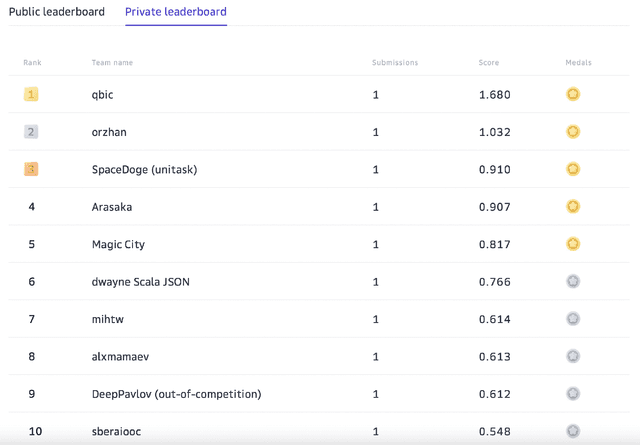
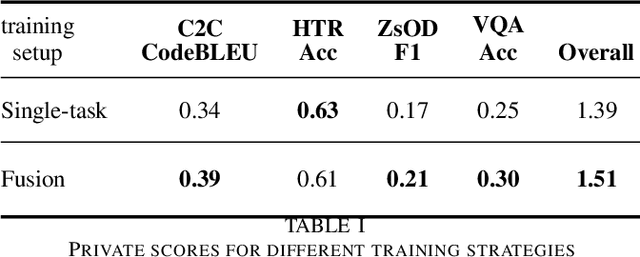
Supporting the current trend in the AI community, we propose the AI Journey 2021 Challenge called Fusion Brain which is targeted to make the universal architecture process different modalities (namely, images, texts, and code) and to solve multiple tasks for vision and language. The Fusion Brain Challenge https://github.com/sberbank-ai/fusion_brain_aij2021 combines the following specific tasks: Code2code Translation, Handwritten Text recognition, Zero-shot Object Detection, and Visual Question Answering. We have created datasets for each task to test the participants' submissions on it. Moreover, we have opened a new handwritten dataset in both Russian and English, which consists of 94,130 pairs of images and texts. The Russian part of the dataset is the largest Russian handwritten dataset in the world. We also propose the baseline solution and corresponding task-specific solutions as well as overall metrics.
Tracing cultural diachronic semantic shifts in Russian using word embeddings: test sets and baselines
May 16, 2019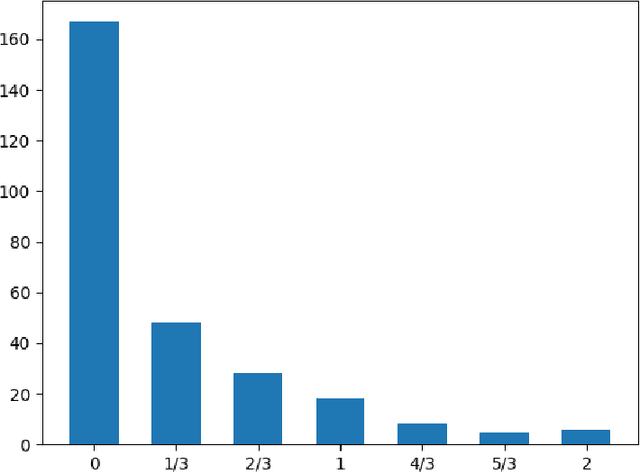
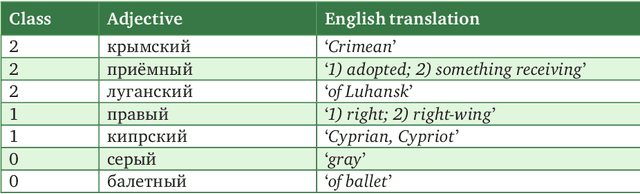
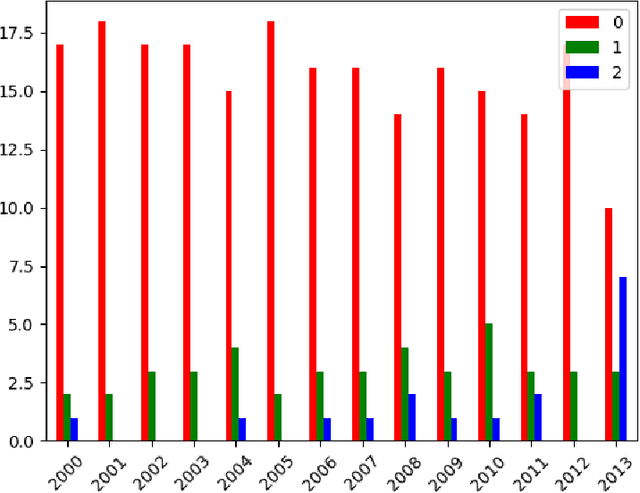
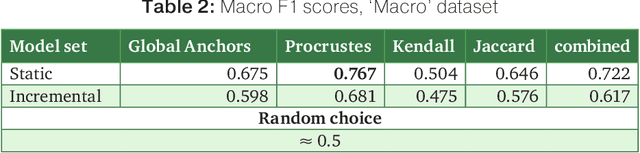
The paper introduces manually annotated test sets for the task of tracing diachronic (temporal) semantic shifts in Russian. The two test sets are complementary in that the first one covers comparatively strong semantic changes occurring to nouns and adjectives from pre-Soviet to Soviet times, while the second one covers comparatively subtle socially and culturally determined shifts occurring in years from 2000 to 2014. Additionally, the second test set offers more granular classification of shifts degree, but is limited to only adjectives. The introduction of the test sets allowed us to evaluate several well-established algorithms of semantic shifts detection (posing this as a classification problem), most of which have never been tested on Russian material. All of these algorithms use distributional word embedding models trained on the corresponding in-domain corpora. The resulting scores provide solid comparison baselines for future studies tackling similar tasks. We publish the datasets, code and the trained models in order to facilitate further research in automatically detecting temporal semantic shifts for Russian words, with time periods of different granularities.