 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
High-level Prior-based Loss Functions for Medical Image Segmentation: A Survey
Nov 16, 2020

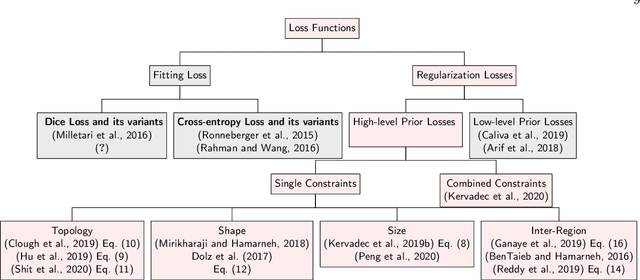
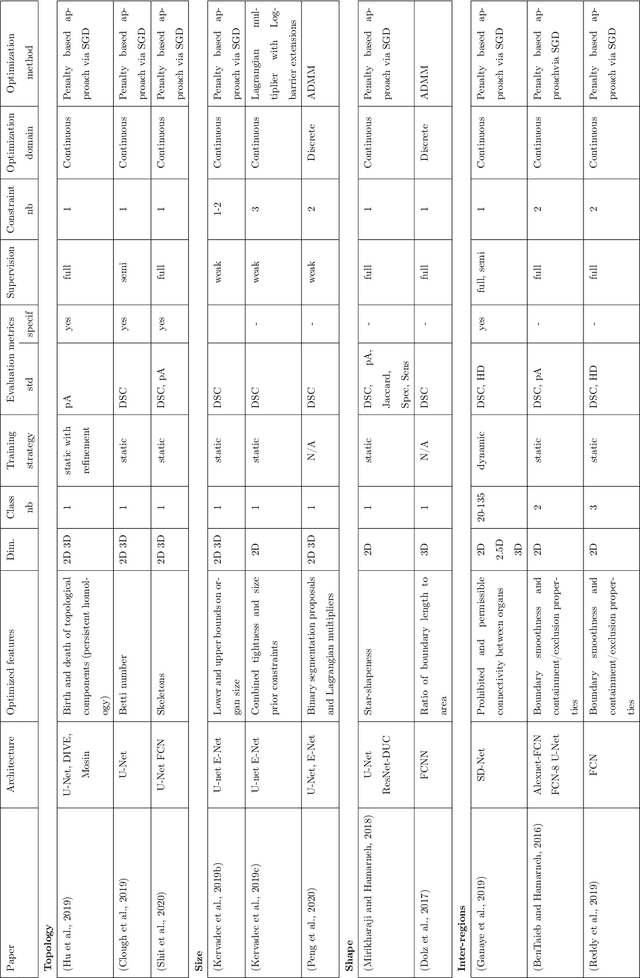
Today, deep convolutional neural networks (CNNs) have demonstrated state of the art performance for supervised medical image segmentation, across various imaging modalities and tasks. Despite early success, segmentation networks may still generate anatomically aberrant segmentations, with holes or inaccuracies near the object boundaries. To mitigate this effect, recent research works have focused on incorporating spatial information or prior knowledge to enforce anatomically plausible segmentation. If the integration of prior knowledge in image segmentation is not a new topic in classical optimization approaches, it is today an increasing trend in CNN based image segmentation, as shown by the growing literature on the topic. In this survey, we focus on high level prior, embedded at the loss function level. We categorize the articles according to the nature of the prior: the object shape, size, topology, and the inter-regions constraints. We highlight strengths and limitations of current approaches, discuss the challenge related to the design and the integration of prior-based losses, and the optimization strategies, and draw future research directions.
DSAL: Deeply Supervised Active Learning from Strong and Weak Labelers for Biomedical Image Segmentation
Jan 22, 2021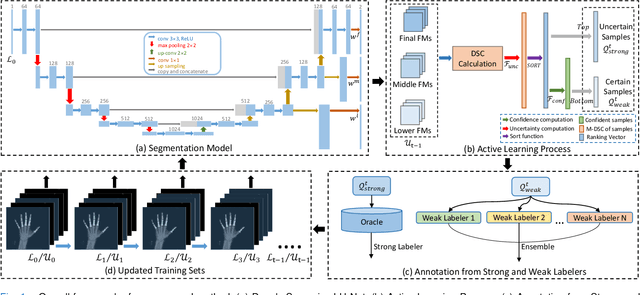
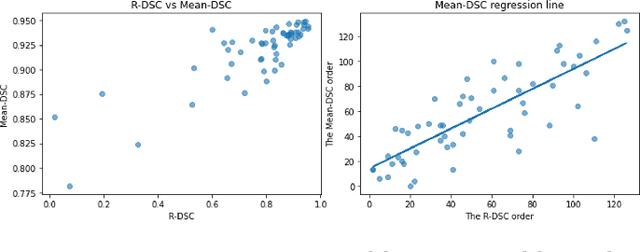
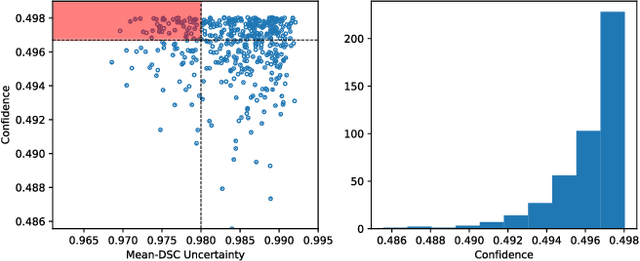
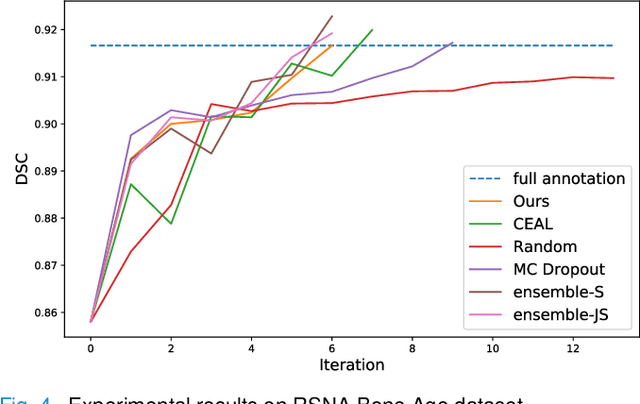
Image segmentation is one of the most essential biomedical image processing problems for different imaging modalities, including microscopy and X-ray in the Internet-of-Medical-Things (IoMT) domain. However, annotating biomedical images is knowledge-driven, time-consuming, and labor-intensive, making it difficult to obtain abundant labels with limited costs. Active learning strategies come into ease the burden of human annotation, which queries only a subset of training data for annotation. Despite receiving attention, most of active learning methods generally still require huge computational costs and utilize unlabeled data inefficiently. They also tend to ignore the intermediate knowledge within networks. In this work, we propose a deep active semi-supervised learning framework, DSAL, combining active learning and semi-supervised learning strategies. In DSAL, a new criterion based on deep supervision mechanism is proposed to select informative samples with high uncertainties and low uncertainties for strong labelers and weak labelers respectively. The internal criterion leverages the disagreement of intermediate features within the deep learning network for active sample selection, which subsequently reduces the computational costs. We use the proposed criteria to select samples for strong and weak labelers to produce oracle labels and pseudo labels simultaneously at each active learning iteration in an ensemble learning manner, which can be examined with IoMT Platform. Extensive experiments on multiple medical image datasets demonstrate the superiority of the proposed method over state-of-the-art active learning methods.
Direct Reconstruction of Linear Parametric Images from Dynamic PET Using Nonlocal Deep Image Prior
Jun 18, 2021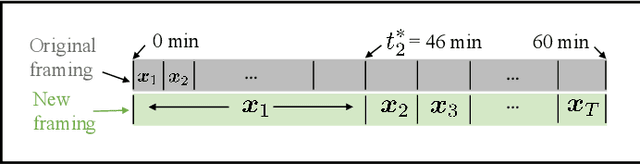
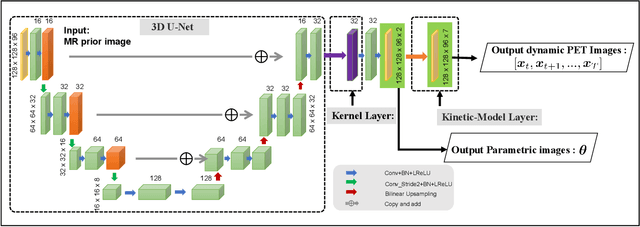
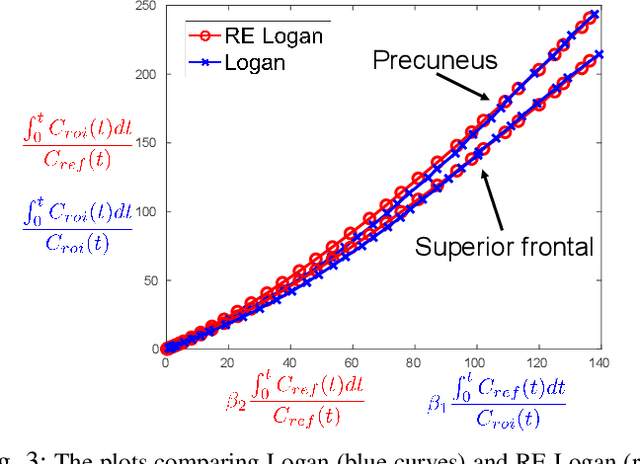
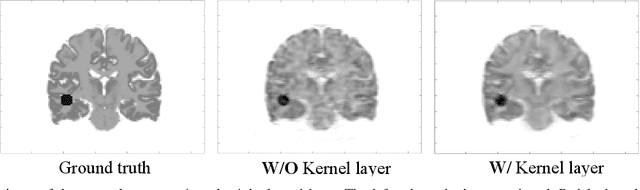
Direct reconstruction methods have been developed to estimate parametric images directly from the measured PET sinograms by combining the PET imaging model and tracer kinetics in an integrated framework. Due to limited counts received, signal-to-noise-ratio (SNR) and resolution of parametric images produced by direct reconstruction frameworks are still limited. Recently supervised deep learning methods have been successfully applied to medical imaging denoising/reconstruction when large number of high-quality training labels are available. For static PET imaging, high-quality training labels can be acquired by extending the scanning time. However, this is not feasible for dynamic PET imaging, where the scanning time is already long enough. In this work, we proposed an unsupervised deep learning framework for direct parametric reconstruction from dynamic PET, which was tested on the Patlak model and the relative equilibrium Logan model. The patient's anatomical prior image, which is readily available from PET/CT or PET/MR scans, was supplied as the network input to provide a manifold constraint, and also utilized to construct a kernel layer to perform non-local feature denoising. The linear kinetic model was embedded in the network structure as a 1x1 convolution layer. The training objective function was based on the PET statistical model. Evaluations based on dynamic datasets of 18F-FDG and 11C-PiB tracers show that the proposed framework can outperform the traditional and the kernel method-based direct reconstruction methods.
DALE : Dark Region-Aware Low-light Image Enhancement
Aug 28, 2020

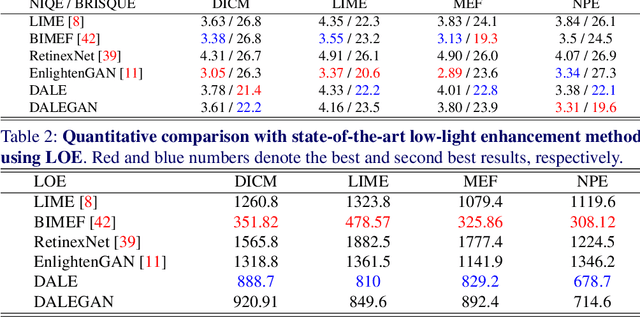

In this paper, we present a novel low-light image enhancement method called dark region-aware low-light image enhancement (DALE), where dark regions are accurately recognized by the proposed visual attention module and their brightness are intensively enhanced. Our method can estimate the visual attention in an efficient manner using super-pixels without any complicated process. Thus, the method can preserve the color, tone, and brightness of original images and prevents normally illuminated areas of the images from being saturated and distorted. Experimental results show that our method accurately identifies dark regions via the proposed visual attention, and qualitatively and quantitatively outperforms state-of-the-art methods.
One-Shot Image Classification by Learning to Restore Prototypes
May 04, 2020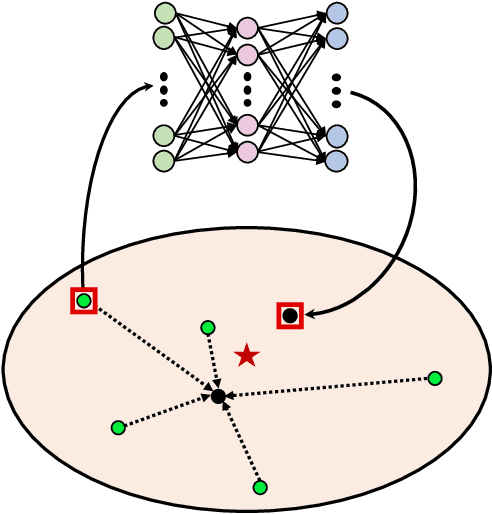


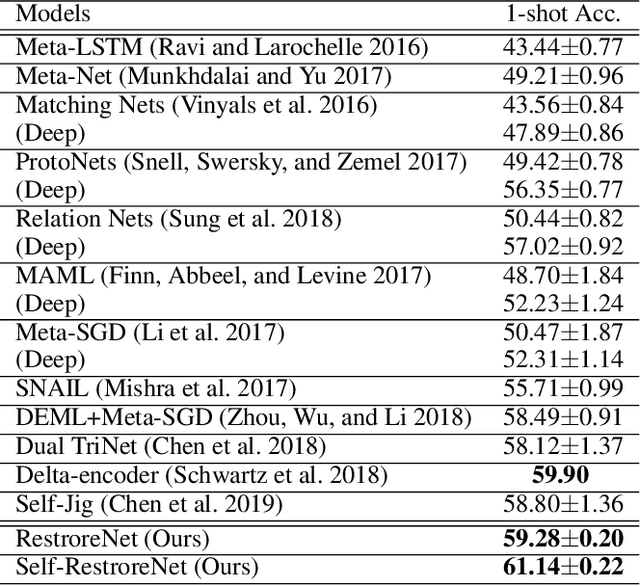
One-shot image classification aims to train image classifiers over the dataset with only one image per category. It is challenging for modern deep neural networks that typically require hundreds or thousands of images per class. In this paper, we adopt metric learning for this problem, which has been applied for few- and many-shot image classification by comparing the distance between the test image and the center of each class in the feature space. However, for one-shot learning, the existing metric learning approaches would suffer poor performance because the single training image may not be representative of the class. For example, if the image is far away from the class center in the feature space, the metric-learning based algorithms are unlikely to make correct predictions for the test images because the decision boundary is shifted by this noisy image. To address this issue, we propose a simple yet effective regression model, denoted by RestoreNet, which learns a class agnostic transformation on the image feature to move the image closer to the class center in the feature space. Experiments demonstrate that RestoreNet obtains superior performance over the state-of-the-art methods on a broad range of datasets. Moreover, RestoreNet can be easily combined with other methods to achieve further improvement.
DeepCapture: Image Spam Detection Using Deep Learning and Data Augmentation
Jun 16, 2020
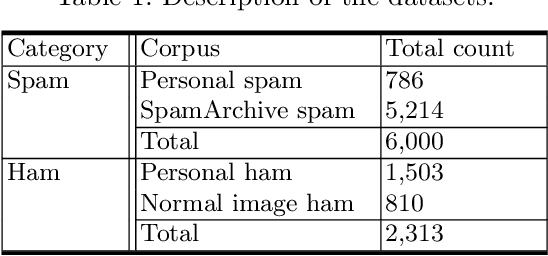

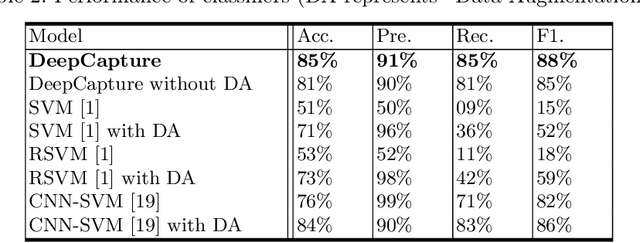
Image spam emails are often used to evade text-based spam filters that detect spam emails with their frequently used keywords. In this paper, we propose a new image spam email detection tool called DeepCapture using a convolutional neural network (CNN) model. There have been many efforts to detect image spam emails, but there is a significant performance degrade against entirely new and unseen image spam emails due to overfitting during the training phase. To address this challenging issue, we mainly focus on developing a more robust model to address the overfitting problem. Our key idea is to build a CNN-XGBoost framework consisting of eight layers only with a large number of training samples using data augmentation techniques tailored towards the image spam detection task. To show the feasibility of DeepCapture, we evaluate its performance with publicly available datasets consisting of 6,000 spam and 2,313 non-spam image samples. The experimental results show that DeepCapture is capable of achieving an F1-score of 88%, which has a 6% improvement over the best existing spam detection model CNN-SVM with an F1-score of 82%. Moreover, DeepCapture outperformed existing image spam detection solutions against new and unseen image datasets.
LAMP: Extracting Text from Gradients with Language Model Priors
Feb 17, 2022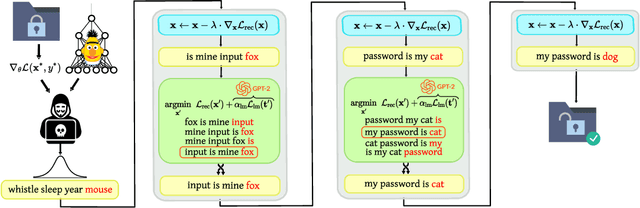
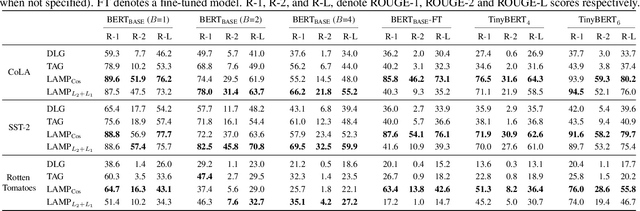
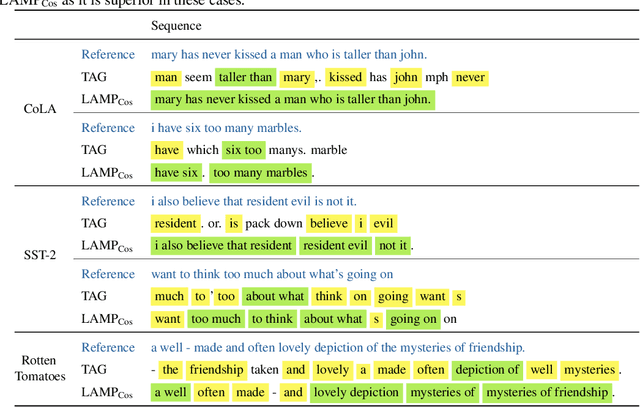
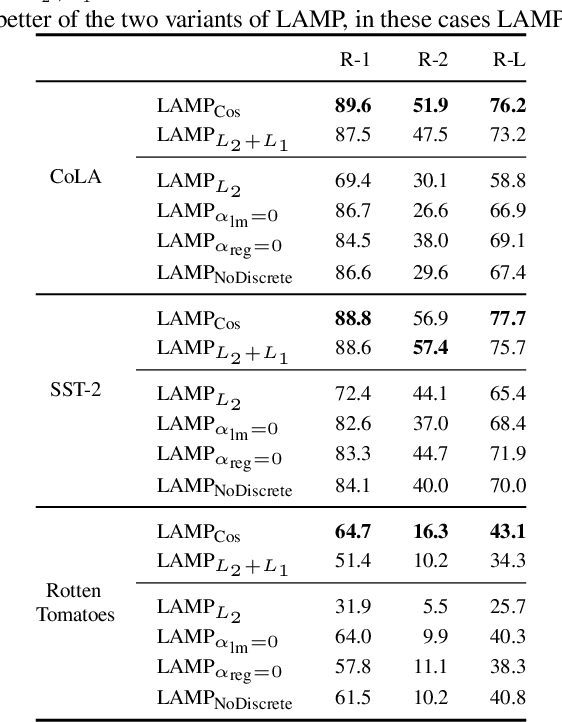
Recent work shows that sensitive user data can be reconstructed from gradient updates, breaking the key privacy promise of federated learning. While success was demonstrated primarily on image data, these methods do not directly transfer to other domains such as text. In this work, we propose LAMP, a novel attack tailored to textual data, that successfully reconstructs original text from gradients. Our key insight is to model the prior probability of the text with an auxiliary language model, utilizing it to guide the search towards more natural text. Concretely, LAMP introduces a discrete text transformation procedure that minimizes both the reconstruction loss and the prior text probability, as provided by the auxiliary language model. The procedure is alternated with a continuous optimization of the reconstruction loss, which also regularizes the length of the reconstructed embeddings. Our experiments demonstrate that LAMP reconstructs the original text significantly more precisely than prior work: we recover 5x more bigrams and $23\%$ longer subsequences on average. Moreover, we are first to recover inputs from batch sizes larger than 1 for textual models. These findings indicate that gradient updates of models operating on textual data leak more information than previously thought.
Street-view Panoramic Video Synthesis from a Single Satellite Image
Dec 17, 2020
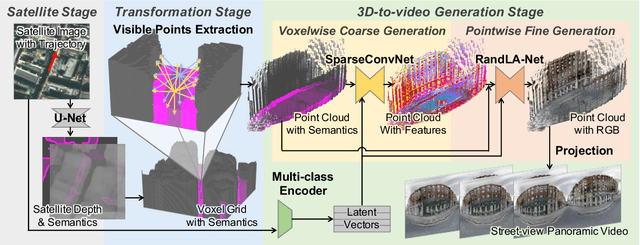


We present a novel method for synthesizing both temporally and geometrically consistent street-view panoramic video from a given single satellite image and camera trajectory. Existing cross-view synthesis approaches focus more on images, while video synthesis in such a case has not yet received enough attention. Single image synthesis approaches are not well suited for video synthesis since they lack temporal consistency which is a crucial property of videos. To this end, our approach explicitly creates a 3D point cloud representation of the scene and maintains dense 3D-2D correspondences across frames that reflect the geometric scene configuration inferred from the satellite view. We implement a cascaded network architecture with two hourglass modules for successive coarse and fine generation for colorizing the point cloud from the semantics and per-class latent vectors. By leveraging computed correspondences, the produced street-view video frames adhere to the 3D geometric scene structure and maintain temporal consistency. Qualitative and quantitative experiments demonstrate superior results compared to other state-of-the-art cross-view synthesis approaches that either lack temporal or geometric consistency. To the best of our knowledge, our work is the first work to synthesize cross-view images to video.
Multi-Label Image Recognition with Multi-Class Attentional Regions
Jul 03, 2020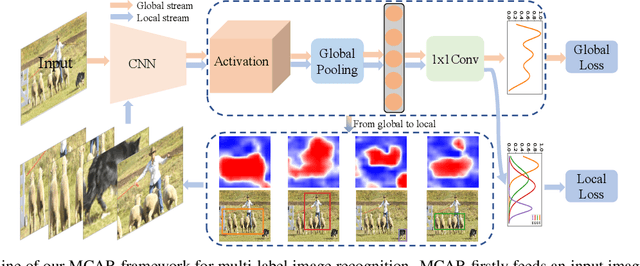
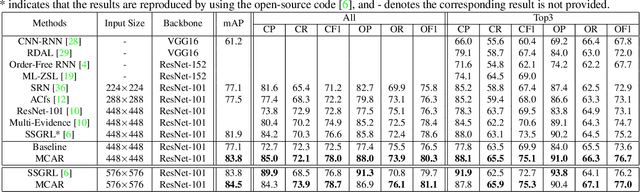
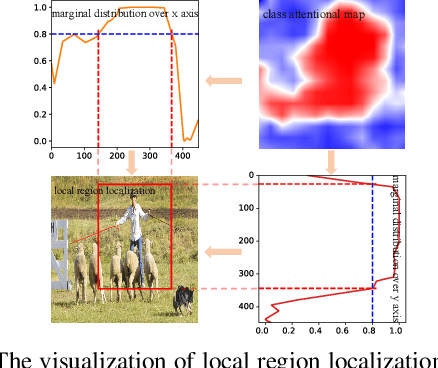
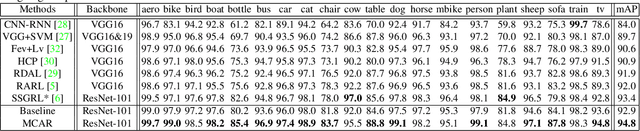
Multi-label image recognition is a practical and challenging task compared to single-label image classification. However, previous works may be suboptimal because of a great number of object proposals or complex attentional region generation modules. In this paper, we propose a simple but efficient two-stream framework to recognize multi-category objects from global image to local regions, similar to how human beings perceive objects. To bridge the gap between global and local streams, we propose a multi-class attentional region module which aims to make the number of attentional regions as small as possible and keep the diversity of these regions as high as possible. Our method can efficiently and effectively recognize multi-class objects with an affordable computation cost and a parameter-free region localization module. Over three benchmarks on multi-label image classification, we create new state-of-the-art results with a single model only using image semantics without label dependency. In addition, the effectiveness of the proposed method is extensively demonstrated under different factors such as global pooling strategy, input size and network architecture.
MedMNIST Classification Decathlon: A Lightweight AutoML Benchmark for Medical Image Analysis
Nov 14, 2020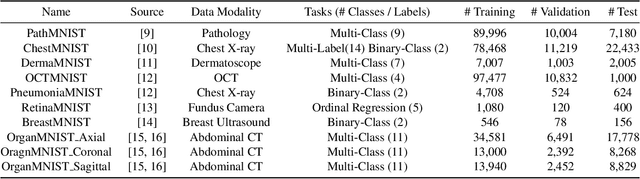
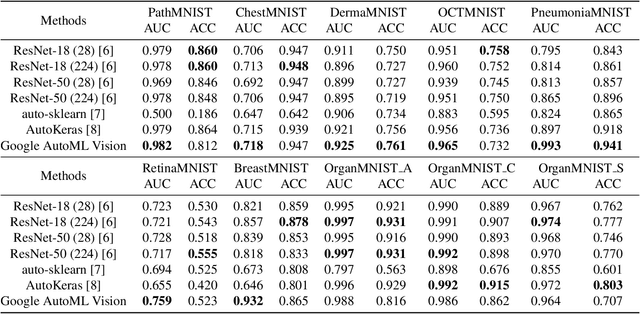

We present MedMNIST, a collection of 10 pre-processed medical open datasets. MedMNIST is standardized to perform classification tasks on lightweight 28x28 images, which requires no background knowledge. Covering the primary data modalities in medical image analysis, it is diverse on data scale (from 100 to 100,000) and tasks (binary/multi-class, ordinal regression and multi-label). MedMNIST could be used for educational purpose, rapid prototyping, multi-modal machine learning or AutoML in medical image analysis. Moreover, MedMNIST Classification Decathlon is designed to benchmark AutoML algorithms on all 10 datasets; We have compared several baseline methods, including open-source or commercial AutoML tools. The datasets, evaluation code and baseline methods for MedMNIST are publicly available at https://medmnist.github.io/.