 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
A-ESRGAN: Training Real-World Blind Super-Resolution with Attention U-Net Discriminators
Dec 19, 2021
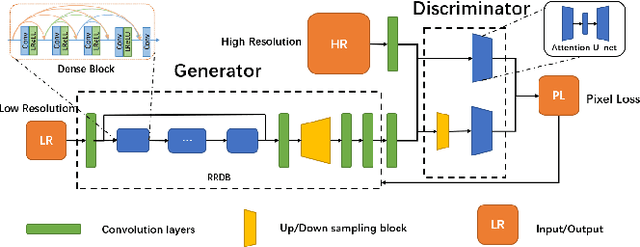

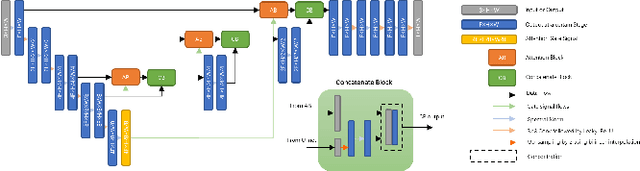
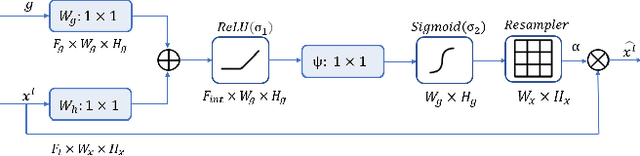
Blind image super-resolution(SR) is a long-standing task in CV that aims to restore low-resolution images suffering from unknown and complex distortions. Recent work has largely focused on adopting more complicated degradation models to emulate real-world degradations. The resulting models have made breakthroughs in perceptual loss and yield perceptually convincing results. However, the limitation brought by current generative adversarial network structures is still significant: treating pixels equally leads to the ignorance of the image's structural features, and results in performance drawbacks such as twisted lines and background over-sharpening or blurring. In this paper, we present A-ESRGAN, a GAN model for blind SR tasks featuring an attention U-Net based, multi-scale discriminator that can be seamlessly integrated with other generators. To our knowledge, this is the first work to introduce attention U-Net structure as the discriminator of GAN to solve blind SR problems. And the paper also gives an interpretation for the mechanism behind multi-scale attention U-Net that brings performance breakthrough to the model. Through comparison experiments with prior works, our model presents state-of-the-art level performance on the non-reference natural image quality evaluator metric. And our ablation studies have shown that with our discriminator, the RRDB based generator can leverage the structural features of an image in multiple scales, and consequently yields more perceptually realistic high-resolution images compared to prior works.
CDNet is all you need: Cascade DCN based underwater object detection RCNN
Nov 25, 2021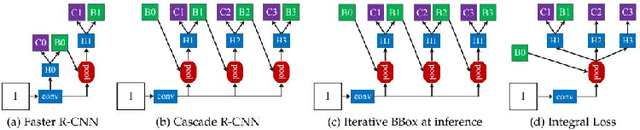
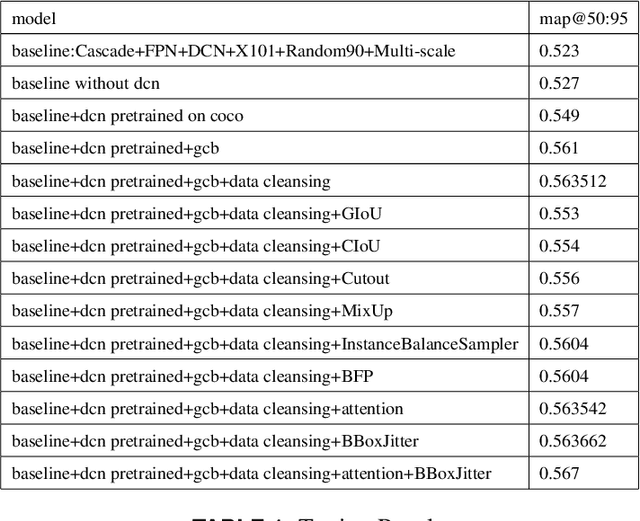
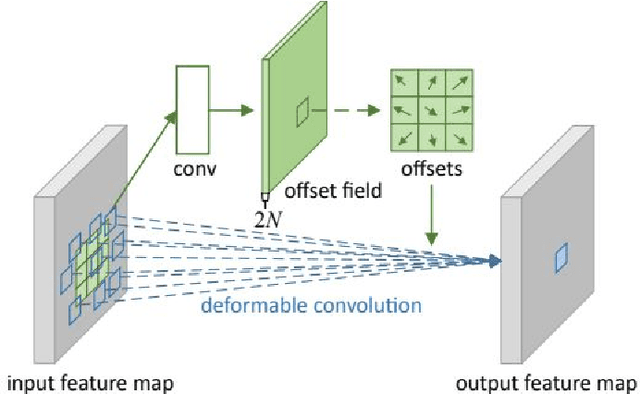
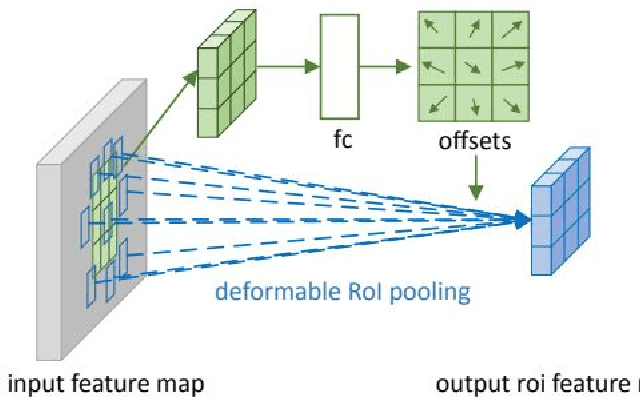
Object detection is a very important basic research direction in the field of computer vision and a basic method for other advanced tasks in the field of computer vision. It has been widely used in practical applications such as object tracking, video behavior recognition and underwater robotics vision. The Cascade-RCNN and Deformable Convolution Network are both classical and excellent object detection algorithms. In this report, we evaluate our Cascade-DCN based method on underwater optical image and acoustics image datasets with different engineering tricks and augumentation.
Analogical Image Translation for Fog Generation
Jun 28, 2020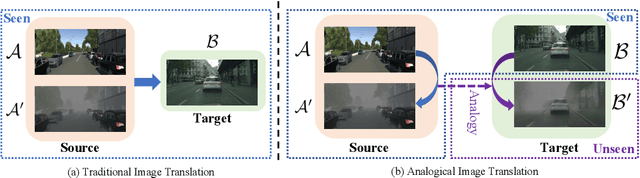
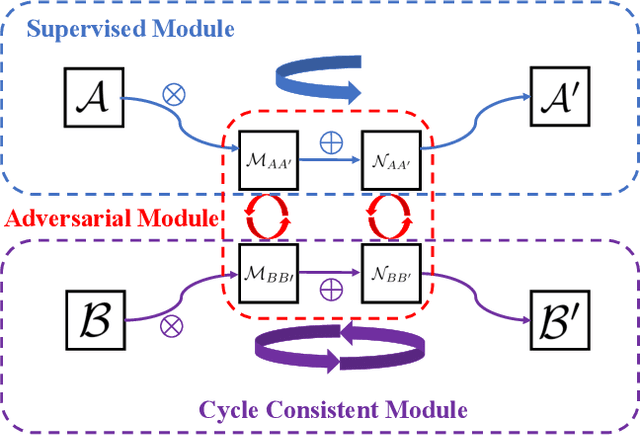
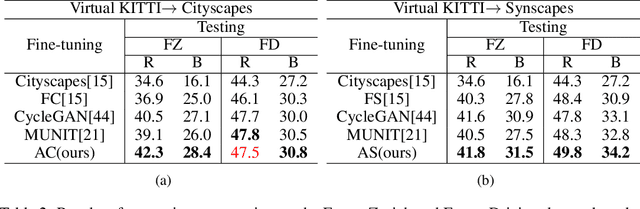

Image-to-image translation is to map images from a given \emph{style} to another given \emph{style}. While exceptionally successful, current methods assume the availability of training images in both source and target domains, which does not always hold in practice. Inspired by humans' reasoning capability of analogy, we propose analogical image translation (AIT). Given images of two styles in the source domain: $\mathcal{A}$ and $\mathcal{A}^\prime$, along with images $\mathcal{B}$ of the first style in the target domain, learn a model to translate $\mathcal{B}$ to $\mathcal{B}^\prime$ in the target domain, such that $\mathcal{A}:\mathcal{A}^\prime ::\mathcal{B}:\mathcal{B}^\prime$. AIT is especially useful for translation scenarios in which training data of one style is hard to obtain but training data of the same two styles in another domain is available. For instance, in the case from normal conditions to extreme, rare conditions, obtaining real training images for the latter case is challenging but obtaining synthetic data for both cases is relatively easy. In this work, we are interested in adding adverse weather effects, more specifically fog effects, to images taken in clear weather. To circumvent the challenge of collecting real foggy images, AIT learns with synthetic clear-weather images, synthetic foggy images and real clear-weather images to add fog effects onto real clear-weather images without seeing any real foggy images during training. AIT achieves this zero-shot image translation capability by coupling a supervised training scheme in the synthetic domain, a cycle consistency strategy in the real domain, an adversarial training scheme between the two domains, and a novel network design. Experiments show the effectiveness of our method for zero-short image translation and its benefit for downstream tasks such as semantic foggy scene understanding.
Right for the Right Reason: Making Image Classification Robust
Jul 23, 2020
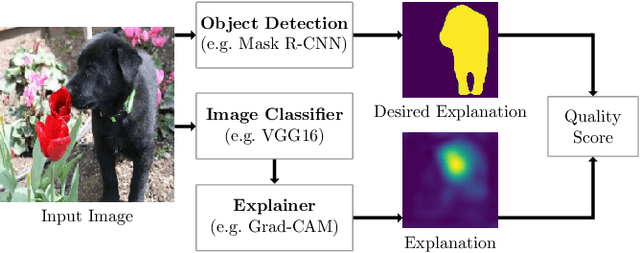
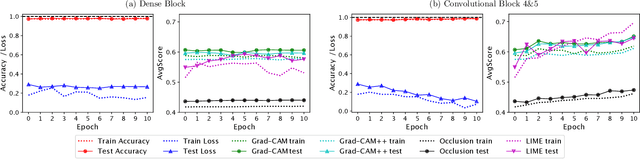

Convolutional neural networks (CNNs) have achieved astonishing performance on various image classification tasks. Although such models classify most images correctly, they do not provide any explanation for their decisions. Recently, there have been attempts to provide such an explanation by determining which parts of the input image the classifier focuses on most. It turns out that many models output the correct classification, but for the wrong reason (e.g., based on irrelevant parts of the image). In this paper, we propose a new score for automatically quantifying to which degree the model focuses on the right image parts. The score is calculated by considering the degree to which the most decisive image regions - given by applying an explainer to the CNN model - overlap with the silhouette of the object to be classified. In extensive experiments using VGG16, ResNet, and MobileNet as CNNs, Occlusion, LIME, and Grad-Cam/Grad-Cam++ as explanation methods, and Dogs vs. Cats and Caltech 101 as data sets, we can show that our metric can indeed be used for making CNN models for image classification more robust while keeping their accuracy.
NVS-MonoDepth: Improving Monocular Depth Prediction with Novel View Synthesis
Dec 22, 2021
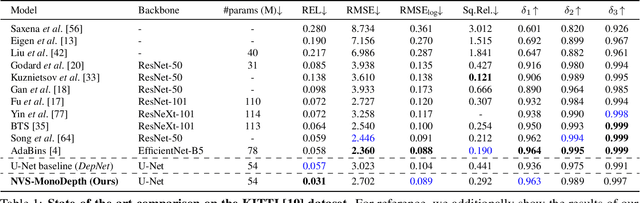
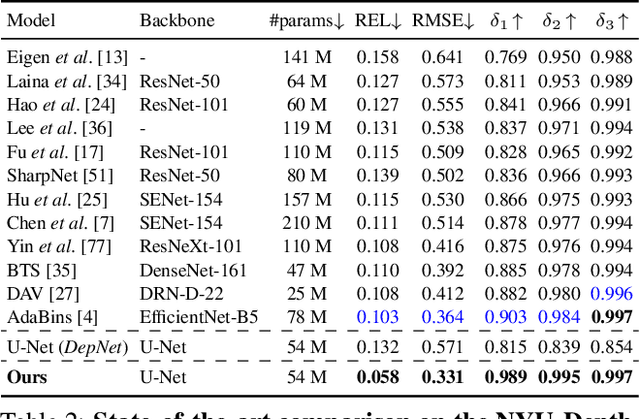
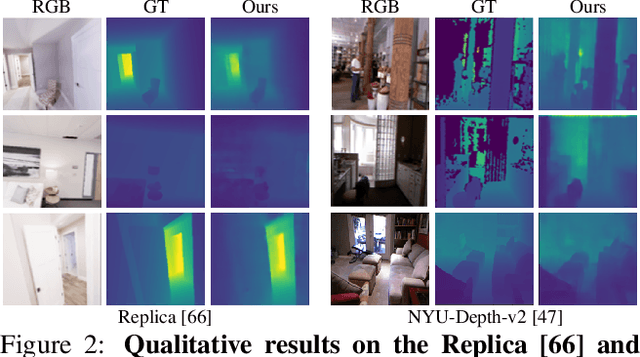
Building upon the recent progress in novel view synthesis, we propose its application to improve monocular depth estimation. In particular, we propose a novel training method split in three main steps. First, the prediction results of a monocular depth network are warped to an additional view point. Second, we apply an additional image synthesis network, which corrects and improves the quality of the warped RGB image. The output of this network is required to look as similar as possible to the ground-truth view by minimizing the pixel-wise RGB reconstruction error. Third, we reapply the same monocular depth estimation onto the synthesized second view point and ensure that the depth predictions are consistent with the associated ground truth depth. Experimental results prove that our method achieves state-of-the-art or comparable performance on the KITTI and NYU-Depth-v2 datasets with a lightweight and simple vanilla U-Net architecture.
* 8 pages (main paper), 9 pages (supplementary material), 14 figures, 4 tables
SURDS: Self-Supervised Attention-guided Reconstruction and Dual Triplet Loss for Writer Independent Offline Signature Verification
Jan 25, 2022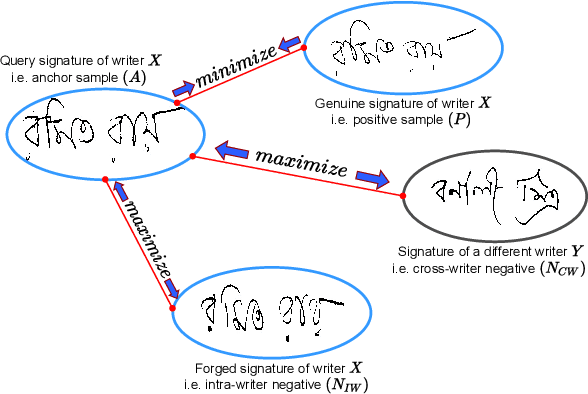

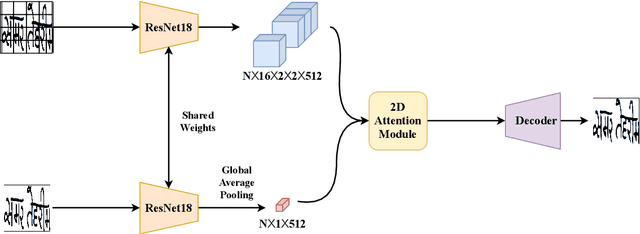
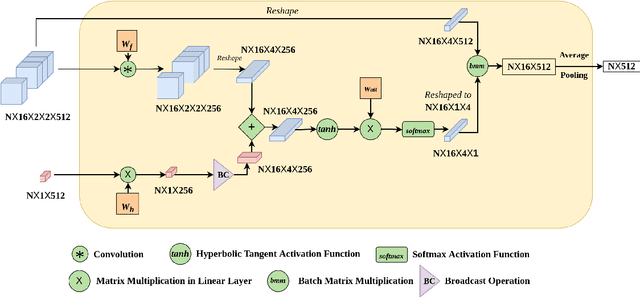
Offline Signature Verification (OSV) is a fundamental biometric task across various forensic, commercial and legal applications. The underlying task at hand is to carefully model fine-grained features of the signatures to distinguish between genuine and forged ones, which differ only in minute deformities. This makes OSV more challenging compared to other verification problems. In this work, we propose a two-stage deep learning framework that leverages self-supervised representation learning as well as metric learning for writer-independent OSV. First, we train an image reconstruction network using an encoder-decoder architecture that is augmented by a 2D spatial attention mechanism using signature image patches. Next, the trained encoder backbone is fine-tuned with a projector head using a supervised metric learning framework, whose objective is to optimize a novel dual triplet loss by sampling negative samples from both within the same writer class as well as from other writers. The intuition behind this is to ensure that a signature sample lies closer to its positive counterpart compared to negative samples from both intra-writer and cross-writer sets. This results in robust discriminative learning of the embedding space. To the best of our knowledge, this is the first work of using self-supervised learning frameworks for OSV. The proposed two-stage framework has been evaluated on two publicly available offline signature datasets and compared with various state-of-the-art methods. It is noted that the proposed method provided promising results outperforming several existing pieces of work.
ADVISE: ADaptive Feature Relevance and VISual Explanations for Convolutional Neural Networks
Mar 02, 2022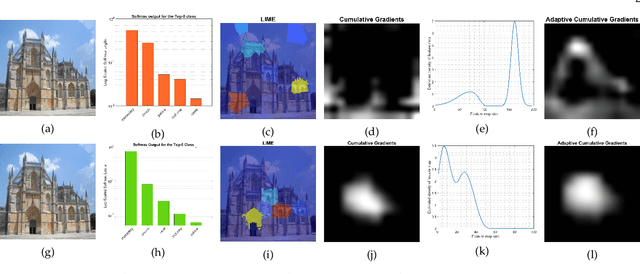
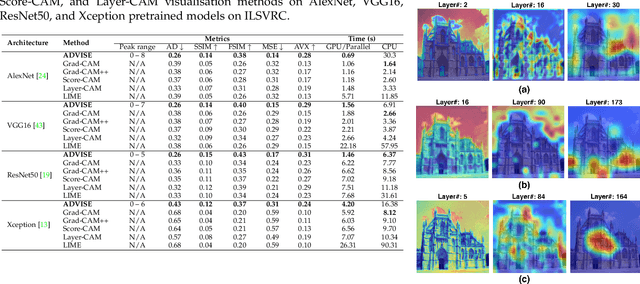
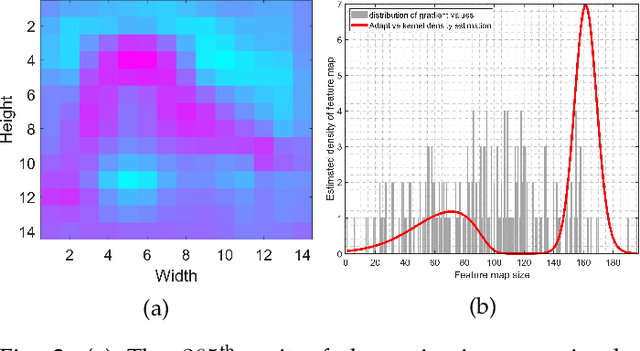
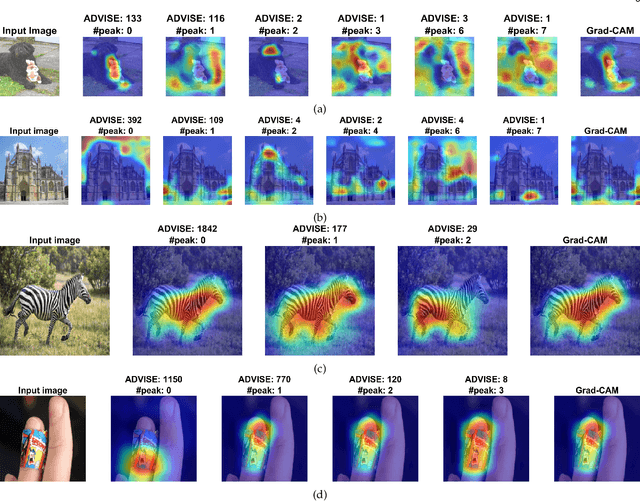
To equip Convolutional Neural Networks (CNNs) with explainability, it is essential to interpret how opaque models take specific decisions, understand what causes the errors, improve the architecture design, and identify unethical biases in the classifiers. This paper introduces ADVISE, a new explainability method that quantifies and leverages the relevance of each unit of the feature map to provide better visual explanations. To this end, we propose using adaptive bandwidth kernel density estimation to assign a relevance score to each unit of the feature map with respect to the predicted class. We also propose an evaluation protocol to quantitatively assess the visual explainability of CNN models. We extensively evaluate our idea in the image classification task using AlexNet, VGG16, ResNet50, and Xception pretrained on ImageNet. We compare ADVISE with the state-of-the-art visual explainable methods and show that the proposed method outperforms competing approaches in quantifying feature-relevance and visual explainability while maintaining competitive time complexity. Our experiments further show that ADVISE fulfils the sensitivity and implementation independence axioms while passing the sanity checks. The implementation is accessible for reproducibility purposes on https://github.com/dehshibi/ADVISE.
Soft Expectation and Deep Maximization for Image Feature Detection
Apr 21, 2021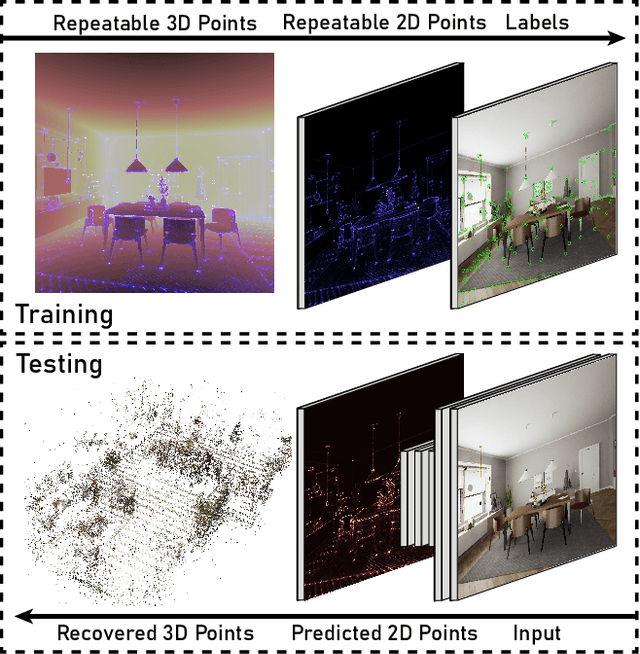
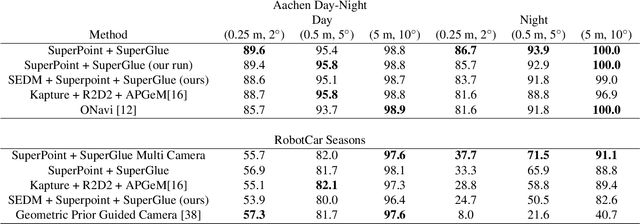
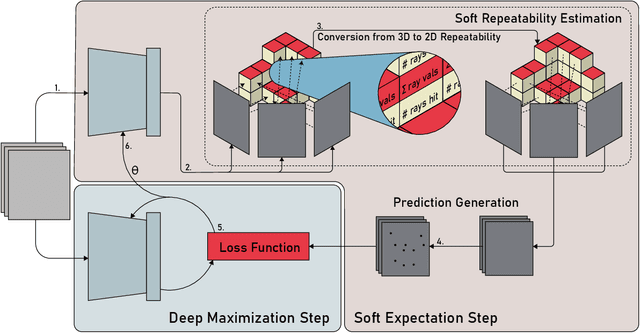
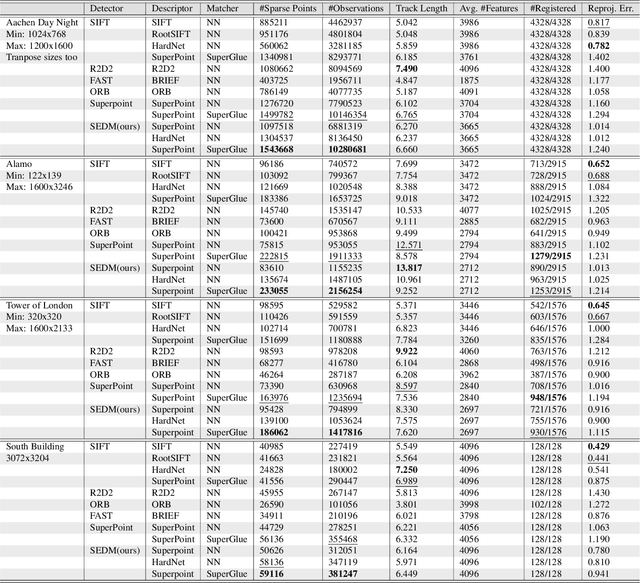
Central to the application of many multi-view geometry algorithms is the extraction of matching points between multiple viewpoints, enabling classical tasks such as camera pose estimation and 3D reconstruction. Over the decades, many approaches that characterize these points have been proposed based on hand-tuned appearance models and more recently data-driven learning methods. We propose SEDM, an iterative semi-supervised learning process that flips the question and first looks for repeatable 3D points, then trains a detector to localize them in image space. Our technique poses the problem as one of expectation maximization (EM), where the likelihood of the detector locating the 3D points is the objective function to be maximized. We utilize the geometry of the scene to refine the estimates of the location of these 3D points and produce a new pseudo ground truth during the expectation step, then train a detector to predict this pseudo ground truth in the maximization step. We apply our detector to standard benchmarks in visual localization, sparse 3D reconstruction, and mean matching accuracy. Our results show that this new model trained using SEDM is able to better localize the underlying 3D points in a scene, improving mean SfM quality by $-0.15\pm0.11$ mean reprojection error when compared to SuperPoint or $-0.38\pm0.23$ when compared to R2D2.
Characterisation of CMOS Image Sensor Performance in Low Light Automotive Applications
Nov 24, 2020

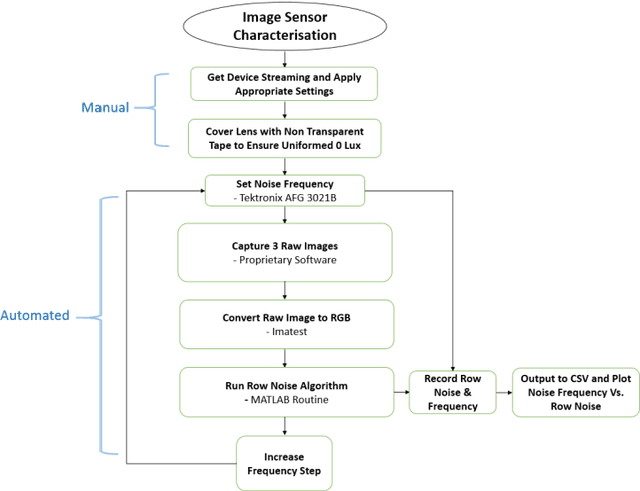
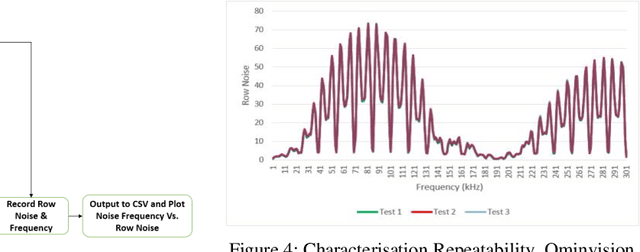
The applications of automotive cameras in Advanced Driver-Assistance Systems (ADAS) are growing rapidly as automotive manufacturers strive to provide 360 degree protection for their customers. Vision systems must capture high quality images in both daytime and night-time scenarios in order to produce the large informational content required for software analysis in applications such as lane departure, pedestrian detection and collision detection. The challenge in producing high quality images in low light scenarios is that the signal to noise ratio is greatly reduced. This can result in noise becoming the dominant factor in a captured image thereby making these safety systems less effective at night. This paper outlines a systematic method for characterisation of state of the art image sensor performance in response to noise, so as to improve the design and performance of automotive cameras in low light scenarios. The experiment outlined in this paper demonstrates how this method can be used to characterise the performance of CMOS image sensors in response to electrical noise on the power supply lines.
Screentone-Preserved Manga Retargeting
Mar 07, 2022
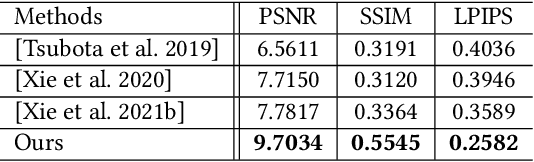
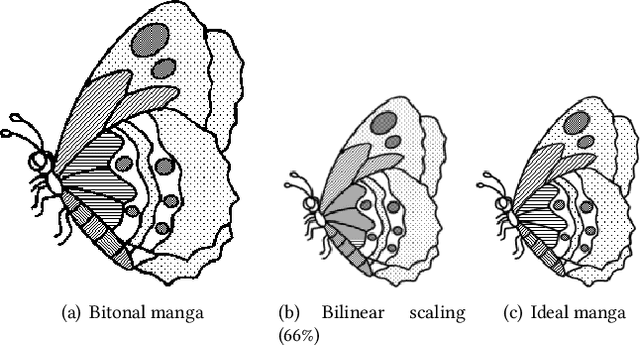
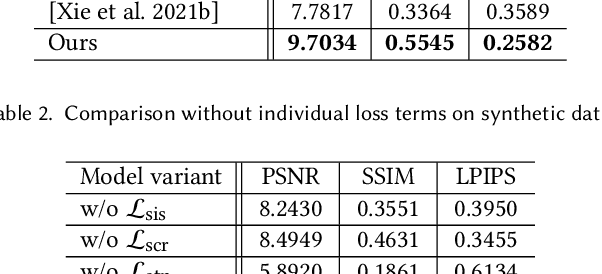
As a popular comic style, manga offers a unique impression by utilizing a rich set of bitonal patterns, or screentones, for illustration. However, screentones can easily be contaminated with visual-unpleasant aliasing and/or blurriness after resampling, which harms its visualization on displays of diverse resolutions. To address this problem, we propose the first manga retargeting method that synthesizes a rescaled manga image while retaining the screentone in each screened region. This is a non-trivial task as accurate region-wise segmentation remains challenging. Fortunately, the rescaled manga shares the same region-wise screentone correspondences with the original manga, which enables us to simplify the screentone synthesis problem as an anchor-based proposals selection and rearrangement problem. Specifically, we design a novel manga sampling strategy to generate aliasing-free screentone proposals, based on hierarchical grid-based anchors that connect the correspondences between the original and the target rescaled manga. Furthermore, a Recurrent Proposal Selection Module (RPSM) is proposed to adaptively integrate these proposals for target screentone synthesis. Besides, to deal with the translation insensitivity nature of screentones, we propose a translation-invariant screentone loss to facilitate the training convergence. Extensive qualitative and quantitative experiments are conducted to verify the effectiveness of our method, and notably compelling results are achieved compared to existing alternative techniques.