 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Parallel Training of GRU Networks with a Multi-Grid Solver for Long Sequences
Mar 07, 2022


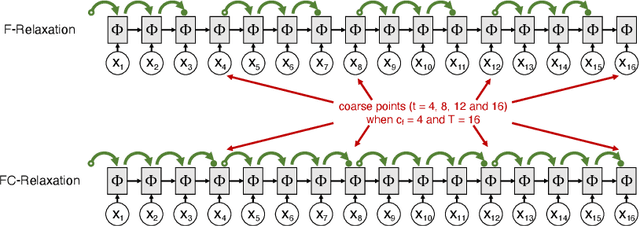

Parallelizing Gated Recurrent Unit (GRU) networks is a challenging task, as the training procedure of GRU is inherently sequential. Prior efforts to parallelize GRU have largely focused on conventional parallelization strategies such as data-parallel and model-parallel training algorithms. However, when the given sequences are very long, existing approaches are still inevitably performance limited in terms of training time. In this paper, we present a novel parallel training scheme (called parallel-in-time) for GRU based on a multigrid reduction in time (MGRIT) solver. MGRIT partitions a sequence into multiple shorter sub-sequences and trains the sub-sequences on different processors in parallel. The key to achieving speedup is a hierarchical correction of the hidden state to accelerate end-to-end communication in both the forward and backward propagation phases of gradient descent. Experimental results on the HMDB51 dataset, where each video is an image sequence, demonstrate that the new parallel training scheme achieves up to 6.5$\times$ speedup over a serial approach. As efficiency of our new parallelization strategy is associated with the sequence length, our parallel GRU algorithm achieves significant performance improvement as the sequence length increases.
Tangles and Hierarchical Clustering
Mar 16, 2022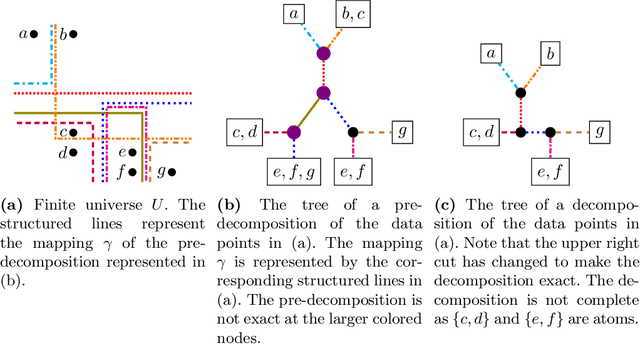
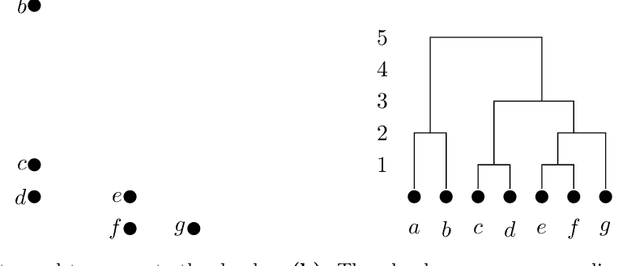
We establish a connection between tangles, a concept from structural graph theory that plays a central role in Robertson and Seymour's graph minor project, and hierarchical clustering. Tangles cannot only be defined for graphs, but in fact for arbitrary connectivity functions, which are functions defined on the subsets of some finite universe. In typical clustering applications these universes consist of points in some metric space. Connectivity functions are usually required to be submodular. It is our first contribution to show that the central duality theorem connecting tangles with hierarchical decompositions (so-called branch decompositions) also holds if submodularity is replaced by a different property that we call maximum-submodular. We then define a connectivity function on finite data sets in an arbitrary metric space and prove that its tangles are in one-to-one correspondence with the clusters obtained by applying the well-known single linkage clustering algorithms to the same data set. Lastly we generalize this correspondence for any hierarchical clustering. We show that the data structure that represents hierarchical clustering results, called dendograms, are equivalent to maximum-submodular connectivity functions and their tangles. The idea of viewing tangles as clusters has first been proposed by Diestel and Whittle in 2016 as an approach to image segmentation. To the best of our knowledge, our result is the first that establishes a precise technical connection between tangles and clusters.
Deblurring via Stochastic Refinement
Dec 05, 2021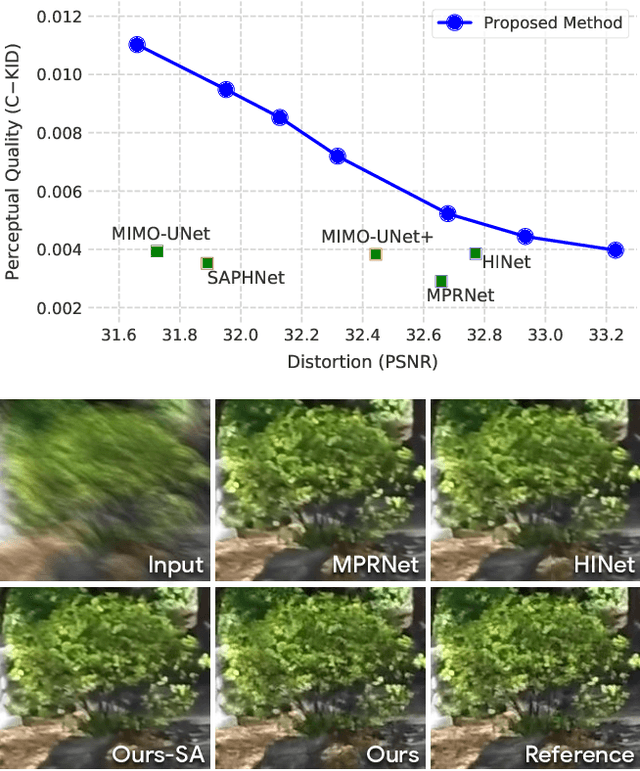
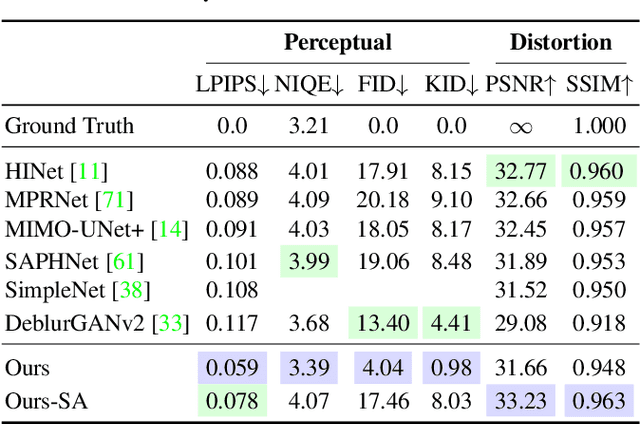
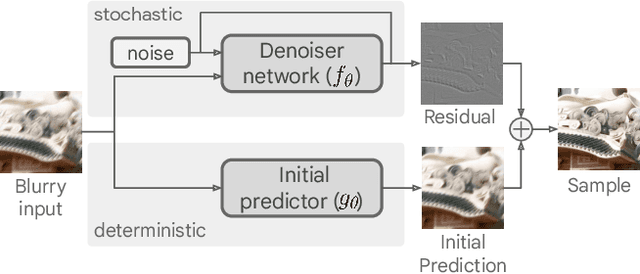

Image deblurring is an ill-posed problem with multiple plausible solutions for a given input image. However, most existing methods produce a deterministic estimate of the clean image and are trained to minimize pixel-level distortion. These metrics are known to be poorly correlated with human perception, and often lead to unrealistic reconstructions. We present an alternative framework for blind deblurring based on conditional diffusion models. Unlike existing techniques, we train a stochastic sampler that refines the output of a deterministic predictor and is capable of producing a diverse set of plausible reconstructions for a given input. This leads to a significant improvement in perceptual quality over existing state-of-the-art methods across multiple standard benchmarks. Our predict-and-refine approach also enables much more efficient sampling compared to typical diffusion models. Combined with a carefully tuned network architecture and inference procedure, our method is competitive in terms of distortion metrics such as PSNR. These results show clear benefits of our diffusion-based method for deblurring and challenge the widely used strategy of producing a single, deterministic reconstruction.
A Two-Block RNN-based Trajectory Prediction from Incomplete Trajectory
Mar 16, 2022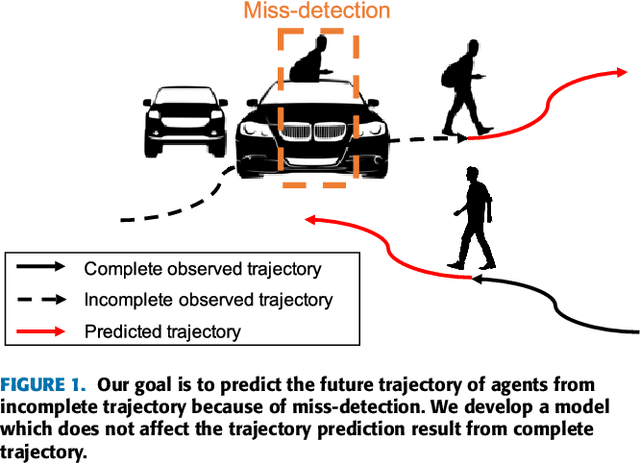
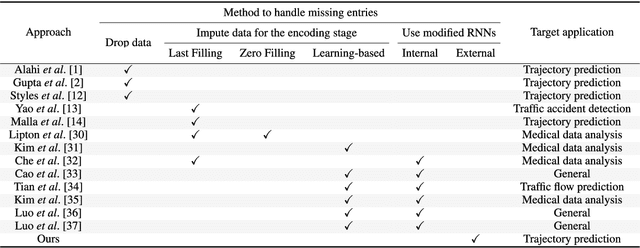

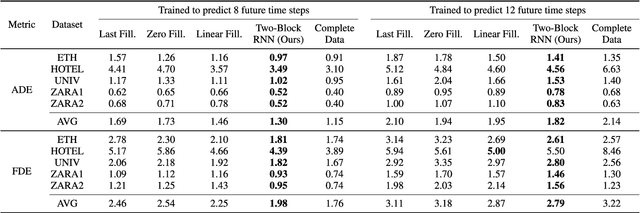
Trajectory prediction has gained great attention and significant progress has been made in recent years. However, most works rely on a key assumption that each video is successfully preprocessed by detection and tracking algorithms and the complete observed trajectory is always available. However, in complex real-world environments, we often encounter miss-detection of target agents (e.g., pedestrian, vehicles) caused by the bad image conditions, such as the occlusion by other agents. In this paper, we address the problem of trajectory prediction from incomplete observed trajectory due to miss-detection, where the observed trajectory includes several missing data points. We introduce a two-block RNN model that approximates the inference steps of the Bayesian filtering framework and seeks the optimal estimation of the hidden state when miss-detection occurs. The model uses two RNNs depending on the detection result. One RNN approximates the inference step of the Bayesian filter with the new measurement when the detection succeeds, while the other does the approximation when the detection fails. Our experiments show that the proposed model improves the prediction accuracy compared to the three baseline imputation methods on publicly available datasets: ETH and UCY ($9\%$ and $7\%$ improvement on the ADE and FDE metrics). We also show that our proposed method can achieve better prediction compared to the baselines when there is no miss-detection.
Diagonal Attention and Style-based GAN for Content-Style Disentanglement in Image Generation and Translation
Mar 30, 2021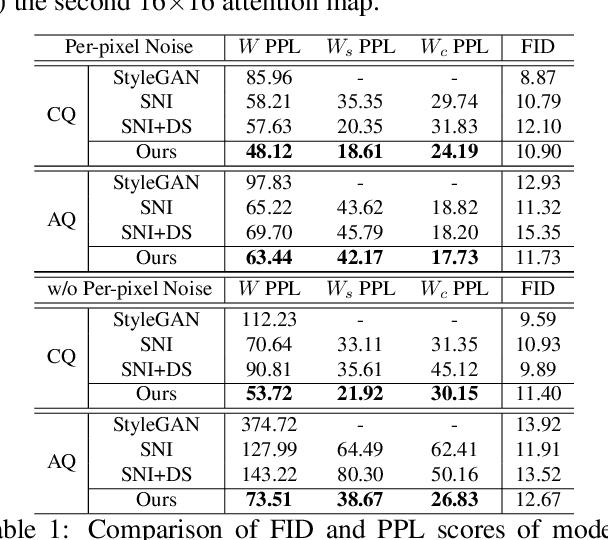
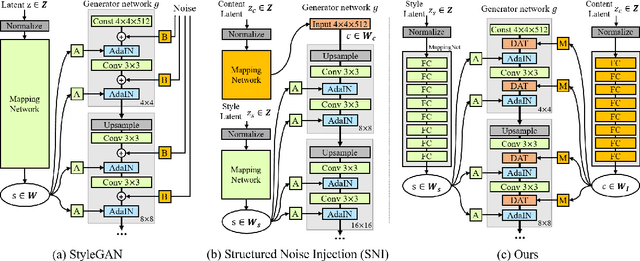
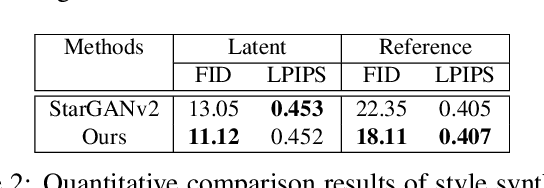
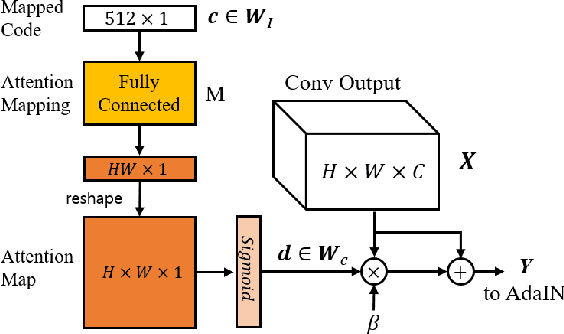
One of the important research topics in image generative models is to disentangle the spatial contents and styles for their separate control. Although StyleGAN can generate content feature vectors from random noises, the resulting spatial content control is primarily intended for minor spatial variations, and the disentanglement of global content and styles is by no means complete. Inspired by a mathematical understanding of normalization and attention, here we present a novel hierarchical adaptive Diagonal spatial ATtention (DAT) layers to separately manipulate the spatial contents from styles in a hierarchical manner. Using DAT and AdaIN, our method enables coarse-to-fine level disentanglement of spatial contents and styles. In addition, our generator can be easily integrated into the GAN inversion framework so that the content and style of translated images from multi-domain image translation tasks can be flexibly controlled. By using various datasets, we confirm that the proposed method not only outperforms the existing models in disentanglement scores, but also provides more flexible control over spatial features in the generated images.
GCNDepth: Self-supervised Monocular Depth Estimation based on Graph Convolutional Network
Dec 13, 2021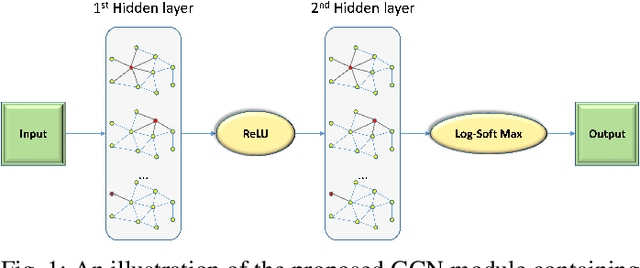
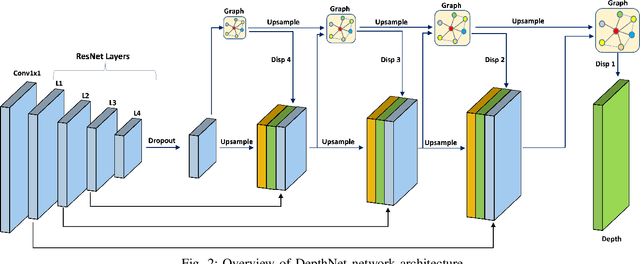

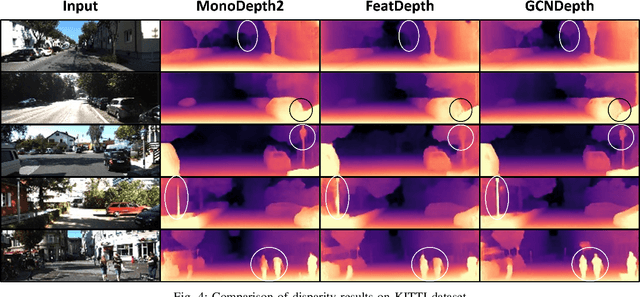
Depth estimation is a challenging task of 3D reconstruction to enhance the accuracy sensing of environment awareness. This work brings a new solution with a set of improvements, which increase the quantitative and qualitative understanding of depth maps compared to existing methods. Recently, a convolutional neural network (CNN) has demonstrated its extraordinary ability in estimating depth maps from monocular videos. However, traditional CNN does not support topological structure and they can work only on regular image regions with determined size and weights. On the other hand, graph convolutional networks (GCN) can handle the convolution on non-Euclidean data and it can be applied to irregular image regions within a topological structure. Therefore, in this work in order to preserve object geometric appearances and distributions, we aim at exploiting GCN for a self-supervised depth estimation model. Our model consists of two parallel auto-encoder networks: the first is an auto-encoder that will depend on ResNet-50 and extract the feature from the input image and on multi-scale GCN to estimate the depth map. In turn, the second network will be used to estimate the ego-motion vector (i.e., 3D pose) between two consecutive frames based on ResNet-18. Both the estimated 3D pose and depth map will be used for constructing a target image. A combination of loss functions related to photometric, projection, and smoothness is used to cope with bad depth prediction and preserve the discontinuities of the objects. In particular, our method provided comparable and promising results with a high prediction accuracy of 89% on the publicly KITTI and Make3D datasets along with a reduction of 40% in the number of trainable parameters compared to the state of the art solutions. The source code is publicly available at https://github.com/ArminMasoumian/GCNDepth.git
Confidence Guided Depth Completion Network
Feb 07, 2022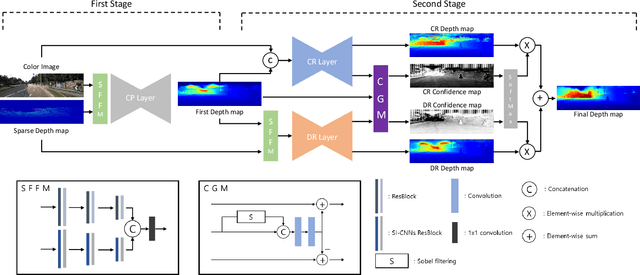
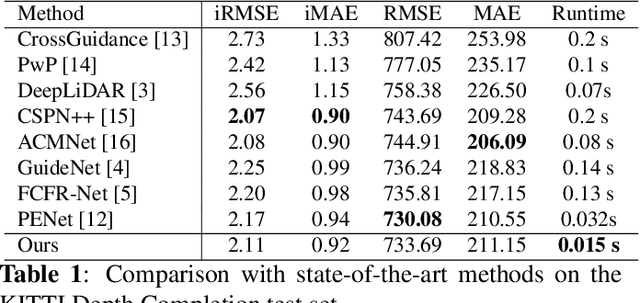

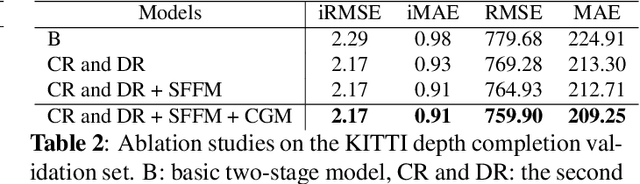
The paper proposes an image-guided depth completion method to estimate accurate dense depth maps with fast computation time. The proposed network has two-stage structure. The first stage predicts a first depth map. Then, the second stage further refines the first depth map using the confidence maps. The second stage consists of two layers, each of which focuses on different regions and generates a refined depth map and a confidence map. The final depth map is obtained by combining two depth maps from the second stage using the corresponding confidence maps. Compared with the top-ranked models on the KITTI depth completion online leaderboard, the proposed model shows much faster computation time and competitive performance.
NUQ: Nonparametric Uncertainty Quantification for Deterministic Neural Networks
Feb 07, 2022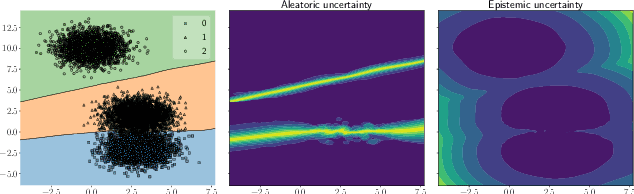

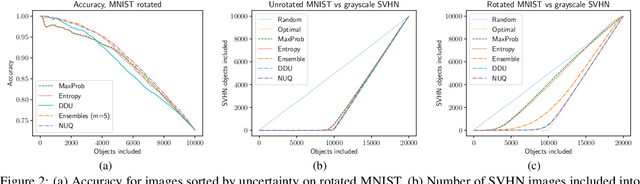

This paper proposes a fast and scalable method for uncertainty quantification of machine learning models' predictions. First, we show the principled way to measure the uncertainty of predictions for a classifier based on Nadaraya-Watson's nonparametric estimate of the conditional label distribution. Importantly, the approach allows to disentangle explicitly aleatoric and epistemic uncertainties. The resulting method works directly in the feature space. However, one can apply it to any neural network by considering an embedding of the data induced by the network. We demonstrate the strong performance of the method in uncertainty estimation tasks on a variety of real-world image datasets, such as MNIST, SVHN, CIFAR-100 and several versions of ImageNet.
Worldsheet: Wrapping the World in a 3D Sheet for View Synthesis from a Single Image
Dec 17, 2020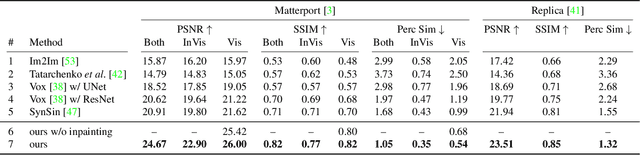
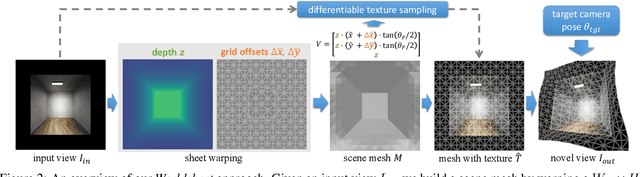
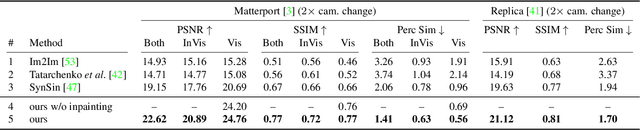

We present Worldsheet, a method for novel view synthesis using just a single RGB image as input. This is a challenging problem as it requires an understanding of the 3D geometry of the scene as well as texture mapping to generate both visible and occluded regions from new view-points. Our main insight is that simply shrink-wrapping a planar mesh sheet onto the input image, consistent with the learned intermediate depth, captures underlying geometry sufficient enough to generate photorealistic unseen views with arbitrarily large view-point changes. To operationalize this, we propose a novel differentiable texture sampler that allows our wrapped mesh sheet to be textured; which is then transformed into a target image via differentiable rendering. Our approach is category-agnostic, end-to-end trainable without using any 3D supervision and requires a single image at test time. Worldsheet consistently outperforms prior state-of-the-art methods on single-image view synthesis across several datasets. Furthermore, this simple idea captures novel views surprisingly well on a wide range of high resolution in-the-wild images in converting them into a navigable 3D pop-up. Video results and code at https://worldsheet.github.io
Enhanced Transfer Learning Through Medical Imaging and Patient Demographic Data Fusion
Nov 29, 2021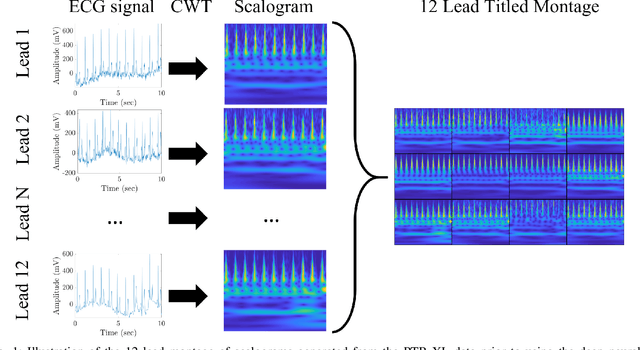
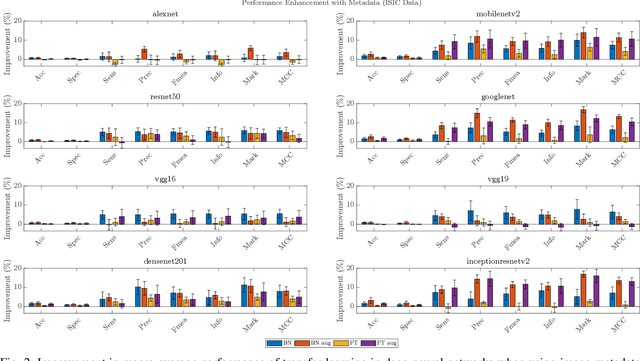
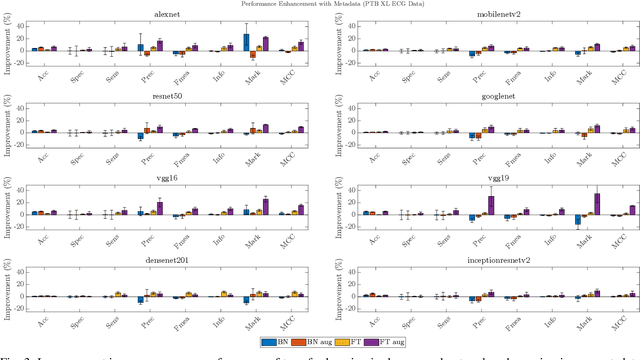
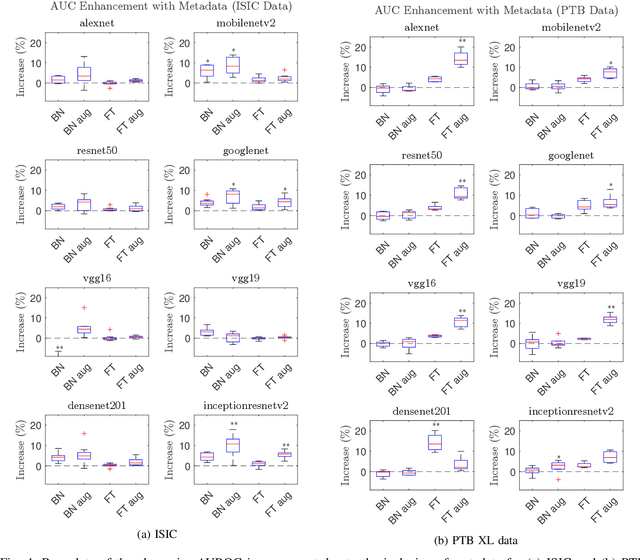
In this work we examine the performance enhancement in classification of medical imaging data when image features are combined with associated non-image data. We compare the performance of eight state-of-the-art deep neural networks in classification tasks when using only image features, compared to when these are combined with patient metadata. We utilise transfer learning with networks pretrained on ImageNet used directly as feature extractors and fine tuned on the target domain. Our experiments show that performance can be significantly enhanced with the inclusion of metadata and use interpretability methods to identify which features lead to these enhancements. Furthermore, our results indicate that the performance enhancement for natural medical imaging (e.g. optical images) benefit most from direct use of pre-trained models, whereas non natural images (e.g. representations of non imaging data) benefit most from fine tuning pre-trained networks. These enhancements come at a negligible additional cost in computation time, and therefore is a practical method for other applications.