 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Parking Analytics Framework using Deep Learning
Mar 15, 2022
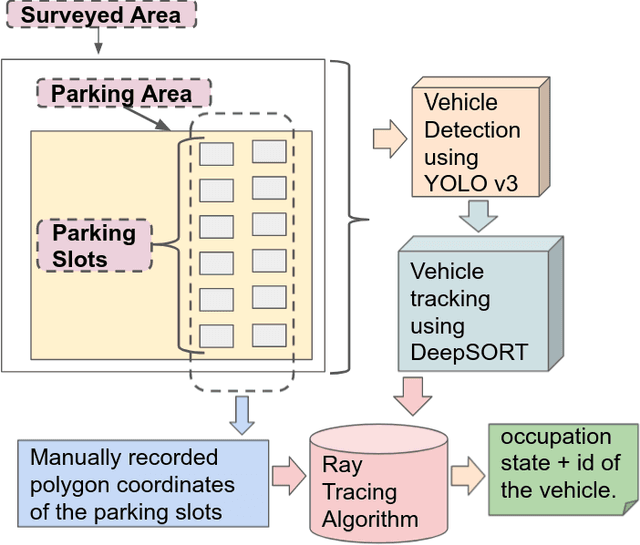
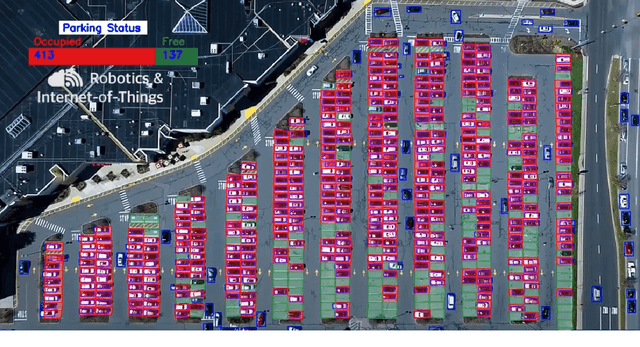
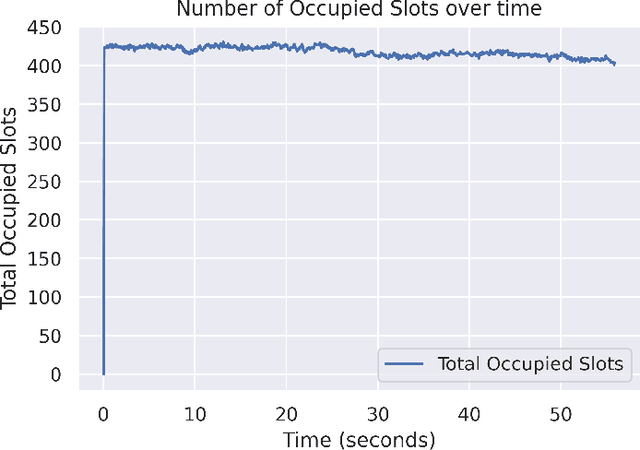
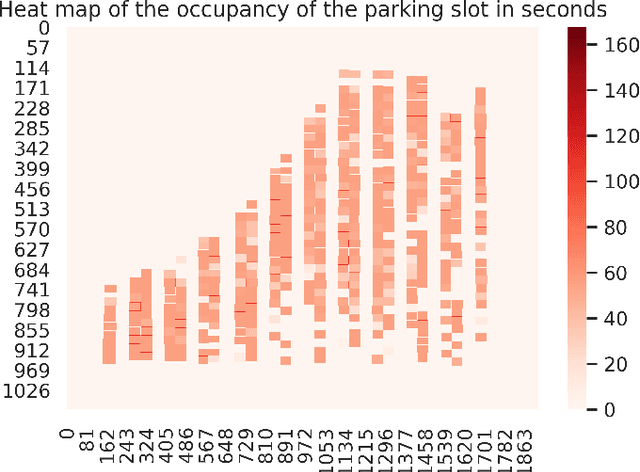
With the number of vehicles continuously increasing, parking monitoring and analysis are becoming a substantial feature of modern cities. In this study, we present a methodology to monitor car parking areas and to analyze their occupancy in real-time. The solution is based on a combination between image analysis and deep learning techniques. It incorporates four building blocks put inside a pipeline: vehicle detection, vehicle tracking, manual annotation of parking slots, and occupancy estimation using the Ray Tracing algorithm. The aim of this methodology is to optimize the use of parking areas and to reduce the time wasted by daily drivers to find the right parking slot for their cars. Also, it helps to better manage the space of the parking areas and to discover misuse cases. A demonstration of the provided solution is shown in the following video link: https://www.youtube.com/watch?v=KbAt8zT14Tc.
Semantic-Aware Domain Generalized Segmentation
Apr 02, 2022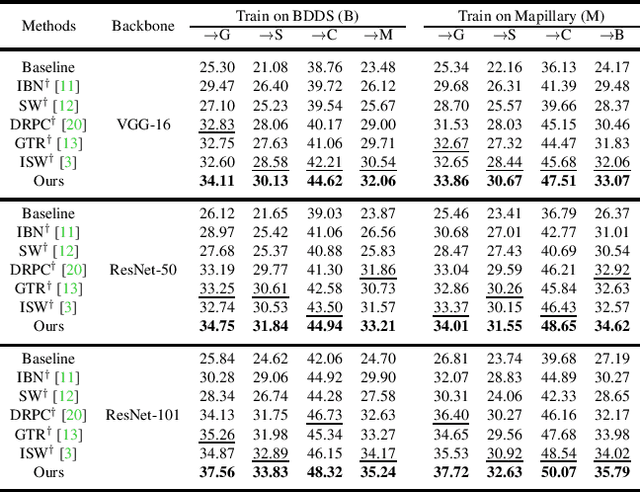
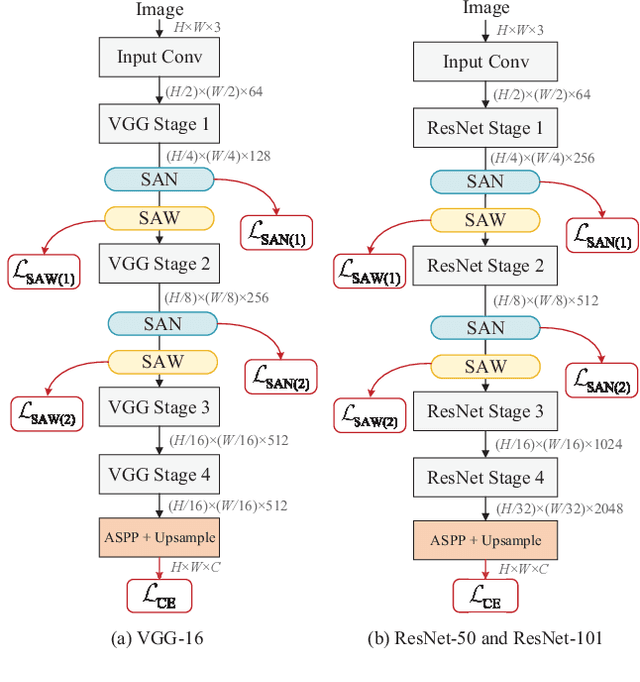
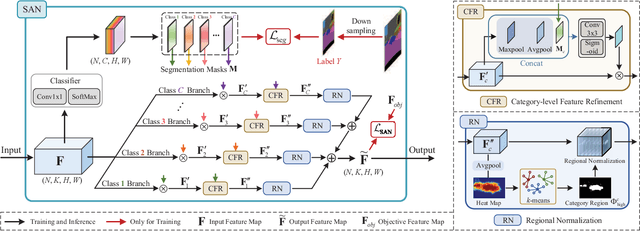

Deep models trained on source domain lack generalization when evaluated on unseen target domains with different data distributions. The problem becomes even more pronounced when we have no access to target domain samples for adaptation. In this paper, we address domain generalized semantic segmentation, where a segmentation model is trained to be domain-invariant without using any target domain data. Existing approaches to tackle this problem standardize data into a unified distribution. We argue that while such a standardization promotes global normalization, the resulting features are not discriminative enough to get clear segmentation boundaries. To enhance separation between categories while simultaneously promoting domain invariance, we propose a framework including two novel modules: Semantic-Aware Normalization (SAN) and Semantic-Aware Whitening (SAW). Specifically, SAN focuses on category-level center alignment between features from different image styles, while SAW enforces distributed alignment for the already center-aligned features. With the help of SAN and SAW, we encourage both intra-category compactness and inter-category separability. We validate our approach through extensive experiments on widely-used datasets (i.e. GTAV, SYNTHIA, Cityscapes, Mapillary and BDDS). Our approach shows significant improvements over existing state-of-the-art on various backbone networks. Code is available at https://github.com/leolyj/SAN-SAW
Learning Consistency from High-quality Pseudo-labels for Weakly Supervised Object Localization
Mar 18, 2022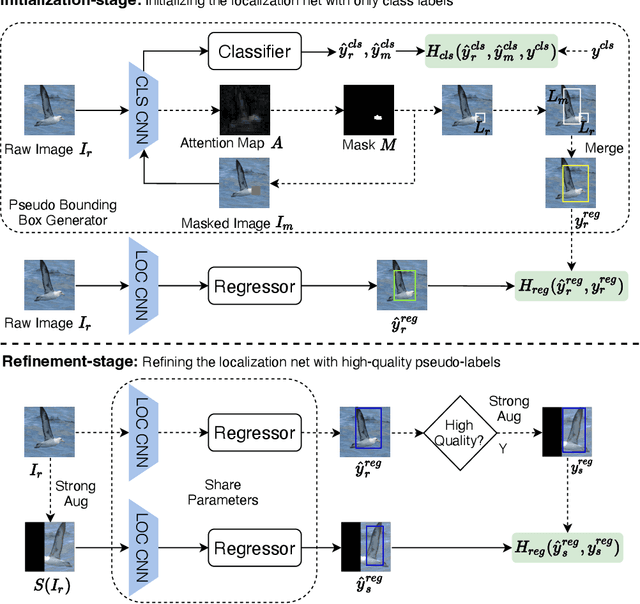
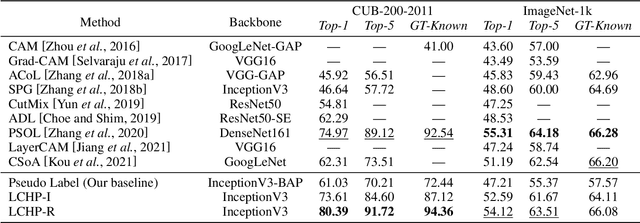

Pseudo-supervised learning methods have been shown to be effective for weakly supervised object localization tasks. However, the effectiveness depends on the powerful regularization ability of deep neural networks. Based on the assumption that the localization network should have similar location predictions on different versions of the same image, we propose a two-stage approach to learn more consistent localization. In the first stage, we propose a mask-based pseudo label generator algorithm, and use the pseudo-supervised learning method to initialize an object localization network. In the second stage, we propose a simple and effective method for evaluating the confidence of pseudo-labels based on classification discrimination, and by learning consistency from high-quality pseudo-labels, we further refine the localization network to get better localization performance. Experimental results show that our proposed approach achieves excellent performance in three benchmark datasets including CUB-200-2011, ImageNet-1k and Tiny-ImageNet, which demonstrates its effectiveness.
ShowFace: Coordinated Face Inpainting with Memory-Disentangled Refinement Networks
Apr 06, 2022
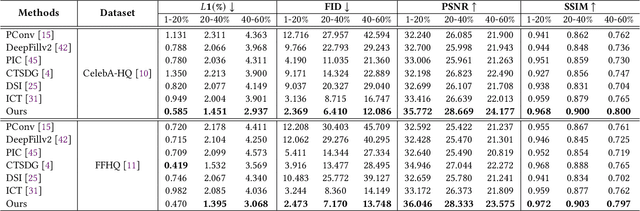
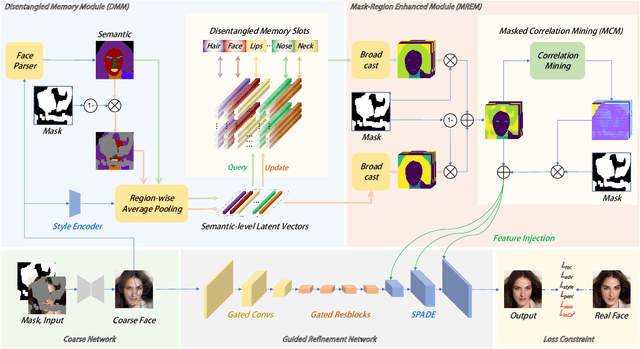
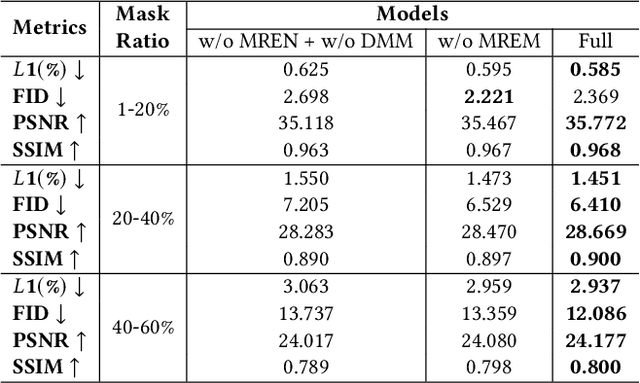
Face inpainting aims to complete the corrupted regions of the face images, which requires coordination between the completed areas and the non-corrupted areas. Recently, memory-oriented methods illustrate great prospects in the generation related tasks by introducing an external memory module to improve image coordination. However, such methods still have limitations in restoring the consistency and continuity for specificfacial semantic parts. In this paper, we propose the coarse-to-fine Memory-Disentangled Refinement Networks (MDRNets) for coordinated face inpainting, in which two collaborative modules are integrated, Disentangled Memory Module (DMM) and Mask-Region Enhanced Module (MREM). Specifically, the DMM establishes a group of disentangled memory blocks to store the semantic-decoupled face representations, which could provide the most relevant information to refine the semantic-level coordination. The MREM involves a masked correlation mining mechanism to enhance the feature relationships into the corrupted regions, which could also make up for the correlation loss caused by memory disentanglement. Furthermore, to better improve the inter-coordination between the corrupted and non-corrupted regions and enhance the intra-coordination in corrupted regions, we design InCo2 Loss, a pair of similarity based losses to constrain the feature consistency. Eventually, extensive experiments conducted on CelebA-HQ and FFHQ datasets demonstrate the superiority of our MDRNets compared with previous State-Of-The-Art methods.
MonoDTR: Monocular 3D Object Detection with Depth-Aware Transformer
Mar 28, 2022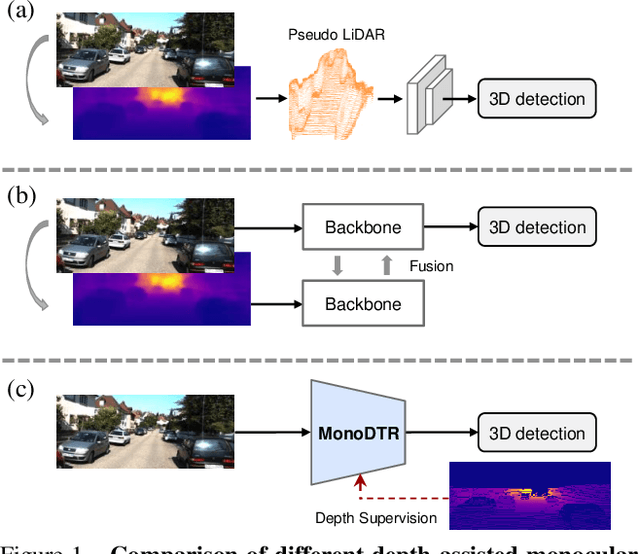
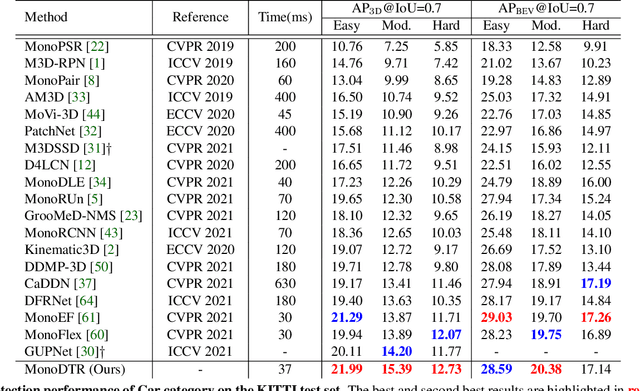
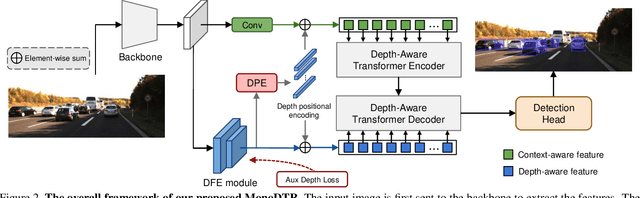
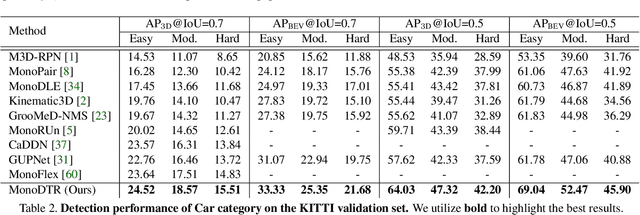
Monocular 3D object detection is an important yet challenging task in autonomous driving. Some existing methods leverage depth information from an off-the-shelf depth estimator to assist 3D detection, but suffer from the additional computational burden and achieve limited performance caused by inaccurate depth priors. To alleviate this, we propose MonoDTR, a novel end-to-end depth-aware transformer network for monocular 3D object detection. It mainly consists of two components: (1) the Depth-Aware Feature Enhancement (DFE) module that implicitly learns depth-aware features with auxiliary supervision without requiring extra computation, and (2) the Depth-Aware Transformer (DTR) module that globally integrates context- and depth-aware features. Moreover, different from conventional pixel-wise positional encodings, we introduce a novel depth positional encoding (DPE) to inject depth positional hints into transformers. Our proposed depth-aware modules can be easily plugged into existing image-only monocular 3D object detectors to improve the performance. Extensive experiments on the KITTI dataset demonstrate that our approach outperforms previous state-of-the-art monocular-based methods and achieves real-time detection. Code is available at https://github.com/kuanchihhuang/MonoDTR
Multi-institutional Collaborations for Improving Deep Learning-based Magnetic Resonance Image Reconstruction Using Federated Learning
Mar 09, 2021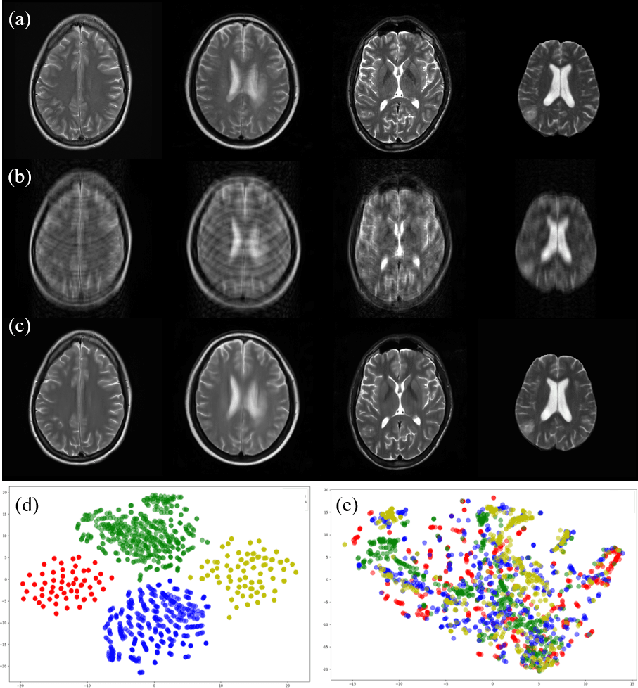
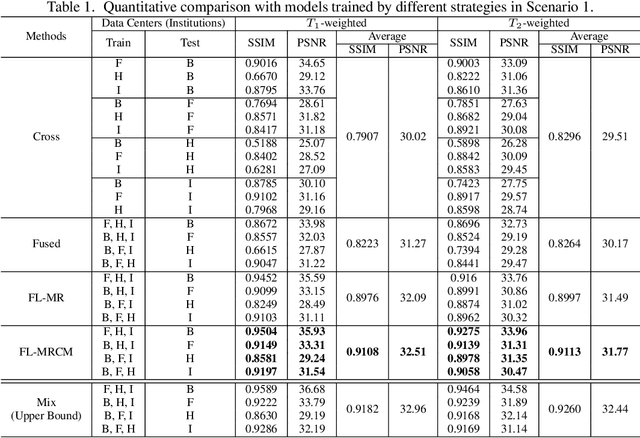
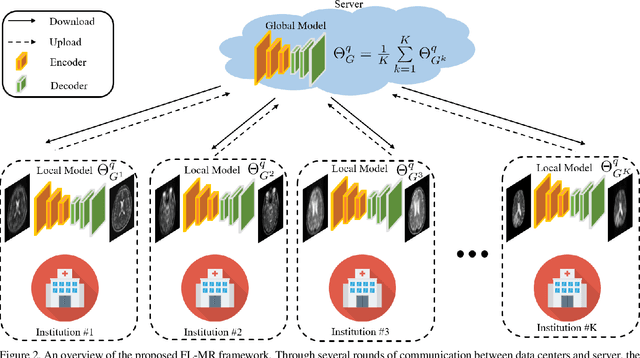
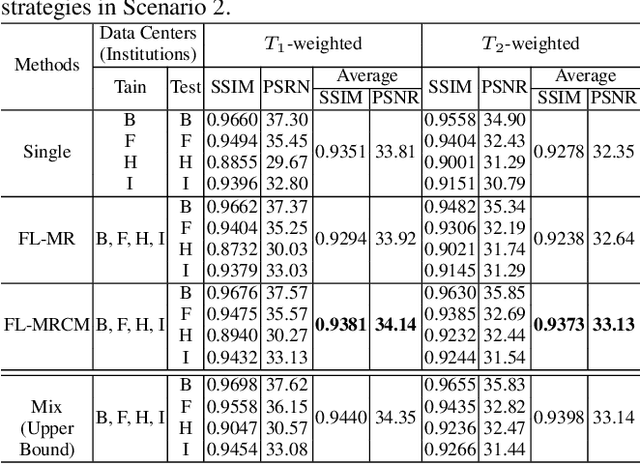
Fast and accurate reconstruction of magnetic resonance (MR) images from under-sampled data is important in many clinical applications. In recent years, deep learning-based methods have been shown to produce superior performance on MR image reconstruction. However, these methods require large amounts of data which is difficult to collect and share due to the high cost of acquisition and medical data privacy regulations. In order to overcome this challenge, we propose a federated learning (FL) based solution in which we take advantage of the MR data available at different institutions while preserving patients' privacy. However, the generalizability of models trained with the FL setting can still be suboptimal due to domain shift, which results from the data collected at multiple institutions with different sensors, disease types, and acquisition protocols, etc. With the motivation of circumventing this challenge, we propose a cross-site modeling for MR image reconstruction in which the learned intermediate latent features among different source sites are aligned with the distribution of the latent features at the target site. Extensive experiments are conducted to provide various insights about FL for MR image reconstruction. Experimental results demonstrate that the proposed framework is a promising direction to utilize multi-institutional data without compromising patients' privacy for achieving improved MR image reconstruction. Our code will be available at https://github.com/guopengf/FLMRCM.
Learning Where to Learn in Cross-View Self-Supervised Learning
Mar 28, 2022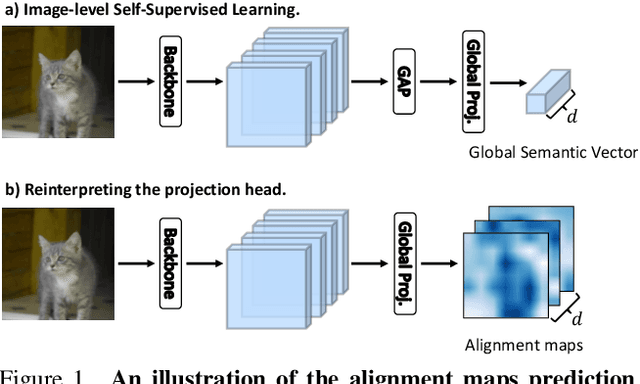
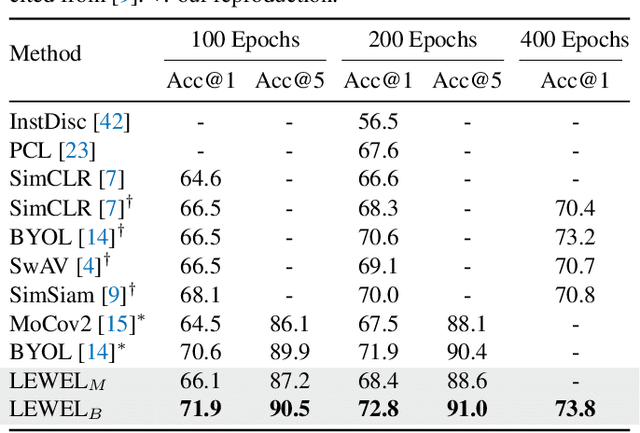
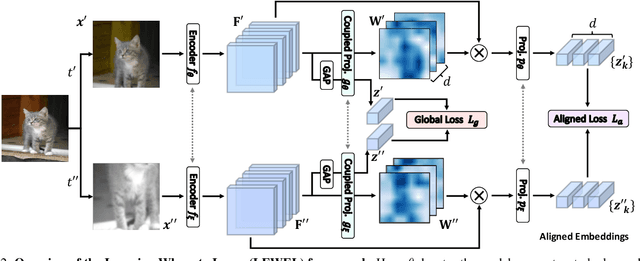
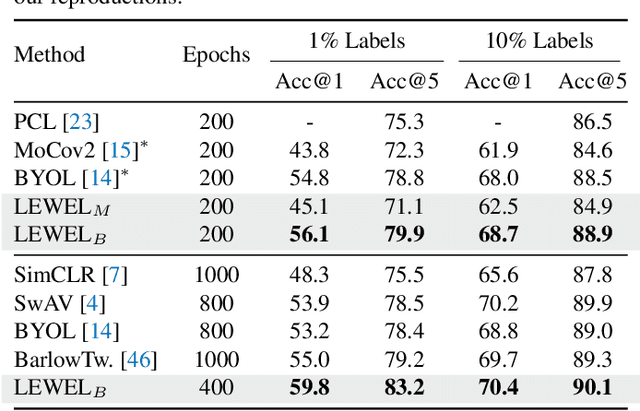
Self-supervised learning (SSL) has made enormous progress and largely narrowed the gap with the supervised ones, where the representation learning is mainly guided by a projection into an embedding space. During the projection, current methods simply adopt uniform aggregation of pixels for embedding; however, this risks involving object-irrelevant nuisances and spatial misalignment for different augmentations. In this paper, we present a new approach, Learning Where to Learn (LEWEL), to adaptively aggregate spatial information of features, so that the projected embeddings could be exactly aligned and thus guide the feature learning better. Concretely, we reinterpret the projection head in SSL as a per-pixel projection and predict a set of spatial alignment maps from the original features by this weight-sharing projection head. A spectrum of aligned embeddings is thus obtained by aggregating the features with spatial weighting according to these alignment maps. As a result of this adaptive alignment, we observe substantial improvements on both image-level prediction and dense prediction at the same time: LEWEL improves MoCov2 by 1.6%/1.3%/0.5%/0.4% points, improves BYOL by 1.3%/1.3%/0.7%/0.6% points, on ImageNet linear/semi-supervised classification, Pascal VOC semantic segmentation, and object detection, respectively.
Using a modified double deep image prior for crosstalk mitigation in multislice ptychography
Jan 29, 2021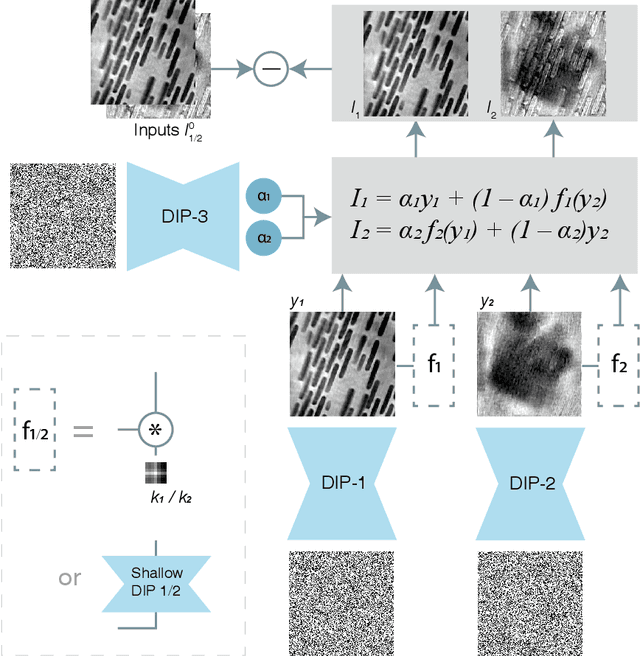
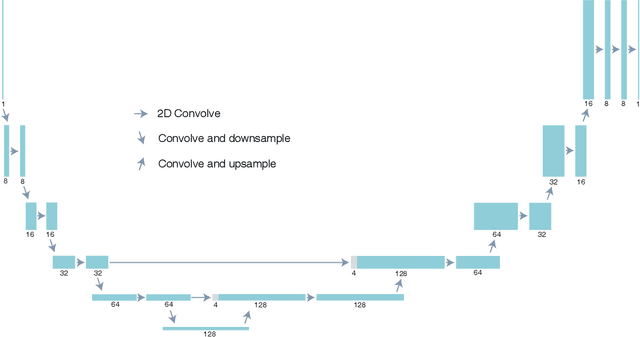

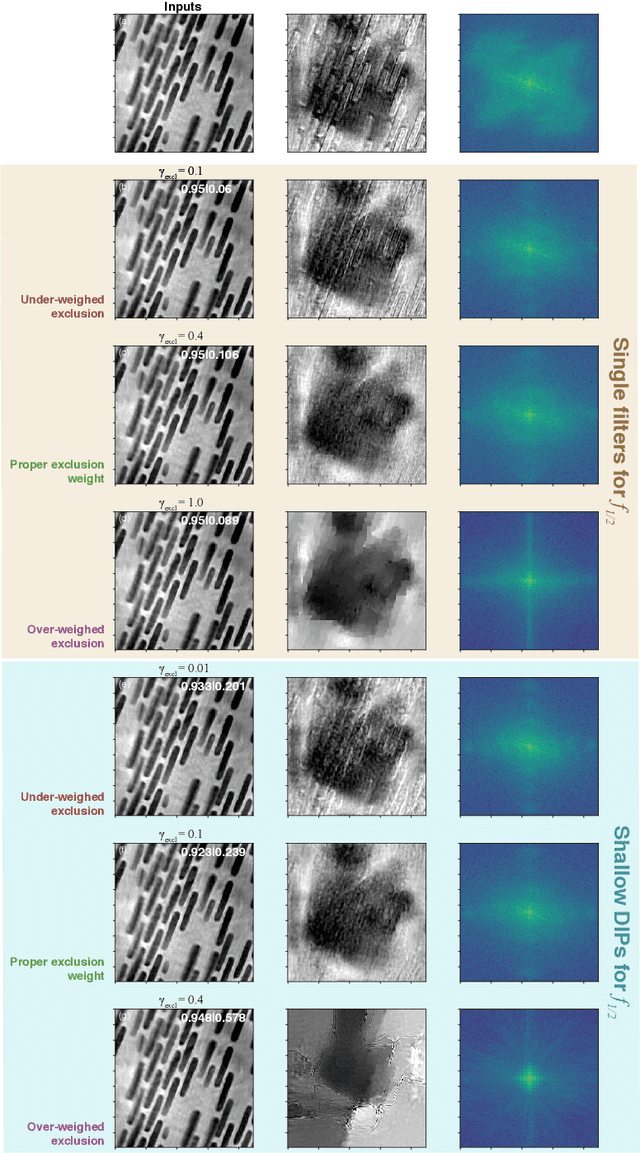
Multislice ptychography is a high-resolution microscopy technique used to image multiple separate axial planes using a single illumination direction. However, multislice ptychography reconstructions are often degraded by crosstalk, where some features on one plane erroneously contribute to the reconstructed image of another plane. Here, we demonstrate the use of a modified "double deep image prior" (DDIP) architecture in mitigating crosstalk artifacts in multislice ptychography. Utilizing the tendency of generative neural networks to produce natural images, a modified DDIP method yielded good results on experimental data. For one of the datasets, we show that using DDIP could remove the need of using additional experimental data, such as from x-ray fluorescence, to suppress the crosstalk. Our method may help x-ray multislice ptychography work for more general experimental scenarios.
Spectral Unmixing of Hyperspectral Images Based on Block Sparse Structure
Apr 10, 2022

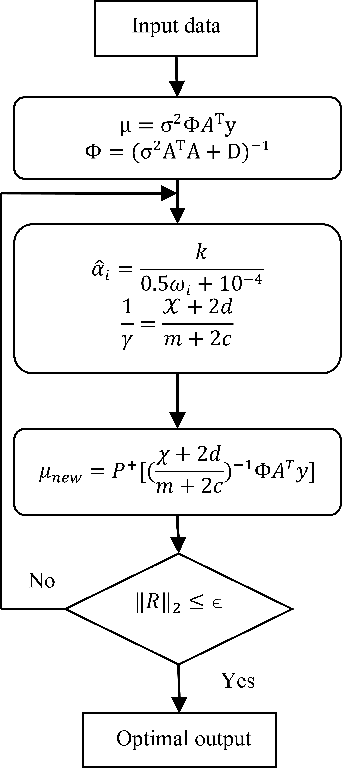
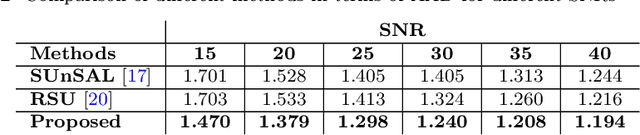
Spectral unmixing (SU) of hyperspectral images (HSIs) is one of the important areas in remote sensing (RS) that needs to be carefully addressed in different RS applications. Despite the high spectral resolution of the hyperspectral data, the relatively low spatial resolution of the sensors may lead to mixture of different pure materials within the image pixels. In this case, the spectrum of a given pixel recorded by the sensor can be a combination of multiple spectra each belonging to a unique material in that pixel. Spectral unmixing is then used as a technique to extract the spectral characteristics of the different materials within the mixed pixels and to recover the spectrum of each pure spectral signature, called endmember. Block-sparsity exists in hyperspectral images as a result of spectral similarity between neighboring pixels. In block-sparse signals, the nonzero samples occur in clusters and the pattern of the clusters is often supposed to be unavailable as prior information. This paper presents an innovative spectral unmixing approach for HSIs based on block-sparse structure and sparse Bayesian learning (SBL) strategy. To evaluate the performance of the proposed SU algorithm, it is tested on both synthetic and real hyperspectral data and the quantitative results are compared to those of other state-of-the-art methods in terms of abundance angel distance (AAD) and mean square error (MSE). The achieved results show the superiority of the proposed algorithm over the other competing methods by a significant margin.
Neural Sparse Representation for Image Restoration
Jun 08, 2020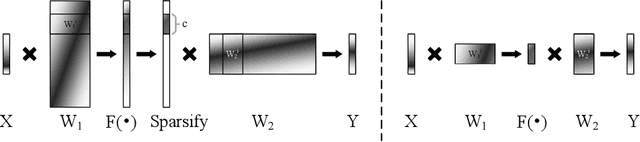
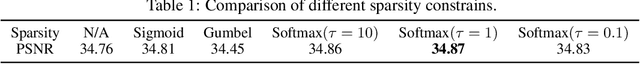

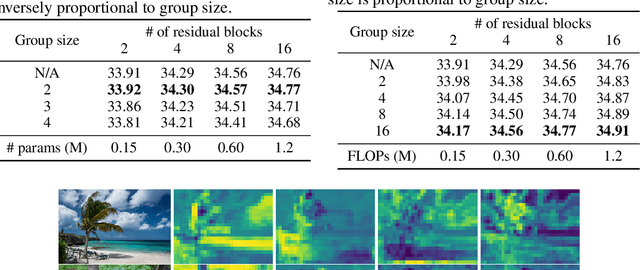
Inspired by the robustness and efficiency of sparse representation in sparse coding based image restoration models, we investigate the sparsity of neurons in deep networks. Our method structurally enforces sparsity constraints upon hidden neurons. The sparsity constraints are favorable for gradient-based learning algorithms and attachable to convolution layers in various networks. Sparsity in neurons enables computation saving by only operating on non-zero components without hurting accuracy. Meanwhile, our method can magnify representation dimensionality and model capacity with negligible additional computation cost. Experiments show that sparse representation is crucial in deep neural networks for multiple image restoration tasks, including image super-resolution, image denoising, and image compression artifacts removal. Code is available at https://github.com/ychfan/nsr