 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Towards Unsupervised Domain Adaptation via Domain-Transformer
Feb 24, 2022
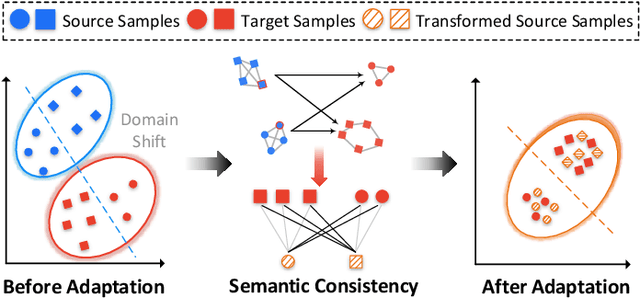
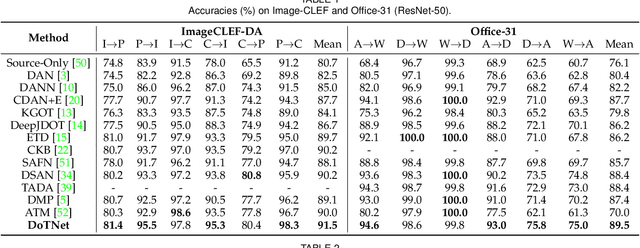
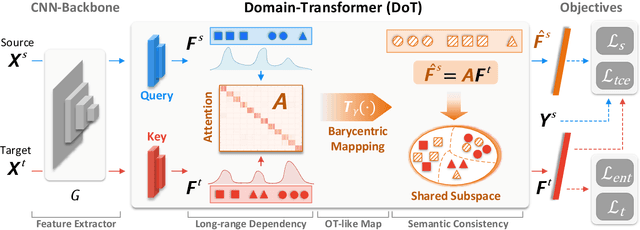
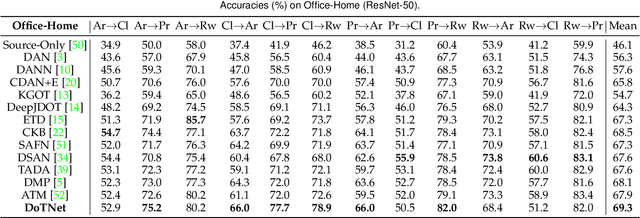
As a vital problem in pattern analysis and machine intelligence, Unsupervised Domain Adaptation (UDA) studies how to transfer an effective feature learner from a labeled source domain to an unlabeled target domain. Plenty of methods based on Convolutional Neural Networks (CNNs) have achieved promising results in the past decades. Inspired by the success of Transformers, some methods attempt to tackle UDA problem by adopting pure transformer architectures, and interpret the models by applying the long-range dependency strategy at image patch-level. However, the algorithmic complexity is high and the interpretability seems weak. In this paper, we propose the Domain-Transformer (DoT) for UDA, which integrates the CNN-backbones and the core attention mechanism of Transformers from a new perspective. Specifically, a plug-and-play domain-level attention mechanism is proposed to learn the sample correspondence between domains. This is significantly different from existing methods which only capture the local interactions among image patches. Instead of explicitly modeling the distribution discrepancy from either domain-level or class-level, DoT learns transferable features by achieving the local semantic consistency across domains, where the domain-level attention and manifold regularization are explored. Then, DoT is free of pseudo-labels and explicit domain discrepancy optimization. Theoretically, DoT is connected with the optimal transportation algorithm and statistical learning theory. The connection provides a new insight to understand the core component of Transformers. Extensive experiments on several benchmark datasets validate the effectiveness of DoT.
Deconstruction and reconstruction of image-degrading effects in the human abdomen using Fullwave: phase aberration, multiple reverberation, and trailing reverberation
Jun 25, 2021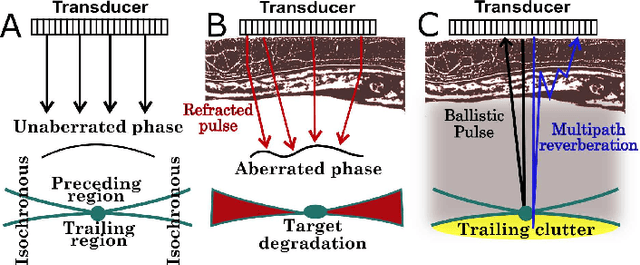
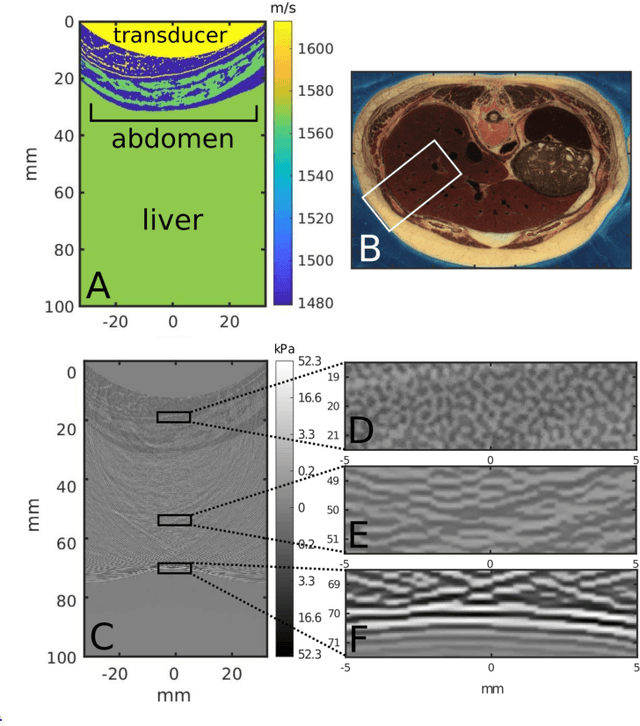
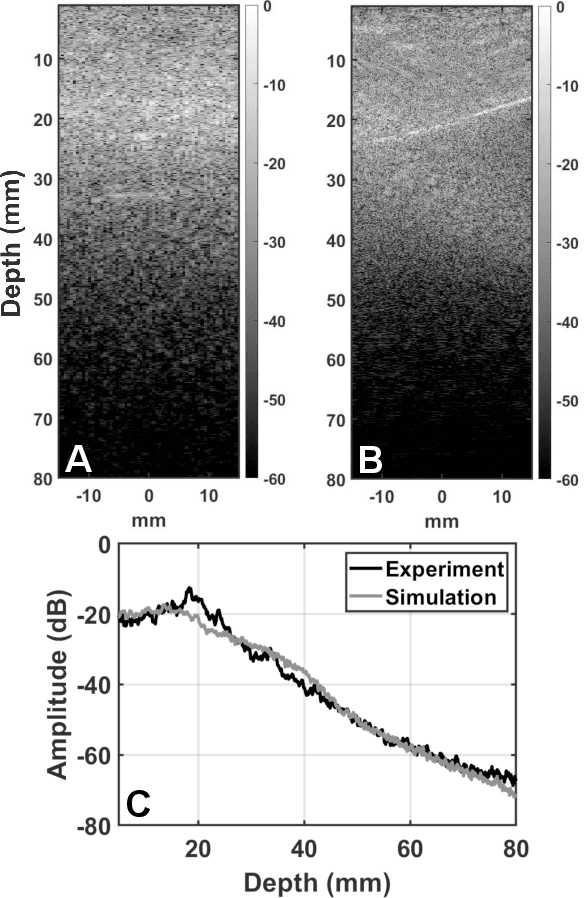
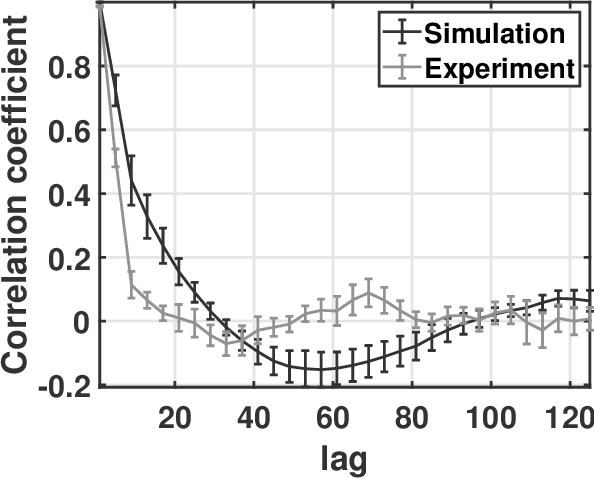
Ultrasound image degradation in the human body is complex and occurs due to the distortion of the wave as it propagates to and from the target. Here, we establish a simulation based framework that deconstructs the sources of image degradation into a separable parameter space that includes phase aberration from speed variation, multiple reverberations, and trailing reverberation. These separable parameters are then used to reconstruct images with known and independently modulable amounts of degradation using methods that depend on the additive or multiplicative nature of the degradation. Experimental measurements and Fullwave simulations in the human abdomen demonstrate this calibrated process in abdominal imaging by matching relevant imaging metrics such as phase aberration, reverberation strength, speckle brightness and coherence length. Applications of the reconstruction technique are illustrated for beamforming strategies (phase aberration correction, spatial coherence imaging), in a standard abdominal environment, as well as in impedance ranges much higher than those naturally occurring in the body.
Category Guided Attention Network for Brain Tumor Segmentation in MRI
Mar 29, 2022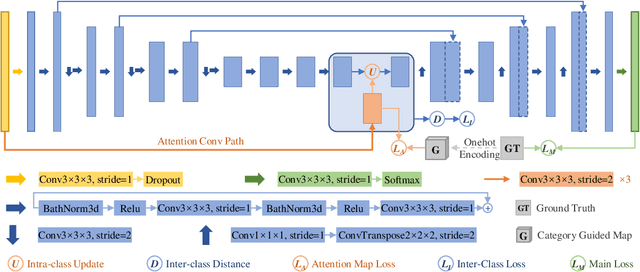
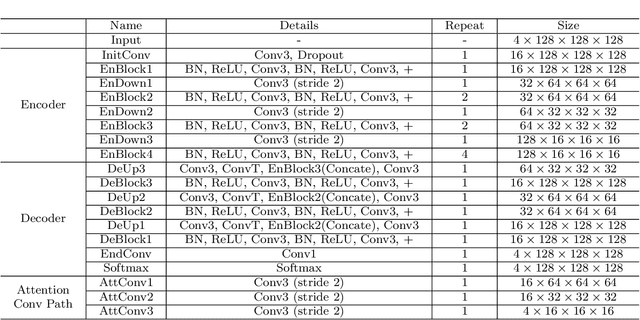
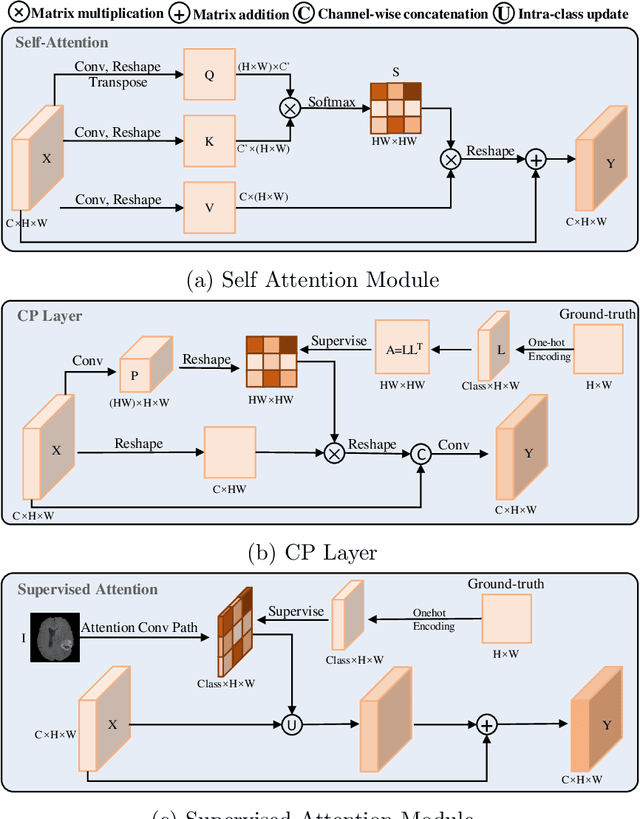
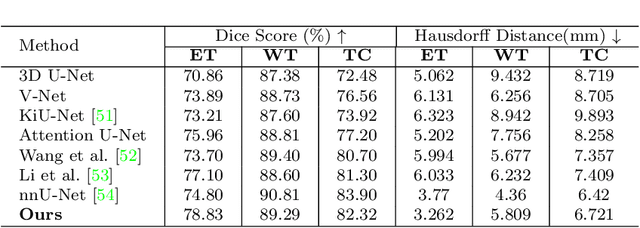
Objective: Magnetic resonance imaging (MRI) has been widely used for the analysis and diagnosis of brain diseases. Accurate and automatic brain tumor segmentation is of paramount importance for radiation treatment. However, low tissue contrast in tumor regions makes it a challenging task.Approach: We propose a novel segmentation network named Category Guided Attention U-Net (CGA U-Net). In this model, we design a Supervised Attention Module (SAM) based on the attention mechanism, which can capture more accurate and stable long-range dependency in feature maps without introducing much computational cost. Moreover, we propose an intra-class update approach to reconstruct feature maps by aggregating pixels of the same category. Main results: Experimental results on the BraTS 2019 datasets show that the proposed method outperformers the state-of-the-art algorithms in both segmentation performance and computational complexity. Significance: The CGA U-Net can effectively capture the global semantic information in the MRI image by using the SAM module, while significantly reducing the computational cost. Code is available at https://github.com/delugewalker/CGA-U-Net.
Multiclass classification using quantum convolutional neural networks with hybrid quantum-classical learning
Mar 29, 2022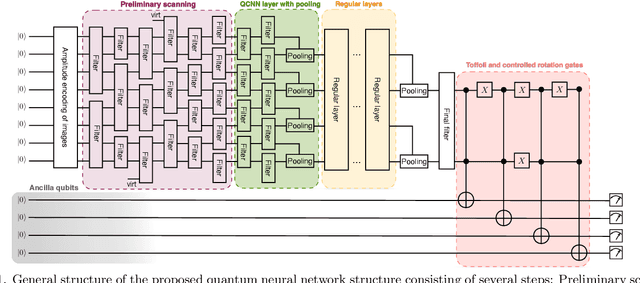
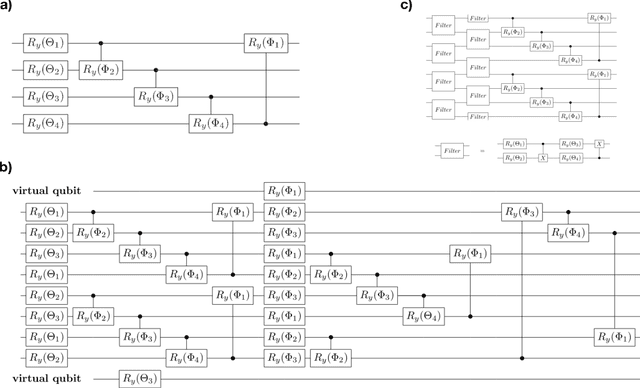
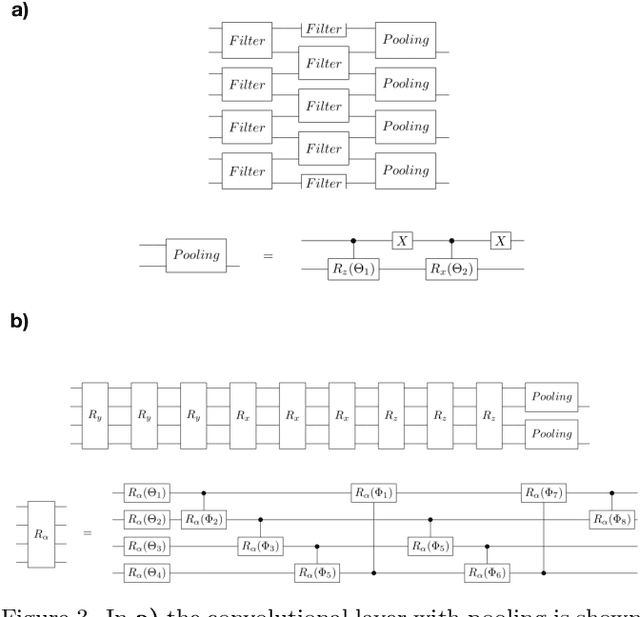
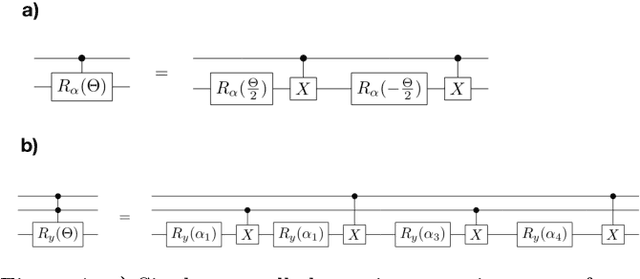
Multiclass classification is of great interest for various machine learning applications, for example, it is a common task in computer vision, where one needs to categorize an image into three or more classes. Here we propose a quantum machine learning approach based on quantum convolutional neural networks for solving this problem. The corresponding learning procedure is implemented via TensorFlowQuantum as a hybrid quantum-classical (variational) model, where quantum output results are fed to softmax cost function with subsequent minimization of it via optimization of parameters of quantum circuit. Our conceptional improvements include a new model for quantum perceptron and optimized structure of the quantum circuit. We use the proposed approach to demonstrate the 4-class classification for the case of the MNIST dataset using eight qubits for data encoding and four acnilla qubits. Our results demonstrate comparable accuracy of our solution with classical convolutional neural networks with comparable numbers of trainable parameters. We expect that our finding provide a new step towards the use of quantum machine learning for solving practically relevant problems in the NISQ era and beyond.
Towards Self-Supervised Learning of Global and Object-Centric Representations
Mar 11, 2022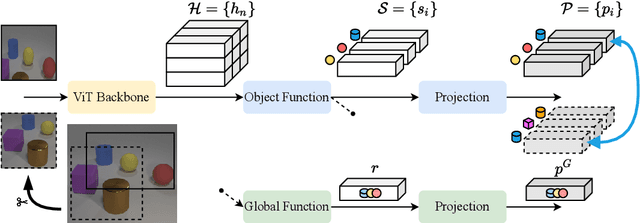

Self-supervision allows learning meaningful representations of natural images which usually contain one central object. How well does it transfer to multi-entity scenes? We discuss key aspects of learning structured object-centric representations with self-supervision and validate our insights through several experiments on the CLEVR dataset. Regarding the architecture, we confirm the importance of competition for attention-based object discovery, where each image patch is exclusively attended by one object. For training, we show that contrastive losses equipped with matching can be applied directly in a latent space, avoiding pixel-based reconstruction. However, such an optimization objective is sensitive to false negatives (recurring objects) and false positives (matching errors). Thus, careful consideration is required around data augmentation and negative sample selection.
Generalizing Adversarial Explanations with Grad-CAM
Apr 11, 2022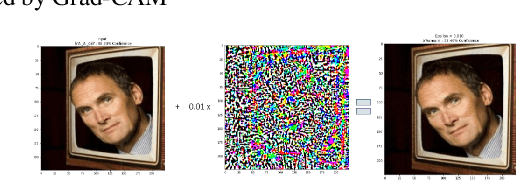
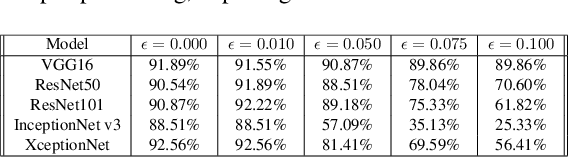

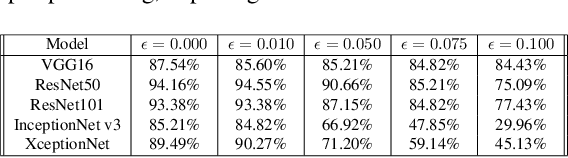
Gradient-weighted Class Activation Mapping (Grad- CAM), is an example-based explanation method that provides a gradient activation heat map as an explanation for Convolution Neural Network (CNN) models. The drawback of this method is that it cannot be used to generalize CNN behaviour. In this paper, we present a novel method that extends Grad-CAM from example-based explanations to a method for explaining global model behaviour. This is achieved by introducing two new metrics, (i) Mean Observed Dissimilarity (MOD) and (ii) Variation in Dissimilarity (VID), for model generalization. These metrics are computed by comparing a Normalized Inverted Structural Similarity Index (NISSIM) metric of the Grad-CAM generated heatmap for samples from the original test set and samples from the adversarial test set. For our experiment, we study adversarial attacks on deep models such as VGG16, ResNet50, and ResNet101, and wide models such as InceptionNetv3 and XceptionNet using Fast Gradient Sign Method (FGSM). We then compute the metrics MOD and VID for the automatic face recognition (AFR) use case with the VGGFace2 dataset. We observe a consistent shift in the region highlighted in the Grad-CAM heatmap, reflecting its participation to the decision making, across all models under adversarial attacks. The proposed method can be used to understand adversarial attacks and explain the behaviour of black box CNN models for image analysis.
Pneumonia Detection in Chest X-Rays using Neural Networks
Apr 07, 2022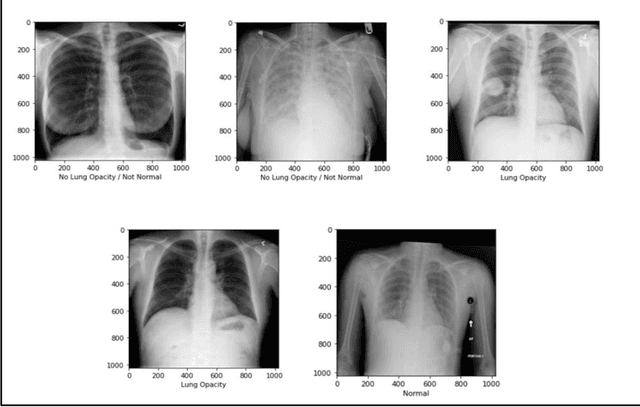
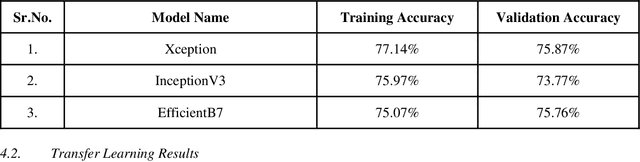
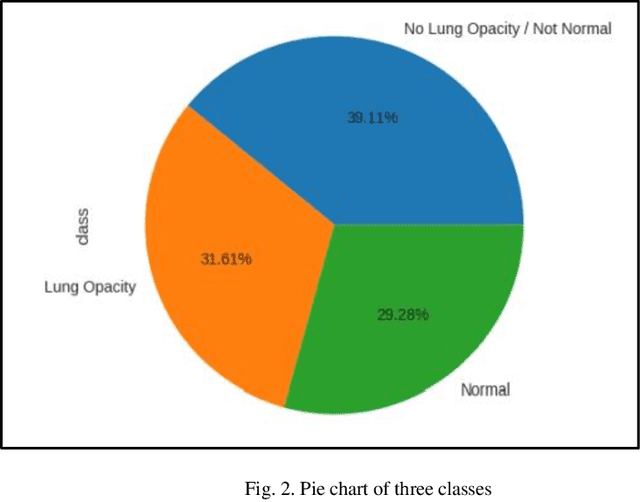

With the advancement in AI, deep learning techniques are widely used to design robust classification models in several areas such as medical diagnosis tasks in which it achieves good performance. In this paper, we have proposed the CNN model (Convolutional Neural Network) for the classification of Chest X-ray images for Radiological Society of North America Pneumonia (RSNA) datasets. The study also tries to achieve the same RSNA benchmark results using the limited computational resources by trying out various approaches to the methodologies that have been implemented in recent years. The proposed method is based on a non-complex CNN and the use of transfer learning algorithms like Xception, InceptionV3/V4, EfficientNetB7. Along with this, the study also tries to achieve the same RSNA benchmark results using the limited computational resources by trying out various approaches to the methodologies that have been implemented in recent years. The RSNA benchmark MAP score is 0.25, but using the Mask RCNN model on a stratified sample of 3017 along with image augmentation gave a MAP score of 0.15. Meanwhile, the YoloV3 without any hyperparameter tuning gave the MAP score of 0.32 but still, the loss keeps decreasing. Running the model for a greater number of iterations can give better results.
LCA-Net: Light Convolutional Autoencoder for Image Dehazing
Aug 24, 2020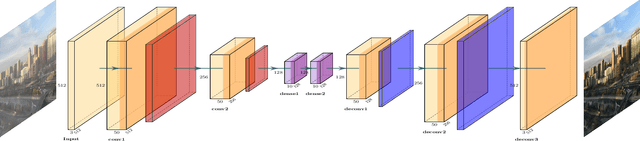


Image dehazing is a crucial image pre-processing task aimed at removing the incoherent noise generated by haze to improve the visual appeal of the image. The existing models use sophisticated networks and custom loss functions which are computationally inefficient and requires heavy hardware to run. Time is of the essence in image pre-processing since real time outputs can be obtained instantly. To overcome these problems, our proposed generic model uses a very light convolutional encoder-decoder network which does not depend on any atmospheric models. The network complexity-image quality trade off is handled well in this neural network and the performance of this network is not limited by low-spec systems. This network achieves optimum dehazing performance at a much faster rate, on several standard datasets, comparable to the state-of-the-art methods in terms of image quality.
Parameter-efficient Fine-tuning for Vision Transformers
Mar 29, 2022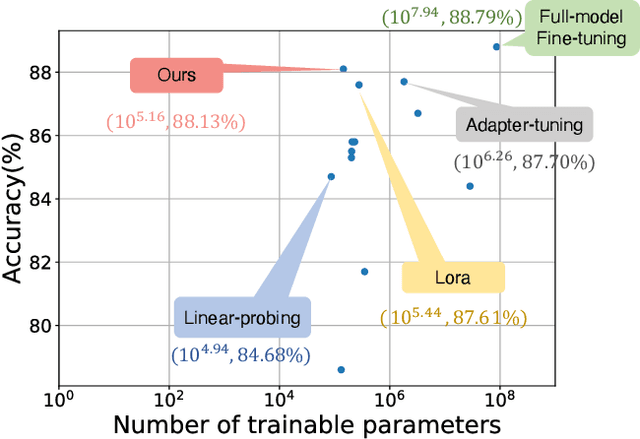

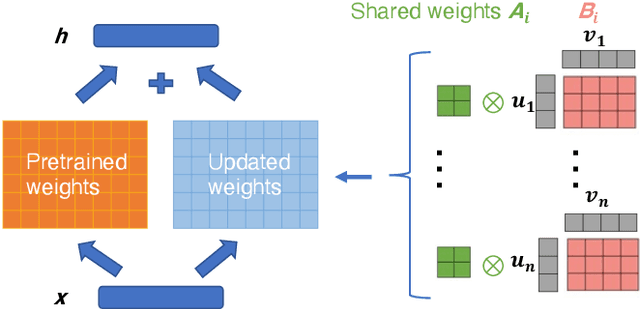
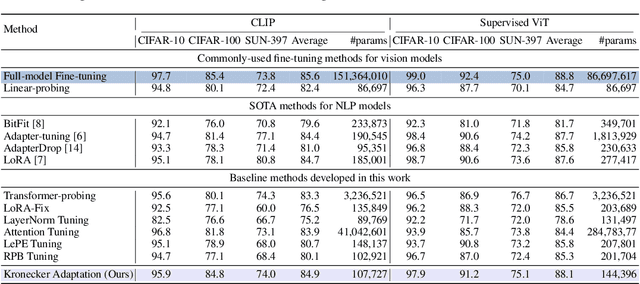
In computer vision, it has achieved great success in adapting large-scale pretrained vision models (e.g., Vision Transformer) to downstream tasks via fine-tuning. Common approaches for fine-tuning either update all model parameters or leverage linear probes. In this paper, we aim to study parameter-efficient fine-tuning strategies for Vision Transformers on vision tasks. We formulate efficient fine-tuning as a subspace training problem and perform a comprehensive benchmarking over different efficient fine-tuning methods. We conduct an empirical study on each efficient fine-tuning method focusing on its performance alongside parameter cost. Furthermore, we also propose a parameter-efficient fine-tuning framework, which first selects submodules by measuring local intrinsic dimensions and then projects them into subspace for further decomposition via a novel Kronecker Adaptation method. We analyze and compare our method with a diverse set of baseline fine-tuning methods (including state-of-the-art methods for pretrained language models). Our method performs the best in terms of the tradeoff between accuracy and parameter efficiency across three commonly used image classification datasets.
Training data-efficient image transformers & distillation through attention
Jan 15, 2021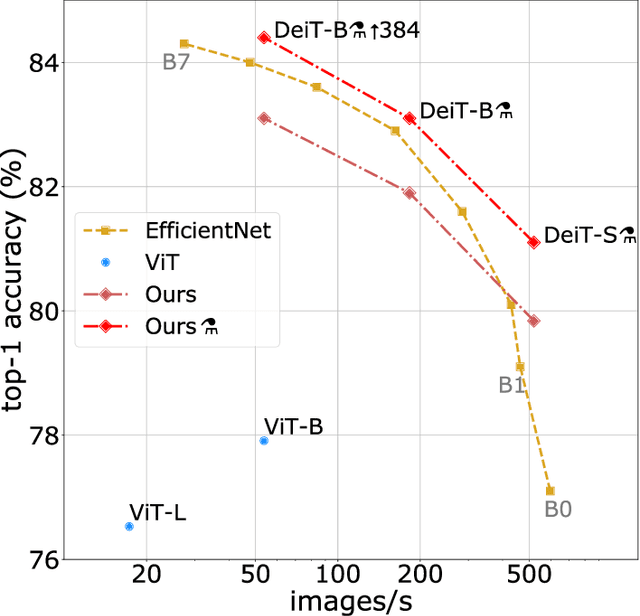
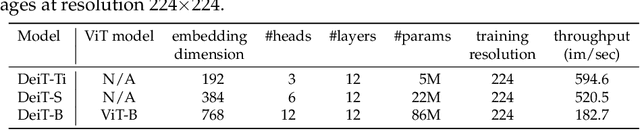
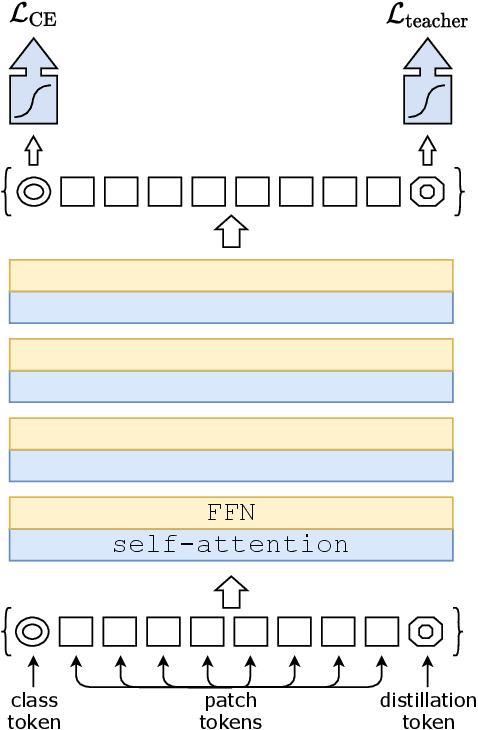
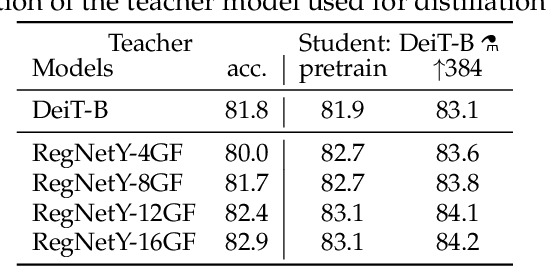
Recently, neural networks purely based on attention were shown to address image understanding tasks such as image classification. However, these visual transformers are pre-trained with hundreds of millions of images using an expensive infrastructure, thereby limiting their adoption. In this work, we produce a competitive convolution-free transformer by training on Imagenet only. We train them on a single computer in less than 3 days. Our reference vision transformer (86M parameters) achieves top-1 accuracy of 83.1% (single-crop evaluation) on ImageNet with no external data. More importantly, we introduce a teacher-student strategy specific to transformers. It relies on a distillation token ensuring that the student learns from the teacher through attention. We show the interest of this token-based distillation, especially when using a convnet as a teacher. This leads us to report results competitive with convnets for both Imagenet (where we obtain up to 85.2% accuracy) and when transferring to other tasks. We share our code and models.