 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Unsupervised Domain Adaptation via Domain-Transformer
Feb 24, 2022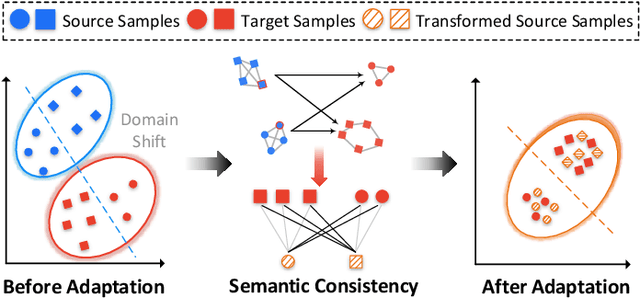
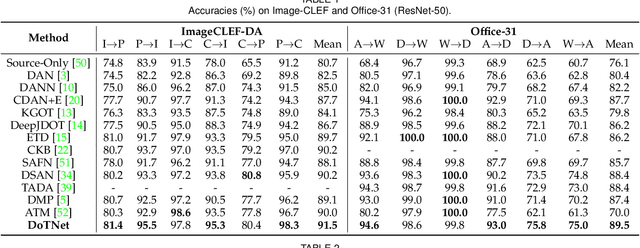
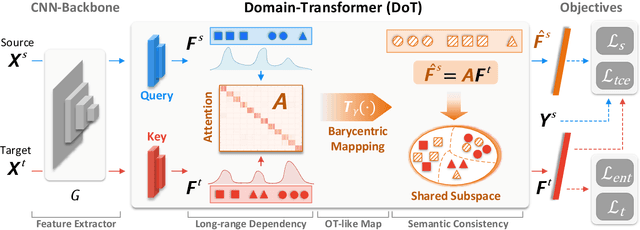
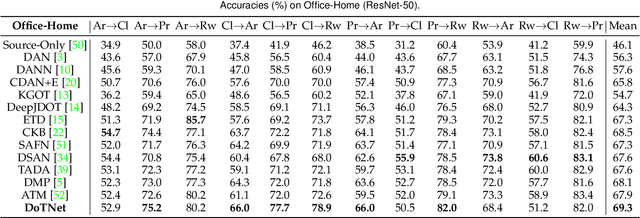
As a vital problem in pattern analysis and machine intelligence, Unsupervised Domain Adaptation (UDA) studies how to transfer an effective feature learner from a labeled source domain to an unlabeled target domain. Plenty of methods based on Convolutional Neural Networks (CNNs) have achieved promising results in the past decades. Inspired by the success of Transformers, some methods attempt to tackle UDA problem by adopting pure transformer architectures, and interpret the models by applying the long-range dependency strategy at image patch-level. However, the algorithmic complexity is high and the interpretability seems weak. In this paper, we propose the Domain-Transformer (DoT) for UDA, which integrates the CNN-backbones and the core attention mechanism of Transformers from a new perspective. Specifically, a plug-and-play domain-level attention mechanism is proposed to learn the sample correspondence between domains. This is significantly different from existing methods which only capture the local interactions among image patches. Instead of explicitly modeling the distribution discrepancy from either domain-level or class-level, DoT learns transferable features by achieving the local semantic consistency across domains, where the domain-level attention and manifold regularization are explored. Then, DoT is free of pseudo-labels and explicit domain discrepancy optimization. Theoretically, DoT is connected with the optimal transportation algorithm and statistical learning theory. The connection provides a new insight to understand the core component of Transformers. Extensive experiments on several benchmark datasets validate the effectiveness of DoT.
Multi-Source Unsupervised Domain Adaptation via Pseudo Target Domain
Feb 22, 2022Multi-source domain adaptation (MDA) aims to transfer knowledge from multiple source domains to an unlabeled target domain. MDA is a challenging task due to the severe domain shift, which not only exists between target and source but also exists among diverse sources. Prior studies on MDA either estimate a mixed distribution of source domains or combine multiple single-source models, but few of them delve into the relevant information among diverse source domains. For this reason, we propose a novel MDA approach, termed Pseudo Target for MDA (PTMDA). Specifically, PTMDA maps each group of source and target domains into a group-specific subspace using adversarial learning with a metric constraint, and constructs a series of pseudo target domains correspondingly. Then we align the remainder source domains with the pseudo target domain in the subspace efficiently, which allows to exploit additional structured source information through the training on pseudo target domain and improves the performance on the real target domain. Besides, to improve the transferability of deep neural networks (DNNs), we replace the traditional batch normalization layer with an effective matching normalization layer, which enforces alignments in latent layers of DNNs and thus gains further promotion. We give theoretical analysis showing that PTMDA as a whole can reduce the target error bound and leads to a better approximation of the target risk in MDA settings. Extensive experiments demonstrate PTMDA's effectiveness on MDA tasks, as it outperforms state-of-the-art methods in most experimental settings.