 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeParameter-efficient Fine-tuning for Vision Transformers
Paper and Code
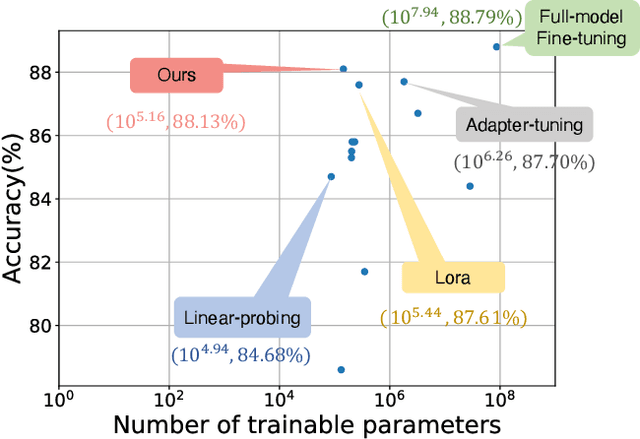

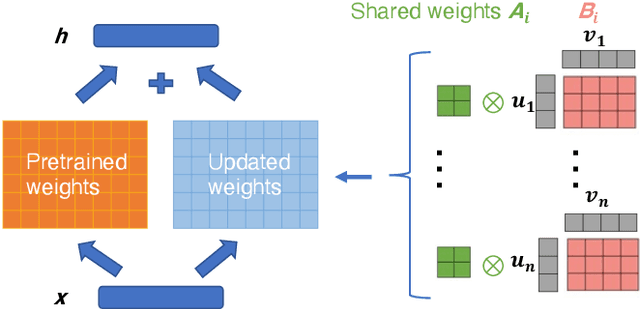
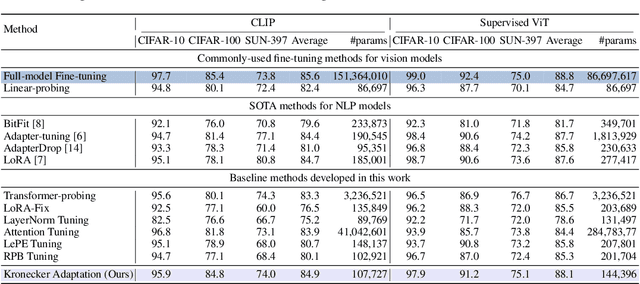
In computer vision, it has achieved great success in adapting large-scale pretrained vision models (e.g., Vision Transformer) to downstream tasks via fine-tuning. Common approaches for fine-tuning either update all model parameters or leverage linear probes. In this paper, we aim to study parameter-efficient fine-tuning strategies for Vision Transformers on vision tasks. We formulate efficient fine-tuning as a subspace training problem and perform a comprehensive benchmarking over different efficient fine-tuning methods. We conduct an empirical study on each efficient fine-tuning method focusing on its performance alongside parameter cost. Furthermore, we also propose a parameter-efficient fine-tuning framework, which first selects submodules by measuring local intrinsic dimensions and then projects them into subspace for further decomposition via a novel Kronecker Adaptation method. We analyze and compare our method with a diverse set of baseline fine-tuning methods (including state-of-the-art methods for pretrained language models). Our method performs the best in terms of the tradeoff between accuracy and parameter efficiency across three commonly used image classification datasets.