 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Texture Characterization of Histopathologic Images Using Ecological Diversity Measures and Discrete Wavelet Transform
Feb 27, 2022

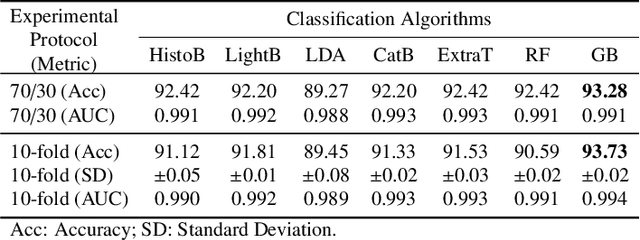
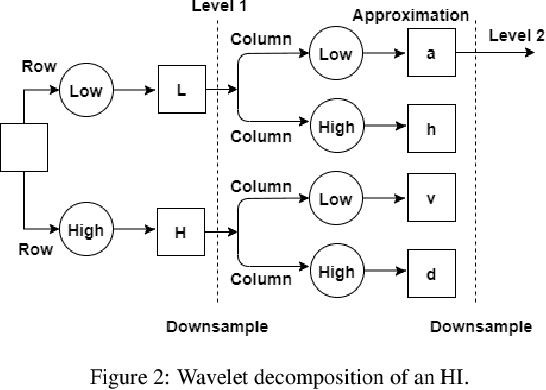
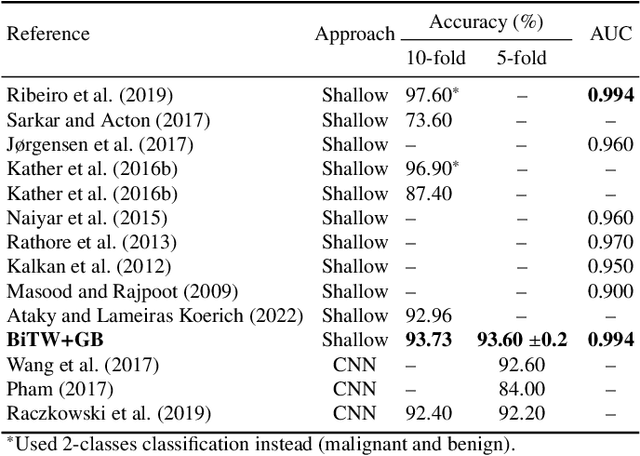
Breast cancer is a health problem that affects mainly the female population. An early detection increases the chances of effective treatment, improving the prognosis of the disease. In this regard, computational tools have been proposed to assist the specialist in interpreting the breast digital image exam, providing features for detecting and diagnosing tumors and cancerous cells. Nonetheless, detecting tumors with a high sensitivity rate and reducing the false positives rate is still challenging. Texture descriptors have been quite popular in medical image analysis, particularly in histopathologic images (HI), due to the variability of both the texture found in such images and the tissue appearance due to irregularity in the staining process. Such variability may exist depending on differences in staining protocol such as fixation, inconsistency in the staining condition, and reagents, either between laboratories or in the same laboratory. Textural feature extraction for quantifying HI information in a discriminant way is challenging given the distribution of intrinsic properties of such images forms a non-deterministic complex system. This paper proposes a method for characterizing texture across HIs with a considerable success rate. By employing ecological diversity measures and discrete wavelet transform, it is possible to quantify the intrinsic properties of such images with promising accuracy on two HI datasets compared with state-of-the-art methods.
Active Phase-Encode Selection for Slice-Specific Fast MR Scanning Using a Transformer-Based Deep Reinforcement Learning Framework
Mar 11, 2022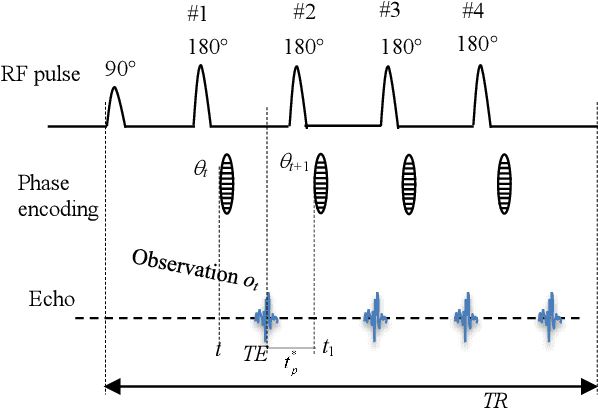
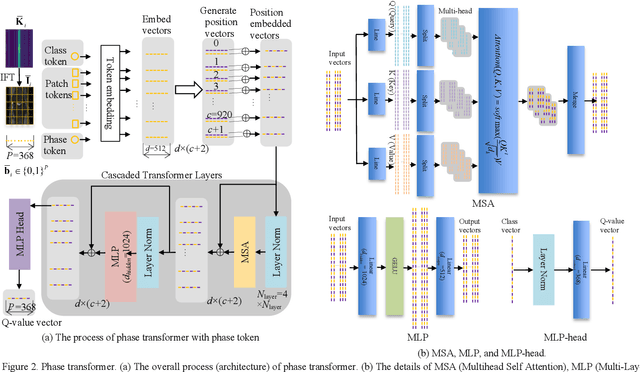
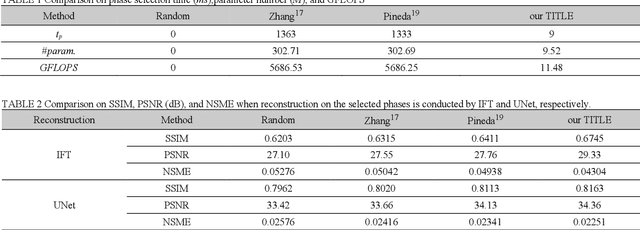
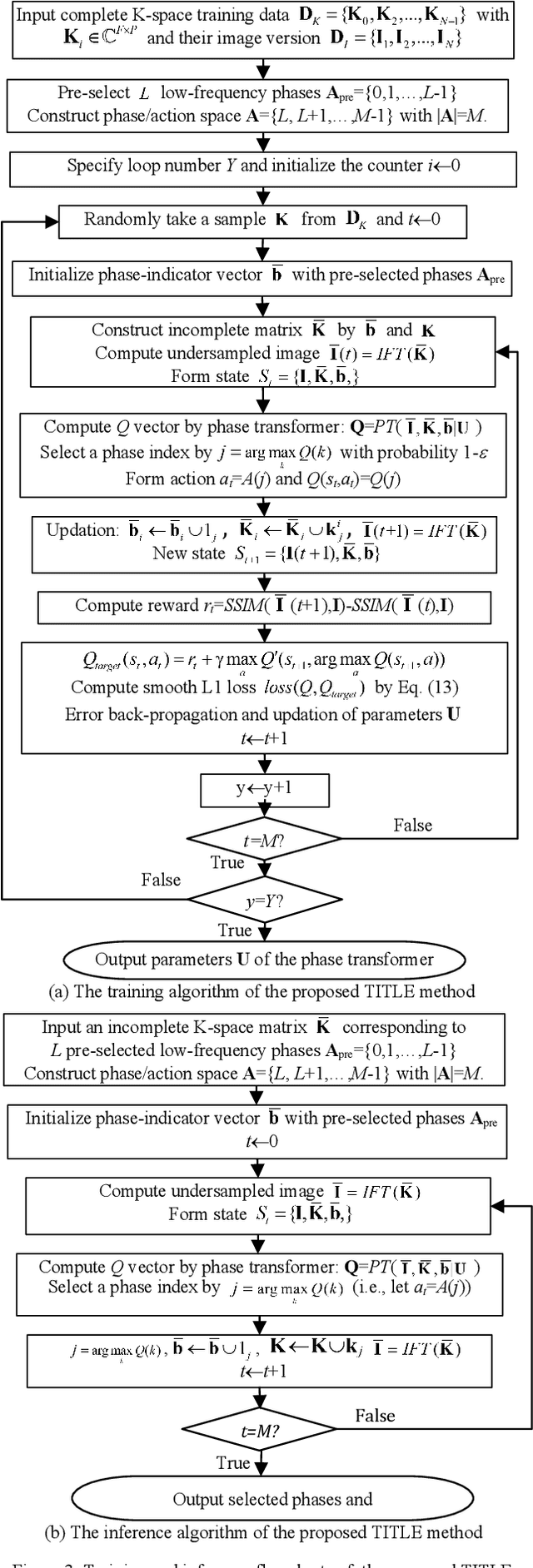
Purpose: Long scan time in phase encoding for forming complete K-space matrices is a critical drawback of MRI, making patients uncomfortable and wasting important time for diagnosing emergent diseases. This paper aims to reducing the scan time by actively and sequentially selecting partial phases in a short time so that a slice can be accurately reconstructed from the resultant slice-specific incomplete K-space matrix. Methods: A transformer based deep reinforcement learning framework is proposed for actively determining a sequence of partial phases according to reconstruction-quality based Q-value (a function of reward), where the reward is the improvement degree of reconstructed image quality. The Q-value is efficiently predicted from binary phase-indicator vectors, incomplete K-space matrices and their corresponding undersampled images with a light-weight transformer so that the sequential information of phases and global relationship in images can be used. The inverse Fourier transform is employed for efficiently computing the undersampled images and hence gaining the rewards of selecting phases. Results: Experimental results on the fastMRI dataset with original K-space data accessible demonstrate the efficiency and accuracy superiorities of proposed method. Compared with the state-of-the-art reinforcement learning based method proposed by Pineda et al., the proposed method is roughly 150 times faster and achieves significant improvement in reconstruction accuracy. Conclusions: We have proposed a light-weight transformer based deep reinforcement learning framework for generating high-quality slice-specific trajectory consisting of a small number of phases. The proposed method, called TITLE (Transformer Involved Trajectory LEarning), has remarkable superiority in phase-encode selection efficiency and image reconstruction accuracy.
Relaxation Labeling Meets GANs: Solving Jigsaw Puzzles with Missing Borders
Mar 28, 2022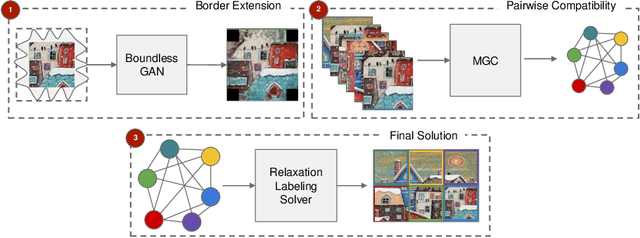
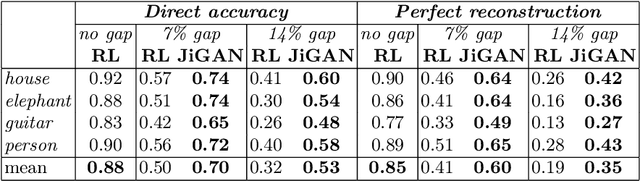
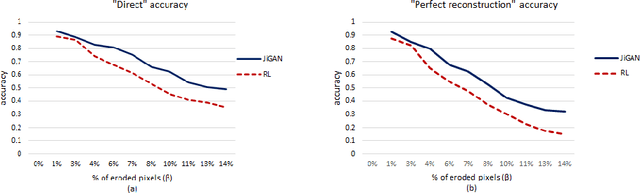
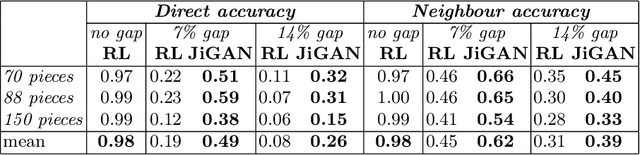
This paper proposes JiGAN, a GAN-based method for solving Jigsaw puzzles with eroded or missing borders. Missing borders is a common real-world situation, for example, when dealing with the reconstruction of broken artifacts or ruined frescoes. In this particular condition, the puzzle's pieces do not align perfectly due to the borders' gaps; in this situation, the patches' direct match is unfeasible due to the lack of color and line continuations. JiGAN, is a two-steps procedure that tackles this issue: first, we repair the eroded borders with a GAN-based image extension model and measure the alignment affinity between pieces; then, we solve the puzzle with the relaxation labeling algorithm to enforce consistency in pieces positioning, hence, reconstructing the puzzle. We test the method on a large dataset of small puzzles and on three commonly used benchmark datasets to demonstrate the feasibility of the proposed approach.
Semi-Supervised Training to Improve Player and Ball Detection in Soccer
Apr 14, 2022
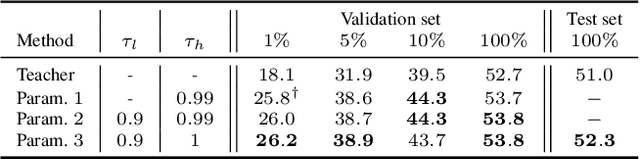
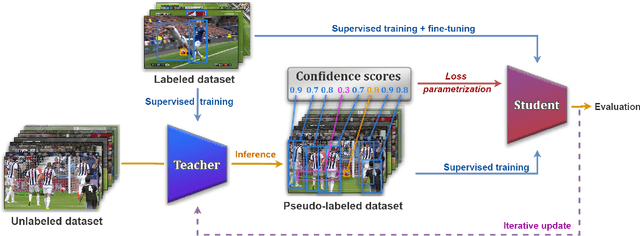

Accurate player and ball detection has become increasingly important in recent years for sport analytics. As most state-of-the-art methods rely on training deep learning networks in a supervised fashion, they require huge amounts of annotated data, which are rarely available. In this paper, we present a novel generic semi-supervised method to train a network based on a labeled image dataset by leveraging a large unlabeled dataset of soccer broadcast videos. More precisely, we design a teacher-student approach in which the teacher produces surrogate annotations on the unlabeled data to be used later for training a student which has the same architecture as the teacher. Furthermore, we introduce three training loss parametrizations that allow the student to doubt the predictions of the teacher during training depending on the proposal confidence score. We show that including unlabeled data in the training process allows to substantially improve the performances of the detection network trained only on the labeled data. Finally, we provide a thorough performance study including different proportions of labeled and unlabeled data, and establish the first benchmark on the new SoccerNet-v3 detection task, with an mAP of 52.3%. Our code is available at https://github.com/rvandeghen/SST .
Neural Radiance Projection
Mar 15, 2022
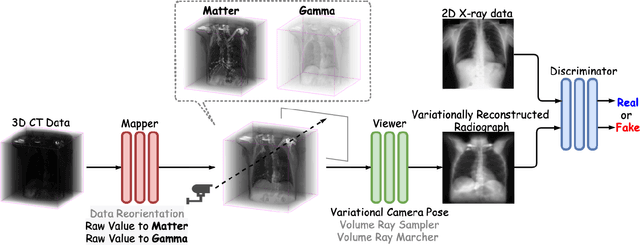
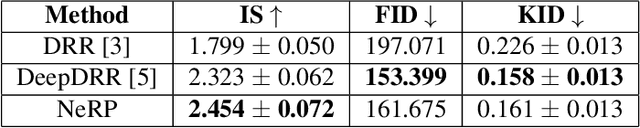
The proposed method, Neural Radiance Projection (NeRP), addresses the three most fundamental shortages of training such a convolutional neural network on X-ray image segmentation: dealing with missing/limited human-annotated datasets; ambiguity on the per-pixel label; and the imbalance across positive- and negative- classes distribution. By harnessing a generative adversarial network, we can synthesize a massive amount of physics-based X-ray images, so-called Variationally Reconstructed Radiographs (VRRs), alongside their segmentation from more accurate labeled 3D Computed Tomography data. As a result, VRRs present more faithfully than other projection methods in terms of photo-realistic metrics. Adding outputs from NeRP also surpasses the vanilla UNet models trained on the same pairs of X-ray images.
BalaGAN: Image Translation Between Imbalanced Domains via Cross-Modal Transfer
Oct 05, 2020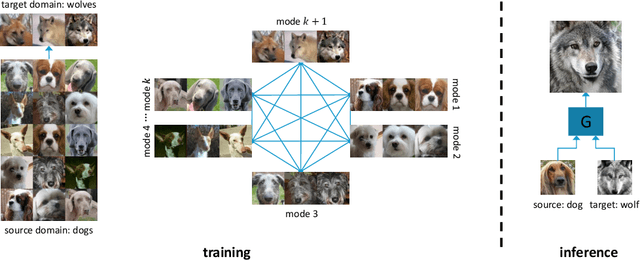
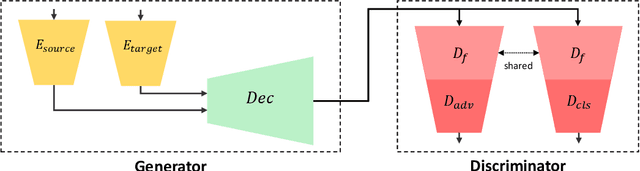
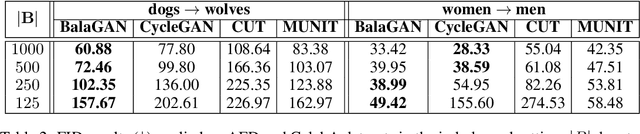

State-of-the-art image-to-image translation methods tend to struggle in an imbalanced domain setting, where one image domain lacks richness and diversity. We introduce a new unsupervised translation network, BalaGAN, specifically designed to tackle the domain imbalance problem. We leverage the latent modalities of the richer domain to turn the image-to-image translation problem, between two imbalanced domains, into a balanced, multi-class, and conditional translation problem, more resembling the style transfer setting. Specifically, we analyze the source domain and learn a decomposition of it into a set of latent modes or classes, without any supervision. This leaves us with a multitude of balanced cross-domain translation tasks, between all pairs of classes, including the target domain. During inference, the trained network takes as input a source image, as well as a reference or style image from one of the modes as a condition, and produces an image which resembles the source on the pixel-wise level, but shares the same mode as the reference. We show that employing modalities within the dataset improves the quality of the translated images, and that BalaGAN outperforms strong baselines of both unconditioned and style-transfer-based image-to-image translation methods, in terms of image quality and diversity.
Realistic Full-Body Anonymization with Surface-Guided GANs
Jan 06, 2022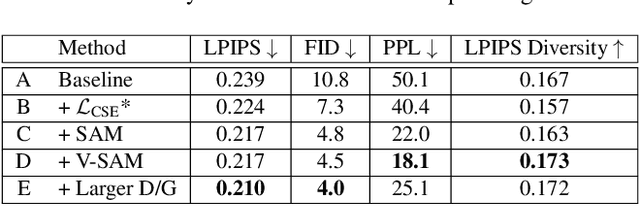

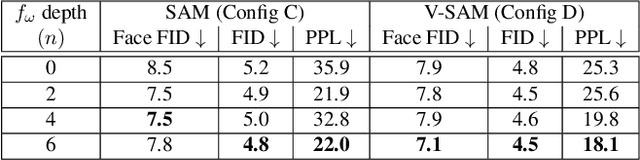
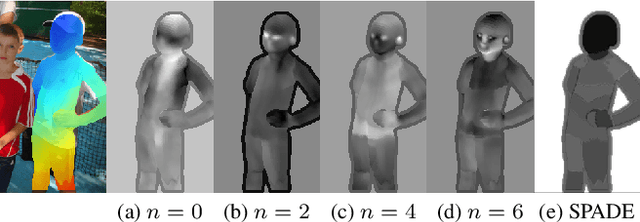
Recent work on image anonymization has shown that generative adversarial networks (GANs) can generate near-photorealistic faces to anonymize individuals. However, scaling these networks to the entire human body has remained a challenging and yet unsolved task. We propose a new anonymization method that generates close-to-photorealistic humans for in-the-wild images.A key part of our design is to guide adversarial nets by dense pixel-to-surface correspondences between an image and a canonical 3D surface.We introduce Variational Surface-Adaptive Modulation (V-SAM) that embeds surface information throughout the generator.Combining this with our novel discriminator surface supervision loss, the generator can synthesize high quality humans with diverse appearance in complex and varying scenes.We show that surface guidance significantly improves image quality and diversity of samples, yielding a highly practical generator.Finally, we demonstrate that surface-guided anonymization preserves the usability of data for future computer vision development
AE-Netv2: Optimization of Image Fusion Efficiency and Network Architecture
Oct 05, 2020
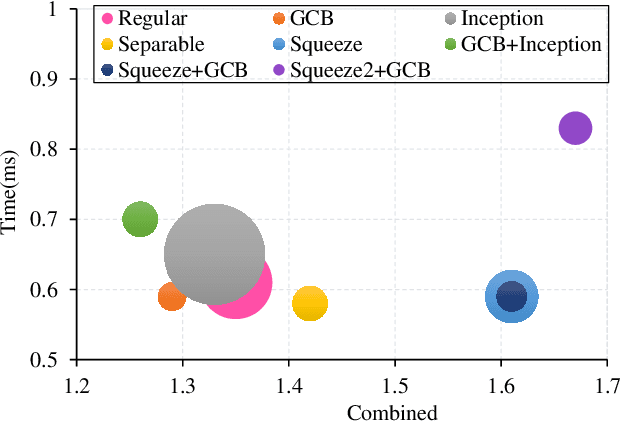

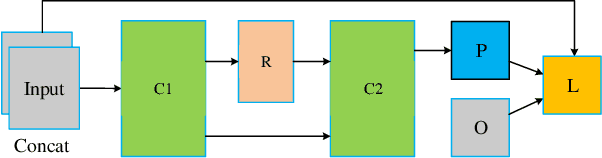
Existing image fusion methods pay few research attention to image fusion efficiency and network architecture. However, the efficiency and accuracy of image fusion has an important impact in practical applications. To solve this problem, we propose an \textit{efficient autonomous evolution image fusion method, dubed by AE-Netv2}. Different from other image fusion methods based on deep learning, AE-Netv2 is inspired by human brain cognitive mechanism. Firstly, we discuss the influence of different network architecture on image fusion quality and fusion efficiency, which provides a reference for the design of image fusion architecture. Secondly, we explore the influence of pooling layer on image fusion task and propose an image fusion method with pooling layer. Finally, we explore the commonness and characteristics of different image fusion tasks, which provides a research basis for further research on the continuous learning characteristics of human brain in the field of image fusion. Comprehensive experiments demonstrate the superiority of AE-Netv2 compared with state-of-the-art methods in different fusion tasks at a real time speed of 100+ FPS on GTX 2070. Among all tested methods based on deep learning, AE-Netv2 has the faster speed, the smaller model size and the better robustness.
Sampling Bias Correction for Supervised Machine Learning: A Bayesian Inference Approach with Practical Applications
Mar 15, 2022Given a supervised machine learning problem where the training set has been subject to a known sampling bias, how can a model be trained to fit the original dataset? We achieve this through the Bayesian inference framework by altering the posterior distribution to account for the sampling function. We then apply this solution to binary logistic regression, and discuss scenarios where a dataset might be subject to intentional sample bias such as label imbalance. This technique is widely applicable for statistical inference on big data, from the medical sciences to image recognition to marketing. Familiarity with it will give the practitioner tools to improve their inference pipeline from data collection to model selection.
HDRUNet: Single Image HDR Reconstruction with Denoising and Dequantization
Jun 19, 2021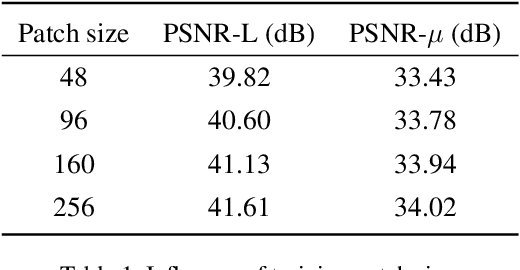
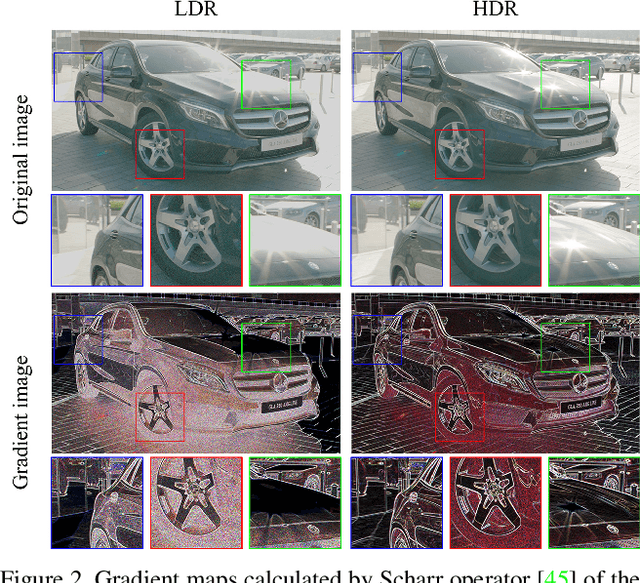
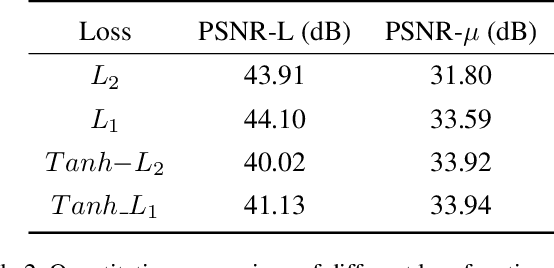
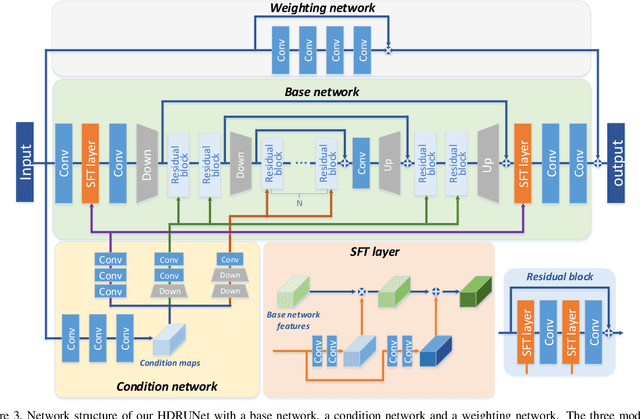
Most consumer-grade digital cameras can only capture a limited range of luminance in real-world scenes due to sensor constraints. Besides, noise and quantization errors are often introduced in the imaging process. In order to obtain high dynamic range (HDR) images with excellent visual quality, the most common solution is to combine multiple images with different exposures. However, it is not always feasible to obtain multiple images of the same scene and most HDR reconstruction methods ignore the noise and quantization loss. In this work, we propose a novel learning-based approach using a spatially dynamic encoder-decoder network, HDRUNet, to learn an end-to-end mapping for single image HDR reconstruction with denoising and dequantization. The network consists of a UNet-style base network to make full use of the hierarchical multi-scale information, a condition network to perform pattern-specific modulation and a weighting network for selectively retaining information. Moreover, we propose a Tanh_L1 loss function to balance the impact of over-exposed values and well-exposed values on the network learning. Our method achieves the state-of-the-art performance in quantitative comparisons and visual quality. The proposed HDRUNet model won the second place in the single frame track of NITRE2021 High Dynamic Range Challenge.