 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Omni-Directional Image Generation from Single Snapshot Image
Oct 12, 2020
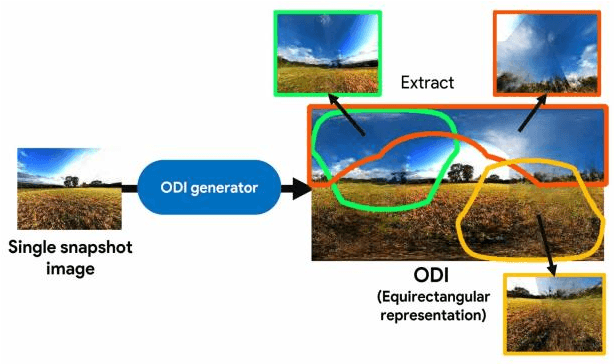
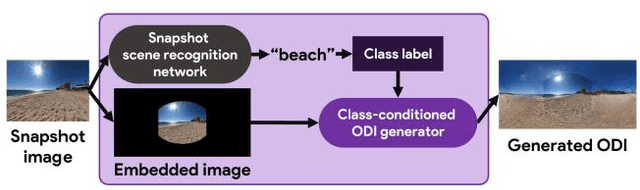
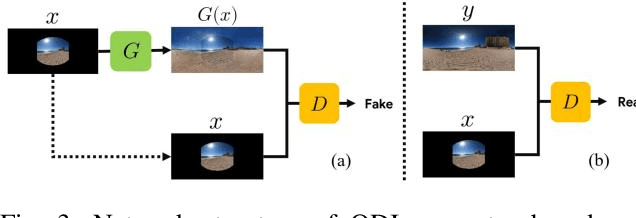
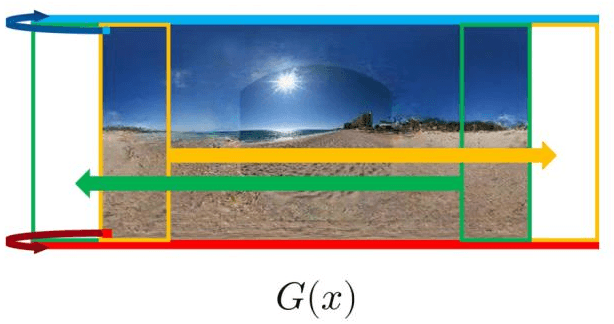
An omni-directional image (ODI) is the image that has a field of view covering the entire sphere around the camera. The ODIs have begun to be used in a wide range of fields such as virtual reality (VR), robotics, and social network services. Although the contents using ODI have increased, the available images and videos are still limited, compared with widespread snapshot images. A large number of ODIs are desired not only for the VR contents, but also for training deep learning models for ODI. For these purposes, a novel computer vision task to generate ODI from a single snapshot image is proposed in this paper. To tackle this problem, the conditional generative adversarial network was applied in combination with class-conditioned convolution layers. With this novel task, VR images and videos will be easily created even with a smartphone camera.
Image Compression with Encoder-Decoder Matched Semantic Segmentation
Jan 30, 2021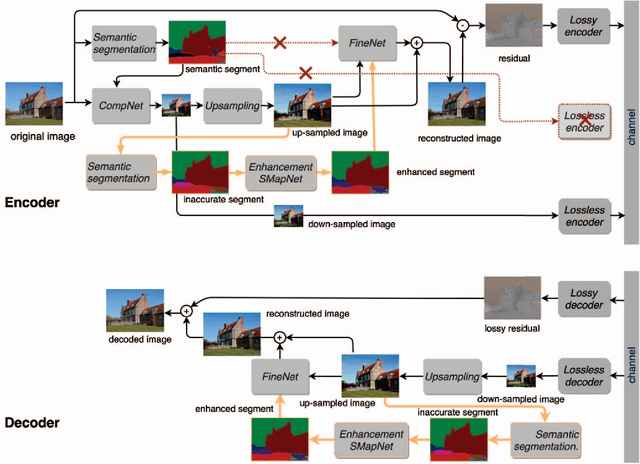

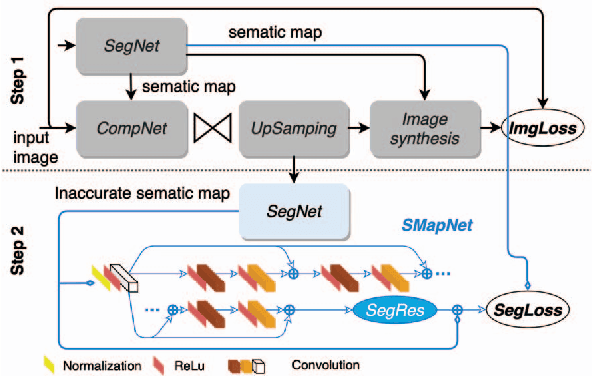
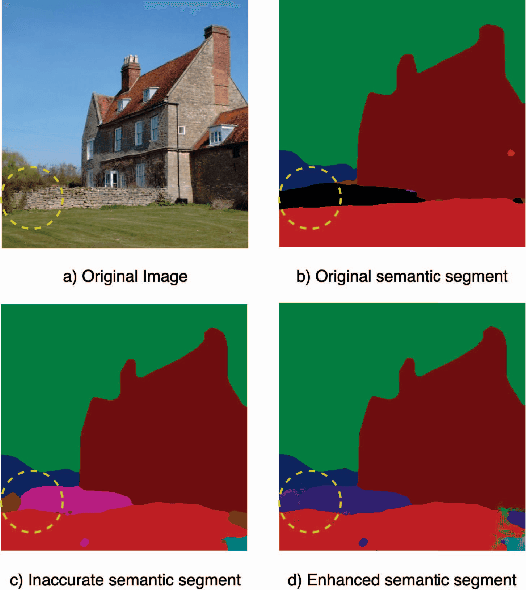
In recent years, layered image compression is demonstrated to be a promising direction, which encodes a compact representation of the input image and apply an up-sampling network to reconstruct the image. To further improve the quality of the reconstructed image, some works transmit the semantic segment together with the compressed image data. Consequently, the compression ratio is also decreased because extra bits are required for transmitting the semantic segment. To solve this problem, we propose a new layered image compression framework with encoder-decoder matched semantic segmentation (EDMS). And then, followed by the semantic segmentation, a special convolution neural network is used to enhance the inaccurate semantic segment. As a result, the accurate semantic segment can be obtained in the decoder without requiring extra bits. The experimental results show that the proposed EDMS framework can get up to 35.31% BD-rate reduction over the HEVC-based (BPG) codec, 5% bitrate, and 24% encoding time saving compare to the state-of-the-art semantic-based image codec.
Rethinking Generic Camera Models for Deep Single Image Camera Calibration to Recover Rotation and Fisheye Distortion
Nov 25, 2021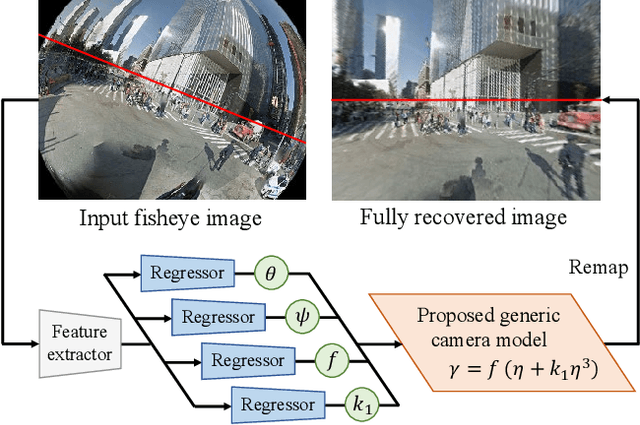
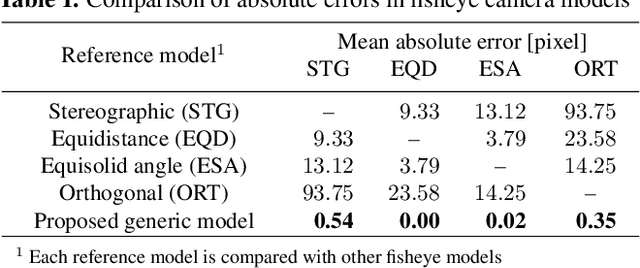
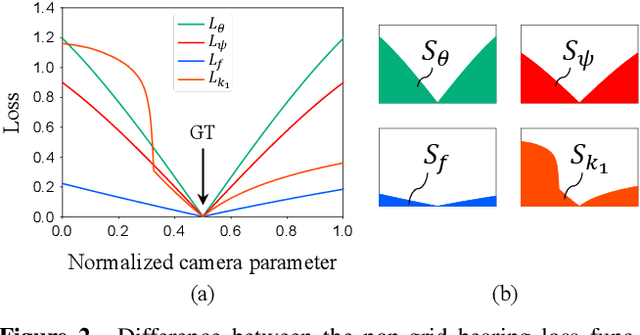
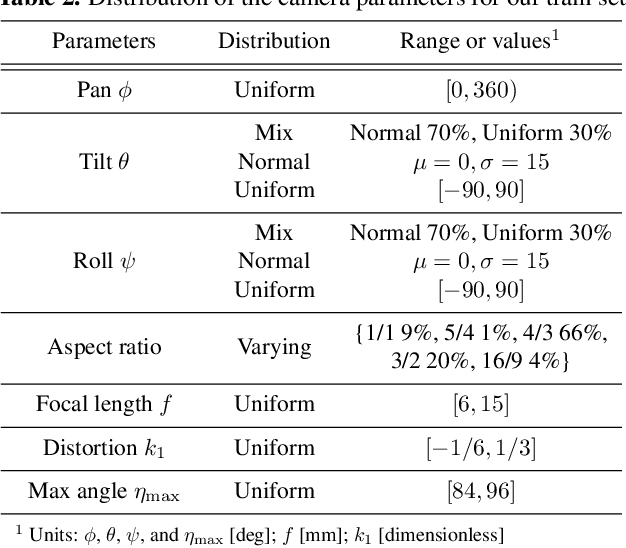
Although recent learning-based calibration methods can predict extrinsic and intrinsic camera parameters from a single image, the accuracy of these methods is degraded in fisheye images. This degradation is caused by mismatching between the actual projection and expected projection. To address this problem, we propose a generic camera model that has the potential to address various types of distortion. Our generic camera model is utilized for learning-based methods through a closed-form numerical calculation of the camera projection. Simultaneously to recover rotation and fisheye distortion, we propose a learning-based calibration method that uses the camera model. Furthermore, we propose a loss function that alleviates the bias of the magnitude of errors for four extrinsic and intrinsic camera parameters. Extensive experiments demonstrated that our proposed method outperformed conventional methods on two largescale datasets and images captured by off-the-shelf fisheye cameras. Moreover, we are the first researchers to analyze the performance of learning-based methods using various types of projection for off-the-shelf cameras.
Exploiting Correspondences with All-pairs Correlations for Multi-view Depth Estimation
May 05, 2022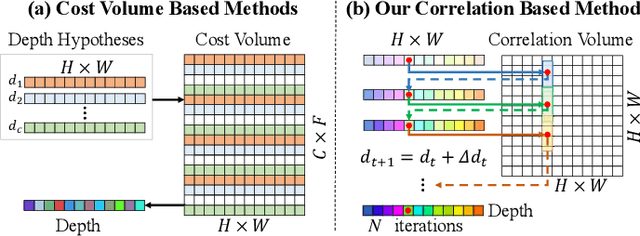
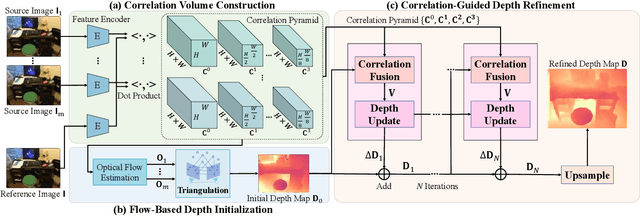
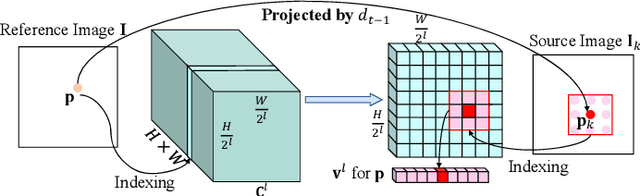
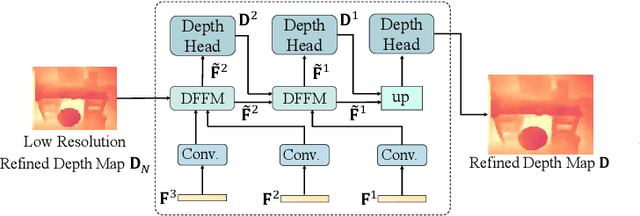
Multi-view depth estimation plays a critical role in reconstructing and understanding the 3D world. Recent learning-based methods have made significant progress in it. However, multi-view depth estimation is fundamentally a correspondence-based optimization problem, but previous learning-based methods mainly rely on predefined depth hypotheses to build correspondence as the cost volume and implicitly regularize it to fit depth prediction, deviating from the essence of iterative optimization based on stereo correspondence. Thus, they suffer unsatisfactory precision and generalization capability. In this paper, we are the first to explore more general image correlations to establish correspondences dynamically for depth estimation. We design a novel iterative multi-view depth estimation framework mimicking the optimization process, which consists of 1) a correlation volume construction module that models the pixel similarity between a reference image and source images as all-to-all correlations; 2) a flow-based depth initialization module that estimates the depth from the 2D optical flow; 3) a novel correlation-guided depth refinement module that reprojects points in different views to effectively fetch relevant correlations for further fusion and integrate the fused correlation for iterative depth update. Without predefined depth hypotheses, the fused correlations establish multi-view correspondence in an efficient way and guide the depth refinement heuristically. We conduct sufficient experiments on ScanNet, DeMoN, ETH3D, and 7Scenes to demonstrate the superiority of our method on multi-view depth estimation and its best generalization ability.
Diverse facial inpainting guided by exemplars
Feb 15, 2022
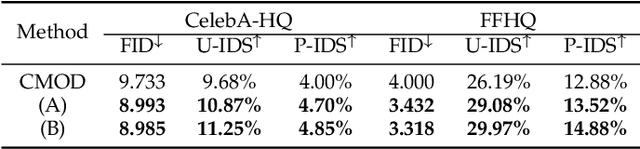
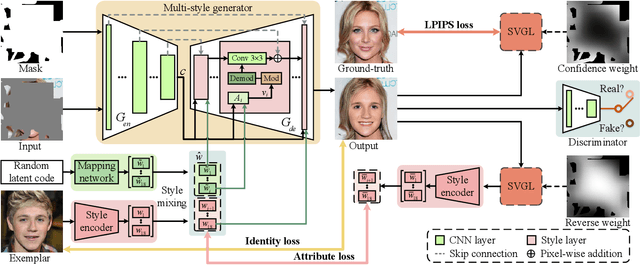
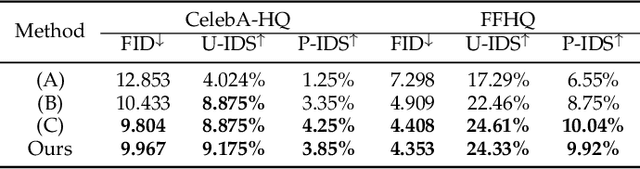
Facial image inpainting is a task of filling visually realistic and semantically meaningful contents for missing or masked pixels in a face image. Although existing methods have made significant progress in achieving high visual quality, the controllable diversity of facial image inpainting remains an open problem in this field. This paper introduces EXE-GAN, a novel diverse and interactive facial inpainting framework, which can not only preserve the high-quality visual effect of the whole image but also complete the face image with exemplar-like facial attributes. The proposed facial inpainting is achieved based on generative adversarial networks by leveraging the global style of input image, the stochastic style, and the exemplar style of exemplar image. A novel attribute similarity metric is introduced to encourage networks to learn the style of facial attributes from the exemplar in a self-supervised way. To guarantee the natural transition across the boundary of inpainted regions, a novel spatial variant gradient backpropagation technique is designed to adjust the loss gradients based on the spatial location. A variety of experimental results and comparisons on public CelebA-HQ and FFHQ datasets are presented to demonstrate the superiority of the proposed method in terms of both the quality and diversity in facial inpainting.
Federated Multi-organ Segmentation with Partially Labeled Data
Jun 14, 2022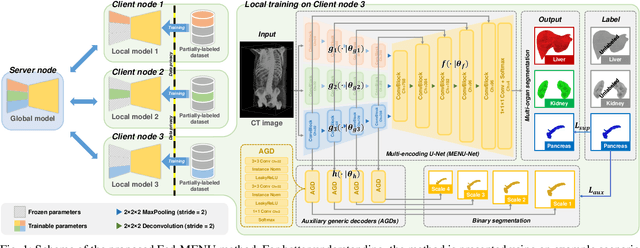
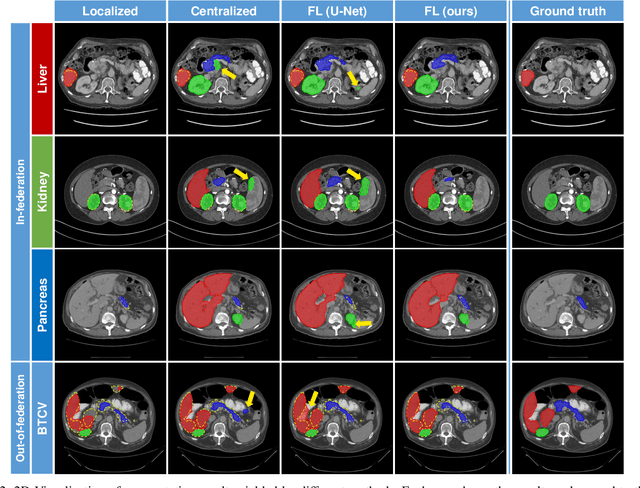
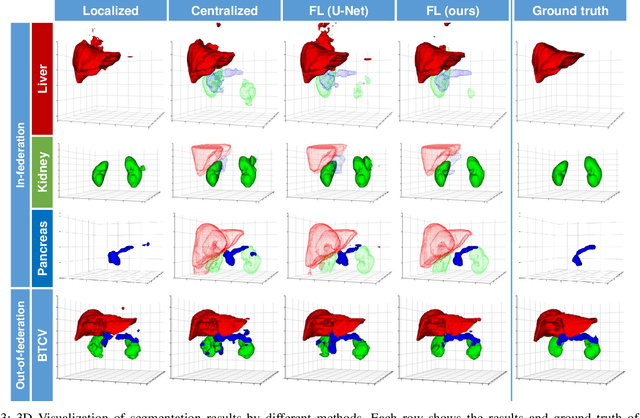
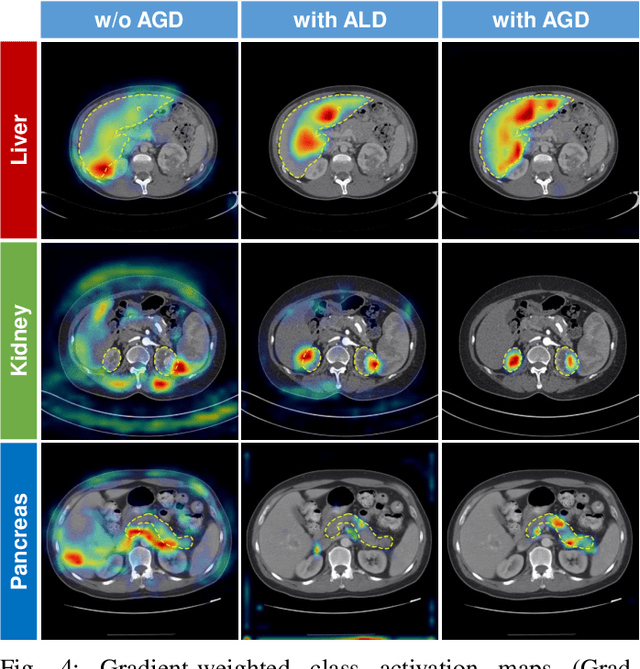
Federated learning is an emerging paradigm allowing large-scale decentralized learning without sharing data across different data owners, which helps address the concern of data privacy in medical image analysis. However, the requirement for label consistency across clients by the existing methods largely narrows its application scope. In practice, each clinical site may only annotate certain organs of interest with partial or no overlap with other sites. Incorporating such partially labeled data into a unified federation is an unexplored problem with clinical significance and urgency. This work tackles the challenge by using a novel federated multi-encoding U-Net (Fed-MENU) method for multi-organ segmentation. In our method, a multi-encoding U-Net (MENU-Net) is proposed to extract organ-specific features through different encoding sub-networks. Each sub-network can be seen as an expert of a specific organ and trained for that client. Moreover, to encourage the organ-specific features extracted by different sub-networks to be informative and distinctive, we regularize the training of the MENU-Net by designing an auxiliary generic decoder (AGD). Extensive experiments on four public datasets show that our Fed-MENU method can effectively obtain a federated learning model using the partially labeled datasets with superior performance to other models trained by either localized or centralized learning methods. Source code will be made publicly available at the time of paper publication.
Soft Compression for Lossless Image Coding
Dec 11, 2020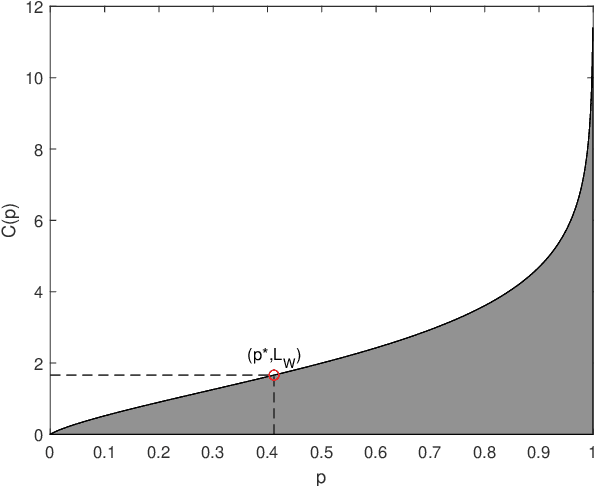
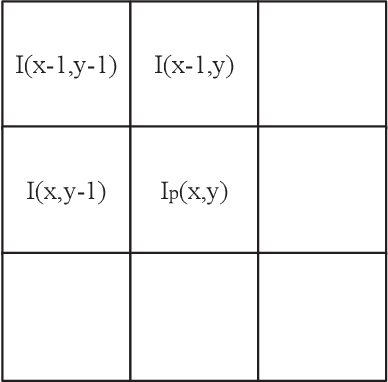
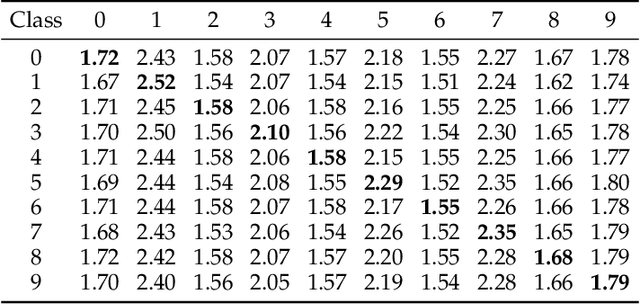

Soft compression is a lossless image compression method, which is committed to eliminating coding redundancy and spatial redundancy at the same time by adopting locations and shapes of codebook to encode an image from the perspective of information theory and statistical distribution. In this paper, we propose a new concept, compressible indicator function with regard to image, which gives a threshold about the average number of bits required to represent a location and can be used for revealing the performance of soft compression. We investigate and analyze soft compression for binary image, gray image and multi-component image by using specific algorithms and compressible indicator value. It is expected that the bandwidth and storage space needed when transmitting and storing the same kind of images can be greatly reduced by applying soft compression.
A case for using rotation invariant features in state of the art feature matchers
Apr 21, 2022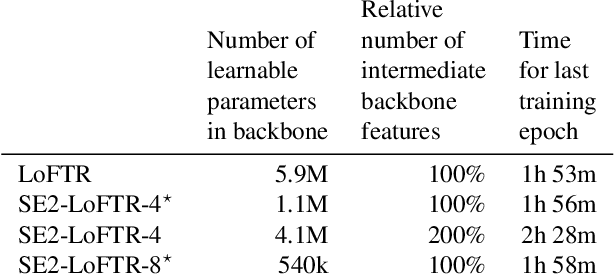

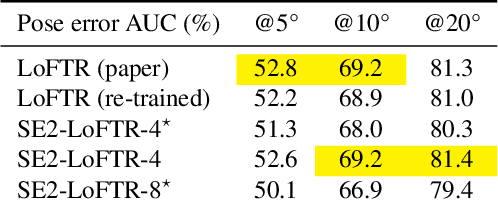
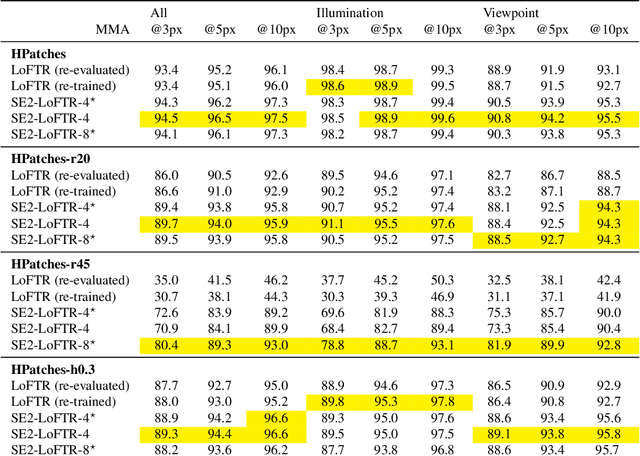
The aim of this paper is to demonstrate that a state of the art feature matcher (LoFTR) can be made more robust to rotations by simply replacing the backbone CNN with a steerable CNN which is equivariant to translations and image rotations. It is experimentally shown that this boost is obtained without reducing performance on ordinary illumination and viewpoint matching sequences.
Anycost GANs for Interactive Image Synthesis and Editing
Mar 04, 2021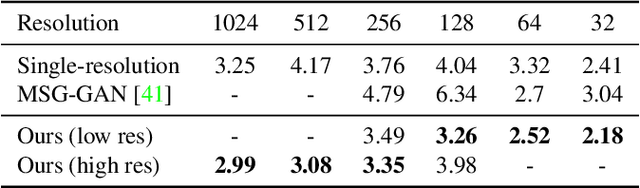
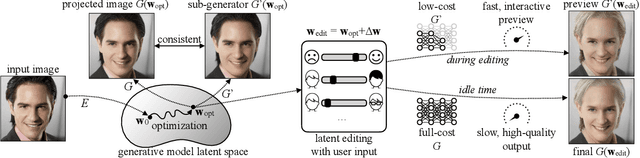

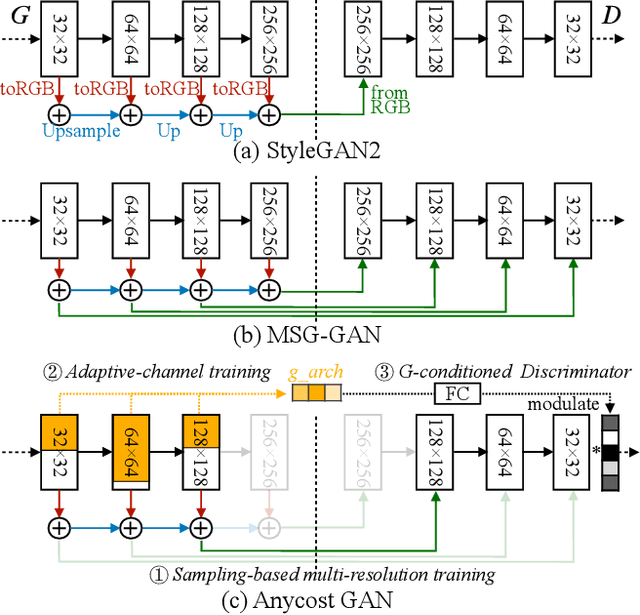
Generative adversarial networks (GANs) have enabled photorealistic image synthesis and editing. However, due to the high computational cost of large-scale generators (e.g., StyleGAN2), it usually takes seconds to see the results of a single edit on edge devices, prohibiting interactive user experience. In this paper, we take inspirations from modern rendering software and propose Anycost GAN for interactive natural image editing. We train the Anycost GAN to support elastic resolutions and channels for faster image generation at versatile speeds. Running subsets of the full generator produce outputs that are perceptually similar to the full generator, making them a good proxy for preview. By using sampling-based multi-resolution training, adaptive-channel training, and a generator-conditioned discriminator, the anycost generator can be evaluated at various configurations while achieving better image quality compared to separately trained models. Furthermore, we develop new encoder training and latent code optimization techniques to encourage consistency between the different sub-generators during image projection. Anycost GAN can be executed at various cost budgets (up to 10x computation reduction) and adapt to a wide range of hardware and latency requirements. When deployed on desktop CPUs and edge devices, our model can provide perceptually similar previews at 6-12x speedup, enabling interactive image editing. The code and demo are publicly available: https://github.com/mit-han-lab/anycost-gan.
Pruning-as-Search: Efficient Neural Architecture Search via Channel Pruning and Structural Reparameterization
Jun 02, 2022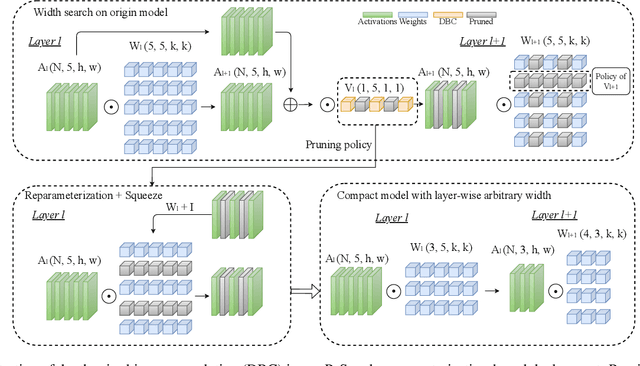
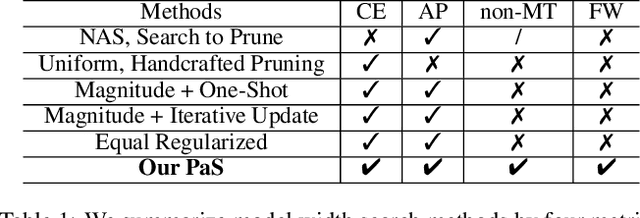

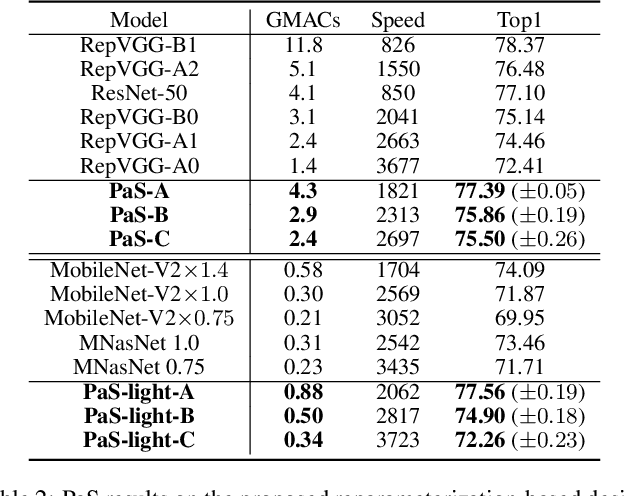
Neural architecture search (NAS) and network pruning are widely studied efficient AI techniques, but not yet perfect. NAS performs exhaustive candidate architecture search, incurring tremendous search cost. Though (structured) pruning can simply shrink model dimension, it remains unclear how to decide the per-layer sparsity automatically and optimally. In this work, we revisit the problem of layer-width optimization and propose Pruning-as-Search (PaS), an end-to-end channel pruning method to search out desired sub-network automatically and efficiently. Specifically, we add a depth-wise binary convolution to learn pruning policies directly through gradient descent. By combining the structural reparameterization and PaS, we successfully searched out a new family of VGG-like and lightweight networks, which enable the flexibility of arbitrary width with respect to each layer instead of each stage. Experimental results show that our proposed architecture outperforms prior arts by around $1.0\%$ top-1 accuracy under similar inference speed on ImageNet-1000 classification task. Furthermore, we demonstrate the effectiveness of our width search on complex tasks including instance segmentation and image translation. Code and models are released.