 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Biosignals-Free Autonomous Prosthetic Hand Control via Imitation Learning
Jun 10, 2025



Limb loss affects millions globally, impairing physical function and reducing quality of life. Most traditional surface electromyographic (sEMG) and semi-autonomous methods require users to generate myoelectric signals for each control, imposing physically and mentally taxing demands. This study aims to develop a fully autonomous control system that enables a prosthetic hand to automatically grasp and release objects of various shapes using only a camera attached to the wrist. By placing the hand near an object, the system will automatically execute grasping actions with a proper grip force in response to the hand's movements and the environment. To release the object being grasped, just naturally place the object close to the table and the system will automatically open the hand. Such a system would provide individuals with limb loss with a very easy-to-use prosthetic control interface and greatly reduce mental effort while using. To achieve this goal, we developed a teleoperation system to collect human demonstration data for training the prosthetic hand control model using imitation learning, which mimics the prosthetic hand actions from human. Through training the model using only a few objects' data from one single participant, we have shown that the imitation learning algorithm can achieve high success rates, generalizing to more individuals and unseen objects with a variation of weights. The demonstrations are available at \href{https://sites.google.com/view/autonomous-prosthetic-hand}{https://sites.google.com/view/autonomous-prosthetic-hand}
GRIG: Few-Shot Generative Residual Image Inpainting
Apr 24, 2023



Image inpainting is the task of filling in missing or masked region of an image with semantically meaningful contents. Recent methods have shown significant improvement in dealing with large-scale missing regions. However, these methods usually require large training datasets to achieve satisfactory results and there has been limited research into training these models on a small number of samples. To address this, we present a novel few-shot generative residual image inpainting method that produces high-quality inpainting results. The core idea is to propose an iterative residual reasoning method that incorporates Convolutional Neural Networks (CNNs) for feature extraction and Transformers for global reasoning within generative adversarial networks, along with image-level and patch-level discriminators. We also propose a novel forgery-patch adversarial training strategy to create faithful textures and detailed appearances. Extensive evaluations show that our method outperforms previous methods on the few-shot image inpainting task, both quantitatively and qualitatively.
Diverse facial inpainting guided by exemplars
Feb 15, 2022
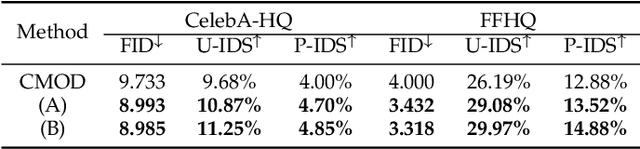
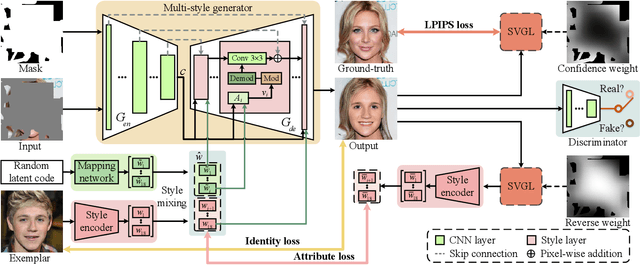
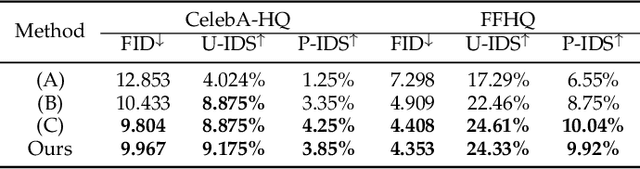
Facial image inpainting is a task of filling visually realistic and semantically meaningful contents for missing or masked pixels in a face image. Although existing methods have made significant progress in achieving high visual quality, the controllable diversity of facial image inpainting remains an open problem in this field. This paper introduces EXE-GAN, a novel diverse and interactive facial inpainting framework, which can not only preserve the high-quality visual effect of the whole image but also complete the face image with exemplar-like facial attributes. The proposed facial inpainting is achieved based on generative adversarial networks by leveraging the global style of input image, the stochastic style, and the exemplar style of exemplar image. A novel attribute similarity metric is introduced to encourage networks to learn the style of facial attributes from the exemplar in a self-supervised way. To guarantee the natural transition across the boundary of inpainted regions, a novel spatial variant gradient backpropagation technique is designed to adjust the loss gradients based on the spatial location. A variety of experimental results and comparisons on public CelebA-HQ and FFHQ datasets are presented to demonstrate the superiority of the proposed method in terms of both the quality and diversity in facial inpainting.