 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Bornon: Bengali Image Captioning with Transformer-based Deep learning approach
Sep 11, 2021
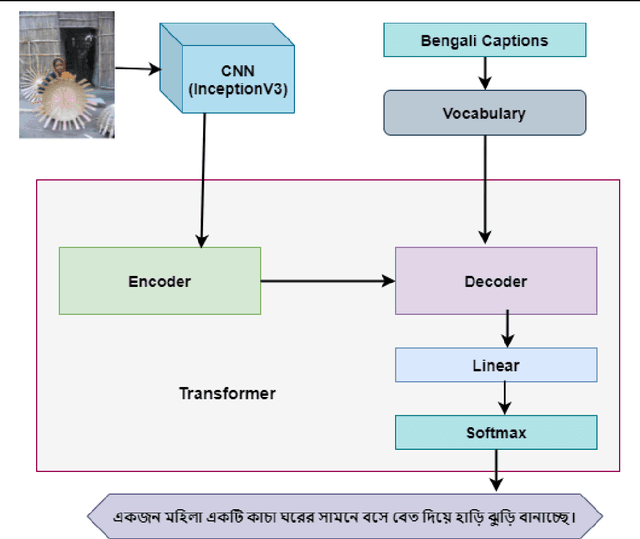

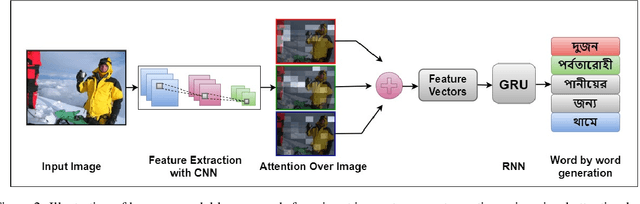
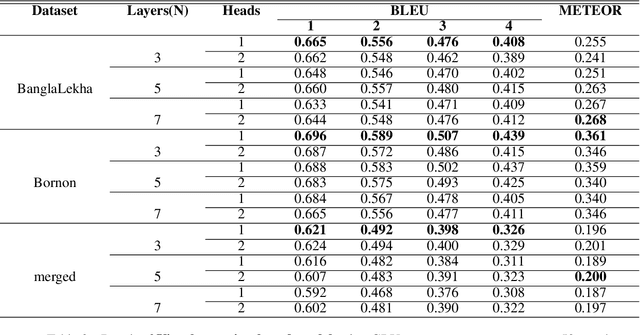
Image captioning using Encoder-Decoder based approach where CNN is used as the Encoder and sequence generator like RNN as Decoder has proven to be very effective. However, this method has a drawback that is sequence needs to be processed in order. To overcome this drawback some researcher has utilized the Transformer model to generate captions from images using English datasets. However, none of them generated captions in Bengali using the transformer model. As a result, we utilized three different Bengali datasets to generate Bengali captions from images using the Transformer model. Additionally, we compared the performance of the transformer-based model with a visual attention-based Encoder-Decoder approach. Finally, we compared the result of the transformer-based model with other models that employed different Bengali image captioning datasets.
Pyramid Hybrid Pooling Quantization for Efficient Fine-Grained Image Retrieval
Sep 11, 2021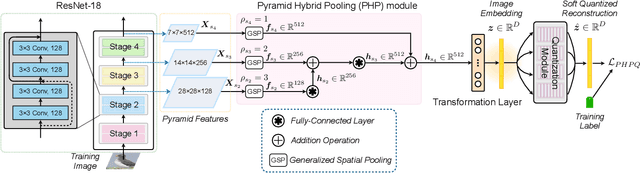
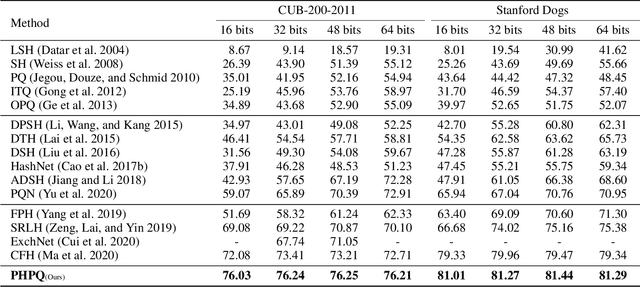
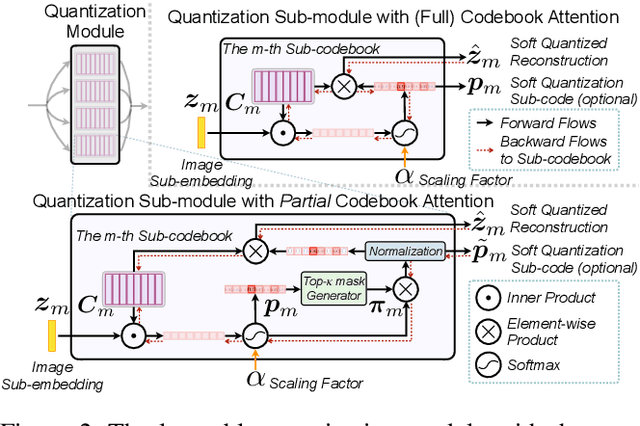
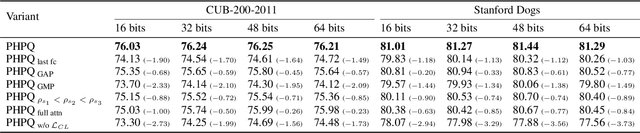
Deep hashing approaches, including deep quantization and deep binary hashing, have become a common solution to large-scale image retrieval due to high computation and storage efficiency. Most existing hashing methods can not produce satisfactory results for fine-grained retrieval, because they usually adopt the outputs of the last CNN layer to generate binary codes, which is less effective to capture subtle but discriminative visual details. To improve fine-grained image hashing, we propose Pyramid Hybrid Pooling Quantization (PHPQ). Specifically, we propose a Pyramid Hybrid Pooling (PHP) module to capture and preserve fine-grained semantic information from multi-level features. Besides, we propose a learnable quantization module with a partial attention mechanism, which helps to optimize the most relevant codewords and improves the quantization. Comprehensive experiments demonstrate that PHPQ outperforms state-of-the-art methods.
Masked Spatial-Spectral Autoencoders Are Excellent Hyperspectral Defenders
Jul 16, 2022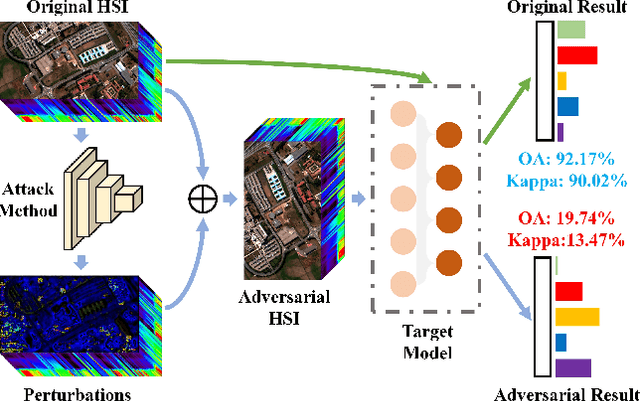
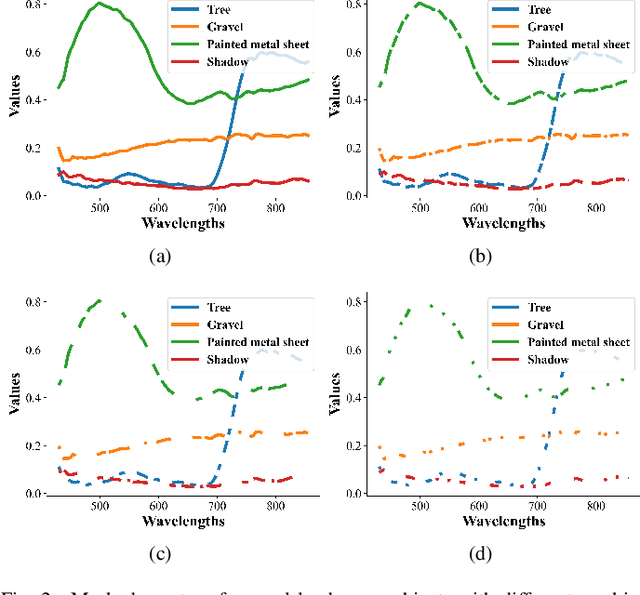

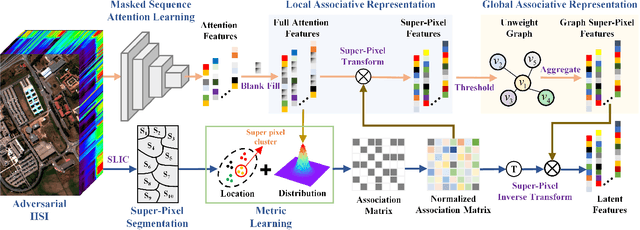
Deep learning methodology contributes a lot to the development of hyperspectral image (HSI) analysis community. However, it also makes HSI analysis systems vulnerable to adversarial attacks. To this end, we propose a masked spatial-spectral autoencoder (MSSA) in this paper under self-supervised learning theory, for enhancing the robustness of HSI analysis systems. First, a masked sequence attention learning module is conducted to promote the inherent robustness of HSI analysis systems along spectral channel. Then, we develop a graph convolutional network with learnable graph structure to establish global pixel-wise combinations.In this way, the attack effect would be dispersed by all the related pixels among each combination, and a better defense performance is achievable in spatial aspect.Finally, to improve the defense transferability and address the problem of limited labelled samples, MSSA employs spectra reconstruction as a pretext task and fits the datasets in a self-supervised manner.Comprehensive experiments over three benchmarks verify the effectiveness of MSSA in comparison with the state-of-the-art hyperspectral classification methods and representative adversarial defense strategies.
Self-supervised Correlation Mining Network for Person Image Generation
Nov 29, 2021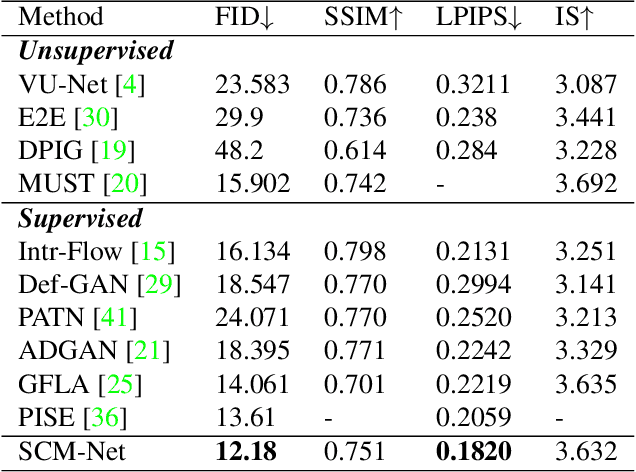
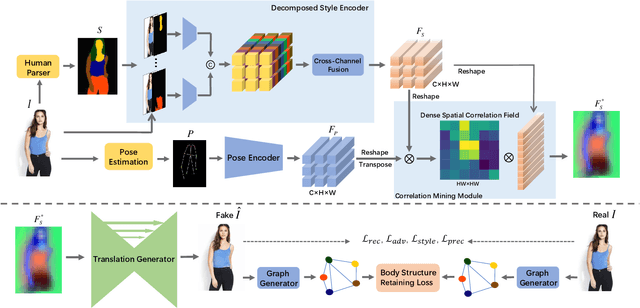
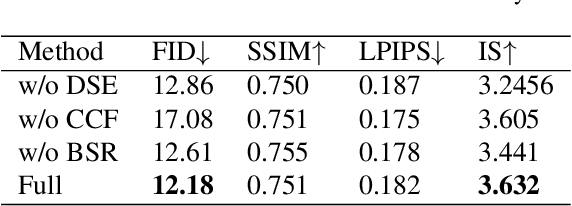

Person image generation aims to perform non-rigid deformation on source images, which generally requires unaligned data pairs for training. Recently, self-supervised methods express great prospects in this task by merging the disentangled representations for self-reconstruction. However, such methods fail to exploit the spatial correlation between the disentangled features. In this paper, we propose a Self-supervised Correlation Mining Network (SCM-Net) to rearrange the source images in the feature space, in which two collaborative modules are integrated, Decomposed Style Encoder (DSE) and Correlation Mining Module (CMM). Specifically, the DSE first creates unaligned pairs at the feature level. Then, the CMM establishes the spatial correlation field for feature rearrangement. Eventually, a translation module transforms the rearranged features to realistic results. Meanwhile, for improving the fidelity of cross-scale pose transformation, we propose a graph based Body Structure Retaining Loss (BSR Loss) to preserve reasonable body structures on half body to full body generation. Extensive experiments conducted on DeepFashion dataset demonstrate the superiority of our method compared with other supervised and unsupervised approaches. Furthermore, satisfactory results on face generation show the versatility of our method in other deformation tasks.
LAViTeR: Learning Aligned Visual and Textual Representations Assisted by Image and Caption Generation
Sep 04, 2021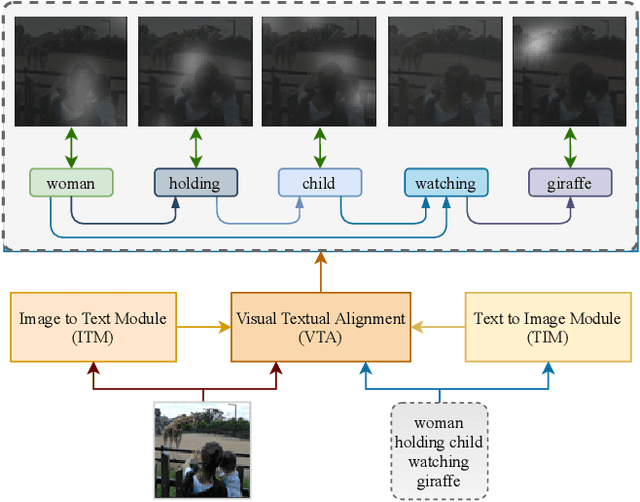
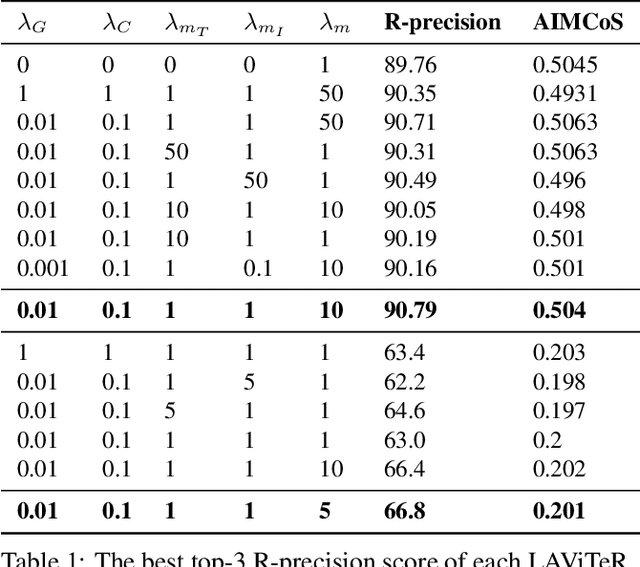
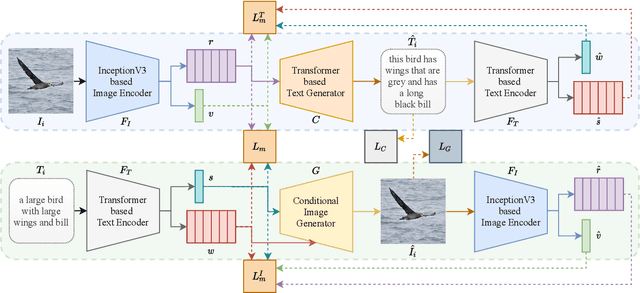
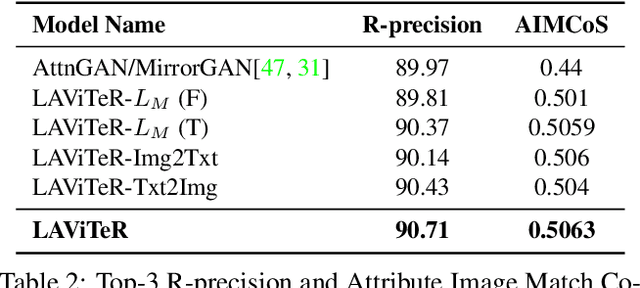
Pre-training visual and textual representations from large-scale image-text pairs is becoming a standard approach for many downstream vision-language tasks. The transformer-based models learn inter and intra-modal attention through a list of self-supervised learning tasks. This paper proposes LAViTeR, a novel architecture for visual and textual representation learning. The main module, Visual Textual Alignment (VTA) will be assisted by two auxiliary tasks, GAN-based image synthesis and Image Captioning. We also propose a new evaluation metric measuring the similarity between the learnt visual and textual embedding. The experimental results on two public datasets, CUB and MS-COCO, demonstrate superior visual and textual representation alignment in the joint feature embedding space
Improvement of image classification by multiple optical scattering
Jul 12, 2021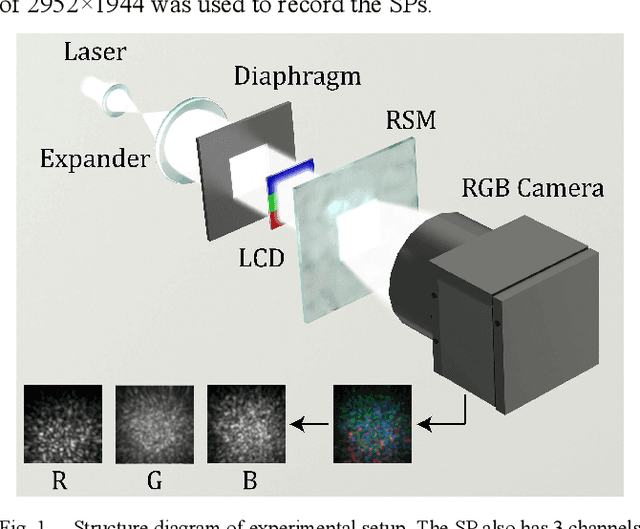
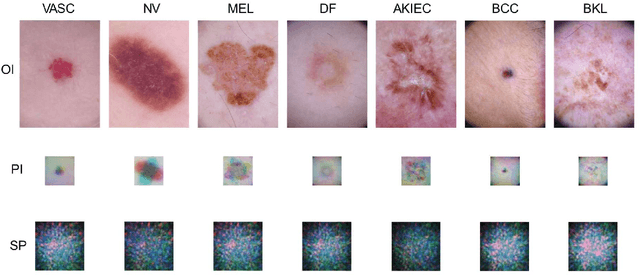
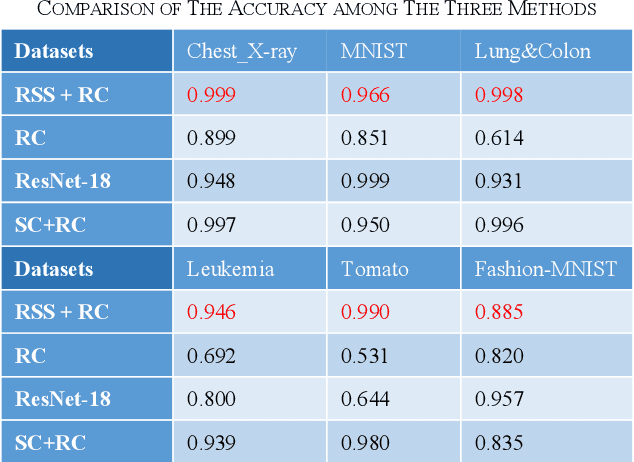
Multiple optical scattering occurs when light propagates in a non-uniform medium. During the multiple scattering, images were distorted and the spatial information they carried became scrambled. However, the image information is not lost but presents in the form of speckle patterns (SPs). In this study, we built up an optical random scattering system based on an LCD and an RGB laser source. We found that the image classification can be improved by the help of random scattering which is considered as a feedforward neural network to extracts features from image. Along with the ridge classification deployed on computer, we achieved excellent classification accuracy higher than 94%, for a variety of data sets covering medical, agricultural, environmental protection and other fields. In addition, the proposed optical scattering system has the advantages of high speed, low power consumption, and miniaturization, which is suitable for deploying in edge computing applications.
Understanding Transfer Learning for Chest Radiograph Clinical Report Generation with Modified Transformer Architectures
May 05, 2022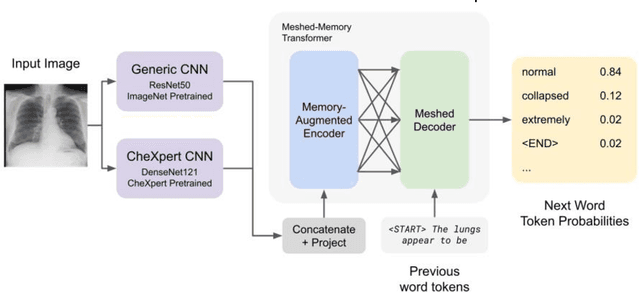
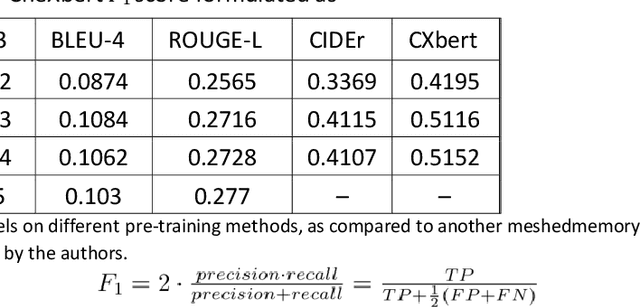
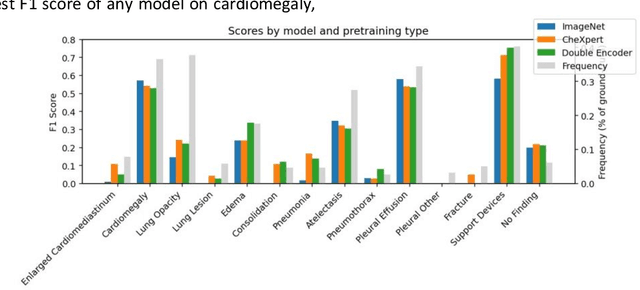

The image captioning task is increasingly prevalent in artificial intelligence applications for medicine. One important application is clinical report generation from chest radiographs. The clinical writing of unstructured reports is time consuming and error-prone. An automated system would improve standardization, error reduction, time consumption, and medical accessibility. In this paper we demonstrate the importance of domain specific pre-training and propose a modified transformer architecture for the medical image captioning task. To accomplish this, we train a series of modified transformers to generate clinical reports from chest radiograph image input. These modified transformers include: a meshed-memory augmented transformer architecture with visual extractor using ImageNet pre-trained weights, a meshed-memory augmented transformer architecture with visual extractor using CheXpert pre-trained weights, and a meshed-memory augmented transformer whose encoder is passed the concatenated embeddings using both ImageNet pre-trained weights and CheXpert pre-trained weights. We use BLEU(1-4), ROUGE-L, CIDEr, and the clinical CheXbert F1 scores to validate our models and demonstrate competitive scores with state of the art models. We provide evidence that ImageNet pre-training is ill-suited for the medical image captioning task, especially for less frequent conditions (eg: enlarged cardiomediastinum, lung lesion, pneumothorax). Furthermore, we demonstrate that the double feature model improves performance for specific medical conditions (edema, consolidation, pneumothorax, support devices) and overall CheXbert F1 score, and should be further developed in future work. Such a double feature model, including both ImageNet pre-training as well as domain specific pre-training, could be used in a wide range of image captioning models in medicine.
Invertible Image Signal Processing
Apr 06, 2021



Unprocessed RAW data is a highly valuable image format for image editing and computer vision. However, since the file size of RAW data is huge, most users can only get access to processed and compressed sRGB images. To bridge this gap, we design an Invertible Image Signal Processing (InvISP) pipeline, which not only enables rendering visually appealing sRGB images but also allows recovering nearly perfect RAW data. Due to our framework's inherent reversibility, we can reconstruct realistic RAW data instead of synthesizing RAW data from sRGB images without any memory overhead. We also integrate a differentiable JPEG compression simulator that empowers our framework to reconstruct RAW data from JPEG images. Extensive quantitative and qualitative experiments on two DSLR demonstrate that our method obtains much higher quality in both rendered sRGB images and reconstructed RAW data than alternative methods.
Image Based Reconstruction of Liquids from 2D Surface Detections
Nov 22, 2021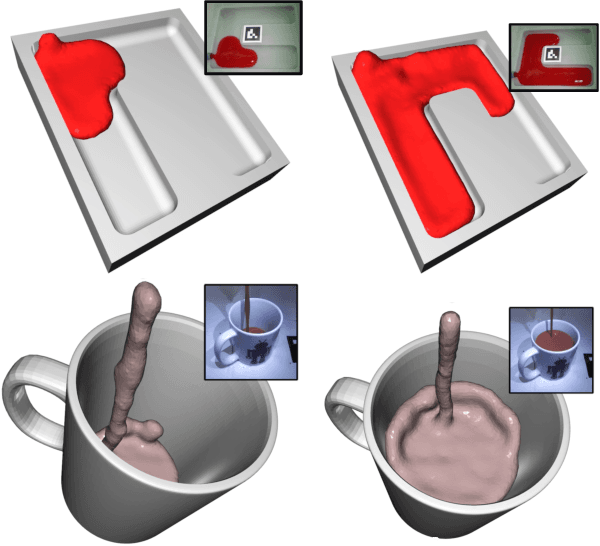
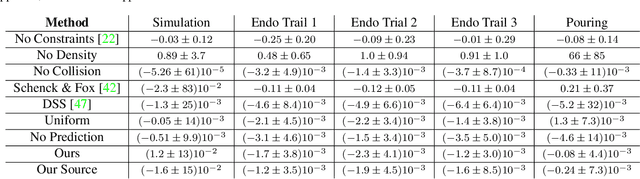
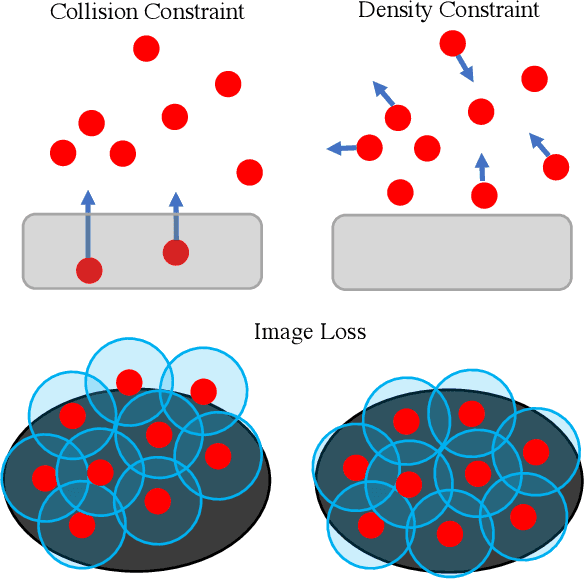
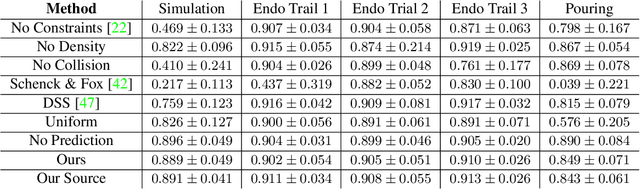
In this work, we present a solution to the challenging problem of reconstructing liquids from image data. The challenges in reconstructing liquids, which is not faced in previous reconstruction works on rigid and deforming surfaces, lies in the inability to use depth sensing and color features due the variable index of refraction, opacity, and environmental reflections. Therefore, we limit ourselves to only surface detections (i.e. binary mask) of liquids as observations and do not assume any prior knowledge on the liquids properties. A novel optimization problem is posed which reconstructs the liquid as particles by minimizing the error between a rendered surface from the particles and the surface detections while satisfying liquid constraints. Our solvers to this optimization problem are presented and no training data is required to apply them. We also propose a dynamic prediction to seed the reconstruction optimization from the previous time-step. We test our proposed methods in simulation and on two new liquid datasets which we open source so the broader research community can continue developing in this under explored area.
A Model-Agnostic SAT-based Approach for Symbolic Explanation Enumeration
Jun 23, 2022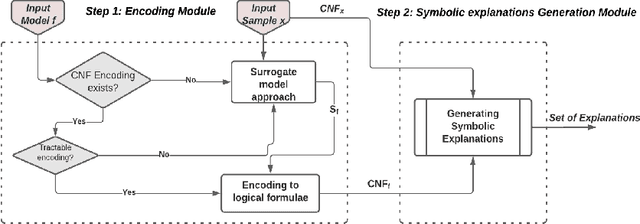
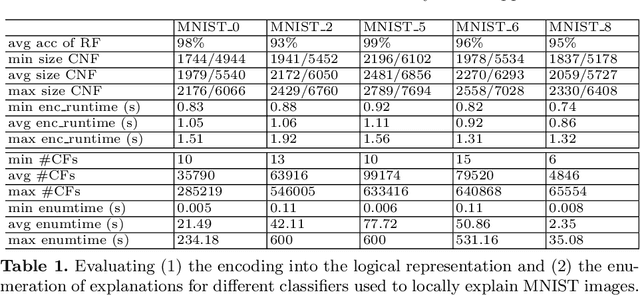
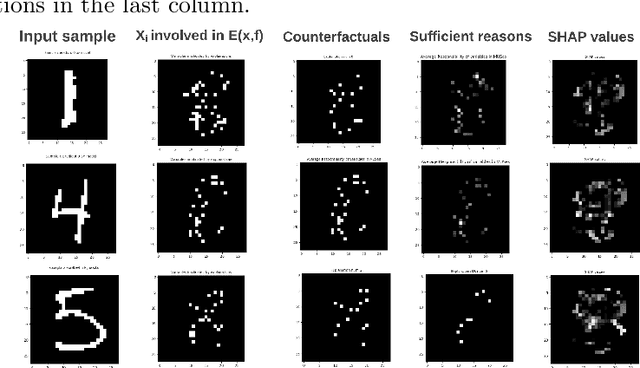
In this paper titled A Model-Agnostic SAT-based approach for Symbolic Explanation Enumeration we propose a generic agnostic approach allowing to generate different and complementary types of symbolic explanations. More precisely, we generate explanations to locally explain a single prediction by analyzing the relationship between the features and the output. Our approach uses a propositional encoding of the predictive model and a SAT-based setting to generate two types of symbolic explanations which are Sufficient Reasons and Counterfactuals. The experimental results on image classification task show the feasibility of the proposed approach and its effectiveness in providing Sufficient Reasons and Counterfactuals explanations.