 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
A Waste Copper Granules Rating System Based on Machine Vision
Jul 14, 2022
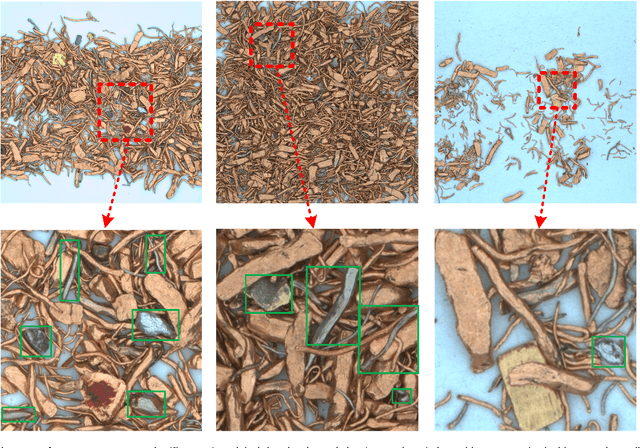
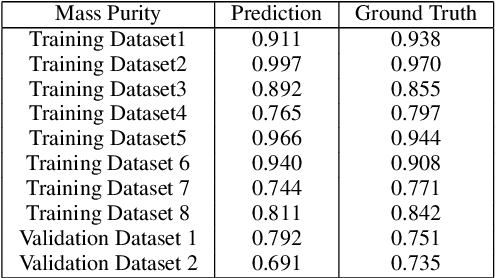

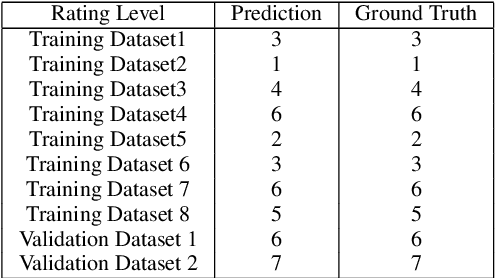
In the field of waste copper granules recycling, engineers should be able to identify all different sorts of impurities in waste copper granules and estimate their mass proportion relying on experience before rating. This manual rating method is costly, lacking in objectivity and comprehensiveness. To tackle this problem, we propose a waste copper granules rating system based on machine vision and deep learning. We firstly formulate the rating task into a 2D image recognition and purity regression task. Then we design a two-stage convolutional rating network to compute the mass purity and rating level of waste copper granules. Our rating network includes a segmentation network and a purity regression network, which respectively calculate the semantic segmentation heatmaps and purity results of the waste copper granules. After training the rating network on the augmented datasets, experiments on real waste copper granules demonstrate the effectiveness and superiority of the proposed network. Specifically, our system is superior to the manual method in terms of accuracy, effectiveness, robustness, and objectivity.
Lossy compression of multidimensional medical images using sinusoidal activation networks: an evaluation study
Aug 03, 2022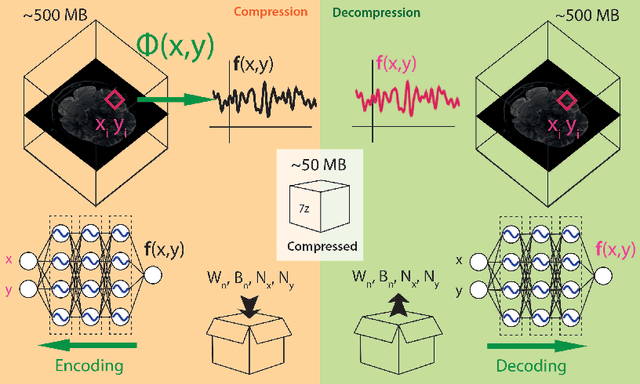
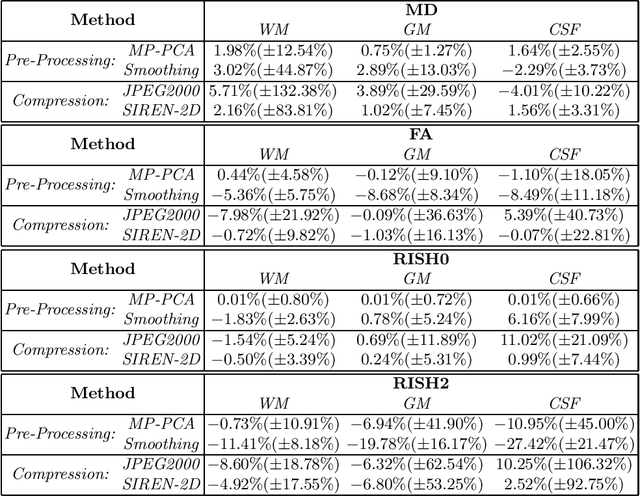
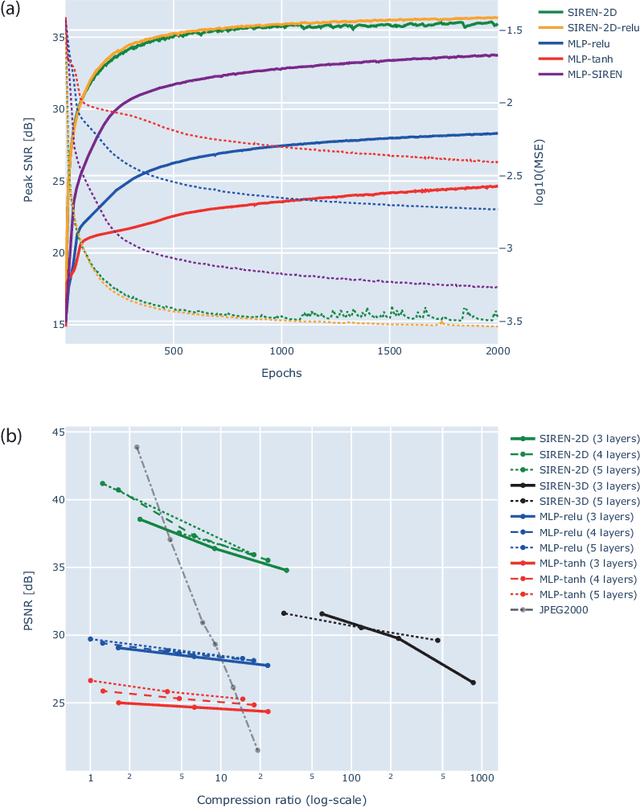
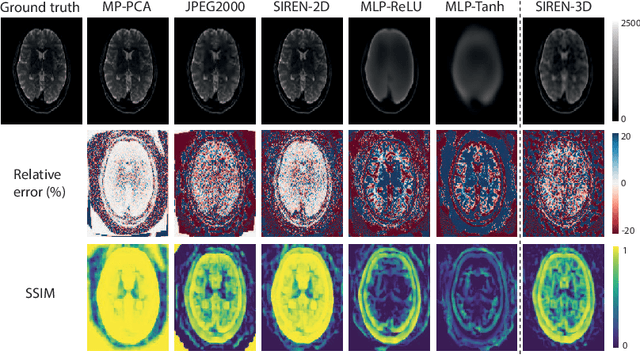
In this work, we evaluate how neural networks with periodic activation functions can be leveraged to reliably compress large multidimensional medical image datasets, with proof-of-concept application to 4D diffusion-weighted MRI (dMRI). In the medical imaging landscape, multidimensional MRI is a key area of research for developing biomarkers that are both sensitive and specific to the underlying tissue microstructure. However, the high-dimensional nature of these data poses a challenge in terms of both storage and sharing capabilities and associated costs, requiring appropriate algorithms able to represent the information in a low-dimensional space. Recent theoretical developments in deep learning have shown how periodic activation functions are a powerful tool for implicit neural representation of images and can be used for compression of 2D images. Here we extend this approach to 4D images and show how any given 4D dMRI dataset can be accurately represented through the parameters of a sinusoidal activation network, achieving a data compression rate about 10 times higher than the standard DEFLATE algorithm. Our results show that the proposed approach outperforms benchmark ReLU and Tanh activation perceptron architectures in terms of mean squared error, peak signal-to-noise ratio and structural similarity index. Subsequent analyses using the tensor and spherical harmonics representations demonstrate that the proposed lossy compression reproduces accurately the characteristics of the original data, leading to relative errors about 5 to 10 times lower than the benchmark JPEG2000 lossy compression and similar to standard pre-processing steps such as MP-PCA denosing, suggesting a loss of information within the currently accepted levels for clinical application.
Toward Real-world Image Super-resolution via Hardware-based Adaptive Degradation Models
Oct 20, 2021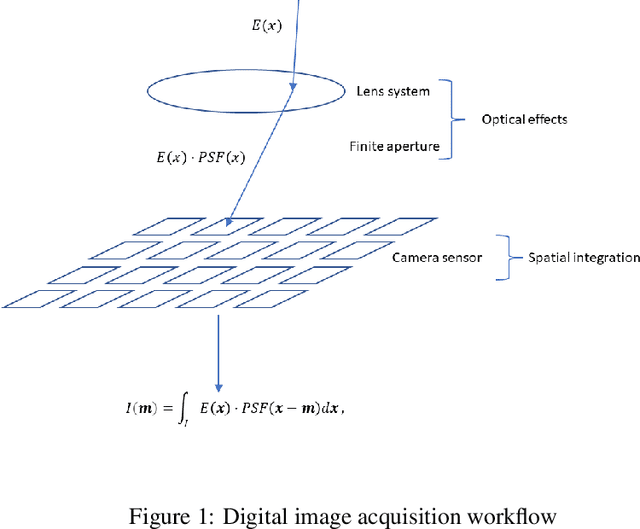
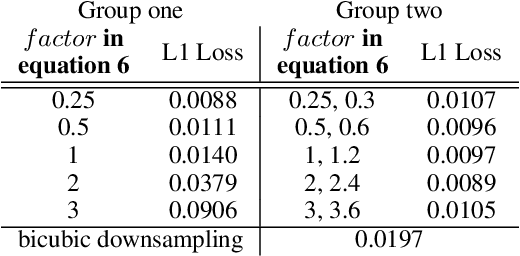
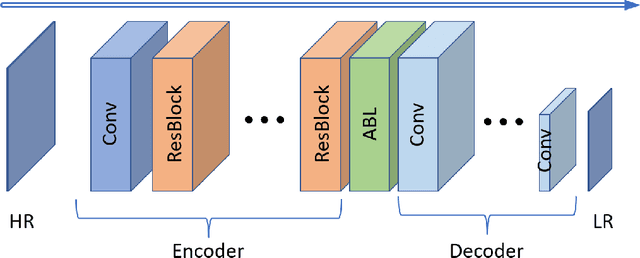
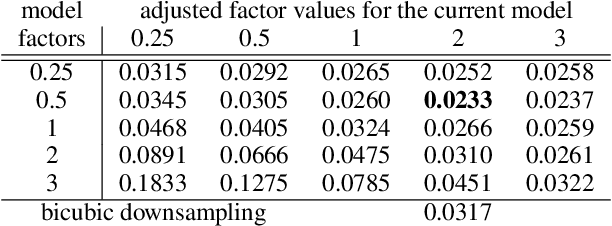
Most single image super-resolution (SR) methods are developed on synthetic low-resolution (LR) and high-resolution (HR) image pairs, which are simulated by a predetermined degradation operation, e.g., bicubic downsampling. However, these methods only learn the inverse process of the predetermined operation, so they fail to super resolve the real-world LR images; the true formulation deviates from the predetermined operation. To address this problem, we propose a novel supervised method to simulate an unknown degradation process with the inclusion of the prior hardware knowledge of the imaging system. We design an adaptive blurring layer (ABL) in the supervised learning framework to estimate the target LR images. The hyperparameters of the ABL can be adjusted for different imaging hardware. The experiments on the real-world datasets validate that our degradation model can estimate LR images more accurately than the predetermined degradation operation, as well as facilitate existing SR methods to perform reconstructions on real-world LR images more accurately than the conventional approaches.
CuDi: Curve Distillation for Efficient and Controllable Exposure Adjustment
Jul 28, 2022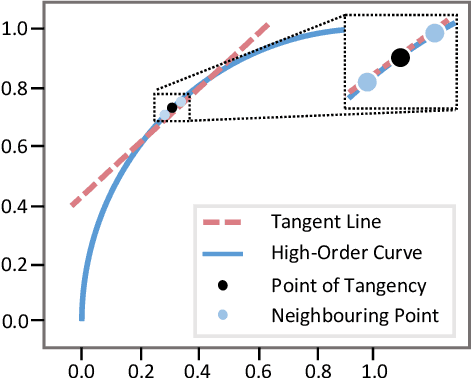


We present Curve Distillation, CuDi, for efficient and controllable exposure adjustment without the requirement of paired or unpaired data during training. Our method inherits the zero-reference learning and curve-based framework from an effective low-light image enhancement method, Zero-DCE, with further speed up in its inference speed, reduction in its model size, and extension to controllable exposure adjustment. The improved inference speed and lightweight model are achieved through novel curve distillation that approximates the time-consuming iterative operation in the conventional curve-based framework by high-order curve's tangent line. The controllable exposure adjustment is made possible with a new self-supervised spatial exposure control loss that constrains the exposure levels of different spatial regions of the output to be close to the brightness distribution of an exposure map serving as an input condition. Different from most existing methods that can only correct either underexposed or overexposed photos, our approach corrects both underexposed and overexposed photos with a single model. Notably, our approach can additionally adjust the exposure levels of a photo globally or locally with the guidance of an input condition exposure map, which can be pre-defined or manually set in the inference stage. Through extensive experiments, we show that our method is appealing for its fast, robust, and flexible performance, outperforming state-of-the-art methods in real scenes. Project page: https://li-chongyi.github.io/CuDi_files/.
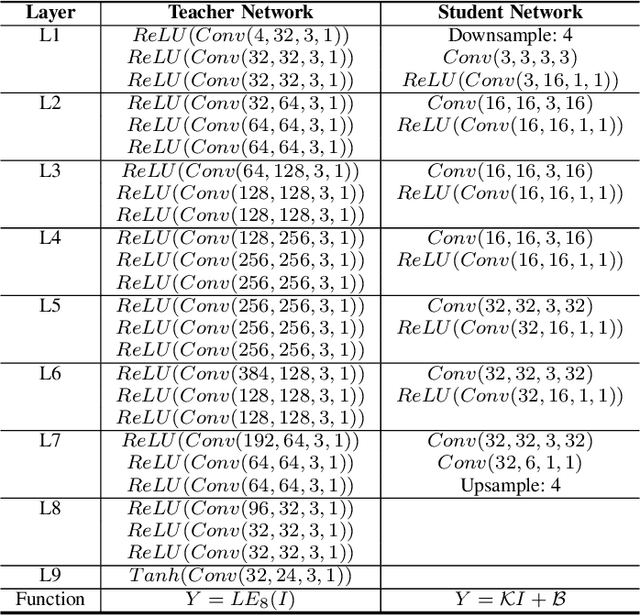
Dual Decomposition of Convex Optimization Layers for Consistent Attention in Medical Images
Jun 07, 2022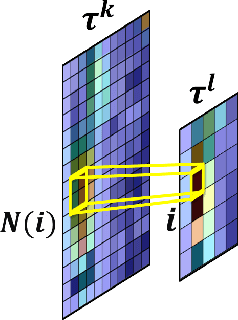
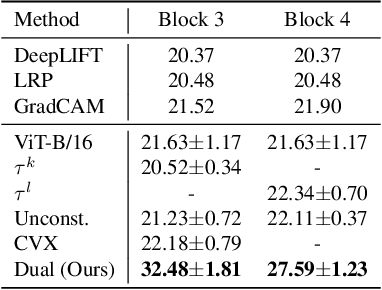
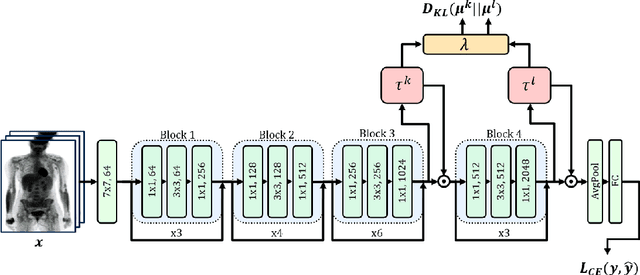
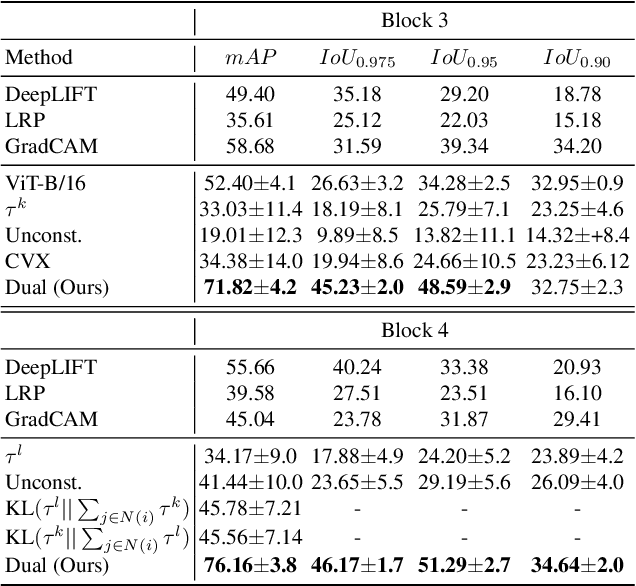
A key concern in integrating machine learning models in medicine is the ability to interpret their reasoning. Popular explainability methods have demonstrated satisfactory results in natural image recognition, yet in medical image analysis, many of these approaches provide partial and noisy explanations. Recently, attention mechanisms have shown compelling results both in their predictive performance and in their interpretable qualities. A fundamental trait of attention is that it leverages salient parts of the input which contribute to the model's prediction. To this end, our work focuses on the explanatory value of attention weight distributions. We propose a multi-layer attention mechanism that enforces consistent interpretations between attended convolutional layers using convex optimization. We apply duality to decompose the consistency constraints between the layers by reparameterizing their attention probability distributions. We further suggest learning the dual witness by optimizing with respect to our objective; thus, our implementation uses standard back-propagation, hence it is highly efficient. While preserving predictive performance, our proposed method leverages weakly annotated medical imaging data and provides complete and faithful explanations to the model's prediction.
Landslide4Sense: Reference Benchmark Data and Deep Learning Models for Landslide Detection
Jun 01, 2022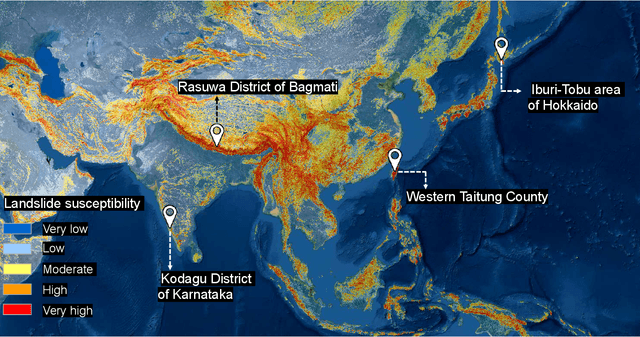
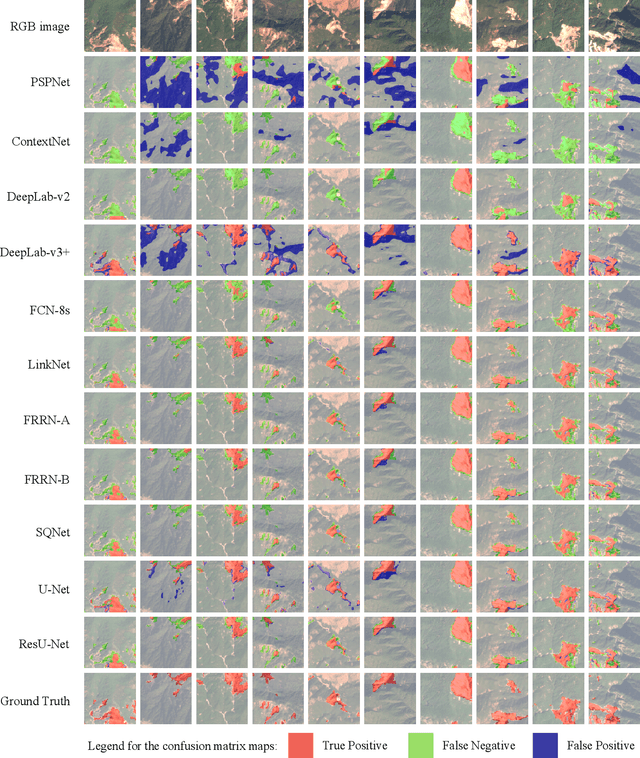
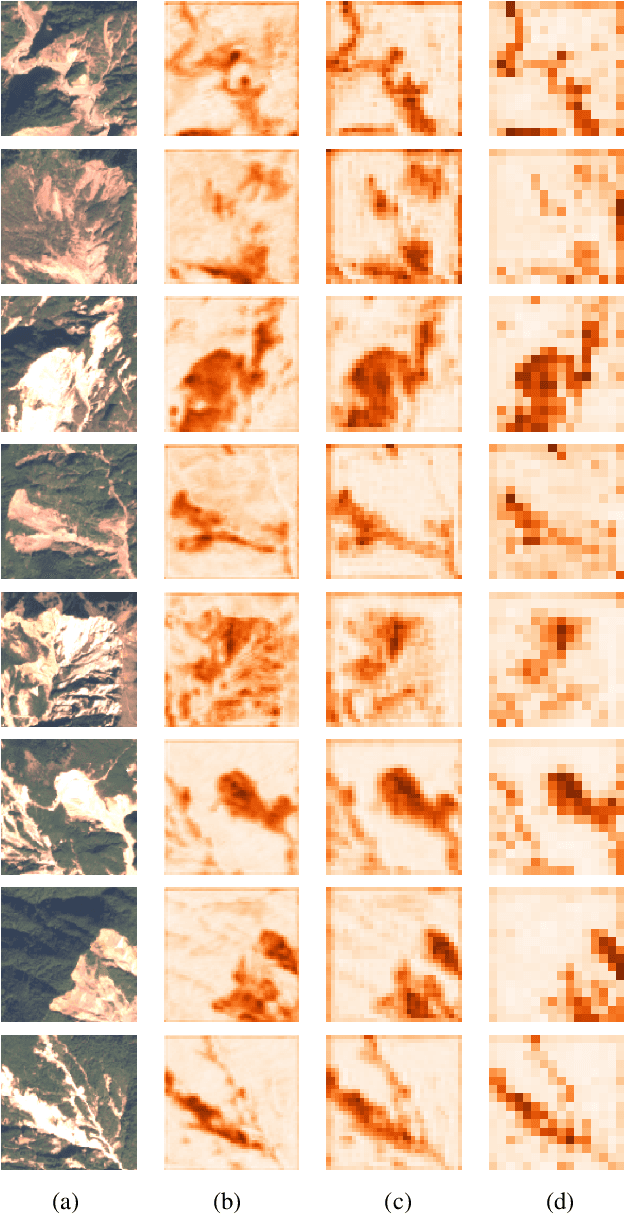
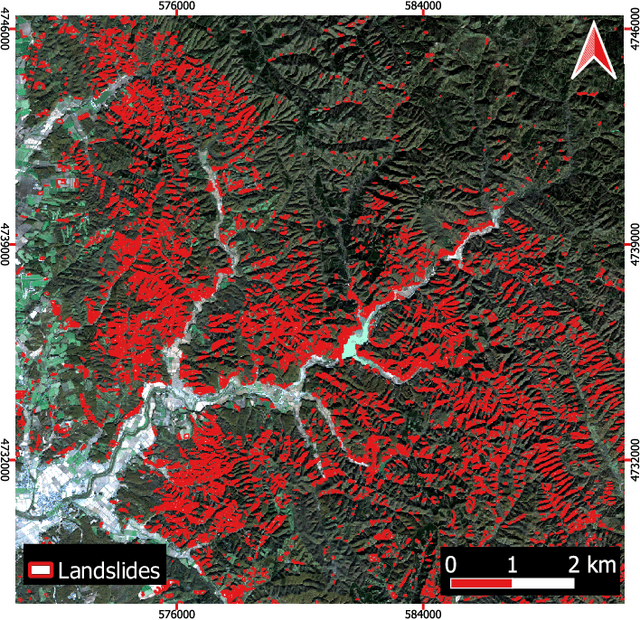
This study introduces \textit{Landslide4Sense}, a reference benchmark for landslide detection from remote sensing. The repository features 3,799 image patches fusing optical layers from Sentinel-2 sensors with the digital elevation model and slope layer derived from ALOS PALSAR. The added topographical information facilitates an accurate detection of landslide borders, which recent researches have shown to be challenging using optical data alone. The extensive data set supports deep learning (DL) studies in landslide detection and the development and validation of methods for the systematic update of landslide inventories. The benchmark data set has been collected at four different times and geographical locations: Iburi (September 2018), Kodagu (August 2018), Gorkha (April 2015), and Taiwan (August 2009). Each image pixel is labelled as belonging to a landslide or not, incorporating various sources and thorough manual annotation. We then evaluate the landslide detection performance of 11 state-of-the-art DL segmentation models: U-Net, ResU-Net, PSPNet, ContextNet, DeepLab-v2, DeepLab-v3+, FCN-8s, LinkNet, FRRN-A, FRRN-B, and SQNet. All models were trained from scratch on patches from one quarter of each study area and tested on independent patches from the other three quarters. Our experiments demonstrate that ResU-Net outperformed the other models for the landslide detection task. We make the multi-source landslide benchmark data (Landslide4Sense) and the tested DL models publicly available at \url{www.landslide4sense.org}, establishing an important resource for remote sensing, computer vision, and machine learning communities in studies of image classification in general and applications to landslide detection in particular.
SdAE: Self-distillated Masked Autoencoder
Jul 31, 2022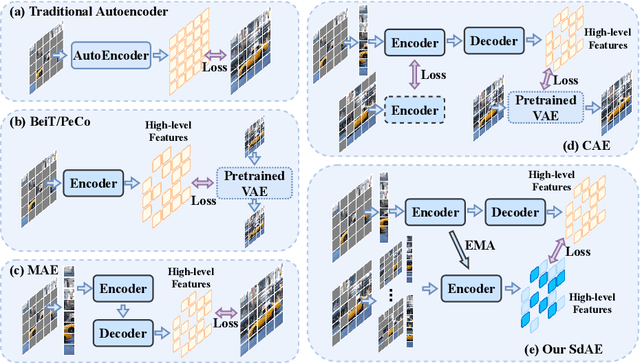

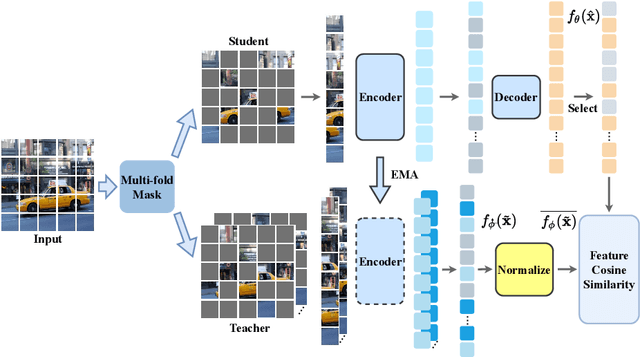
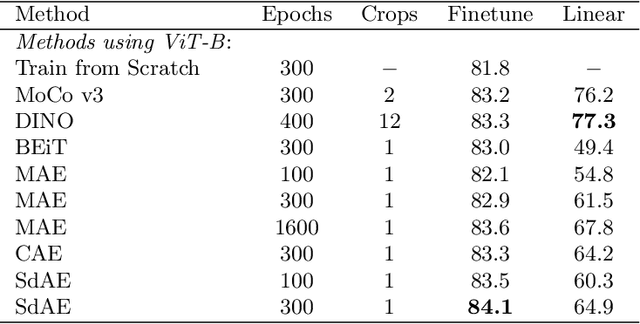
With the development of generative-based self-supervised learning (SSL) approaches like BeiT and MAE, how to learn good representations by masking random patches of the input image and reconstructing the missing information has grown in concern. However, BeiT and PeCo need a "pre-pretraining" stage to produce discrete codebooks for masked patches representing. MAE does not require a pre-training codebook process, but setting pixels as reconstruction targets may introduce an optimization gap between pre-training and downstream tasks that good reconstruction quality may not always lead to the high descriptive capability for the model. Considering the above issues, in this paper, we propose a simple Self-distillated masked AutoEncoder network, namely SdAE. SdAE consists of a student branch using an encoder-decoder structure to reconstruct the missing information, and a teacher branch producing latent representation of masked tokens. We also analyze how to build good views for the teacher branch to produce latent representation from the perspective of information bottleneck. After that, we propose a multi-fold masking strategy to provide multiple masked views with balanced information for boosting the performance, which can also reduce the computational complexity. Our approach generalizes well: with only 300 epochs pre-training, a vanilla ViT-Base model achieves an 84.1% fine-tuning accuracy on ImageNet-1k classification, 48.6 mIOU on ADE20K segmentation, and 48.9 mAP on COCO detection, which surpasses other methods by a considerable margin. Code is available at https://github.com/AbrahamYabo/SdAE.
FedRare: Federated Learning with Intra- and Inter-Client Contrast for Effective Rare Disease Classification
Jun 28, 2022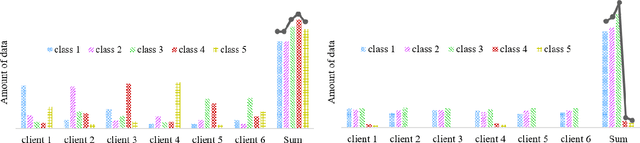
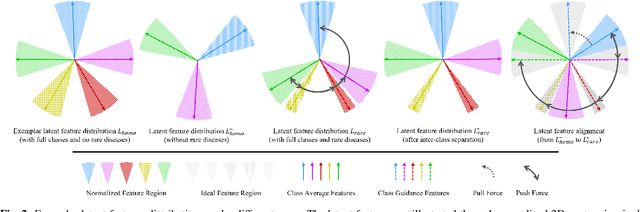
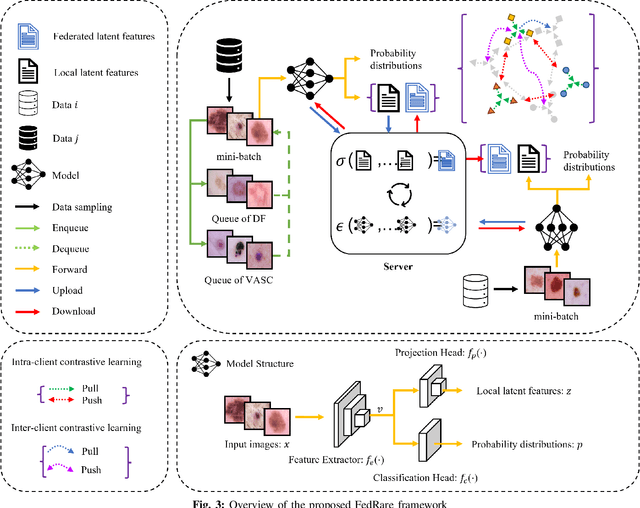
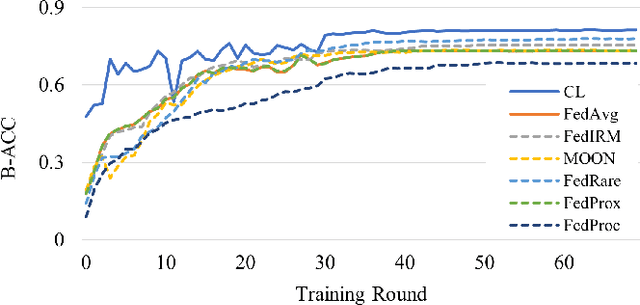
Federated learning (FL), enabling different medical institutions or clients to train a model collaboratively without data privacy leakage, has drawn great attention in medical imaging communities recently. Though inter-client data heterogeneity has been thoroughly studied, the class imbalance problem due to the existence of rare diseases still is under-explored. In this paper, we propose a novel FL framework FedRare for medical image classification especially on dealing with data heterogeneity with the existence of rare diseases. In FedRare, each client trains a model locally to extract highly-separable latent features for classification via intra-client supervised contrastive learning. Considering the limited data on rare diseases, we build positive sample queues for augmentation (i.e. data re-sampling). The server in FedRare would collect the latent features from clients and automatically select the most reliable latent features as guidance sent back to clients. Then, each client is jointly trained by an inter-client contrastive loss to align its latent features to the federated latent features of full classes. In this way, the parameter/feature variances across clients are effectively minimized, leading to better convergence and performance improvements. Experimental results on the publicly-available dataset for skin lesion diagnosis demonstrate FedRare's superior performance. Under the 10-client federated setting where four clients have no rare disease samples, FedRare achieves an average increase of 9.60% and 5.90% in balanced accuracy compared to the baseline framework FedAvg and the state-of-the-art approach FedIRM respectively. Considering the board existence of rare diseases in clinical scenarios, we believe FedRare would benefit future FL framework design for medical image classification. The source code of this paper is publicly available at https://github.com/wnn2000/FedRare.
3D High-Quality Magnetic Resonance Image Restoration in Clinics Using Deep Learning
Nov 28, 2021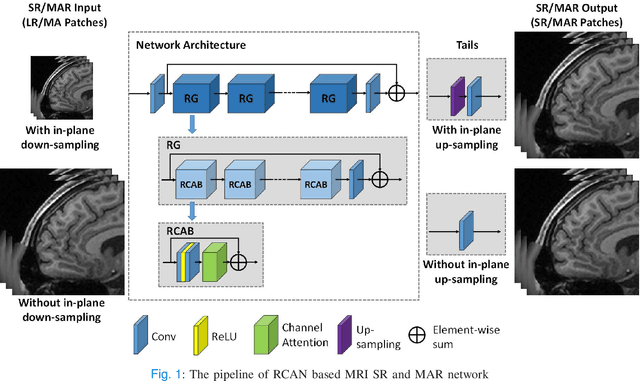
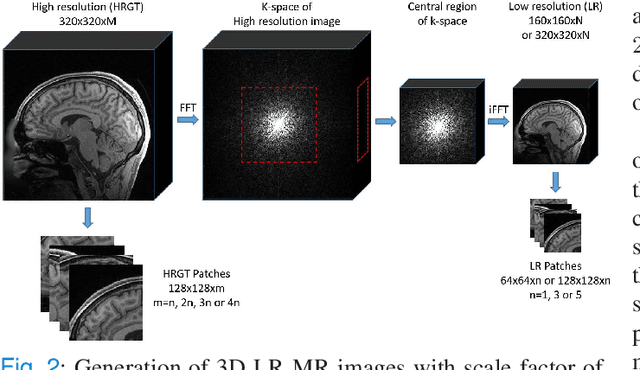
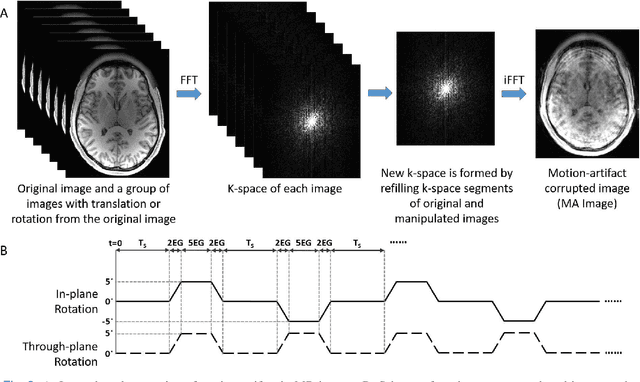

Shortening acquisition time and reducing the motion-artifact are two of the most essential concerns in magnetic resonance imaging. As a promising solution, deep learning-based high quality MR image restoration has been investigated to generate higher resolution and motion artifact-free MR images from lower resolution images acquired with shortened acquisition time, without costing additional acquisition time or modifying the pulse sequences. However, numerous problems still exist to prevent deep learning approaches from becoming practical in the clinic environment. Specifically, most of the prior works focus solely on the network model but ignore the impact of various downsampling strategies on the acquisition time. Besides, the long inference time and high GPU consumption are also the bottle neck to deploy most of the prior works in clinics. Furthermore, prior studies employ random movement in retrospective motion artifact generation, resulting in uncontrollable severity of motion artifact. More importantly, doctors are unsure whether the generated MR images are trustworthy, making diagnosis difficult. To overcome all these problems, we employed a unified 2D deep learning neural network for both 3D MRI super resolution and motion artifact reduction, demonstrating such a framework can achieve better performance in 3D MRI restoration task compared to other states of the art methods and remains the GPU consumption and inference time significantly low, thus easier to deploy. We also analyzed several downsampling strategies based on the acceleration factor, including multiple combinations of in-plane and through-plane downsampling, and developed a controllable and quantifiable motion artifact generation method. At last, the pixel-wise uncertainty was calculated and used to estimate the accuracy of generated image, providing additional information for reliable diagnosis.
Variational AutoEncoder for Reference based Image Super-Resolution
Jun 08, 2021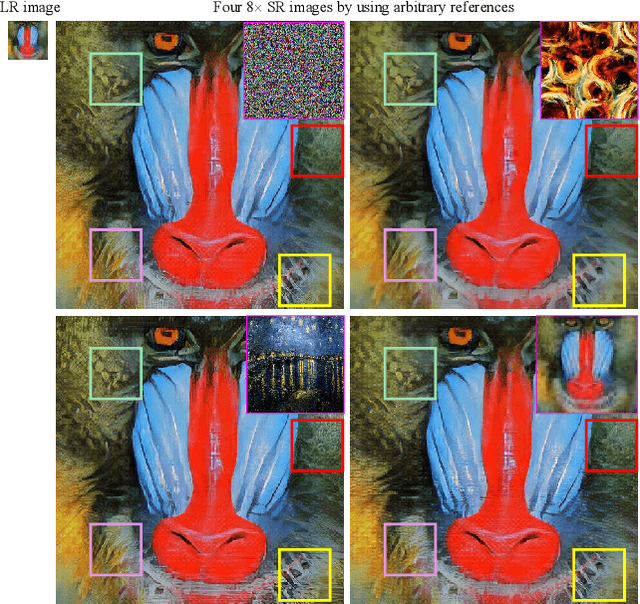

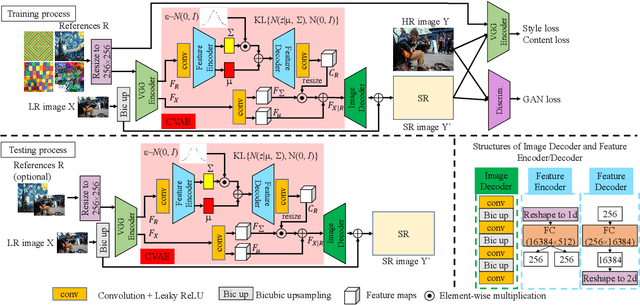
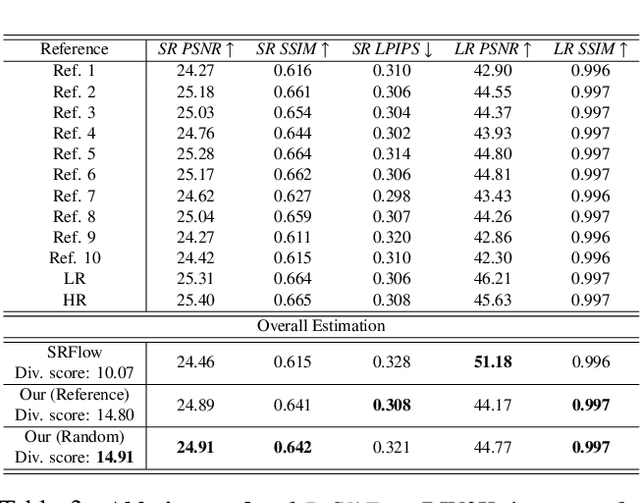
In this paper, we propose a novel reference based image super-resolution approach via Variational AutoEncoder (RefVAE). Existing state-of-the-art methods mainly focus on single image super-resolution which cannot perform well on large upsampling factors, e.g., 8$\times$. We propose a reference based image super-resolution, for which any arbitrary image can act as a reference for super-resolution. Even using random map or low-resolution image itself, the proposed RefVAE can transfer the knowledge from the reference to the super-resolved images. Depending upon different references, the proposed method can generate different versions of super-resolved images from a hidden super-resolution space. Besides using different datasets for some standard evaluations with PSNR and SSIM, we also took part in the NTIRE2021 SR Space challenge and have provided results of the randomness evaluation of our approach. Compared to other state-of-the-art methods, our approach achieves higher diverse scores.
* 10 pages, 6 figures