 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
A Novel Application of Image-to-Image Translation: Chromosome Straightening Framework by Learning from a Single Image
Mar 04, 2021
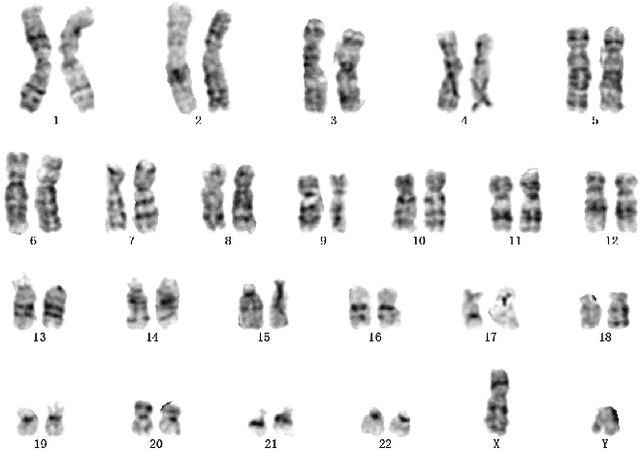

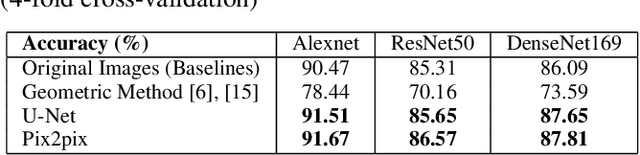
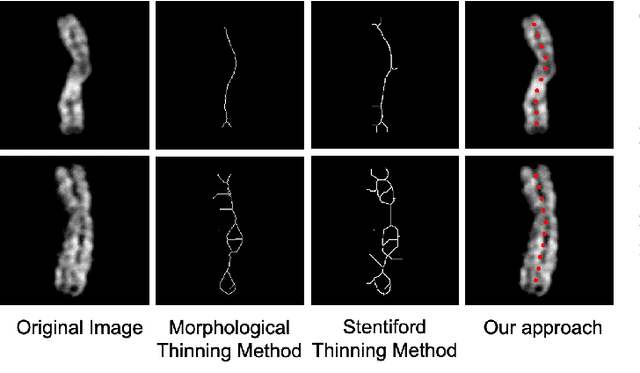
In medical imaging, chromosome straightening plays a significant role in the pathological study of chromosomes and in the development of cytogenetic maps. Whereas different approaches exist for the straightening task, they are mostly geometric algorithms whose outputs are characterized by jagged edges or fragments with discontinued banding patterns. To address the flaws in the geometric algorithms, we propose a novel framework based on image-to-image translation to learn a pertinent mapping dependence for synthesizing straightened chromosomes with uninterrupted banding patterns and preserved details. In addition, to avoid the pitfall of deficient input chromosomes, we construct an augmented dataset using only one single curved chromosome image for training models. Based on this framework, we apply two popular image-to-image translation architectures, U-shape networks and conditional generative adversarial networks, to assess its efficacy. Experiments on a dataset comprising of 642 real-world chromosomes demonstrate the superiority of our framework as compared to the geometric method in straightening performance by rendering realistic and continued chromosome details. Furthermore, our straightened results improve the chromosome classification, achieving 0.98%-1.39% in mean accuracy.
Instance-specific 6-DoF Object Pose Estimation from Minimal Annotations
Jul 27, 2022
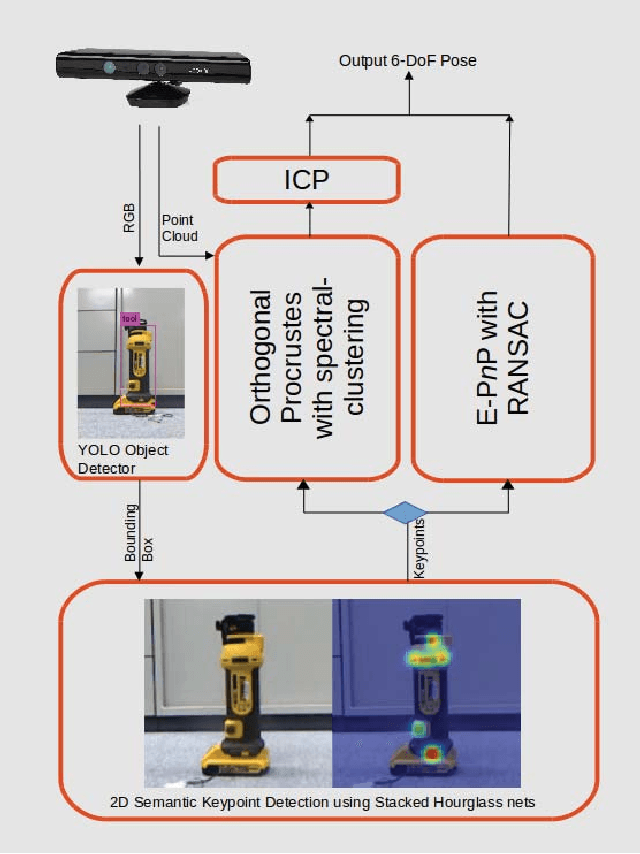
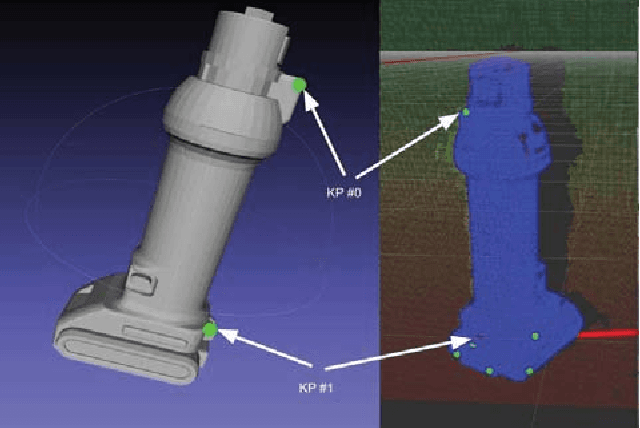
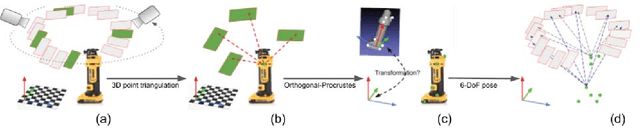
In many robotic applications, the environment setting in which the 6-DoF pose estimation of a known, rigid object and its subsequent grasping is to be performed, remains nearly unchanging and might even be known to the robot in advance. In this paper, we refer to this problem as instance-specific pose estimation: the robot is expected to estimate the pose with a high degree of accuracy in only a limited set of familiar scenarios. Minor changes in the scene, including variations in lighting conditions and background appearance, are acceptable but drastic alterations are not anticipated. To this end, we present a method to rapidly train and deploy a pipeline for estimating the continuous 6-DoF pose of an object from a single RGB image. The key idea is to leverage known camera poses and rigid body geometry to partially automate the generation of a large labeled dataset. The dataset, along with sufficient domain randomization, is then used to supervise the training of deep neural networks for predicting semantic keypoints. Experimentally, we demonstrate the convenience and effectiveness of our proposed method to accurately estimate object pose requiring only a very small amount of manual annotation for training.
* GitHub code: https://github.com/rohanpsingh/ObjectKeypointTrainer
TransferI2I: Transfer Learning for Image-to-Image Translation from Small Datasets
May 13, 2021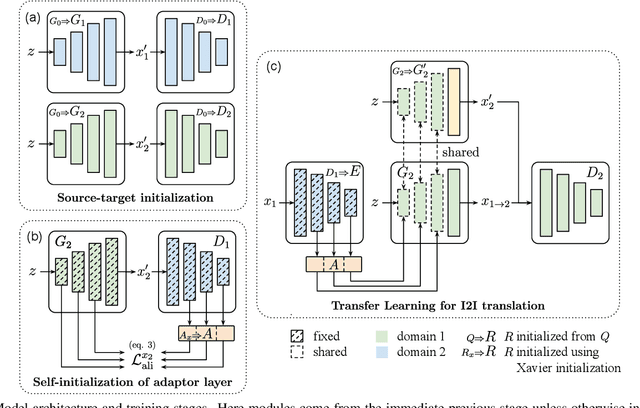
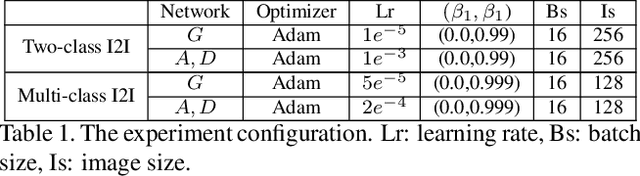
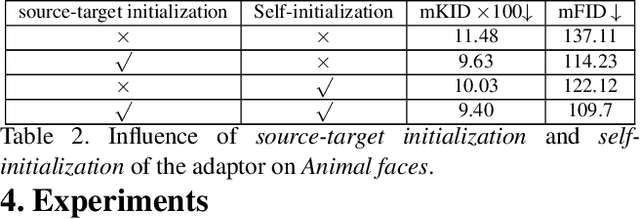
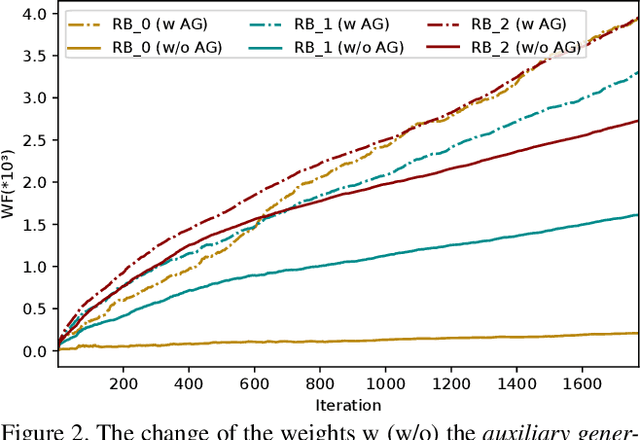
Image-to-image (I2I) translation has matured in recent years and is able to generate high-quality realistic images. However, despite current success, it still faces important challenges when applied to small domains. Existing methods use transfer learning for I2I translation, but they still require the learning of millions of parameters from scratch. This drawback severely limits its application on small domains. In this paper, we propose a new transfer learning for I2I translation (TransferI2I). We decouple our learning process into the image generation step and the I2I translation step. In the first step we propose two novel techniques: source-target initialization and self-initialization of the adaptor layer. The former finetunes the pretrained generative model (e.g., StyleGAN) on source and target data. The latter allows to initialize all non-pretrained network parameters without the need of any data. These techniques provide a better initialization for the I2I translation step. In addition, we introduce an auxiliary GAN that further facilitates the training of deep I2I systems even from small datasets. In extensive experiments on three datasets, (Animal faces, Birds, and Foods), we show that we outperform existing methods and that mFID improves on several datasets with over 25 points.
DeStripe: A Self2Self Spatio-Spectral Graph Neural Network with Unfolded Hessian for Stripe Artifact Removal in Light-sheet Microscopy
Jun 27, 2022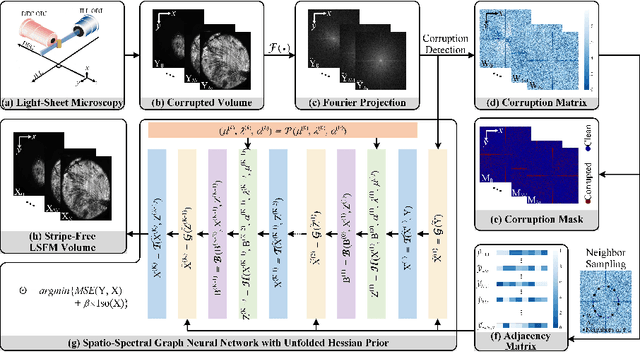
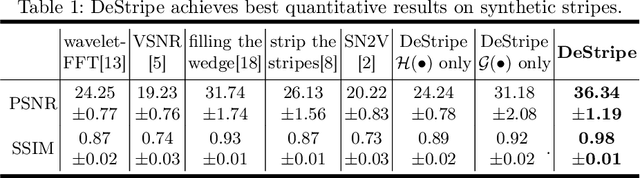

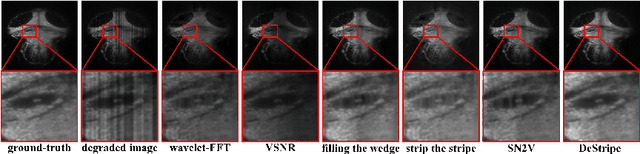
Light-sheet fluorescence microscopy (LSFM) is a cutting-edge volumetric imaging technique that allows for three-dimensional imaging of mesoscopic samples with decoupled illumination and detection paths. Although the selective excitation scheme of such a microscope provides intrinsic optical sectioning that minimizes out-of-focus fluorescence background and sample photodamage, it is prone to light absorption and scattering effects, which results in uneven illumination and striping artifacts in the images adversely. To tackle this issue, in this paper, we propose a blind stripe artifact removal algorithm in LSFM, called DeStripe, which combines a self-supervised spatio-spectral graph neural network with unfolded Hessian prior. Specifically, inspired by the desirable properties of Fourier transform in condensing striping information into isolated values in the frequency domain, DeStripe firstly localizes the potentially corrupted Fourier coefficients by exploiting the structural difference between unidirectional stripe artifacts and more isotropic foreground images. Affected Fourier coefficients can then be fed into a graph neural network for recovery, with a Hessian regularization unrolled to further ensure structures in the standard image space are well preserved. Since in realistic, stripe-free LSFM barely exists with a standard image acquisition protocol, DeStripe is equipped with a Self2Self denoising loss term, enabling artifact elimination without access to stripe-free ground truth images. Competitive experimental results demonstrate the efficacy of DeStripe in recovering corrupted biomarkers in LSFM with both synthetic and real stripe artifacts.
Unsupervised Foggy Scene Understanding via Self Spatial-Temporal Label Diffusion
Jun 10, 2022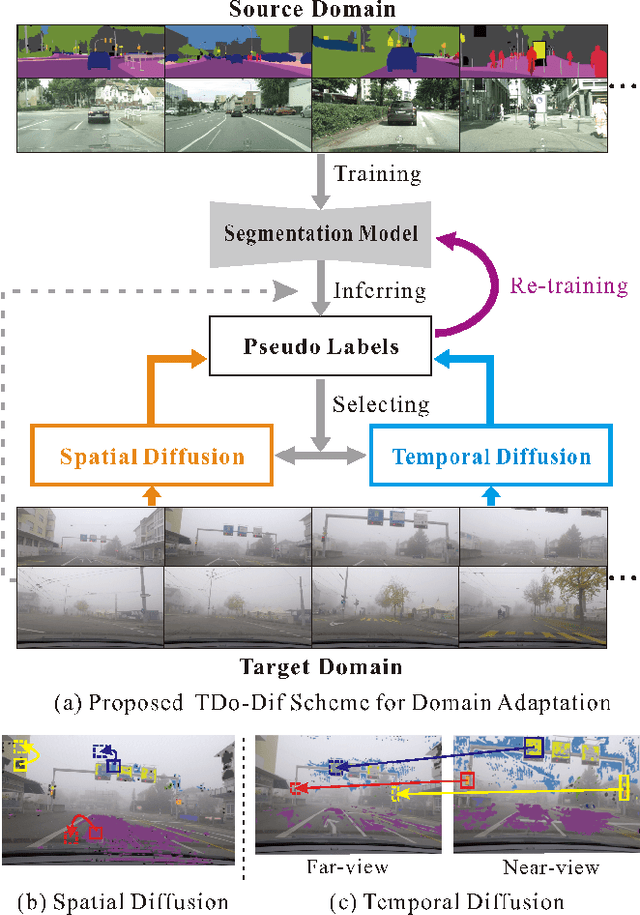
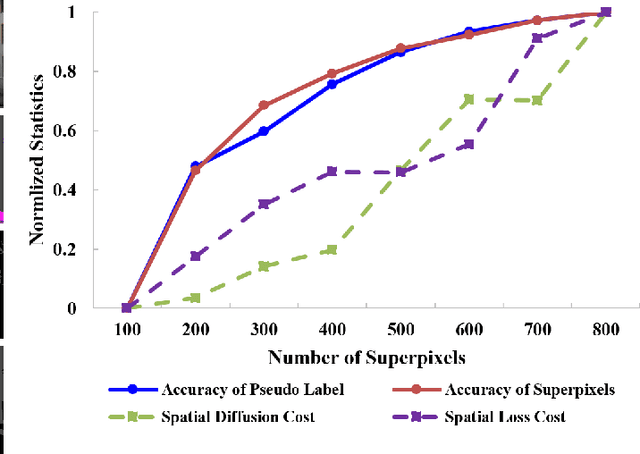
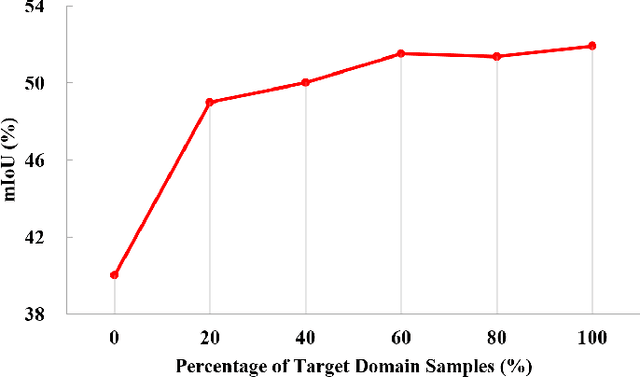
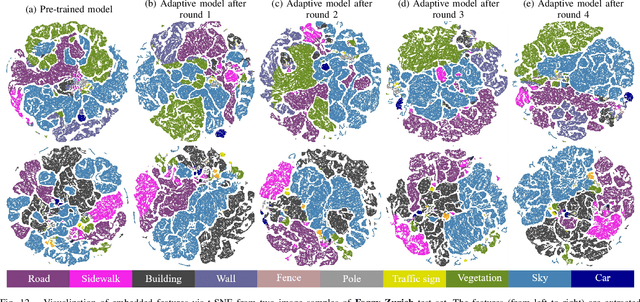
Understanding foggy image sequence in the driving scenes is critical for autonomous driving, but it remains a challenging task due to the difficulty in collecting and annotating real-world images of adverse weather. Recently, the self-training strategy has been considered a powerful solution for unsupervised domain adaptation, which iteratively adapts the model from the source domain to the target domain by generating target pseudo labels and re-training the model. However, the selection of confident pseudo labels inevitably suffers from the conflict between sparsity and accuracy, both of which will lead to suboptimal models. To tackle this problem, we exploit the characteristics of the foggy image sequence of driving scenes to densify the confident pseudo labels. Specifically, based on the two discoveries of local spatial similarity and adjacent temporal correspondence of the sequential image data, we propose a novel Target-Domain driven pseudo label Diffusion (TDo-Dif) scheme. It employs superpixels and optical flows to identify the spatial similarity and temporal correspondence, respectively and then diffuses the confident but sparse pseudo labels within a superpixel or a temporal corresponding pair linked by the flow. Moreover, to ensure the feature similarity of the diffused pixels, we introduce local spatial similarity loss and temporal contrastive loss in the model re-training stage. Experimental results show that our TDo-Dif scheme helps the adaptive model achieve 51.92% and 53.84% mean intersection-over-union (mIoU) on two publicly available natural foggy datasets (Foggy Zurich and Foggy Driving), which exceeds the state-of-the-art unsupervised domain adaptive semantic segmentation methods. Models and data can be found at https://github.com/velor2012/TDo-Dif.
Semantically Accurate Super-Resolution Generative Adversarial Networks
May 17, 2022This work addresses the problems of semantic segmentation and image super-resolution by jointly considering the performance of both in training a Generative Adversarial Network (GAN). We propose a novel architecture and domain-specific feature loss, allowing super-resolution to operate as a pre-processing step to increase the performance of downstream computer vision tasks, specifically semantic segmentation. We demonstrate this approach using Nearmap's aerial imagery dataset which covers hundreds of urban areas at 5-7 cm per pixel resolution. We show the proposed approach improves perceived image quality as well as quantitative segmentation accuracy across all prediction classes, yielding an average accuracy improvement of 11.8% and 108% at 4x and 32x super-resolution, compared with state-of-the art single-network methods. This work demonstrates that jointly considering image-based and task-specific losses can improve the performance of both, and advances the state-of-the-art in semantic-aware super-resolution of aerial imagery.
Generalized MPI Multi-Patch Reconstruction using Clusters of similar System Matrices
May 02, 2022
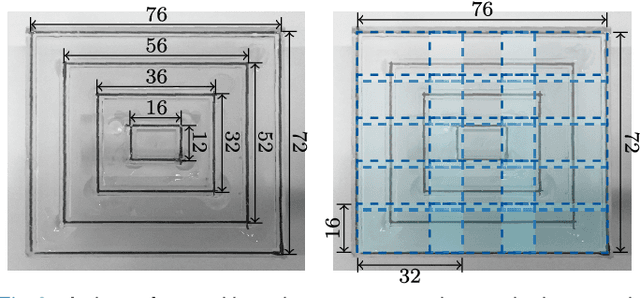
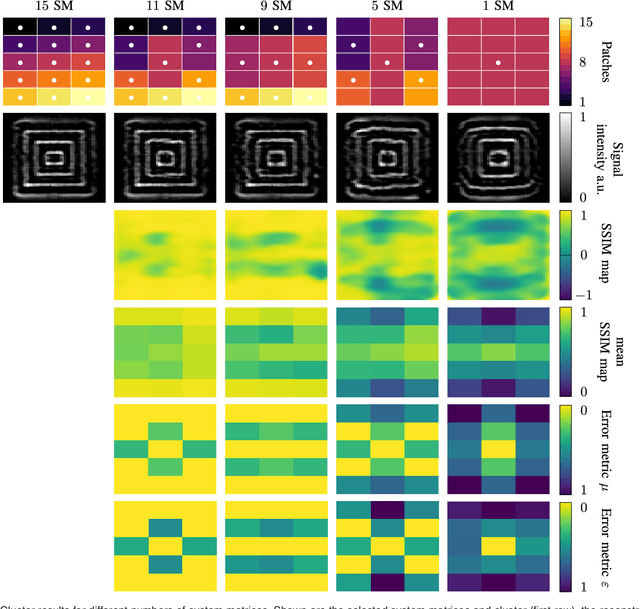
The tomographic imaging method magnetic particle imaging (MPI) requires a multi-patch approach for capturing large field of views. This approach consists of a continuous or stepwise spatial shift of a small sub-volume of only few cubic centimeters size, which is scanned using one or multiple excitation fields in the kHz range. Under the assumption of ideal magnetic fields, the MPI system matrix is shift invariant and in turn a single matrix suffices for image reconstruction significantly reducing the calibration time and reconstruction effort. For large field imperfections, however, the method can lead to severe image artifacts. In the present work we generalize the efficient multi-patch reconstruction to work under non-ideal field conditions, where shift invariance holds only approximately for small shifts of the sub-volume. Patches are clustered based on a magnetic-field-based metric such that in each cluster the shift invariance holds in good approximation. The total number of clusters is the main parameter of our method and allows to trade off calibration time and image artifacts. The magnetic-field-based metric allows to perform the clustering without prior knowledge of the system matrices. The developed reconstruction algorithm is evaluated on a multi-patch measurement sequence with 15 patches, where efficient multi-patch reconstruction with a single calibration measurement leads to strong image artifacts. Analysis reveals that calibration measurements can be decreased from 15 to 11 with no visible image artifacts. A further reduction to 9 is possible with only slight degradation in image quality.
Neural apparent BRDF fields for multiview photometric stereo
Jul 14, 2022
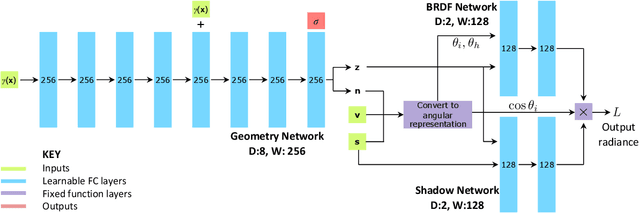


We propose to tackle the multiview photometric stereo problem using an extension of Neural Radiance Fields (NeRFs), conditioned on light source direction. The geometric part of our neural representation predicts surface normal direction, allowing us to reason about local surface reflectance. The appearance part of our neural representation is decomposed into a neural bidirectional reflectance function (BRDF), learnt as part of the fitting process, and a shadow prediction network (conditioned on light source direction) allowing us to model the apparent BRDF. This balance of learnt components with inductive biases based on physical image formation models allows us to extrapolate far from the light source and viewer directions observed during training. We demonstrate our approach on a multiview photometric stereo benchmark and show that competitive performance can be obtained with the neural density representation of a NeRF.
ORFD: A Dataset and Benchmark for Off-Road Freespace Detection
Jun 20, 2022



Freespace detection is an essential component of autonomous driving technology and plays an important role in trajectory planning. In the last decade, deep learning-based free space detection methods have been proved feasible. However, these efforts were focused on urban road environments and few deep learning-based methods were specifically designed for off-road free space detection due to the lack of off-road benchmarks. In this paper, we present the ORFD dataset, which, to our knowledge, is the first off-road free space detection dataset. The dataset was collected in different scenes (woodland, farmland, grassland, and countryside), different weather conditions (sunny, rainy, foggy, and snowy), and different light conditions (bright light, daylight, twilight, darkness), which totally contains 12,198 LiDAR point cloud and RGB image pairs with the traversable area, non-traversable area and unreachable area annotated in detail. We propose a novel network named OFF-Net, which unifies Transformer architecture to aggregate local and global information, to meet the requirement of large receptive fields for free space detection tasks. We also propose the cross-attention to dynamically fuse LiDAR and RGB image information for accurate off-road free space detection. Dataset and code are publicly available athttps://github.com/chaytonmin/OFF-Net.
A semi-automatic ultrasound image analysis system for the grading diagnosis of COVID-19 pneumonia
Nov 04, 2021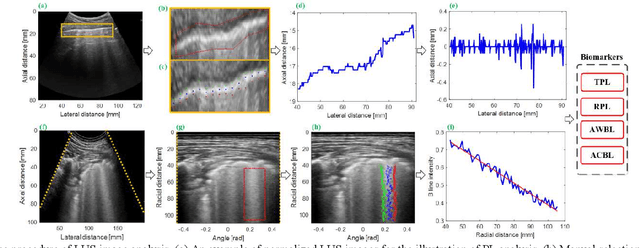
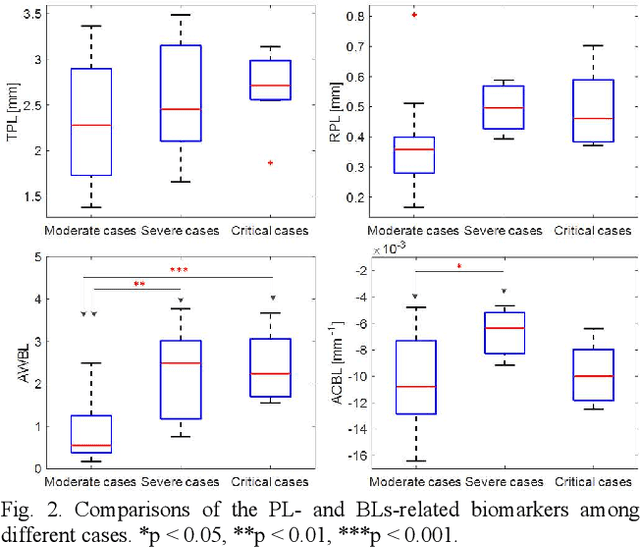
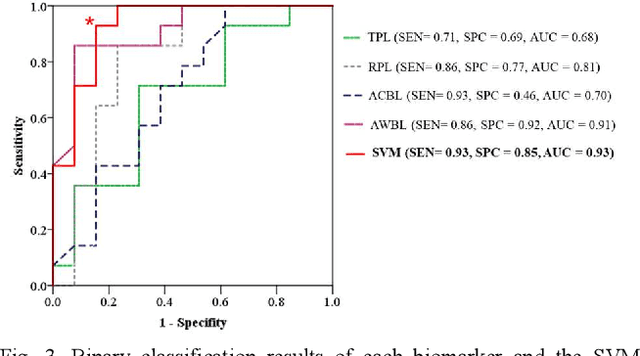
This paper proposes a semi-automatic system based on quantitative characterization of the specific image patterns in lung ultrasound (LUS) images, in order to assess the lung conditions of patients with COVID-19 pneumonia, as well as to differentiate between the severe / and no-severe cases. Specifically, four parameters are extracted from each LUS image, namely the thickness (TPL) and roughness (RPL) of the pleural line, and the accumulated with (AWBL) and acoustic coefficient (ACBL) of B lines. 27 patients are enrolled in this study, which are grouped into 13 moderate patients, 7 severe patients and 7 critical patients. Furthermore, the severe and critical patients are regarded as the severe cases, and the moderate patients are regarded as the non-severe cases. Biomarkers among different groups are compared. Each single biomarker and a classifier with all the biomarkers as input are utilized for the binary diagnosis of severe case and non-severe case, respectively. The classifier achieves the best classification performance among all the compared methods (area under the receiver operating characteristics curve = 0.93, sensitivity = 0.93, specificity = 0.85). The proposed image analysis system could be potentially applied to the grading and prognosis evaluation of patients with COVID-19 pneumonia.