 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
One-Trimap Video Matting
Jul 27, 2022
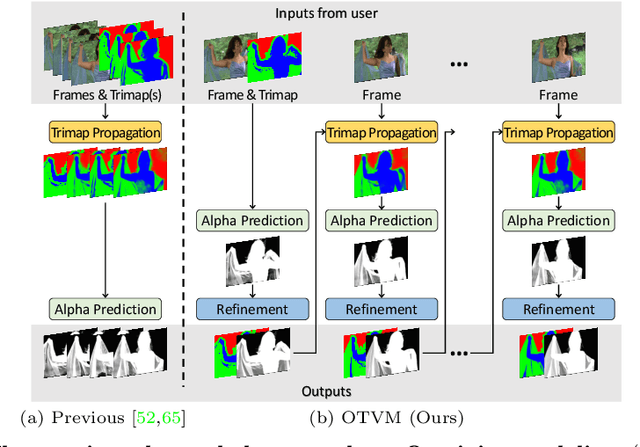
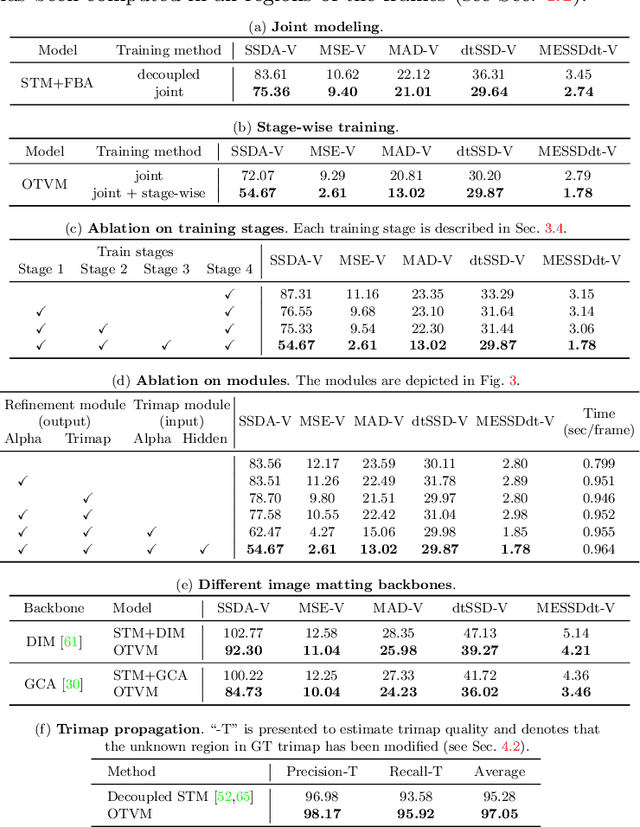
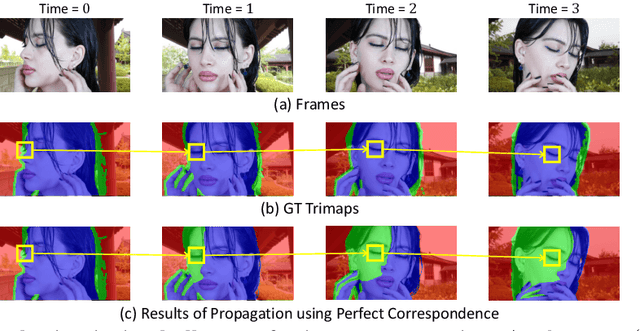
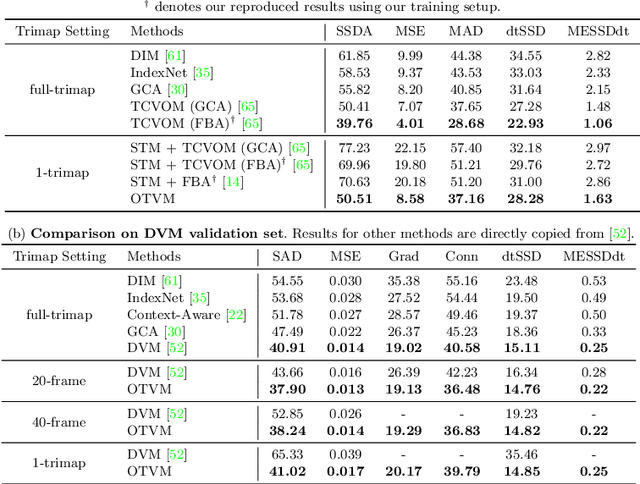
Recent studies made great progress in video matting by extending the success of trimap-based image matting to the video domain. In this paper, we push this task toward a more practical setting and propose One-Trimap Video Matting network (OTVM) that performs video matting robustly using only one user-annotated trimap. A key of OTVM is the joint modeling of trimap propagation and alpha prediction. Starting from baseline trimap propagation and alpha prediction networks, our OTVM combines the two networks with an alpha-trimap refinement module to facilitate information flow. We also present an end-to-end training strategy to take full advantage of the joint model. Our joint modeling greatly improves the temporal stability of trimap propagation compared to the previous decoupled methods. We evaluate our model on two latest video matting benchmarks, Deep Video Matting and VideoMatting108, and outperform state-of-the-art by significant margins (MSE improvements of 56.4% and 56.7%, respectively). The source code and model are available online: https://github.com/Hongje/OTVM.
Edge-preserving Near-light Photometric Stereo with Neural Surfaces
Jul 11, 2022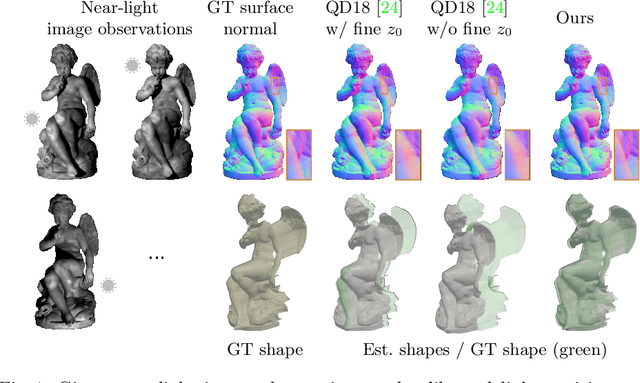
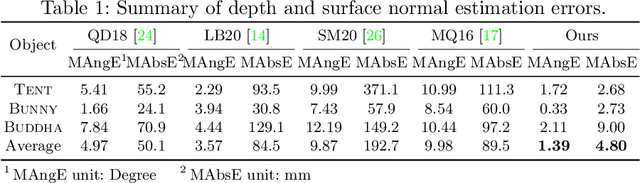
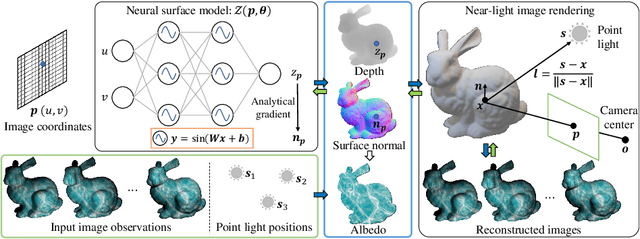
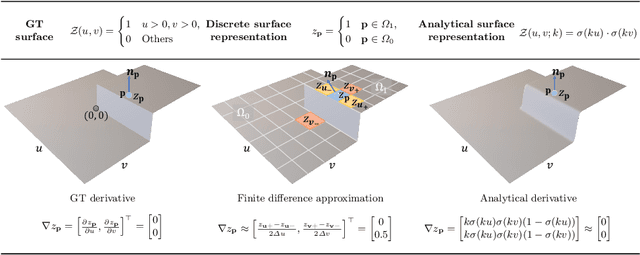
This paper presents a near-light photometric stereo method that faithfully preserves sharp depth edges in the 3D reconstruction. Unlike previous methods that rely on finite differentiation for approximating depth partial derivatives and surface normals, we introduce an analytically differentiable neural surface in near-light photometric stereo for avoiding differentiation errors at sharp depth edges, where the depth is represented as a neural function of the image coordinates. By further formulating the Lambertian albedo as a dependent variable resulting from the surface normal and depth, our method is insusceptible to inaccurate depth initialization. Experiments on both synthetic and real-world scenes demonstrate the effectiveness of our method for detailed shape recovery with edge preservation.
An Efficient Dual-reference Training Data Acquisition Method for CNN Image Super-Resolution
Aug 24, 2021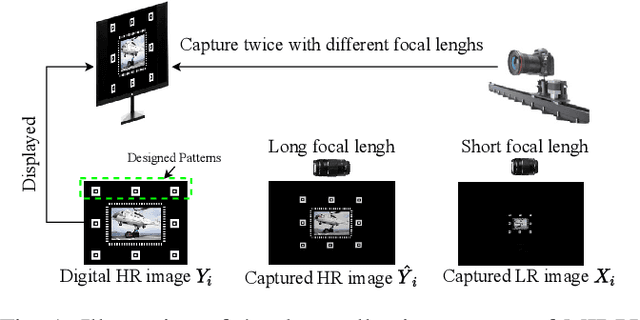



For deep learning methods of image super-resolution, the most critical issue is whether the paired low and high resolution images for training accurately reflect the sampling process of real cameras. Low and high resolution (LR$\sim$HR) image pairs synthesized by existing degradation models (e.g. bicubic downsampling) deviate from those in reality; thus the super-resolution CNN trained by these synthesized LR$\sim$HR image pairs does not perform well when being applied to real images. In this paper, we propose a novel method to capture a large set of realistic LR$\sim$HR image pairs using real cameras. The data acquisition is carried out under controllable lab conditions with minimum human intervention and at high throughput (about 500 image pairs per hour). The high level of automation makes it easy to produce a set of real LR$\sim$HR training image pairs for each camera.Our innovation is to shoot images displayed on an ultra-high quality screen at different resolutions. There are three distinctive advantages of our method for image super-resolution. First, as the LR and HR images are taken of a 3D planar surface (the screen) the registration problem fits exactly to a homography model and we can display specially designed markers on the image to improve the registration precision. Second, the displayed digital image file can be exploited as a reference to optimize the high frequency content of the restored image. Third, this high-efficiency data collection method makes it possible to collect a customized dataset for each camera sensor, for which one can train a specific model for the intended camera sensor. Experimental results show that training a super-resolution CNN by our LR$\sim$HR dataset has superior restoration performance than training it by existing datasets on real world images at the inference stage.
Evaluating Transformer based Semantic Segmentation Networks for Pathological Image Segmentation
Aug 26, 2021
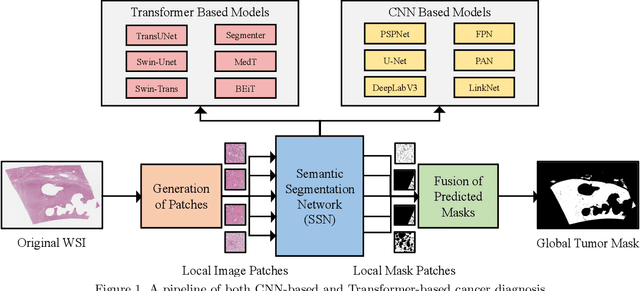
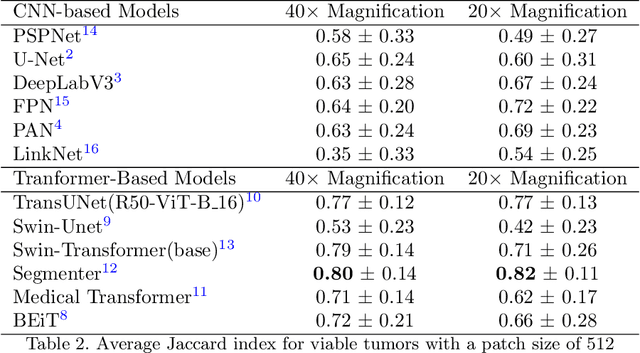
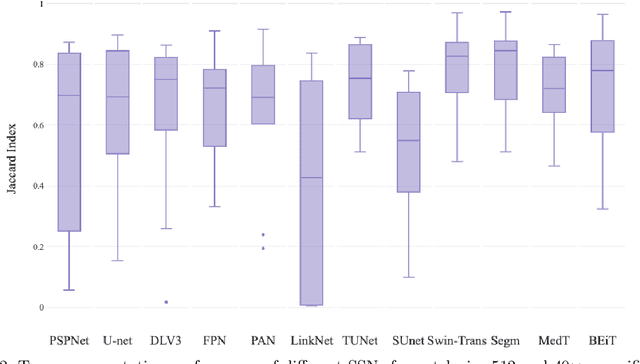
Histopathology has played an essential role in cancer diagnosis. With the rapid advances in convolutional neural networks (CNN). Various CNN-based automated pathological image segmentation approaches have been developed in computer-assisted pathological image analysis. In the past few years, Transformer neural networks (Transformer) have shown the unique merit of capturing the global long distance dependencies across the entire image as a new deep learning paradigm. Such merit is appealing for exploring spatially heterogeneous pathological images. However, there have been very few, if any, studies that have systematically evaluated the current Transformer based approaches in pathological image segmentation. To assess the performance of Transformer segmentation models on whole slide images (WSI), we quantitatively evaluated six prevalent transformer-based models on tumor segmentation, using the widely used PAIP liver histopathological dataset. For a more comprehensive analysis, we also compare the transformer-based models with six major traditional CNN-based models. The results show that the Transformer-based models exhibit a general superior performance over the CNN-based models. In particular, Segmenter, Swin-Transformer and TransUNet, all transformer-based, came out as the best performers among the twelve evaluated models.
Probing Image-Language Transformers for Verb Understanding
Jun 16, 2021
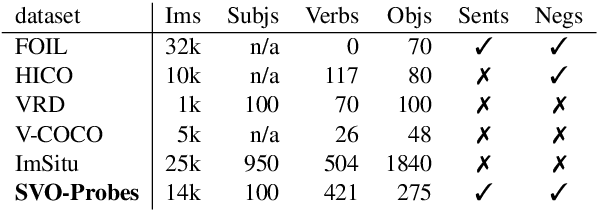

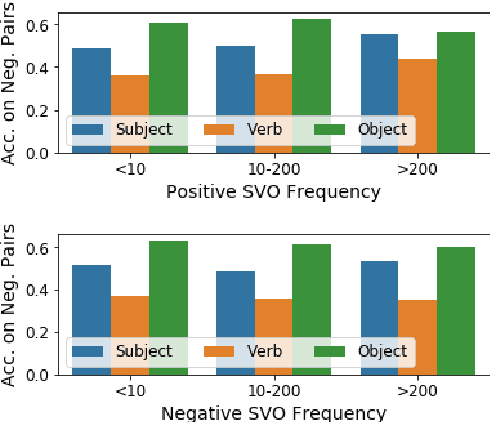
Multimodal image-language transformers have achieved impressive results on a variety of tasks that rely on fine-tuning (e.g., visual question answering and image retrieval). We are interested in shedding light on the quality of their pretrained representations -- in particular, if these models can distinguish different types of verbs or if they rely solely on nouns in a given sentence. To do so, we collect a dataset of image-sentence pairs (in English) consisting of 421 verbs that are either visual or commonly found in the pretraining data (i.e., the Conceptual Captions dataset). We use this dataset to evaluate pretrained image-language transformers and find that they fail more in situations that require verb understanding compared to other parts of speech. We also investigate what category of verbs are particularly challenging.
Field Distortion Model Based on Fredholm Integral
May 18, 2022
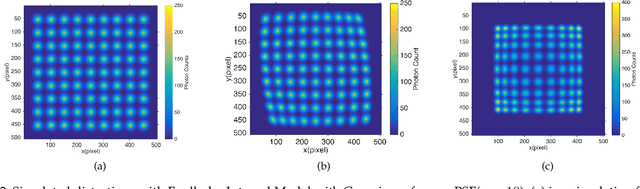

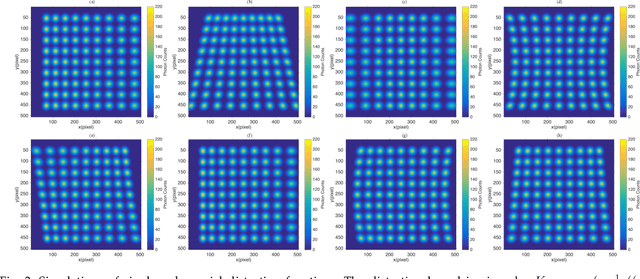
Field distortion is widespread in imaging systems. If it cannot be measured and corrected well, it will affect the accuracy of photogrammetry. To this end, we proposed a general field distortion model based on Fredholm integration, which uses a reconstructed high-resolution reference point spread function (PSF) and two sets of 4-variable polynomials to describe an imaging system. The model includes the point-to-point positional distortion from the object space to the image space and the deformation of the PSF so that we can measure an actual field distortion with arbitrary accuracy. We also derived the formula required for correcting the sampling effect of the image sensor. Through numerical simulation, we verify the effectiveness of the model and reconstruction algorithm. This model will have potential application in high-precision image calibration, photogrammetry and astrometry.
Leveraging Smartphone Sensors for Detecting Abnormal Gait for Smart Wearable Mobile Technologies
Aug 03, 2022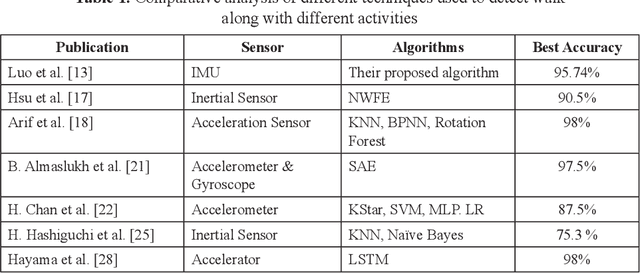
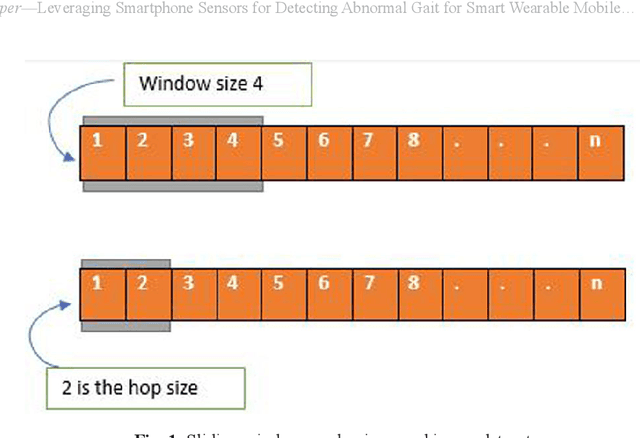
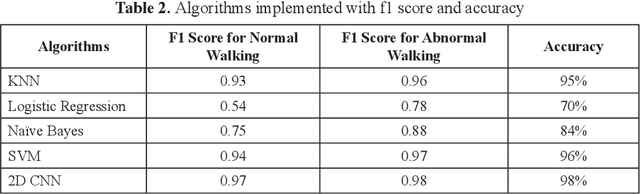
Walking is one of the most common modes of terrestrial locomotion for humans. Walking is essential for humans to perform most kinds of daily activities. When a person walks, there is a pattern in it, and it is known as gait. Gait analysis is used in sports and healthcare. We can analyze this gait in different ways, like using video captured by the surveillance cameras or depth image cameras in the lab environment. It also can be recognized by wearable sensors. e.g., accelerometer, force sensors, gyroscope, flexible goniometer, magneto resistive sensors, electromagnetic tracking system, force sensors, and electromyography (EMG). Analysis through these sensors required a lab condition, or users must wear these sensors. For detecting abnormality in gait action of a human, we need to incorporate the sensors separately. We can know about one's health condition by abnormal human gait after detecting it. Understanding a regular gait vs. abnormal gait may give insights to the health condition of the subject using the smart wearable technologies. Therefore, in this paper, we proposed a way to analyze abnormal human gait through smartphone sensors. Though smart devices like smartphones and smartwatches are used by most of the person nowadays. So, we can track down their gait using sensors of these intelligent wearable devices.
Mirror Complementary Transformer Network for RGB-thermal Salient Object Detection
Jul 07, 2022
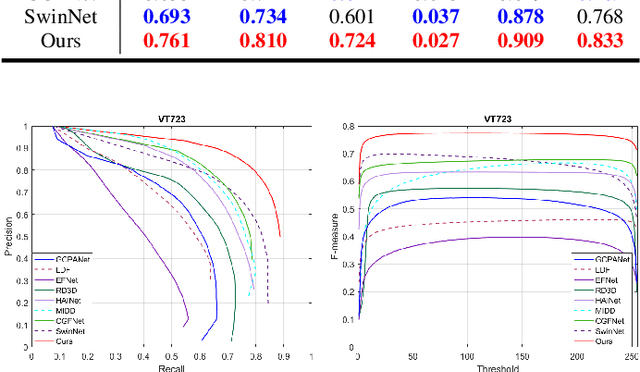
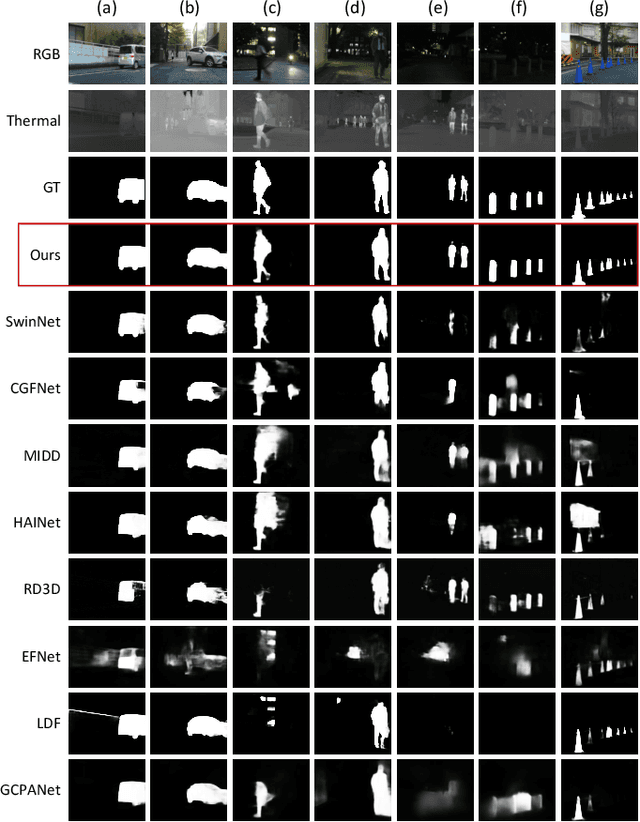

RGB-thermal salient object detection (RGB-T SOD) aims to locate the common prominent objects of an aligned visible and thermal infrared image pair and accurately segment all the pixels belonging to those objects. It is promising in challenging scenes such as nighttime and complex backgrounds due to the insensitivity to lighting conditions of thermal images. Thus, the key problem of RGB-T SOD is to make the features from the two modalities complement and adjust each other flexibly, since it is inevitable that any modalities of RGB-T image pairs failure due to challenging scenes such as extreme light conditions and thermal crossover. In this paper, we propose a novel mirror complementary Transformer network (MCNet) for RGB-T SOD. Specifically, we introduce a Transformer-based feature extraction module to effective extract hierarchical features of RGB and thermal images. Then, through the attention-based feature interaction and serial multiscale dilated convolution (SDC) based feature fusion modules, the proposed model achieves the complementary interaction of low-level features and the semantic fusion of deep features. Finally, based on the mirror complementary structure, the salient regions of the two modalities can be accurately extracted even one modality is invalid. To demonstrate the robustness of the proposed model under challenging scenes in real world, we build a novel RGB-T SOD dataset VT723 based on a large public semantic segmentation RGB-T dataset used in the autonomous driving domain. Expensive experiments on benchmark and VT723 datasets show that the proposed method outperforms state-of-the-art approaches, including CNN-based and Transformer-based methods. The code and dataset will be released later at https://github.com/jxr326/SwinMCNet.
Robustifying Vision Transformer without Retraining from Scratch by Test-Time Class-Conditional Feature Alignment
Jun 28, 2022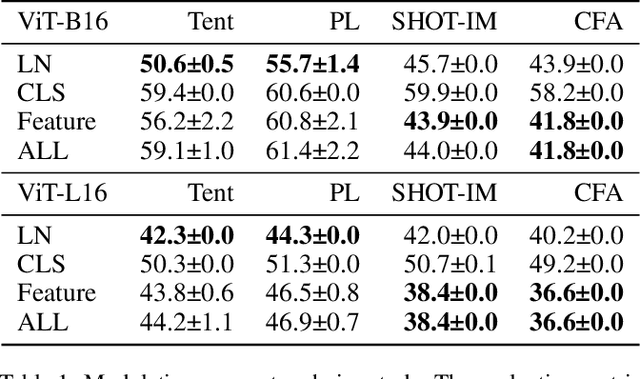
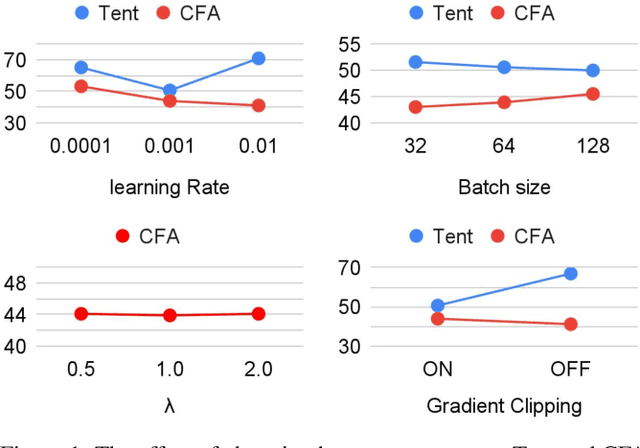
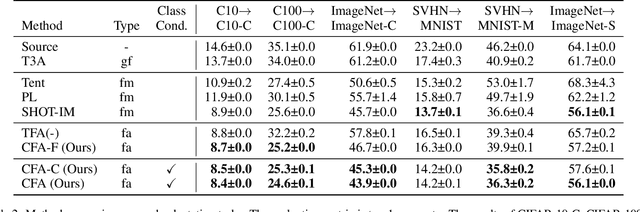

Vision Transformer (ViT) is becoming more popular in image processing. Specifically, we investigate the effectiveness of test-time adaptation (TTA) on ViT, a technique that has emerged to correct its prediction during test-time by itself. First, we benchmark various test-time adaptation approaches on ViT-B16 and ViT-L16. It is shown that the TTA is effective on ViT and the prior-convention (sensibly selecting modulation parameters) is not necessary when using proper loss function. Based on the observation, we propose a new test-time adaptation method called class-conditional feature alignment (CFA), which minimizes both the class-conditional distribution differences and the whole distribution differences of the hidden representation between the source and target in an online manner. Experiments of image classification tasks on common corruption (CIFAR-10-C, CIFAR-100-C, and ImageNet-C) and domain adaptation (digits datasets and ImageNet-Sketch) show that CFA stably outperforms the existing baselines on various datasets. We also verify that CFA is model agnostic by experimenting on ResNet, MLP-Mixer, and several ViT variants (ViT-AugReg, DeiT, and BeiT). Using BeiT backbone, CFA achieves 19.8% top-1 error rate on ImageNet-C, outperforming the existing test-time adaptation baseline 44.0%. This is a state-of-the-art result among TTA methods that do not need to alter training phase.
EMDS-7: Environmental Microorganism Image Dataset Seventh Version for Multiple Object Detection Evaluation
Oct 28, 2021
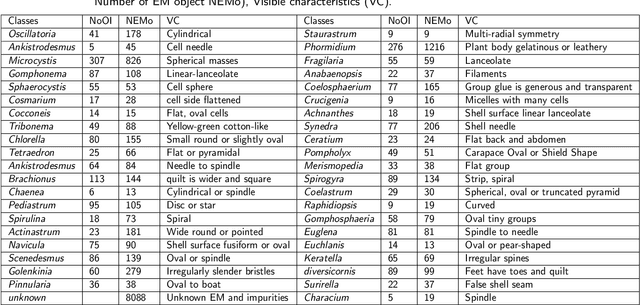

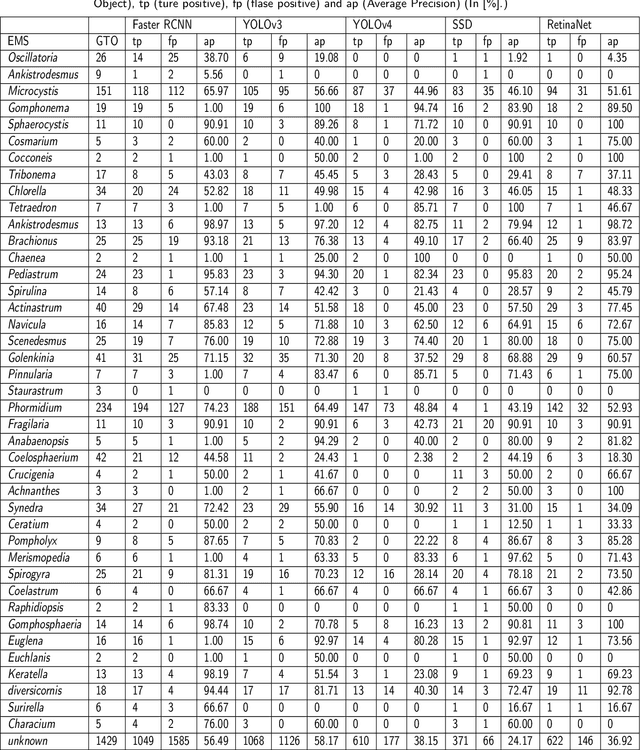
The Environmental Microorganism Image Dataset Seventh Version (EMDS-7) is a microscopic image data set, including the original Environmental Microorganism images (EMs) and the corresponding object labeling files in ".XML" format file. The EMDS-7 data set consists of 41 types of EMs, which has a total of 2365 images and 13216 labeled objects. The EMDS-7 database mainly focuses on the object detection. In order to prove the effectiveness of EMDS-7, we select the most commonly used deep learning methods (Faster-RCNN, YOLOv3, YOLOv4, SSD and RetinaNet) and evaluation indices for testing and evaluation. EMDS-7 is freely published for non-commercial purpose at: https://figshare.com/articles/dataset/EMDS-7_DataSet/16869571