 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Learning to See Through Dazzle
Mar 04, 2024
Machine vision is susceptible to laser dazzle, where intense laser light can blind and distort its perception of the environment through oversaturation or permanent damage to sensor pixels. Here we employ a wavefront-coded phase mask to diffuse the energy of laser light and introduce a sandwich generative adversarial network (SGAN) to restore images from complex image degradations, such as varying laser-induced image saturation, mask-induced image blurring, unknown lighting conditions, and various noise corruptions. The SGAN architecture combines discriminative and generative methods by wrapping two GANs around a learnable image deconvolution module. In addition, we make use of Fourier feature representations to reduce the spectral bias of neural networks and improve its learning of high-frequency image details. End-to-end training includes the realistic physics-based synthesis of a large set of training data from publicly available images. We trained the SGAN to suppress the peak laser irradiance as high as $10^6$ times the sensor saturation threshold - the point at which camera sensors may experience damage without the mask. The trained model was evaluated on both a synthetic data set and data collected from the laboratory. The proposed image restoration model quantitatively and qualitatively outperforms state-of-the-art methods for a wide range of scene contents, laser powers, incident laser angles, ambient illumination strengths, and noise characteristics.
Medical Image Segmentation with InTEnt: Integrated Entropy Weighting for Single Image Test-Time Adaptation
Feb 16, 2024Test-time adaptation (TTA) refers to adapting a trained model to a new domain during testing. Existing TTA techniques rely on having multiple test images from the same domain, yet this may be impractical in real-world applications such as medical imaging, where data acquisition is expensive and imaging conditions vary frequently. Here, we approach such a task, of adapting a medical image segmentation model with only a single unlabeled test image. Most TTA approaches, which directly minimize the entropy of predictions, fail to improve performance significantly in this setting, in which we also observe the choice of batch normalization (BN) layer statistics to be a highly important yet unstable factor due to only having a single test domain example. To overcome this, we propose to instead integrate over predictions made with various estimates of target domain statistics between the training and test statistics, weighted based on their entropy statistics. Our method, validated on 24 source/target domain splits across 3 medical image datasets surpasses the leading method by 2.9% Dice coefficient on average.
Distinctive Image Captioning: Leveraging Ground Truth Captions in CLIP Guided Reinforcement Learning
Feb 21, 2024Training image captioning models using teacher forcing results in very generic samples, whereas more distinctive captions can be very useful in retrieval applications or to produce alternative texts describing images for accessibility. Reinforcement Learning (RL) allows to use cross-modal retrieval similarity score between the generated caption and the input image as reward to guide the training, leading to more distinctive captions. Recent studies show that pre-trained cross-modal retrieval models can be used to provide this reward, completely eliminating the need for reference captions. However, we argue in this paper that Ground Truth (GT) captions can still be useful in this RL framework. We propose a new image captioning model training strategy that makes use of GT captions in different ways. Firstly, they can be used to train a simple MLP discriminator that serves as a regularization to prevent reward hacking and ensures the fluency of generated captions, resulting in a textual GAN setup extended for multimodal inputs. Secondly, they can serve as additional trajectories in the RL strategy, resulting in a teacher forcing loss weighted by the similarity of the GT to the image. This objective acts as an additional learning signal grounded to the distribution of the GT captions. Thirdly, they can serve as strong baselines when added to the pool of captions used to compute the proposed contrastive reward to reduce the variance of gradient estimate. Experiments on MS-COCO demonstrate the interest of the proposed training strategy to produce highly distinctive captions while maintaining high writing quality.
A Deep Learning Method for Classification of Biophilic Artworks
Mar 08, 2024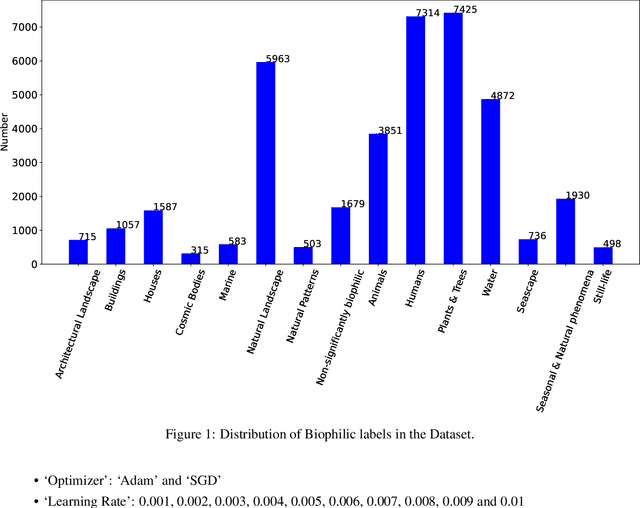
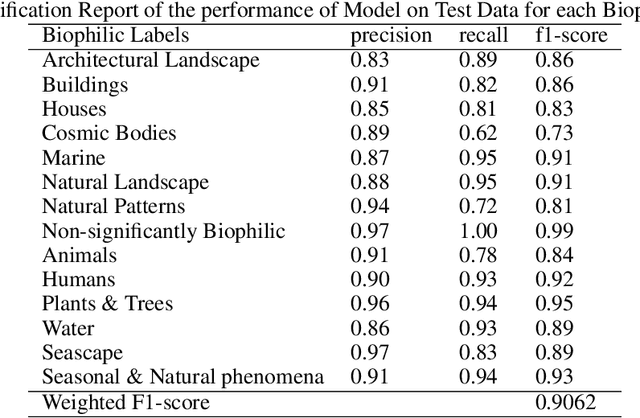
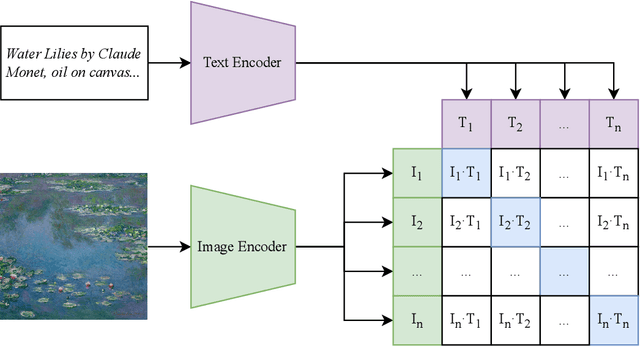
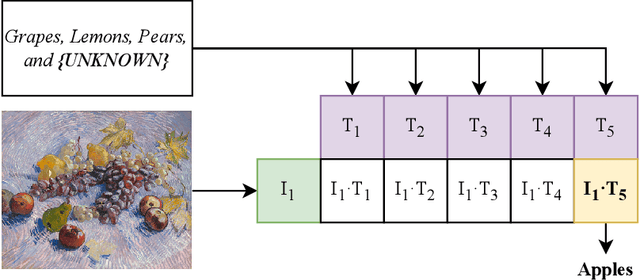
Biophilia is an innate love for living things and nature itself that has been associated with a positive impact on mental health and well-being. This study explores the application of deep learning methods for the classification of Biophilic artwork, in order to learn and explain the different Biophilic characteristics present in a visual representation of a painting. Using the concept of Biophilia that postulates the deep connection of human beings with nature, we use an artificially intelligent algorithm to recognise the different patterns underlying the Biophilic features in an artwork. Our proposed method uses a lower-dimensional representation of an image and a decoder model to extract salient features of the image of each Biophilic trait, such as plants, water bodies, seasons, animals, etc., based on learnt factors such as shape, texture, and illumination. The proposed classification model is capable of extracting Biophilic artwork that not only helps artists, collectors, and researchers studying to interpret and exploit the effects of mental well-being on exposure to nature-inspired visual aesthetics but also enables a methodical exploration of the study of Biophilia and Biophilic artwork for aesthetic preferences. Using the proposed algorithms, we have also created a gallery of Biophilic collections comprising famous artworks from different European and American art galleries, which will soon be published on the Vieunite@ online community.
FocusCLIP: Multimodal Subject-Level Guidance for Zero-Shot Transfer in Human-Centric Tasks
Mar 11, 2024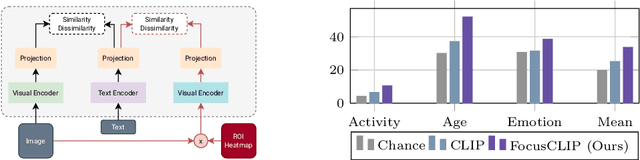
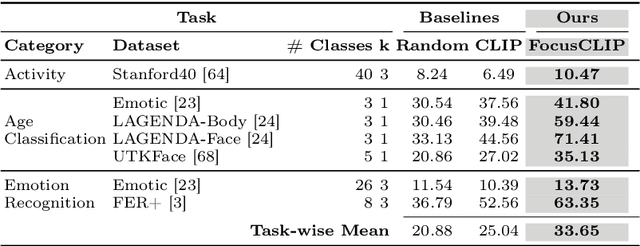
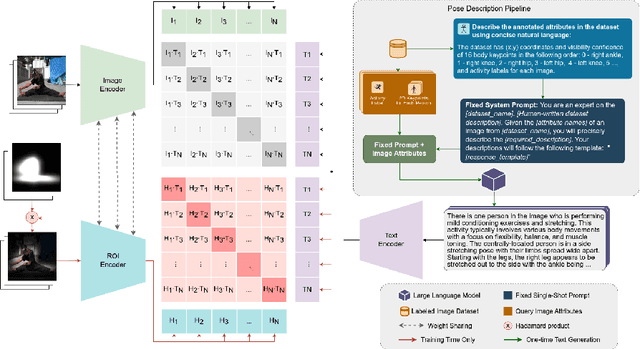
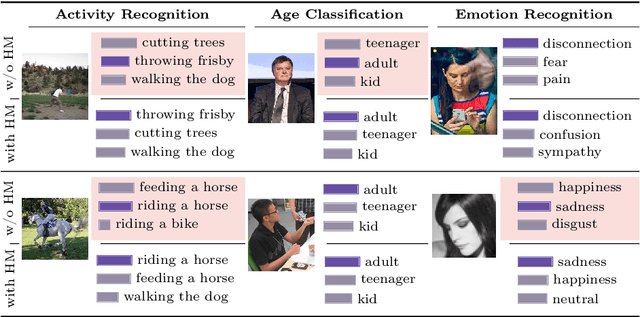
We propose FocusCLIP, integrating subject-level guidance--a specialized mechanism for target-specific supervision--into the CLIP framework for improved zero-shot transfer on human-centric tasks. Our novel contributions enhance CLIP on both the vision and text sides. On the vision side, we incorporate ROI heatmaps emulating human visual attention mechanisms to emphasize subject-relevant image regions. On the text side, we introduce human pose descriptions to provide rich contextual information. For human-centric tasks, FocusCLIP is trained with images from the MPII Human Pose dataset. The proposed approach surpassed CLIP by an average of 8.61% across five previously unseen datasets covering three human-centric tasks. FocusCLIP achieved an average accuracy of 33.65% compared to 25.04% by CLIP. We observed a 3.98% improvement in activity recognition, a 14.78% improvement in age classification, and a 7.06% improvement in emotion recognition. Moreover, using our proposed single-shot LLM prompting strategy, we release a high-quality MPII Pose Descriptions dataset to encourage further research in multimodal learning for human-centric tasks. Furthermore, we also demonstrate the effectiveness of our subject-level supervision on non-human-centric tasks. FocusCLIP shows a 2.47% improvement over CLIP in zero-shot bird classification using the CUB dataset. Our findings emphasize the potential of integrating subject-level guidance with general pretraining methods for enhanced downstream performance.
Query-guided Prototype Evolution Network for Few-Shot Segmentation
Mar 11, 2024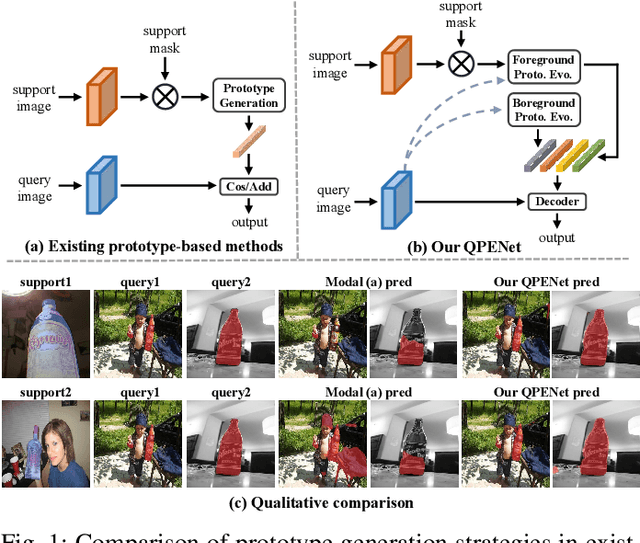
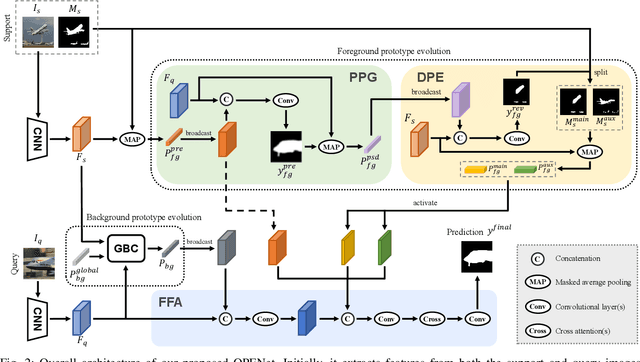
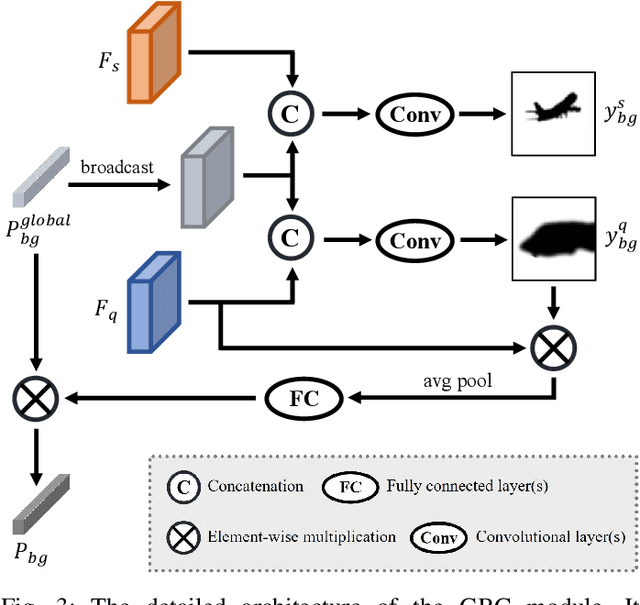

Previous Few-Shot Segmentation (FSS) approaches exclusively utilize support features for prototype generation, neglecting the specific requirements of the query. To address this, we present the Query-guided Prototype Evolution Network (QPENet), a new method that integrates query features into the generation process of foreground and background prototypes, thereby yielding customized prototypes attuned to specific queries. The evolution of the foreground prototype is accomplished through a \textit{support-query-support} iterative process involving two new modules: Pseudo-prototype Generation (PPG) and Dual Prototype Evolution (DPE). The PPG module employs support features to create an initial prototype for the preliminary segmentation of the query image, resulting in a pseudo-prototype reflecting the unique needs of the current query. Subsequently, the DPE module performs reverse segmentation on support images using this pseudo-prototype, leading to the generation of evolved prototypes, which can be considered as custom solutions. As for the background prototype, the evolution begins with a global background prototype that represents the generalized features of all training images. We also design a Global Background Cleansing (GBC) module to eliminate potential adverse components mirroring the characteristics of the current foreground class. Experimental results on the PASCAL-$5^i$ and COCO-$20^i$ datasets attest to the substantial enhancements achieved by QPENet over prevailing state-of-the-art techniques, underscoring the validity of our ideas.
Language-guided Image Reflection Separation
Feb 19, 2024This paper studies the problem of language-guided reflection separation, which aims at addressing the ill-posed reflection separation problem by introducing language descriptions to provide layer content. We propose a unified framework to solve this problem, which leverages the cross-attention mechanism with contrastive learning strategies to construct the correspondence between language descriptions and image layers. A gated network design and a randomized training strategy are employed to tackle the recognizable layer ambiguity. The effectiveness of the proposed method is validated by the significant performance advantage over existing reflection separation methods on both quantitative and qualitative comparisons.
VEglue: Testing Visual Entailment Systems via Object-Aligned Joint Erasing
Mar 05, 2024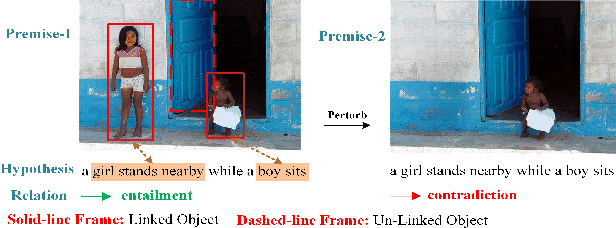

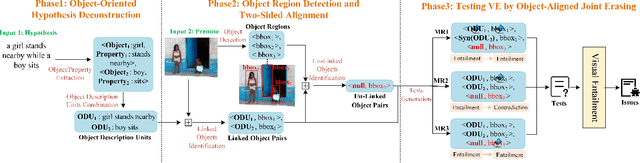
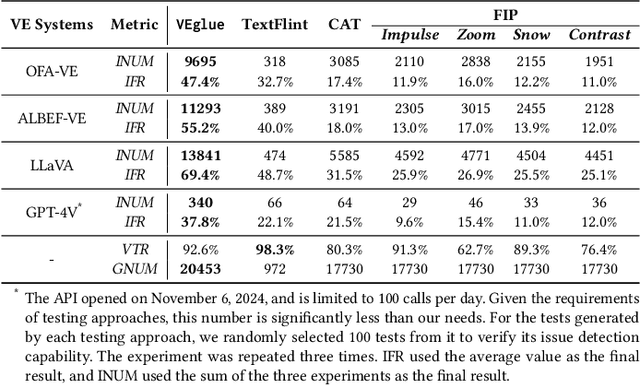
Visual entailment (VE) is a multimodal reasoning task consisting of image-sentence pairs whereby a promise is defined by an image, and a hypothesis is described by a sentence. The goal is to predict whether the image semantically entails the sentence. VE systems have been widely adopted in many downstream tasks. Metamorphic testing is the commonest technique for AI algorithms, but it poses a significant challenge for VE testing. They either only consider perturbations on single modality which would result in ineffective tests due to the destruction of the relationship of image-text pair, or just conduct shallow perturbations on the inputs which can hardly detect the decision error made by VE systems. Motivated by the fact that objects in the image are the fundamental element for reasoning, we propose VEglue, an object-aligned joint erasing approach for VE systems testing. It first aligns the object regions in the premise and object descriptions in the hypothesis to identify linked and un-linked objects. Then, based on the alignment information, three Metamorphic Relations are designed to jointly erase the objects of the two modalities. We evaluate VEglue on four widely-used VE systems involving two public datasets. Results show that VEglue could detect 11,609 issues on average, which is 194%-2,846% more than the baselines. In addition, VEglue could reach 52.5% Issue Finding Rate (IFR) on average, and significantly outperform the baselines by 17.1%-38.2%. Furthermore, we leverage the tests generated by VEglue to retrain the VE systems, which largely improves model performance (50.8% increase in accuracy) on newly generated tests without sacrificing the accuracy on the original test set.
Multi-Objective Learning for Deformable Image Registration
Feb 23, 2024Deformable image registration (DIR) involves optimization of multiple conflicting objectives, however, not many existing DIR algorithms are multi-objective (MO). Further, while there has been progress in the design of deep learning algorithms for DIR, there is no work in the direction of MO DIR using deep learning. In this paper, we fill this gap by combining a recently proposed approach for MO training of neural networks with a well-known deep neural network for DIR and create a deep learning based MO DIR approach. We evaluate the proposed approach for DIR of pelvic magnetic resonance imaging (MRI) scans. We experimentally demonstrate that the proposed MO DIR approach -- providing multiple registration outputs for each patient that each correspond to a different trade-off between the objectives -- has additional desirable properties from a clinical use point-of-view as compared to providing a single DIR output. The experiments also show that the proposed MO DIR approach provides a better spread of DIR outputs across the entire trade-off front than simply training multiple neural networks with weights for each objective sampled from a grid of possible values.
U-shaped Vision Mamba for Single Image Dehazing
Feb 16, 2024Currently, Transformer is the most popular architecture for image dehazing, but due to its large computational complexity, its ability to handle long-range dependency is limited on resource-constrained devices. To tackle this challenge, we introduce the U-shaped Vision Mamba (UVM-Net), an efficient single-image dehazing network. Inspired by the State Space Sequence Models (SSMs), a new deep sequence model known for its power to handle long sequences, we design a Bi-SSM block that integrates the local feature extraction ability of the convolutional layer with the ability of the SSM to capture long-range dependencies. Extensive experimental results demonstrate the effectiveness of our method. Our method provides a more highly efficient idea of long-range dependency modeling for image dehazing as well as other image restoration tasks. The URL of the code is \url{https://github.com/zzr-idam/UVM-Net}. Our method takes only \textbf{0.009} seconds to infer a $325 \times 325$ resolution image (100FPS) without I/O handling time.