 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
HarrisZ$^+$: Harris Corner Selection for Next-Gen Image Matching Pipelines
Sep 29, 2021

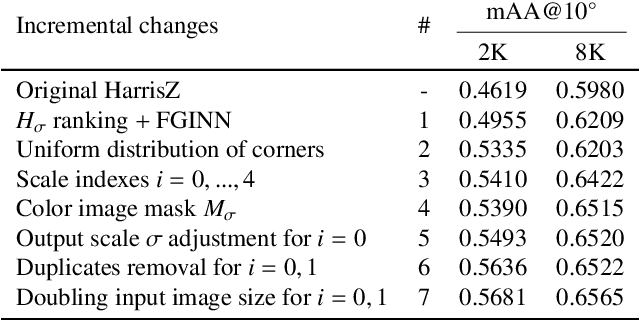

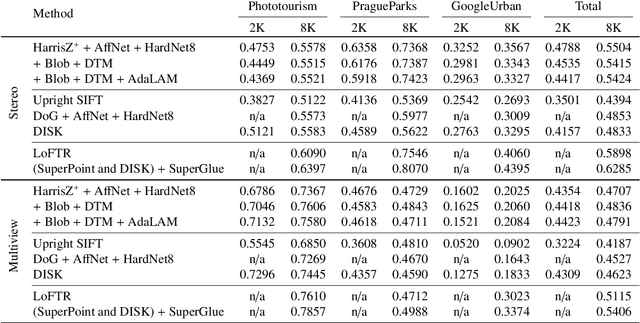
Due to its role in many computer vision tasks, image matching has been subjected to an active investigation by researchers, which has lead to better and more discriminant feature descriptors and to more robust matching strategies, also thanks to the advent of the deep learning and the increased computational power of the modern hardware. Despite of these achievements, the keypoint extraction process at the base of the image matching pipeline has not seen equivalent progresses. This paper presents Harrisz$^{+}$, an upgrade to the HarrisZ corner detector, optimized to synergically take advance of the recent improvements of the other steps of the image matching pipeline. Harrisz$^{+}$ does not only consists of a tuning of the setup parameters, but introduces further refinements to the selection criteria delineated by HarrisZ, so providing more, yet discriminative, keypoints, which are better distributed on the image and with higher localization accuracy. The image matching pipeline including Harrisz$^{+}$, together with the other modern components, obtained in different recent matching benchmarks state-of-the-art results among the classic image matching pipelines, closely following results of the more recent fully deep end-to-end trainable approaches.
Pixel-Level Face Image Quality Assessment for Explainable Face Recognition
Oct 21, 2021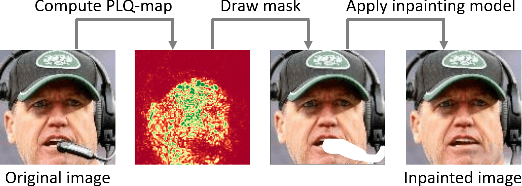
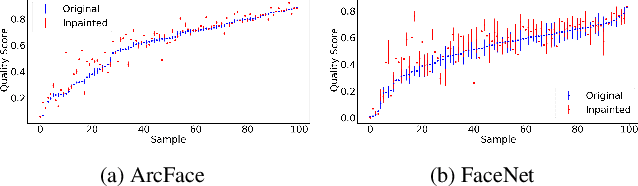
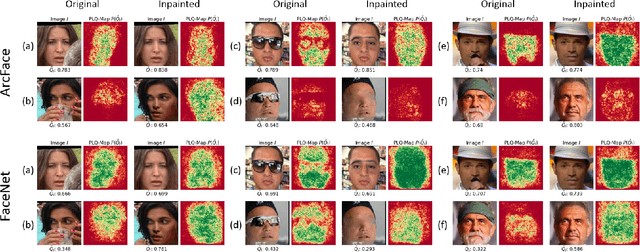
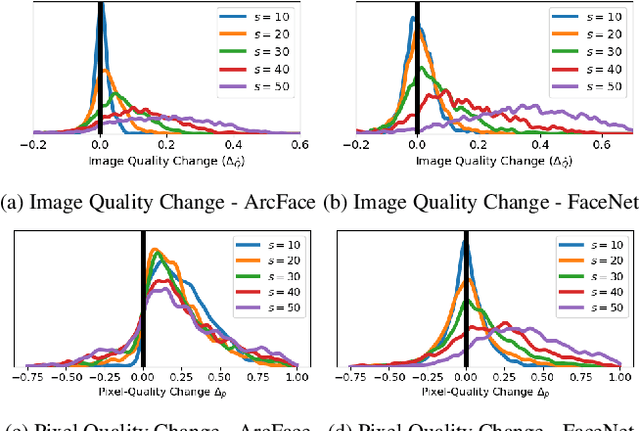
An essential factor to achieve high performance in face recognition systems is the quality of its samples. Since these systems are involved in various daily life there is a strong need of making face recognition processes understandable for humans. In this work, we introduce the concept of pixel-level face image quality that determines the utility of pixels in a face image for recognition. Given an arbitrary face recognition network, in this work, we propose a training-free approach to assess the pixel-level qualities of a face image. To achieve this, a model-specific quality value of the input image is estimated and used to build a sample-specific quality regression model. Based on this model, quality-based gradients are back-propagated and converted into pixel-level quality estimates. In the experiments, we qualitatively and quantitatively investigated the meaningfulness of the pixel-level qualities based on real and artificial disturbances and by comparing the explanation maps on ICAO-incompliant faces. In all scenarios, the results demonstrate that the proposed solution produces meaningful pixel-level qualities. The code is publicly available.
Culture-to-Culture Image Translation with Generative Adversarial Networks
Jan 14, 2022

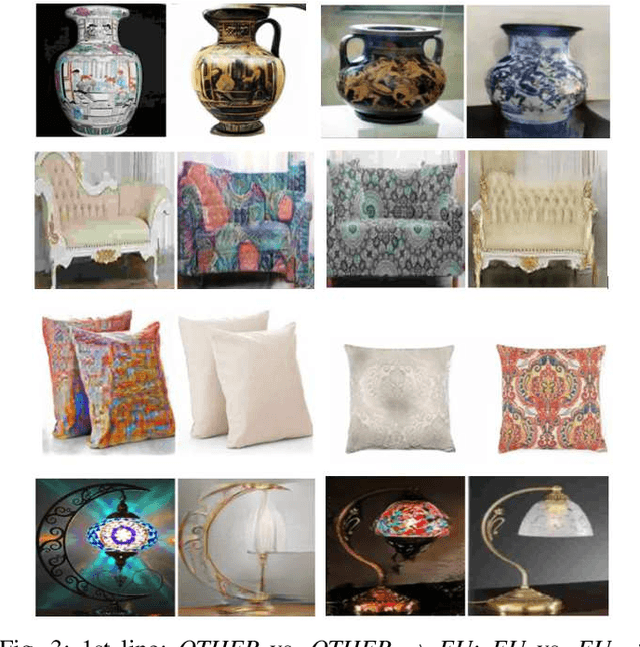

This article introduces the concept of image "culturization", i.e., defined as the process of altering the "brushstroke of cultural features" that make objects perceived as belonging to a given culture while preserving their functionalities. First, we propose a pipeline for translating objects' images from a source to a target cultural domain based on Generative Adversarial Networks (GAN). Then, we gather data through an online questionnaire to test four hypotheses concerning the preferences of Italian participants towards objects and environments belonging to different cultures. As expected, results depend on individual tastes and preference: however, they are in line with our conjecture that some people, during the interaction with a robot or another intelligent system, might prefer to be shown images whose cultural domain has been modified to match their cultural background.
Constraining Pseudo-label in Self-training Unsupervised Domain Adaptation with Energy-based Model
Aug 26, 2022Deep learning is usually data starved, and the unsupervised domain adaptation (UDA) is developed to introduce the knowledge in the labeled source domain to the unlabeled target domain. Recently, deep self-training presents a powerful means for UDA, involving an iterative process of predicting the target domain and then taking the confident predictions as hard pseudo-labels for retraining. However, the pseudo-labels are usually unreliable, thus easily leading to deviated solutions with propagated errors. In this paper, we resort to the energy-based model and constrain the training of the unlabeled target sample with an energy function minimization objective. It can be achieved via a simple additional regularization or an energy-based loss. This framework allows us to gain the benefits of the energy-based model, while retaining strong discriminative performance following a plug-and-play fashion. The convergence property and its connection with classification expectation minimization are investigated. We deliver extensive experiments on the most popular and large-scale UDA benchmarks of image classification as well as semantic segmentation to demonstrate its generality and effectiveness.
Label Assistant: A Workflow for Assisted Data Annotation in Image Segmentation Tasks
Nov 27, 2021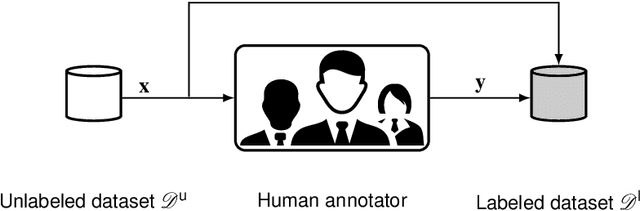
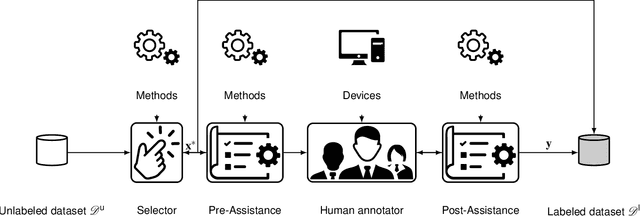
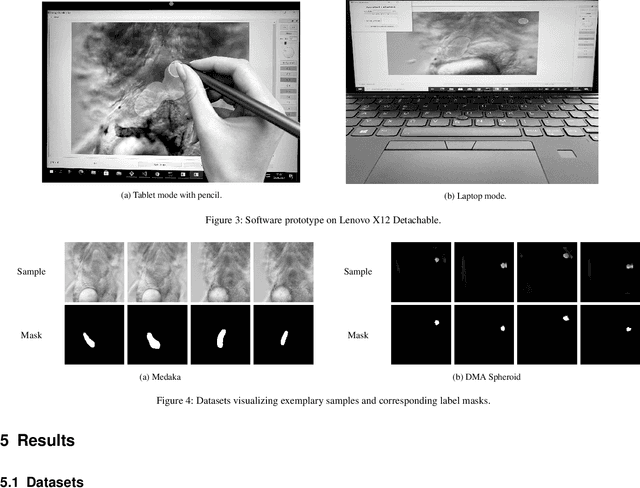
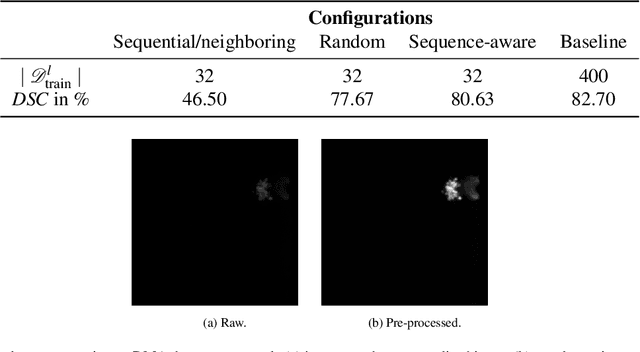
Recent research in the field of computer vision strongly focuses on deep learning architectures to tackle image processing problems. Deep neural networks are often considered in complex image processing scenarios since traditional computer vision approaches are expensive to develop or reach their limits due to complex relations. However, a common criticism is the need for large annotated datasets to determine robust parameters. Annotating images by human experts is time-consuming, burdensome, and expensive. Thus, support is needed to simplify annotation, increase user efficiency, and annotation quality. In this paper, we propose a generic workflow to assist the annotation process and discuss methods on an abstract level. Thereby, we review the possibilities of focusing on promising samples, image pre-processing, pre-labeling, label inspection, or post-processing of annotations. In addition, we present an implementation of the proposal by means of a developed flexible and extendable software prototype nested in hybrid touchscreen/laptop device.
Image Processing Methods for Coronal Hole Segmentation, Matching, and Map Classification
Jan 04, 2022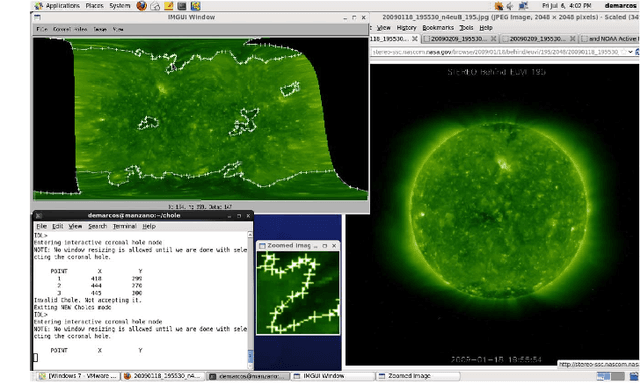

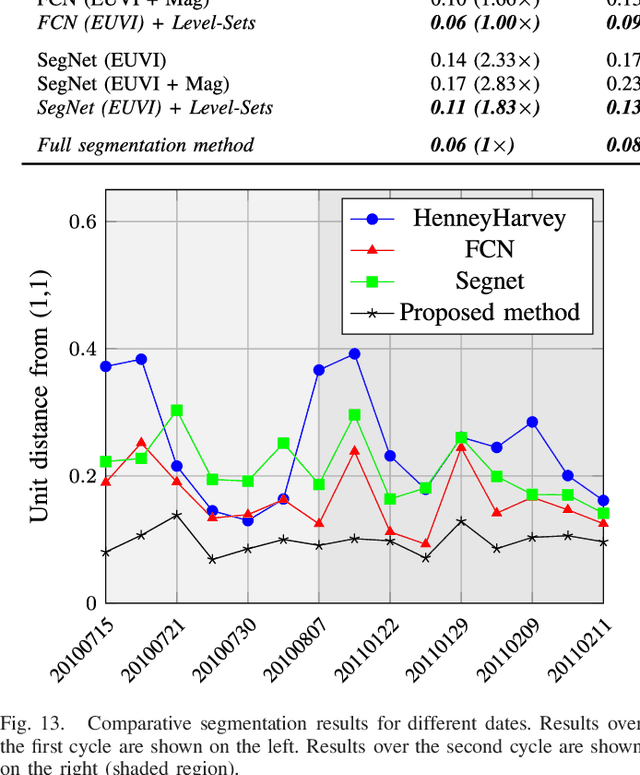
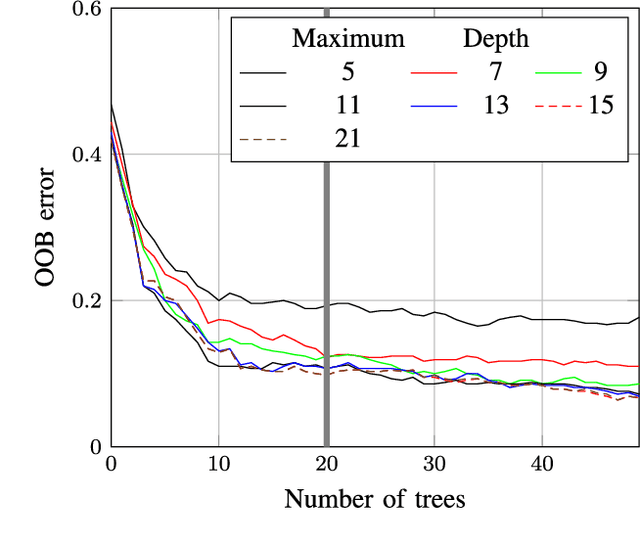
The paper presents the results from a multi-year effort to develop and validate image processing methods for selecting the best physical models based on solar image observations. The approach consists of selecting the physical models based on their agreement with coronal holes extracted from the images. Ultimately, the goal is to use physical models to predict geomagnetic storms. We decompose the problem into three subproblems: (i) coronal hole segmentation based on physical constraints, (ii) matching clusters of coronal holes between different maps, and (iii) physical map classification. For segmenting coronal holes, we develop a multi-modal method that uses segmentation maps from three different methods to initialize a level-set method that evolves the initial coronal hole segmentation to the magnetic boundary. Then, we introduce a new method based on Linear Programming for matching clusters of coronal holes. The final matching is then performed using Random Forests. The methods were carefully validated using consensus maps derived from multiple readers, manual clustering, manual map classification, and method validation for 50 maps. The proposed multi-modal segmentation method significantly outperformed SegNet, U-net, Henney-Harvey, and FCN by providing accurate boundary detection. Overall, the method gave a 95.5% map classification accuracy.
Semantic Relation Preserving Knowledge Distillation for Image-to-Image Translation
May 19, 2021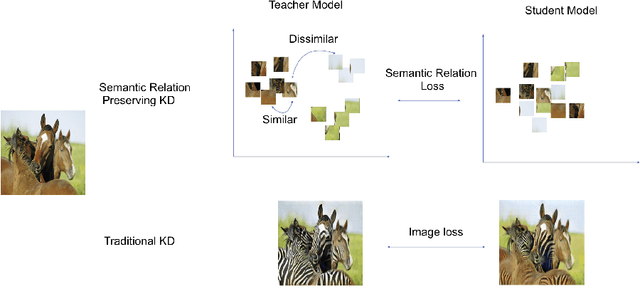
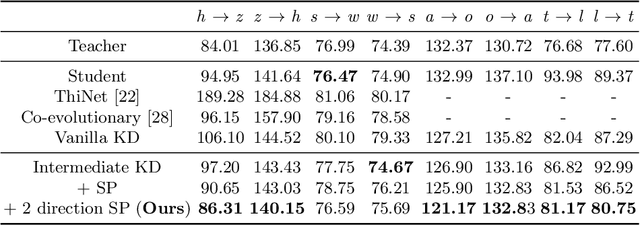
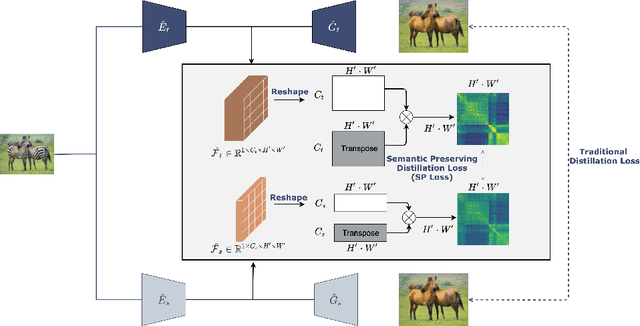
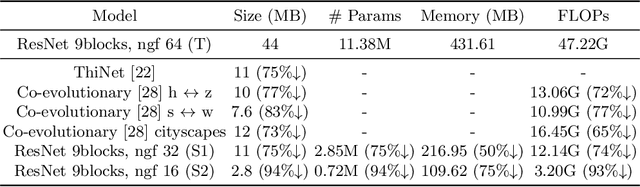
Generative adversarial networks (GANs) have shown significant potential in modeling high dimensional distributions of image data, especially on image-to-image translation tasks. However, due to the complexity of these tasks, state-of-the-art models often contain a tremendous amount of parameters, which results in large model size and long inference time. In this work, we propose a novel method to address this problem by applying knowledge distillation together with distillation of a semantic relation preserving matrix. This matrix, derived from the teacher's feature encoding, helps the student model learn better semantic relations. In contrast to existing compression methods designed for classification tasks, our proposed method adapts well to the image-to-image translation task on GANs. Experiments conducted on 5 different datasets and 3 different pairs of teacher and student models provide strong evidence that our methods achieve impressive results both qualitatively and quantitatively.
E-NeRV: Expedite Neural Video Representation with Disentangled Spatial-Temporal Context
Jul 17, 2022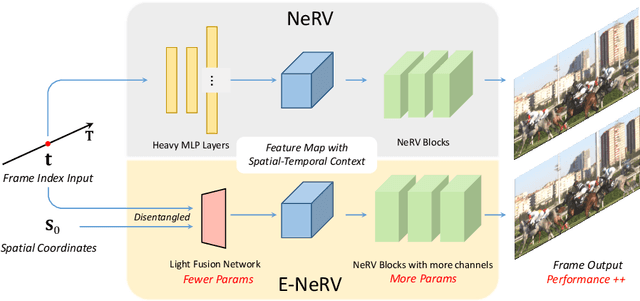

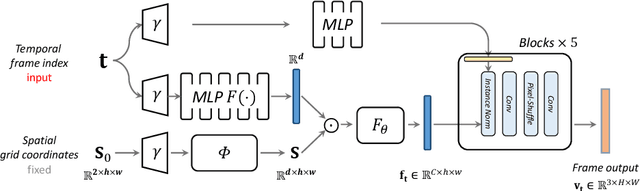
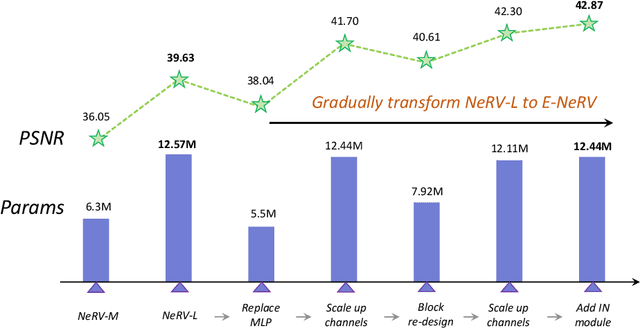
Recently, the image-wise implicit neural representation of videos, NeRV, has gained popularity for its promising results and swift speed compared to regular pixel-wise implicit representations. However, the redundant parameters within the network structure can cause a large model size when scaling up for desirable performance. The key reason of this phenomenon is the coupled formulation of NeRV, which outputs the spatial and temporal information of video frames directly from the frame index input. In this paper, we propose E-NeRV, which dramatically expedites NeRV by decomposing the image-wise implicit neural representation into separate spatial and temporal context. Under the guidance of this new formulation, our model greatly reduces the redundant model parameters, while retaining the representation ability. We experimentally find that our method can improve the performance to a large extent with fewer parameters, resulting in a more than $8\times$ faster speed on convergence. Code is available at https://github.com/kyleleey/E-NeRV.
OrthoMAD: Morphing Attack Detection Through Orthogonal Identity Disentanglement
Aug 16, 2022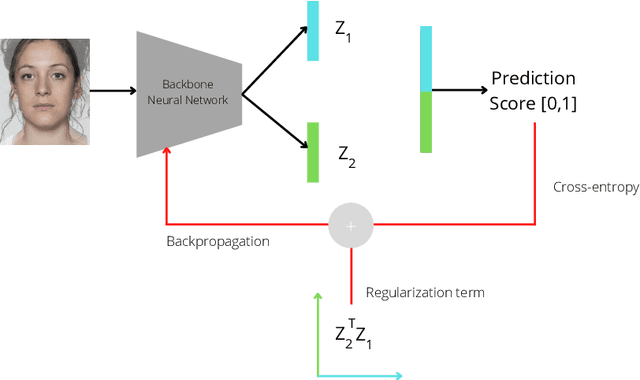
Morphing attacks are one of the many threats that are constantly affecting deep face recognition systems. It consists of selecting two faces from different individuals and fusing them into a final image that contains the identity information of both. In this work, we propose a novel regularisation term that takes into account the existent identity information in both and promotes the creation of two orthogonal latent vectors. We evaluate our proposed method (OrthoMAD) in five different types of morphing in the FRLL dataset and evaluate the performance of our model when trained on five distinct datasets. With a small ResNet-18 as the backbone, we achieve state-of-the-art results in the majority of the experiments, and competitive results in the others. The code of this paper will be publicly available.
A Text Attention Network for Spatial Deformation Robust Scene Text Image Super-resolution
Mar 18, 2022
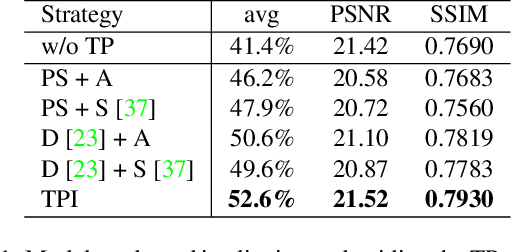
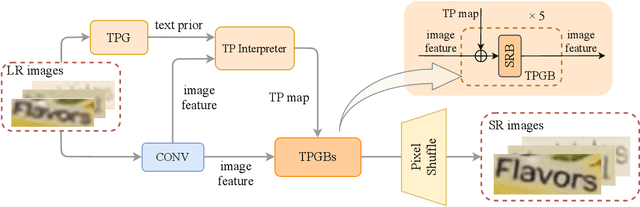
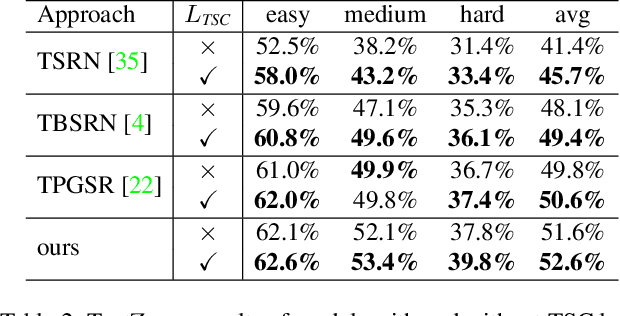
Scene text image super-resolution aims to increase the resolution and readability of the text in low-resolution images. Though significant improvement has been achieved by deep convolutional neural networks (CNNs), it remains difficult to reconstruct high-resolution images for spatially deformed texts, especially rotated and curve-shaped ones. This is because the current CNN-based methods adopt locality-based operations, which are not effective to deal with the variation caused by deformations. In this paper, we propose a CNN based Text ATTention network (TATT) to address this problem. The semantics of the text are firstly extracted by a text recognition module as text prior information. Then we design a novel transformer-based module, which leverages global attention mechanism, to exert the semantic guidance of text prior to the text reconstruction process. In addition, we propose a text structure consistency loss to refine the visual appearance by imposing structural consistency on the reconstructions of regular and deformed texts. Experiments on the benchmark TextZoom dataset show that the proposed TATT not only achieves state-of-the-art performance in terms of PSNR/SSIM metrics, but also significantly improves the recognition accuracy in the downstream text recognition task, particularly for text instances with multi-orientation and curved shapes. Code is available at https://github.com/mjq11302010044/TATT.