 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLarge Means Left: Political Bias in Large Language Models Increases with Their Number of Parameters
May 07, 2025With the increasing prevalence of artificial intelligence, careful evaluation of inherent biases needs to be conducted to form the basis for alleviating the effects these predispositions can have on users. Large language models (LLMs) are predominantly used by many as a primary source of information for various topics. LLMs frequently make factual errors, fabricate data (hallucinations), or present biases, exposing users to misinformation and influencing opinions. Educating users on their risks is key to responsible use, as bias, unlike hallucinations, cannot be caught through data verification. We quantify the political bias of popular LLMs in the context of the recent vote of the German Bundestag using the score produced by the Wahl-O-Mat. This metric measures the alignment between an individual's political views and the positions of German political parties. We compare the models' alignment scores to identify factors influencing their political preferences. Doing so, we discover a bias toward left-leaning parties, most dominant in larger LLMs. Also, we find that the language we use to communicate with the models affects their political views. Additionally, we analyze the influence of a model's origin and release date and compare the results to the outcome of the recent vote of the Bundestag. Our results imply that LLMs are prone to exhibiting political bias. Large corporations with the necessary means to develop LLMs, thus, knowingly or unknowingly, have a responsibility to contain these biases, as they can influence each voter's decision-making process and inform public opinion in general and at scale.
Assessing Political Bias in Large Language Models
May 17, 2024



The assessment of societal biases within Large Language Models (LLMs) has emerged as a critical concern in the contemporary discourse surrounding Artificial Intelligence (AI) ethics and their impact. Especially, recognizing and considering political biases is important for practical applications to gain a deeper understanding of the possibilities and behaviors and to prevent unwanted statements. As the upcoming elections of the European Parliament will not remain unaffected by LLMs, we evaluate the bias of the current most popular open-source models concerning political issues within the European Union (EU) from a German perspective. To do so, we use the "Wahl-O-Mat", a voting advice application used in Germany, to determine which political party is the most aligned for the respective LLM. We show that larger models, such as Llama3-70B, tend to align more closely with left-leaning political parties like GR\"UNE and Volt, while smaller models often remain neutral, particularly in English. This highlights the nuanced behavior of LLMs and the importance of language in shaping their political stances. Our findings underscore the importance of rigorously assessing and addressing societal bias in LLMs to safeguard the integrity and fairness of applications that employ the power of modern machine learning methods.
Label Assistant: A Workflow for Assisted Data Annotation in Image Segmentation Tasks
Nov 27, 2021
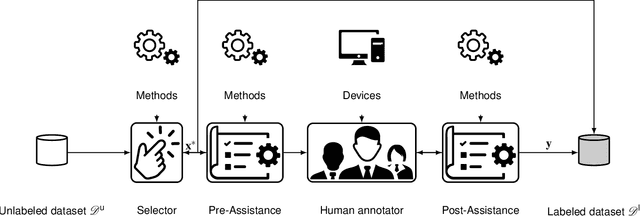
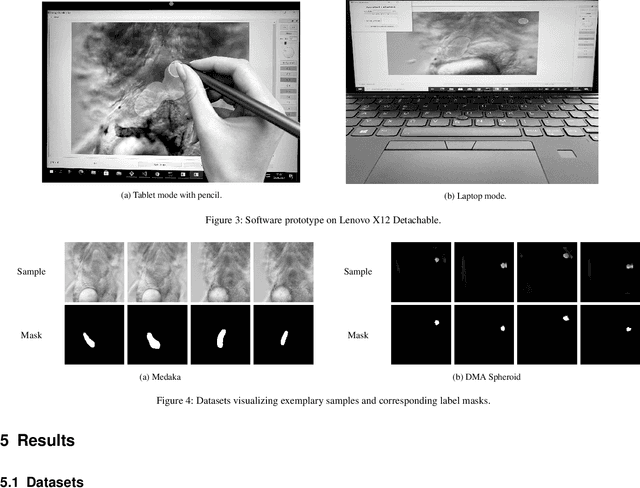
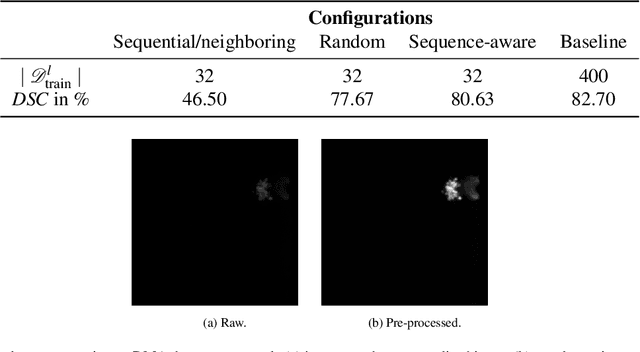
Recent research in the field of computer vision strongly focuses on deep learning architectures to tackle image processing problems. Deep neural networks are often considered in complex image processing scenarios since traditional computer vision approaches are expensive to develop or reach their limits due to complex relations. However, a common criticism is the need for large annotated datasets to determine robust parameters. Annotating images by human experts is time-consuming, burdensome, and expensive. Thus, support is needed to simplify annotation, increase user efficiency, and annotation quality. In this paper, we propose a generic workflow to assist the annotation process and discuss methods on an abstract level. Thereby, we review the possibilities of focusing on promising samples, image pre-processing, pre-labeling, label inspection, or post-processing of annotations. In addition, we present an implementation of the proposal by means of a developed flexible and extendable software prototype nested in hybrid touchscreen/laptop device.