 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Improving Accuracy and Explainability of Online Handwriting Recognition
Sep 14, 2022
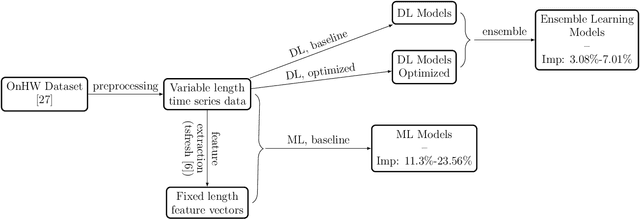
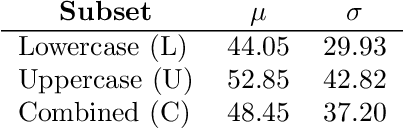
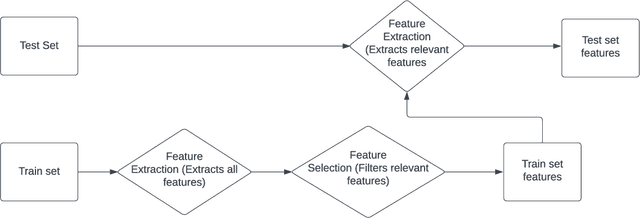
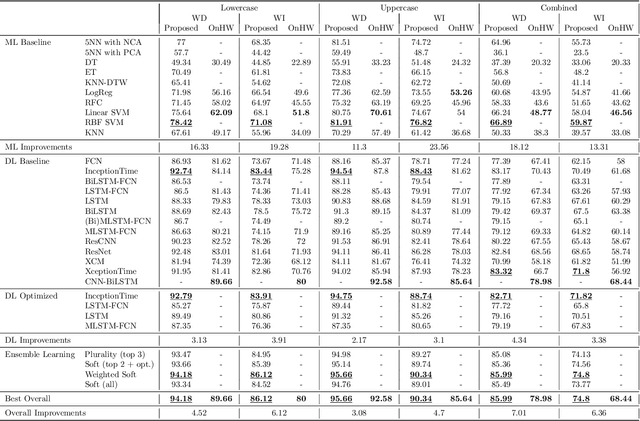
Handwriting recognition technology allows recognizing a written text from a given data. The recognition task can target letters, symbols, or words, and the input data can be a digital image or recorded by various sensors. A wide range of applications from signature verification to electronic document processing can be realized by implementing efficient and accurate handwriting recognition algorithms. Over the years, there has been an increasing interest in experimenting with different types of technology to collect handwriting data, create datasets, and develop algorithms to recognize characters and symbols. More recently, the OnHW-chars dataset has been published that contains multivariate time series data of the English alphabet collected using a ballpoint pen fitted with sensors. The authors of OnHW-chars also provided some baseline results through their machine learning (ML) and deep learning (DL) classifiers. In this paper, we develop handwriting recognition models on the OnHW-chars dataset and improve the accuracy of previous models. More specifically, our ML models provide $11.3\%$-$23.56\%$ improvements over the previous ML models, and our optimized DL models with ensemble learning provide $3.08\%$-$7.01\%$ improvements over the previous DL models. In addition to our accuracy improvements over the spectrum, we aim to provide some level of explainability for our models to provide more logic behind chosen methods and why the models make sense for the data type in the dataset. Our results are verifiable and reproducible via the provided public repository.
Geo-DefakeHop: High-Performance Geographic Fake Image Detection
Oct 19, 2021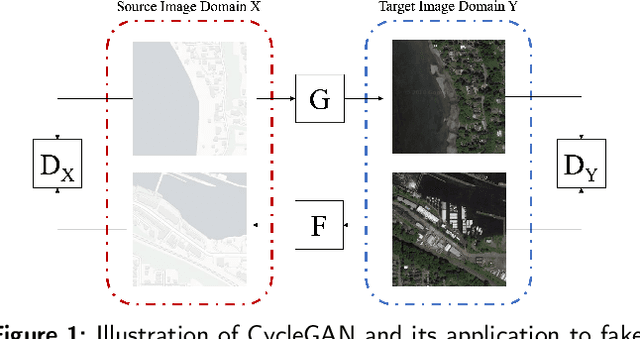
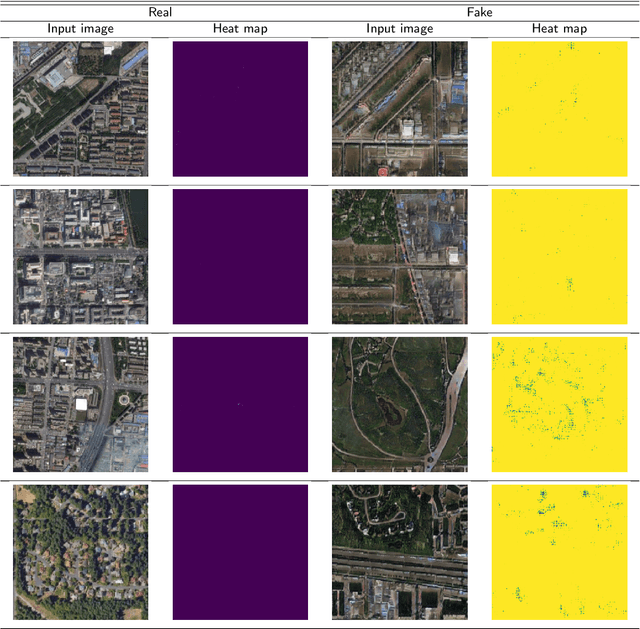
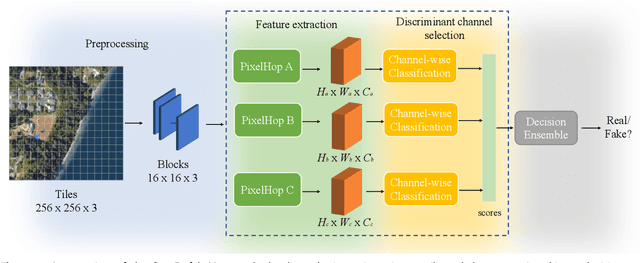

A robust fake satellite image detection method, called Geo-DefakeHop, is proposed in this work. Geo-DefakeHop is developed based on the parallel subspace learning (PSL) methodology. PSL maps the input image space into several feature subspaces using multiple filter banks. By exploring response differences of different channels between real and fake images for a filter bank, Geo-DefakeHop learns the most discriminant channels and uses their soft decision scores as features. Then, Geo-DefakeHop selects a few discriminant features from each filter bank and ensemble them to make a final binary decision. Geo-DefakeHop offers a light-weight high-performance solution to fake satellite images detection. Its model size is analyzed, which ranges from 0.8 to 62K parameters. Furthermore, it is shown by experimental results that it achieves an F1-score higher than 95\% under various common image manipulations such as resizing, compression and noise corruption.
Self-Supervised Intrinsic Image Decomposition Network Considering Reflectance Consistency
Nov 05, 2021

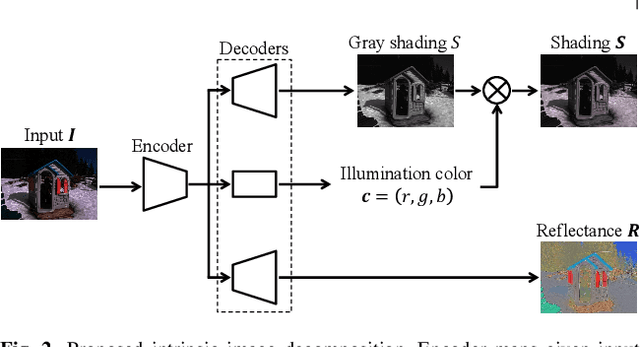
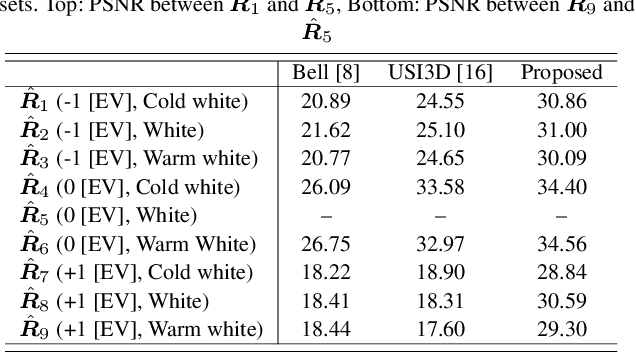
We propose a novel intrinsic image decomposition network considering reflectance consistency. Intrinsic image decomposition aims to decompose an image into illumination-invariant and illumination-variant components, referred to as ``reflectance'' and ``shading,'' respectively. Although there are three consistencies that the reflectance and shading should satisfy, most conventional work does not sufficiently account for consistency with respect to reflectance, owing to the use of a white-illuminant decomposition model and the lack of training images capturing the same objects under various illumination-brightness and -color conditions. For this reason, the three consistencies are considered in the proposed network by using a color-illuminant model and training the network with losses calculated from images taken under various illumination conditions. In addition, the proposed network can be trained in a self-supervised manner because various illumination conditions can easily be simulated. Experimental results show that our network can decompose images into reflectance and shading components.
Neural Neural Textures Make Sim2Real Consistent
Jun 27, 2022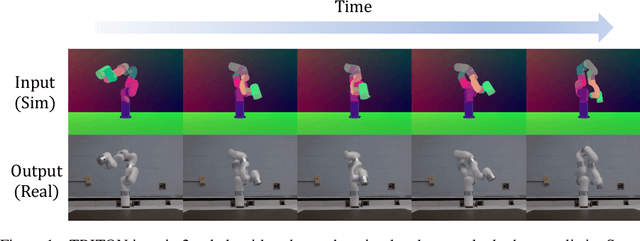
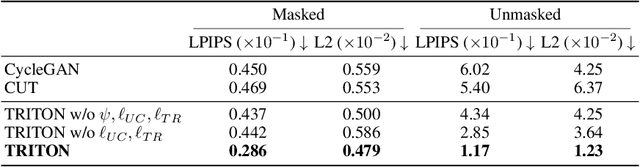


Unpaired image translation algorithms can be used for sim2real tasks, but many fail to generate temporally consistent results. We present a new approach that combines differentiable rendering with image translation to achieve temporal consistency over indefinite timescales, using surface consistency losses and \emph{neural neural textures}. We call this algorithm TRITON (Texture Recovering Image Translation Network): an unsupervised, end-to-end, stateless sim2real algorithm that leverages the underlying 3D geometry of input scenes by generating realistic-looking learnable neural textures. By settling on a particular texture for the objects in a scene, we ensure consistency between frames statelessly. Unlike previous algorithms, TRITON is not limited to camera movements -- it can handle the movement of objects as well, making it useful for downstream tasks such as robotic manipulation.
A Survey on Adversarial Image Synthesis
Jun 30, 2021Generative Adversarial Networks (GANs) have been extremely successful in various application domains. Adversarial image synthesis has drawn increasing attention and made tremendous progress in recent years because of its wide range of applications in many computer vision and image processing problems. Among the many applications of GAN, image synthesis is the most well-studied one, and research in this area has already demonstrated the great potential of using GAN in image synthesis. In this paper, we provide a taxonomy of methods used in image synthesis, review different models for text-to-image synthesis and image-to-image translation, and discuss some evaluation metrics as well as possible future research directions in image synthesis with GAN.
On the Optimal Combination of Cross-Entropy and Soft Dice Losses for Lesion Segmentation with Out-of-Distribution Robustness
Sep 14, 2022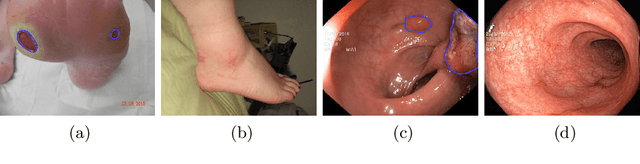
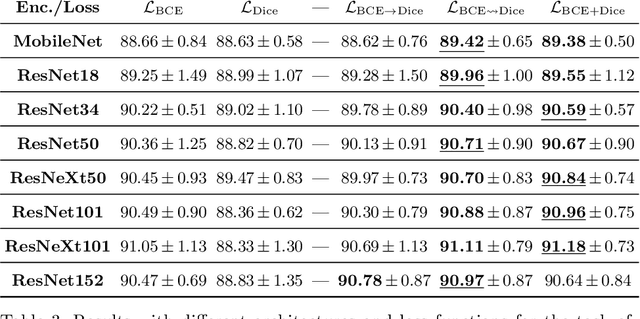
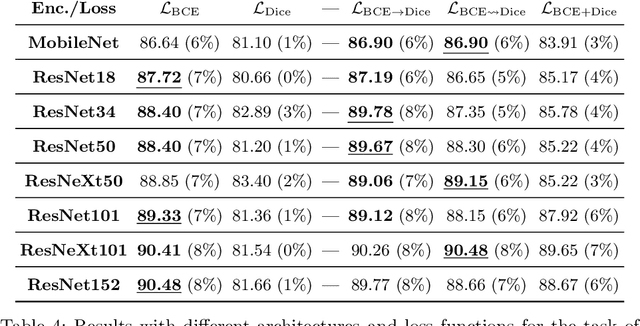
We study the impact of different loss functions on lesion segmentation from medical images. Although the Cross-Entropy (CE) loss is the most popular option when dealing with natural images, for biomedical image segmentation the soft Dice loss is often preferred due to its ability to handle imbalanced scenarios. On the other hand, the combination of both functions has also been successfully applied in this kind of tasks. A much less studied problem is the generalization ability of all these losses in the presence of Out-of-Distribution (OoD) data. This refers to samples appearing in test time that are drawn from a different distribution than training images. In our case, we train our models on images that always contain lesions, but in test time we also have lesion-free samples. We analyze the impact of the minimization of different loss functions on in-distribution performance, but also its ability to generalize to OoD data, via comprehensive experiments on polyp segmentation from endoscopic images and ulcer segmentation from diabetic feet images. Our findings are surprising: CE-Dice loss combinations that excel in segmenting in-distribution images have a poor performance when dealing with OoD data, which leads us to recommend the adoption of the CE loss for this kind of problems, due to its robustness and ability to generalize to OoD samples. Code associated to our experiments can be found at https://github.com/agaldran/lesion_losses_ood .
All You Need is RAW: Defending Against Adversarial Attacks with Camera Image Pipelines
Dec 16, 2021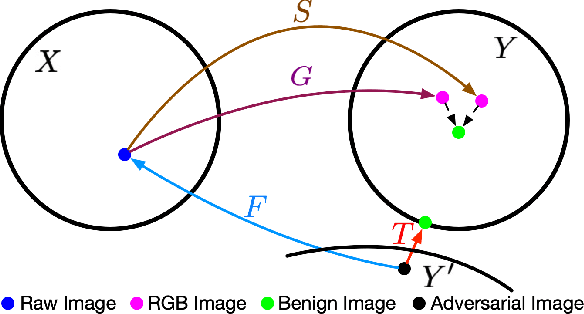
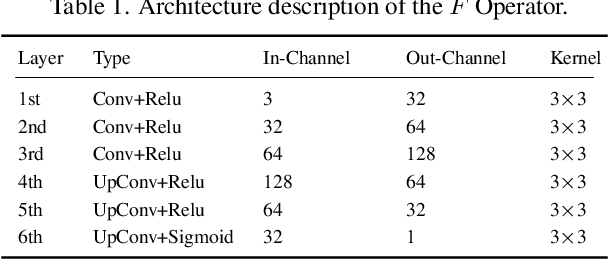
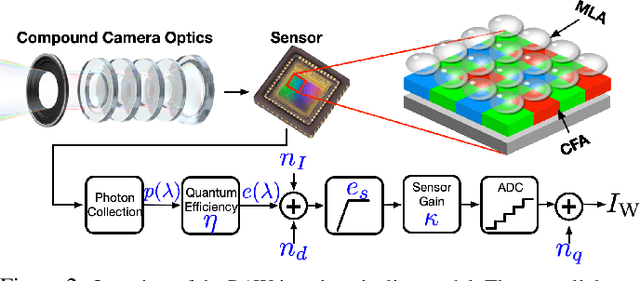
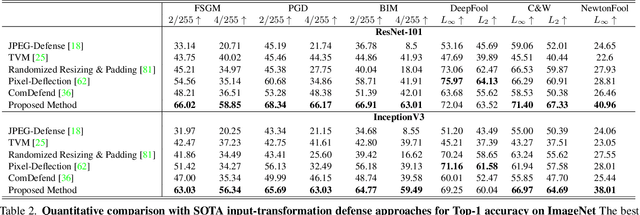
Existing neural networks for computer vision tasks are vulnerable to adversarial attacks: adding imperceptible perturbations to the input images can fool these methods to make a false prediction on an image that was correctly predicted without the perturbation. Various defense methods have proposed image-to-image mapping methods, either including these perturbations in the training process or removing them in a preprocessing denoising step. In doing so, existing methods often ignore that the natural RGB images in today's datasets are not captured but, in fact, recovered from RAW color filter array captures that are subject to various degradations in the capture. In this work, we exploit this RAW data distribution as an empirical prior for adversarial defense. Specifically, we proposed a model-agnostic adversarial defensive method, which maps the input RGB images to Bayer RAW space and back to output RGB using a learned camera image signal processing (ISP) pipeline to eliminate potential adversarial patterns. The proposed method acts as an off-the-shelf preprocessing module and, unlike model-specific adversarial training methods, does not require adversarial images to train. As a result, the method generalizes to unseen tasks without additional retraining. Experiments on large-scale datasets (e.g., ImageNet, COCO) for different vision tasks (e.g., classification, semantic segmentation, object detection) validate that the method significantly outperforms existing methods across task domains.
Chunk-aware Alignment and Lexical Constraint for Visual Entailment with Natural Language Explanations
Jul 23, 2022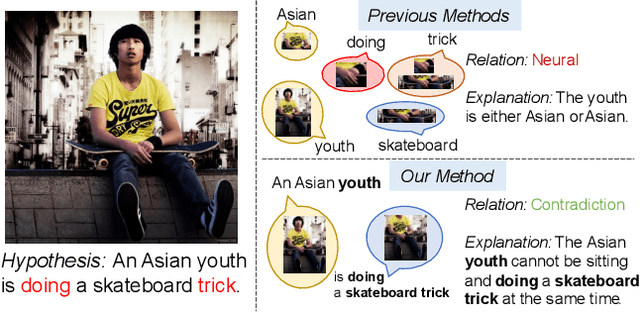
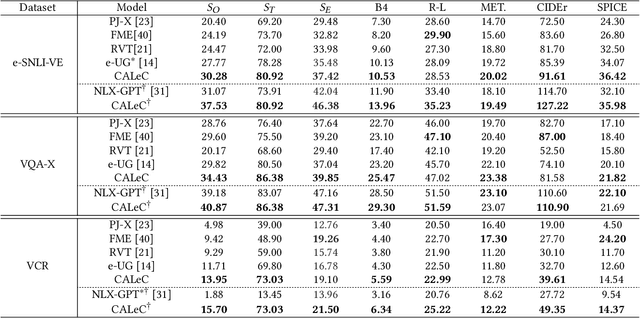
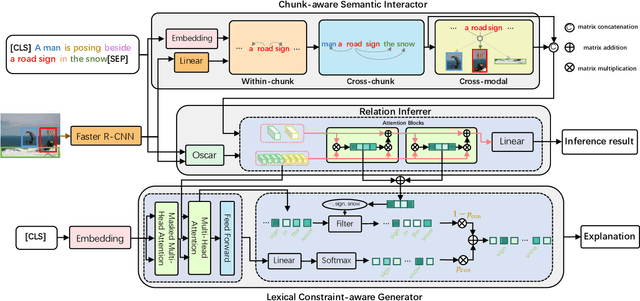
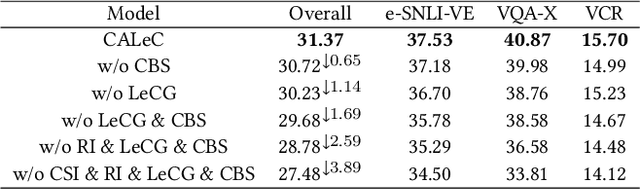
Visual Entailment with natural language explanations aims to infer the relationship between a text-image pair and generate a sentence to explain the decision-making process. Previous methods rely mainly on a pre-trained vision-language model to perform the relation inference and a language model to generate the corresponding explanation. However, the pre-trained vision-language models mainly build token-level alignment between text and image yet ignore the high-level semantic alignment between the phrases (chunks) and visual contents, which is critical for vision-language reasoning. Moreover, the explanation generator based only on the encoded joint representation does not explicitly consider the critical decision-making points of relation inference. Thus the generated explanations are less faithful to visual-language reasoning. To mitigate these problems, we propose a unified Chunk-aware Alignment and Lexical Constraint based method, dubbed as CALeC. It contains a Chunk-aware Semantic Interactor (arr. CSI), a relation inferrer, and a Lexical Constraint-aware Generator (arr. LeCG). Specifically, CSI exploits the sentence structure inherent in language and various image regions to build chunk-aware semantic alignment. Relation inferrer uses an attention-based reasoning network to incorporate the token-level and chunk-level vision-language representations. LeCG utilizes lexical constraints to expressly incorporate the words or chunks focused by the relation inferrer into explanation generation, improving the faithfulness and informativeness of the explanations. We conduct extensive experiments on three datasets, and experimental results indicate that CALeC significantly outperforms other competitor models on inference accuracy and quality of generated explanations.
OrthoMAD: Morphing Attack Detection Through Orthogonal Identity Disentanglement
Aug 23, 2022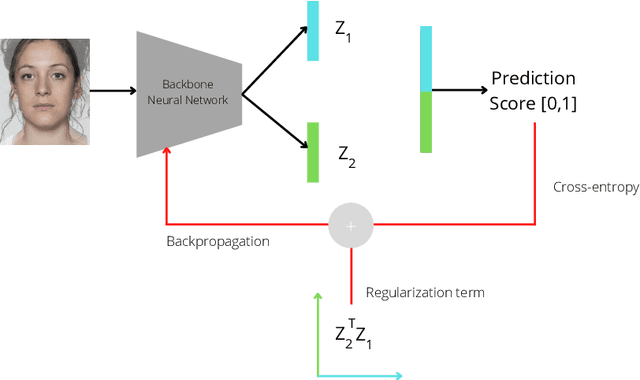
Morphing attacks are one of the many threats that are constantly affecting deep face recognition systems. It consists of selecting two faces from different individuals and fusing them into a final image that contains the identity information of both. In this work, we propose a novel regularisation term that takes into account the existent identity information in both and promotes the creation of two orthogonal latent vectors. We evaluate our proposed method (OrthoMAD) in five different types of morphing in the FRLL dataset and evaluate the performance of our model when trained on five distinct datasets. With a small ResNet-18 as the backbone, we achieve state-of-the-art results in the majority of the experiments, and competitive results in the others. The code of this paper will be publicly available.
Camera Adaptation for Fundus-Image-Based CVD Risk Estimation
Jun 18, 2022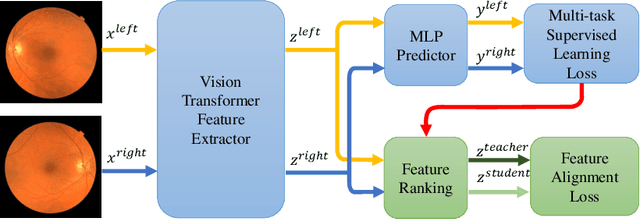
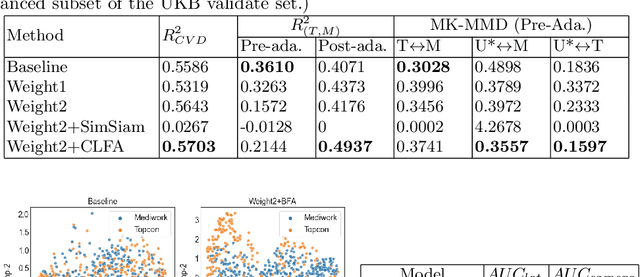
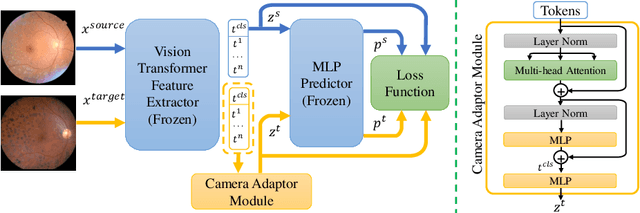

Recent studies have validated the association between cardiovascular disease (CVD) risk and retinal fundus images. Combining deep learning (DL) and portable fundus cameras will enable CVD risk estimation in various scenarios and improve healthcare democratization. However, there are still significant issues to be solved. One of the top priority issues is the different camera differences between the databases for research material and the samples in the production environment. Most high-quality retinography databases ready for research are collected from high-end fundus cameras, and there is a significant domain discrepancy between different cameras. To fully explore the domain discrepancy issue, we first collect a Fundus Camera Paired (FCP) dataset containing pair-wise fundus images captured by the high-end Topcon retinal camera and the low-end Mediwork portable fundus camera of the same patients. Then, we propose a cross-laterality feature alignment pre-training scheme and a self-attention camera adaptor module to improve the model robustness. The cross-laterality feature alignment training encourages the model to learn common knowledge from the same patient's left and right fundus images and improve model generalization. Meanwhile, the device adaptation module learns feature transformation from the target domain to the source domain. We conduct comprehensive experiments on both the UK Biobank database and our FCP data. The experimental results show that the CVD risk regression accuracy and the result consistency over two cameras are improved with our proposed method. The code is available here: \url{https://github.com/linzhlalala/CVD-risk-based-on-retinal-fundus-images}