 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Deep Curriculum Learning for PolSAR Image Classification
Dec 26, 2021
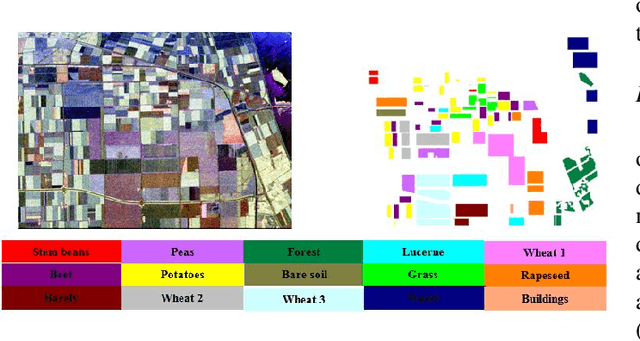
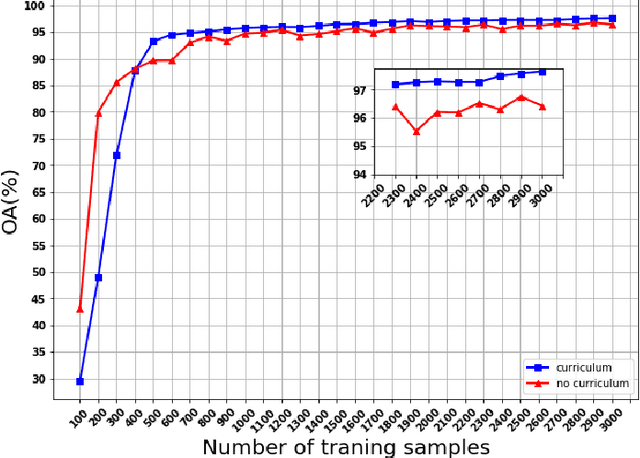

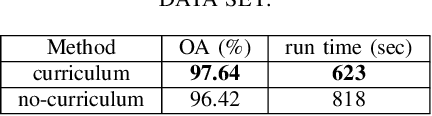
Following the great success of curriculum learning in the area of machine learning, a novel deep curriculum learning method proposed in this paper, entitled DCL, particularly for the classification of fully polarimetric synthetic aperture radar (PolSAR) data. This method utilizes the entropy-alpha target decomposition method to estimate the degree of complexity of each PolSAR image patch before applying it to the convolutional neural network (CNN). Also, an accumulative mini-batch pacing function is used to introduce more difficult patches to CNN.Experiments on the widely used data set of AIRSAR Flevoland reveal that the proposed curriculum learning method can not only increase classification accuracy but also lead to faster training convergence.
Bag of Tricks and A Strong baseline for Image Copy Detection
Nov 13, 2021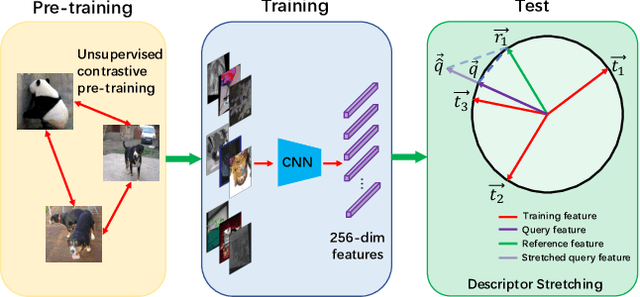
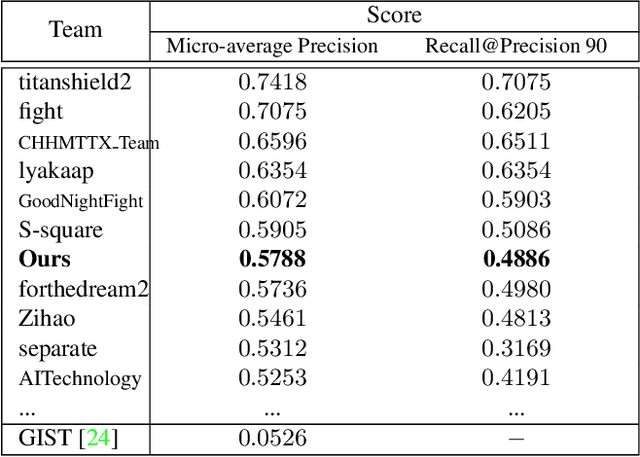
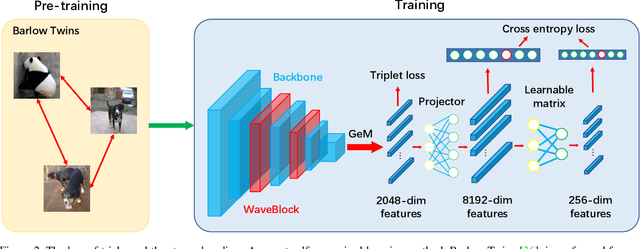
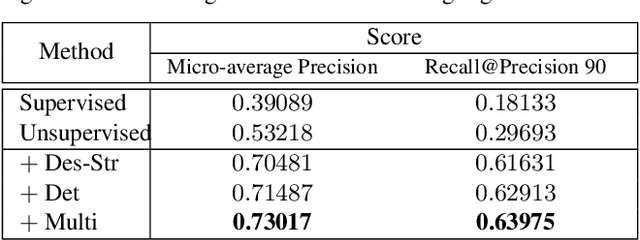
Image copy detection is of great importance in real-life social media. In this paper, a bag of tricks and a strong baseline are proposed for image copy detection. Unsupervised pre-training substitutes the commonly-used supervised one. Beyond that, we design a descriptor stretching strategy to stabilize the scores of different queries. Experiments demonstrate that the proposed method is effective. The proposed baseline ranks third out of 526 participants on the Facebook AI Image Similarity Challenge: Descriptor Track. The code and trained models are available at https://github.com/WangWenhao0716/ISC-Track2-Submission.
Nonlinear Intensity Sonar Image Matching based on Deep Convolution Features
Nov 29, 2021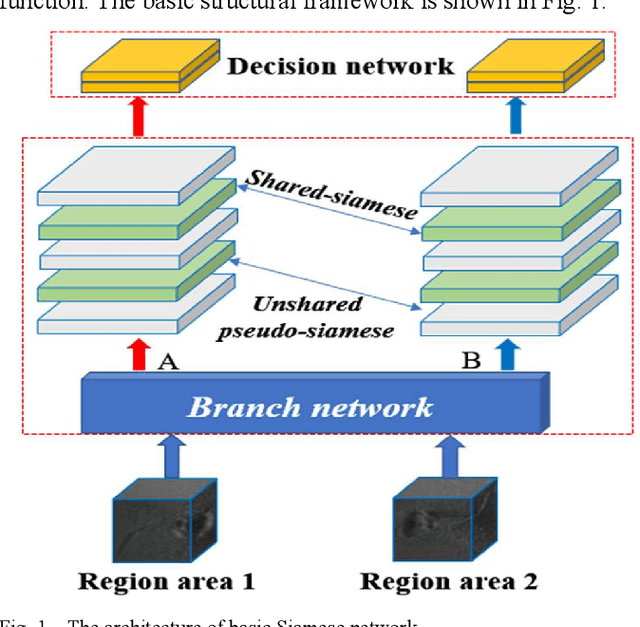
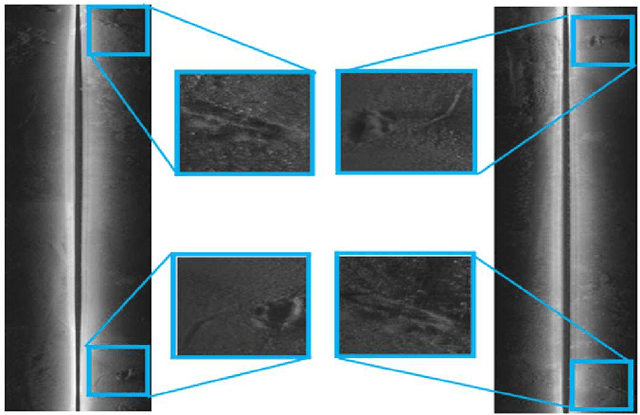
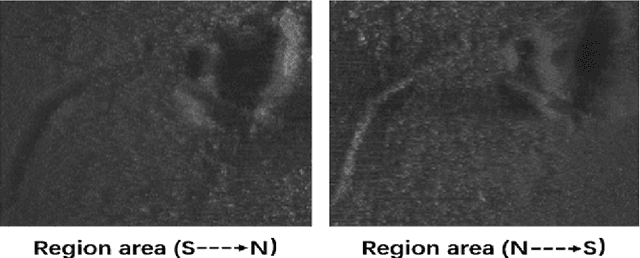
In the field of deep-sea exploration, sonar is presently the only efficient long-distance sensing device. The complicated underwater environment, such as noise interference, low target intensity or background dynamics, has brought many negative effects on sonar imaging. Among them, the problem of nonlinear intensity is extremely prevalent. It is also known as the anisotropy of acoustic imaging, that is, when AUVs carry sonar to detect the same target from different angles, the intensity difference between image pairs is sometimes very large, which makes the traditional matching algorithm almost ineffective. However, image matching is the basis of comprehensive tasks such as navigation, positioning, and mapping. Therefore, it is very valuable to obtain robust and accurate matching results. This paper proposes a combined matching method based on phase information and deep convolution features. It has two outstanding advantages: one is that deep convolution features could be used to measure the similarity of the local and global positions of the sonar image; the other is that local feature matching could be performed at the key target position of the sonar image. This method does not need complex manual design, and completes the matching task of nonlinear intensity sonar images in a close end-to-end manner. Feature matching experiments are carried out on the deep-sea sonar images captured by AUVs, and the results show that our proposal has good matching accuracy and robustness.
Classifier-Free Diffusion Guidance
Jul 26, 2022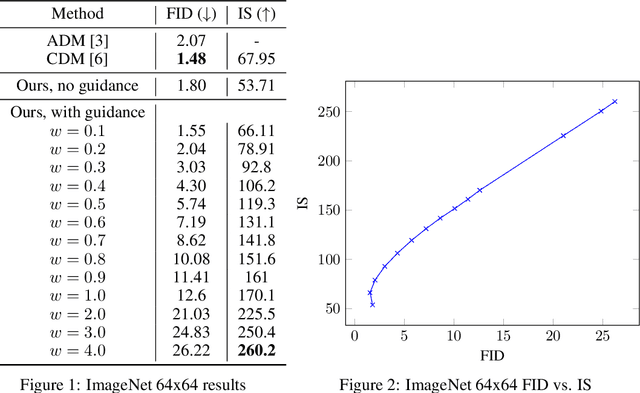


Classifier guidance is a recently introduced method to trade off mode coverage and sample fidelity in conditional diffusion models post training, in the same spirit as low temperature sampling or truncation in other types of generative models. Classifier guidance combines the score estimate of a diffusion model with the gradient of an image classifier and thereby requires training an image classifier separate from the diffusion model. It also raises the question of whether guidance can be performed without a classifier. We show that guidance can be indeed performed by a pure generative model without such a classifier: in what we call classifier-free guidance, we jointly train a conditional and an unconditional diffusion model, and we combine the resulting conditional and unconditional score estimates to attain a trade-off between sample quality and diversity similar to that obtained using classifier guidance.
Incremental Online Learning Algorithms Comparison for Gesture and Visual Smart Sensors
Sep 01, 2022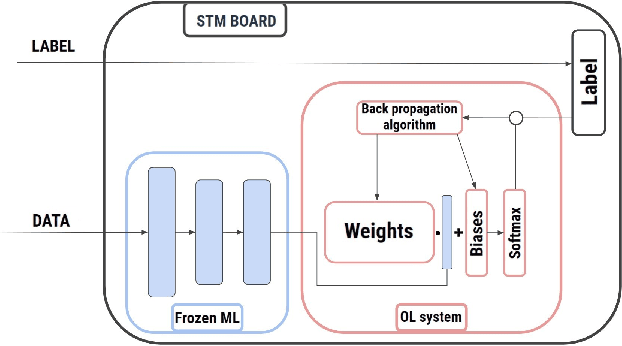

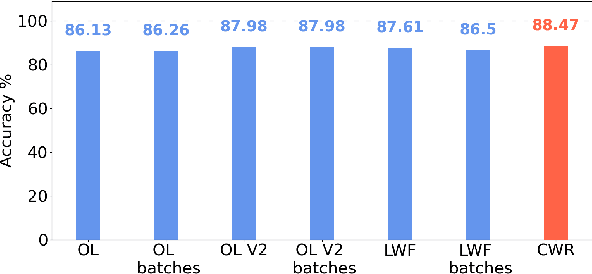
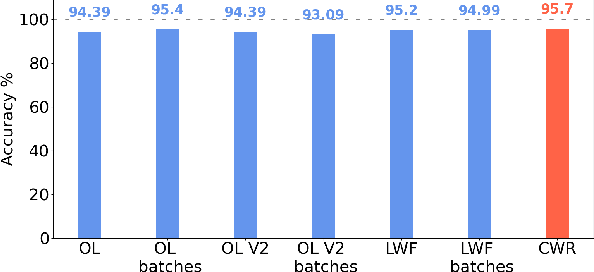
Tiny machine learning (TinyML) in IoT systems exploits MCUs as edge devices for data processing. However, traditional TinyML methods can only perform inference, limited to static environments or classes. Real case scenarios usually work in dynamic environments, thus drifting the context where the original neural model is no more suitable. For this reason, pre-trained models reduce accuracy and reliability during their lifetime because the data recorded slowly becomes obsolete or new patterns appear. Continual learning strategies maintain the model up to date, with runtime fine-tuning of the parameters. This paper compares four state-of-the-art algorithms in two real applications: i) gesture recognition based on accelerometer data and ii) image classification. Our results confirm these systems' reliability and the feasibility of deploying them in tiny-memory MCUs, with a drop in the accuracy of a few percentage points with respect to the original models for unconstrained computing platforms.
FisheyeEX: Polar Outpainting for Extending the FoV of Fisheye Lens
Jun 12, 2022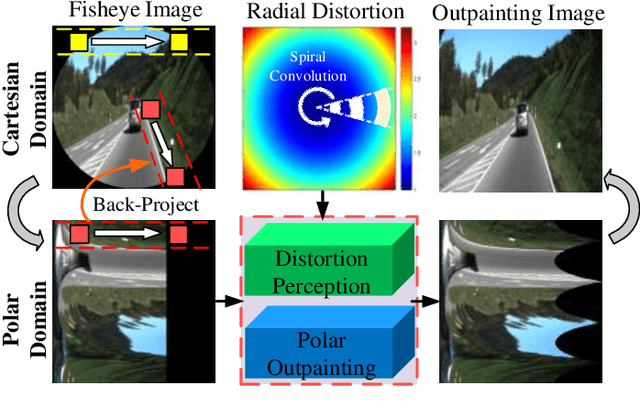
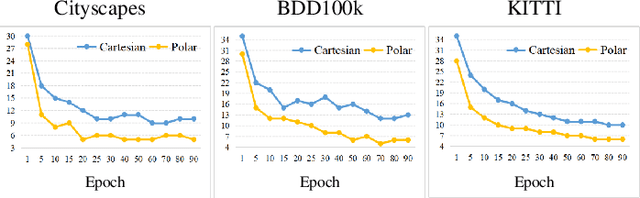
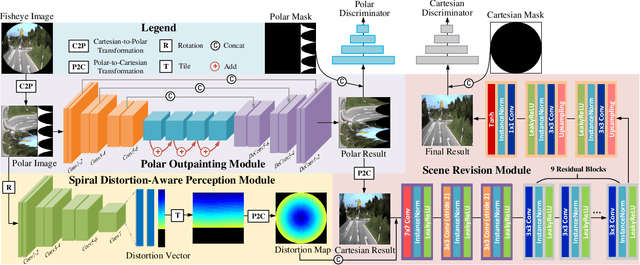
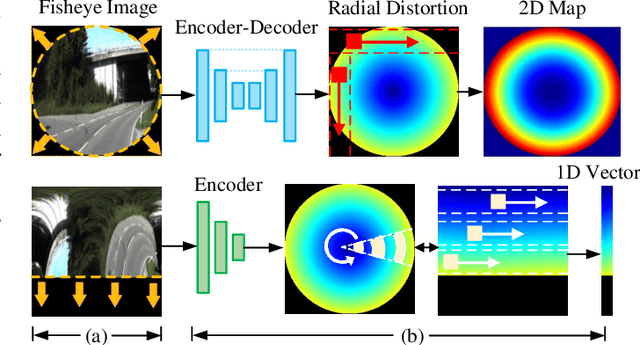
Fisheye lens gains increasing applications in computational photography and assisted driving because of its wide field of view (FoV). However, the fisheye image generally contains invalid black regions induced by its imaging model. In this paper, we present a FisheyeEX method that extends the FoV of the fisheye lens by outpainting the invalid regions, improving the integrity of captured scenes. Compared with the rectangle and undistorted image, there are two challenges for fisheye image outpainting: irregular painting regions and distortion synthesis. Observing the radial symmetry of the fisheye image, we first propose a polar outpainting strategy to extrapolate the coherent semantics from the center to the outside region. Such an outpainting manner considers the distribution pattern of radial distortion and the circle boundary, boosting a more reasonable completion direction. For the distortion synthesis, we propose a spiral distortion-aware perception module, in which the learning path keeps consistent with the distortion prior of the fisheye image. Subsequently, a scene revision module rearranges the generated pixels with the estimated distortion to match the fisheye image, thus extending the FoV. In the experiment, we evaluate the proposed FisheyeEX on three popular outdoor datasets: Cityscapes, BDD100k, and KITTI, and one real-world fisheye image dataset. The results demonstrate that our approach significantly outperforms the state-of-the-art methods, gaining around 27% more content beyond the original fisheye image.
MissMarple : A Novel Socio-inspired Feature-transfer Learning Deep Network for Image Splicing Detection
Dec 15, 2021In this paper we propose a novel socio-inspired convolutional neural network (CNN) deep learning model for image splicing detection. Based on the premise that learning from the detection of coarsely spliced image regions can improve the detection of visually imperceptible finely spliced image forgeries, the proposed model referred to as, MissMarple, is a twin CNN network involving feature-transfer learning. Results obtained from training and testing the proposed model using the benchmark datasets like Columbia splicing, WildWeb, DSO1 and a proposed dataset titled AbhAS consisting of realistic splicing forgeries revealed improvement in detection accuracy over the existing deep learning models.
Text Gestalt: Stroke-Aware Scene Text Image Super-Resolution
Dec 13, 2021
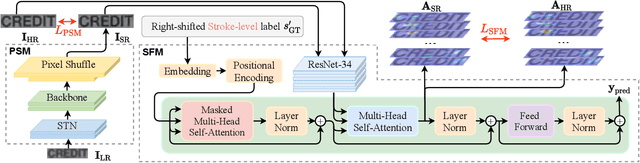
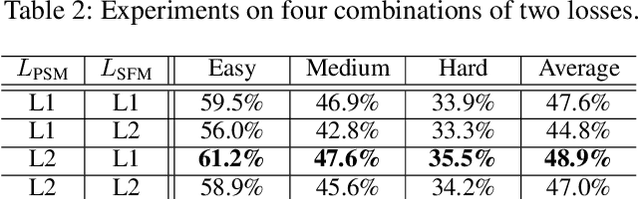
In the last decade, the blossom of deep learning has witnessed the rapid development of scene text recognition. However, the recognition of low-resolution scene text images remains a challenge. Even though some super-resolution methods have been proposed to tackle this problem, they usually treat text images as general images while ignoring the fact that the visual quality of strokes (the atomic unit of text) plays an essential role for text recognition. According to Gestalt Psychology, humans are capable of composing parts of details into the most similar objects guided by prior knowledge. Likewise, when humans observe a low-resolution text image, they will inherently use partial stroke-level details to recover the appearance of holistic characters. Inspired by Gestalt Psychology, we put forward a Stroke-Aware Scene Text Image Super-Resolution method containing a Stroke-Focused Module (SFM) to concentrate on stroke-level internal structures of characters in text images. Specifically, we attempt to design rules for decomposing English characters and digits at stroke-level, then pre-train a text recognizer to provide stroke-level attention maps as positional clues with the purpose of controlling the consistency between the generated super-resolution image and high-resolution ground truth. The extensive experimental results validate that the proposed method can indeed generate more distinguishable images on TextZoom and manually constructed Chinese character dataset Degraded-IC13. Furthermore, since the proposed SFM is only used to provide stroke-level guidance when training, it will not bring any time overhead during the test phase. Code is available at https://github.com/FudanVI/FudanOCR/tree/main/text-gestalt.
Probing Contextual Diversity for Dense Out-of-Distribution Detection
Aug 30, 2022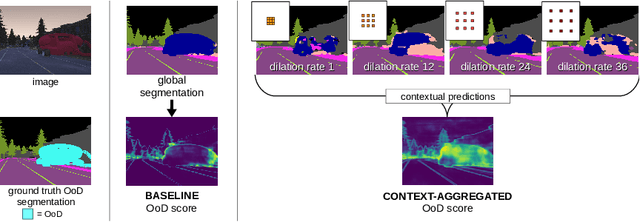
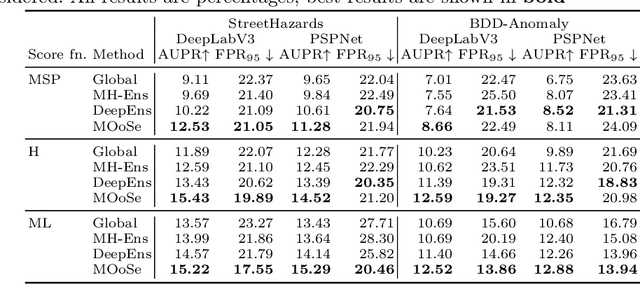
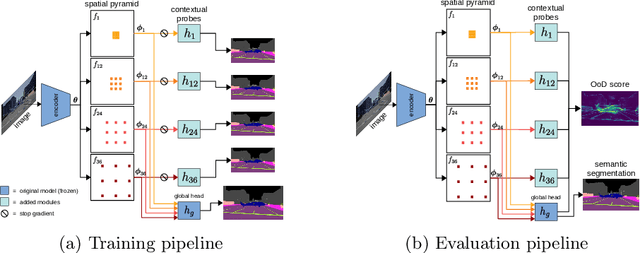
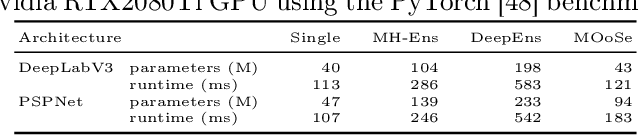
Detection of out-of-distribution (OoD) samples in the context of image classification has recently become an area of interest and active study, along with the topic of uncertainty estimation, to which it is closely related. In this paper we explore the task of OoD segmentation, which has been studied less than its classification counterpart and presents additional challenges. Segmentation is a dense prediction task for which the model's outcome for each pixel depends on its surroundings. The receptive field and the reliance on context play a role for distinguishing different classes and, correspondingly, for spotting OoD entities. We introduce MOoSe, an efficient strategy to leverage the various levels of context represented within semantic segmentation models and show that even a simple aggregation of multi-scale representations has consistently positive effects on OoD detection and uncertainty estimation.
Photon-Limited Blind Deconvolution using Unsupervised Iterative Kernel Estimation
Aug 02, 2022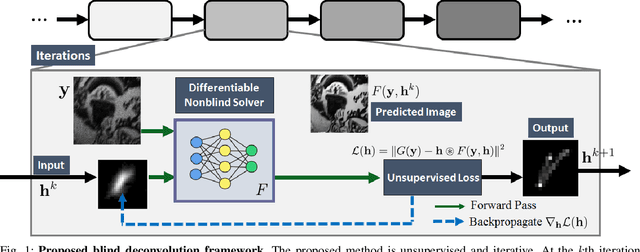
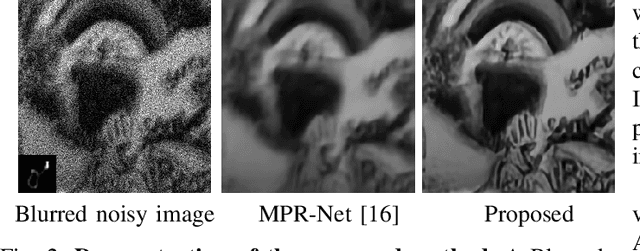
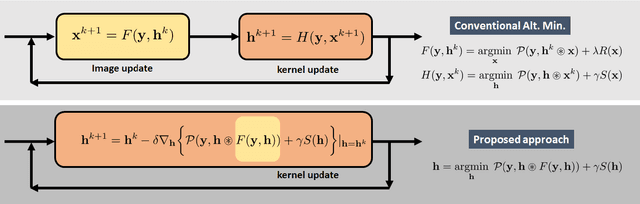
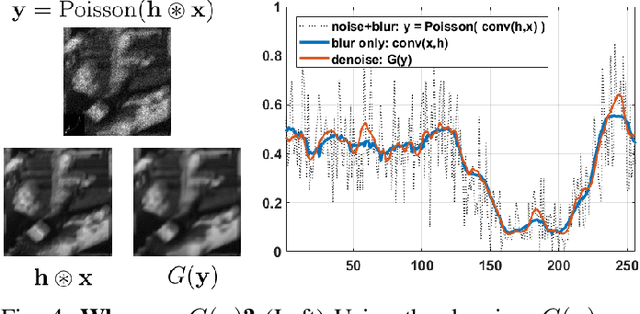
Blind deconvolution in low-light is one of the more challenging problems in image restoration because of the photon shot noise. However, existing algorithms -- both classical and deep-learning based -- are not designed for this condition. When the shot noise is strong, conventional deconvolution methods fail because (1) the presence of noise makes the estimation of the blur kernel difficult; (2) generic deep-restoration models rarely model the forward process explicitly; (3) there are currently no iterative strategies to incorporate a non-blind solver in a kernel estimation stage. This paper addresses these challenges by presenting an unsupervised blind deconvolution method. At the core of this method is a reformulation of the general blind deconvolution framework from the conventional image-kernel alternating minimization to a purely kernel-based minimization. This kernel-based minimization leads to a new iterative scheme that backpropagates an unsupervised loss through a pre-trained non-blind solver to update the blur kernel. Experimental results show that the proposed framework achieves superior results than state-of-the-art blind deconvolution algorithms in low-light conditions.