 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
MGTR: End-to-End Mutual Gaze Detection with Transformer
Sep 22, 2022
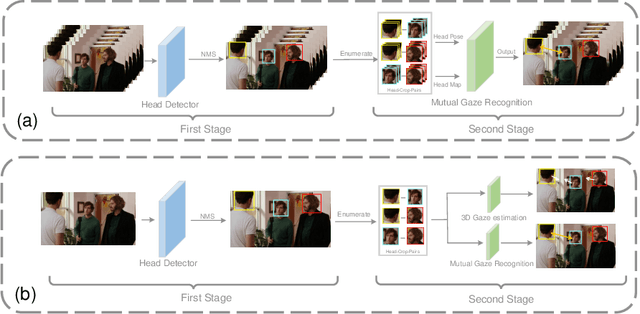
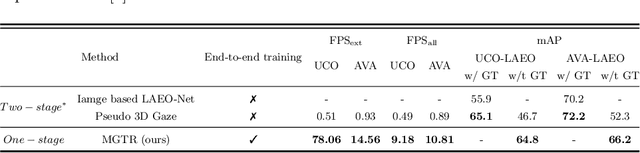
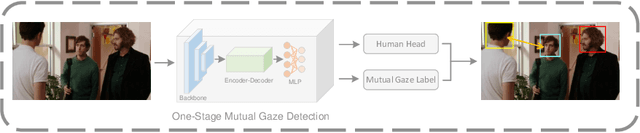
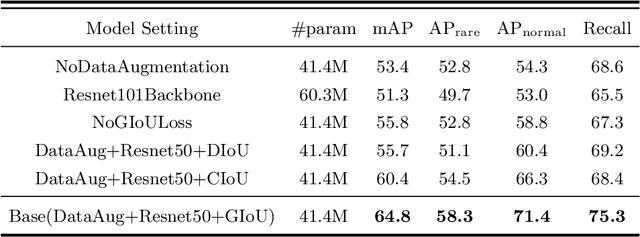
People's looking at each other or mutual gaze is ubiquitous in our daily interactions, and detecting mutual gaze is of great significance for understanding human social scenes. Current mutual gaze detection methods focus on two-stage methods, whose inference speed is limited by the two-stage pipeline and the performance in the second stage is affected by the first one. In this paper, we propose a novel one-stage mutual gaze detection framework called Mutual Gaze TRansformer or MGTR to perform mutual gaze detection in an end-to-end manner. By designing mutual gaze instance triples, MGTR can detect each human head bounding box and simultaneously infer mutual gaze relationship based on global image information, which streamlines the whole process with simplicity. Experimental results on two mutual gaze datasets show that our method is able to accelerate mutual gaze detection process without losing performance. Ablation study shows that different components of MGTR can capture different levels of semantic information in images. Code is available at https://github.com/Gmbition/MGTR
Semantic Segmentation using Neural Ordinary Differential Equations
Sep 18, 2022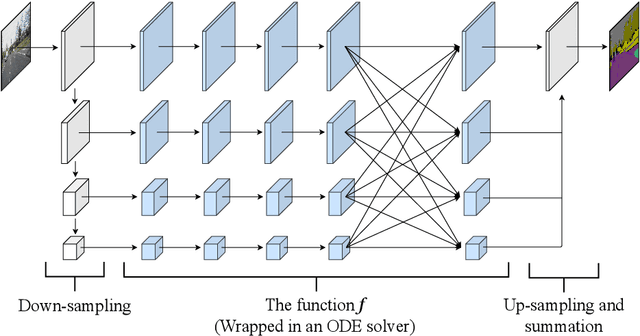
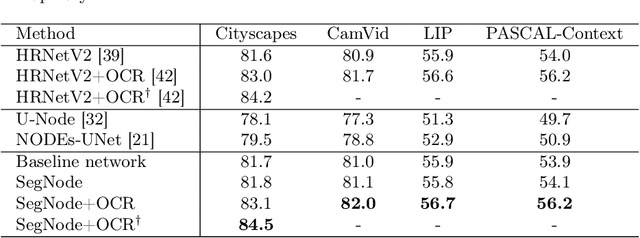

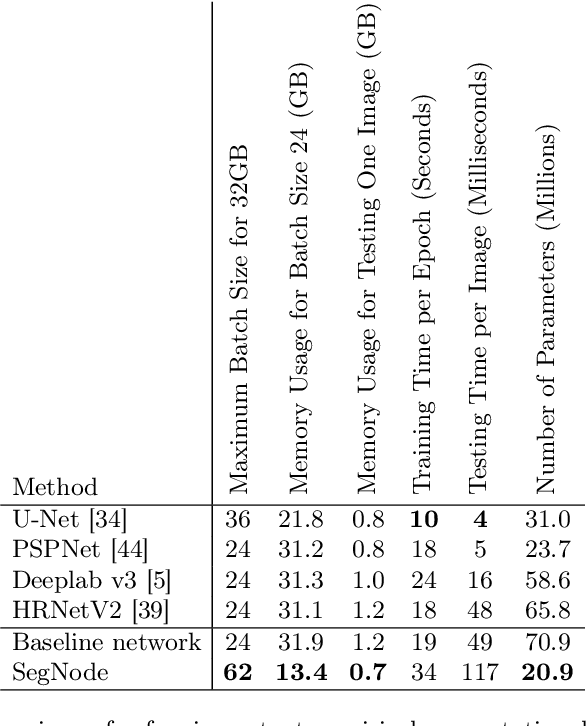
The idea of neural Ordinary Differential Equations (ODE) is to approximate the derivative of a function (data model) instead of the function itself. In residual networks, instead of having a discrete sequence of hidden layers, the derivative of the continuous dynamics of hidden state can be parameterized by an ODE. It has been shown that this type of neural network is able to produce the same results as an equivalent residual network for image classification. In this paper, we design a novel neural ODE for the semantic segmentation task. We start by a baseline network that consists of residual modules, then we use the modules to build our neural ODE network. We show that our neural ODE is able to achieve the state-of-the-art results using 57% less memory for training, 42% less memory for testing, and 68% less number of parameters. We evaluate our model on the Cityscapes, CamVid, LIP, and PASCAL-Context datasets.
Robustness Certification of Visual Perception Models via Camera Motion Smoothing
Oct 04, 2022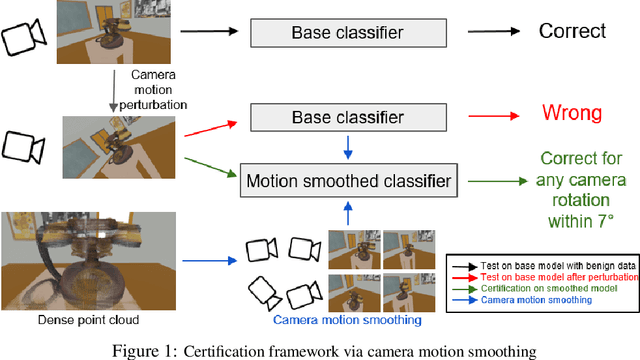
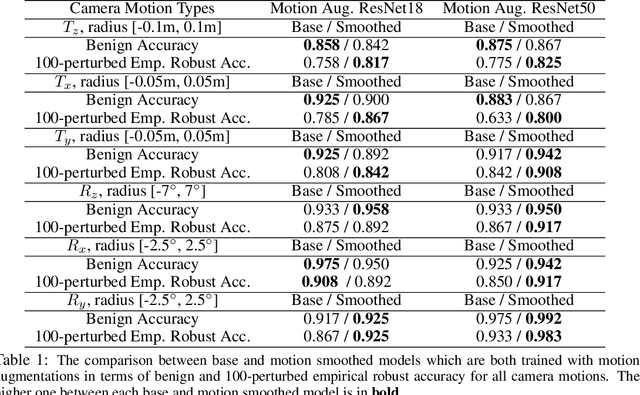
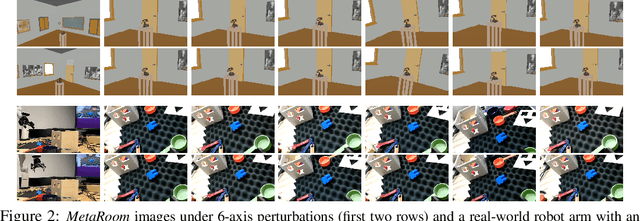
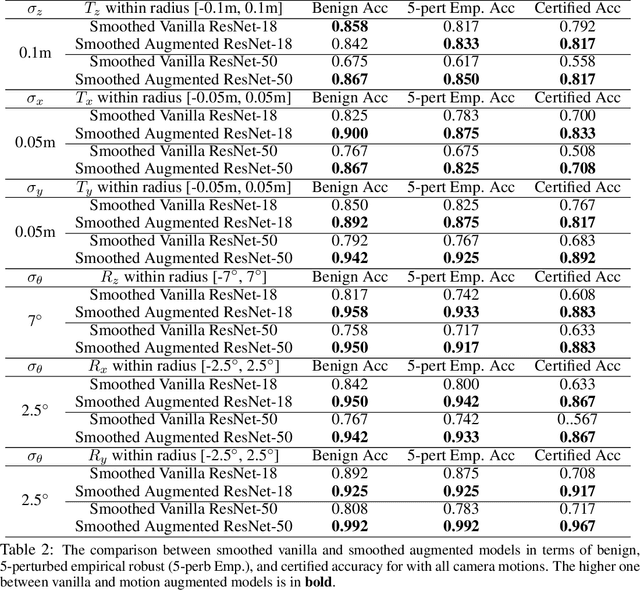
A vast literature shows that the learning-based visual perception model is sensitive to adversarial noises but few works consider the robustness of robotic perception models under widely-existing camera motion perturbations. To this end, we study the robustness of the visual perception model under camera motion perturbations to investigate the influence of camera motion on robotic perception. Specifically, we propose a motion smoothing technique for arbitrary image classification models, whose robustness under camera motion perturbations could be certified. The proposed robustness certification framework based on camera motion smoothing provides tight and scalable robustness guarantees for visual perception modules so that they are applicable to wide robotic applications. As far as we are aware, this is the first work to provide the robustness certification for the deep perception module against camera motions, which improves the trustworthiness of robotic perception. A realistic indoor robotic dataset with the dense point cloud map for the entire room, MetaRoom, is introduced for the challenging certifiable robust perception task. We conduct extensive experiments to validate the certification approach via motion smoothing against camera motion perturbations. Our framework guarantees the certified accuracy of 81.7% against camera translation perturbation along depth direction within -0.1m ` 0.1m. We also validate the effectiveness of our method on the real-world robot by conducting hardware experiment on the robotic arm with an eye-in-hand camera. The code is available on https://github.com/HanjiangHu/camera-motion-smoothing.
SwarMan: Anthropomorphic Swarm of Drones Avatar with Body Tracking and Deep Learning-Based Gesture Recognition
Oct 04, 2022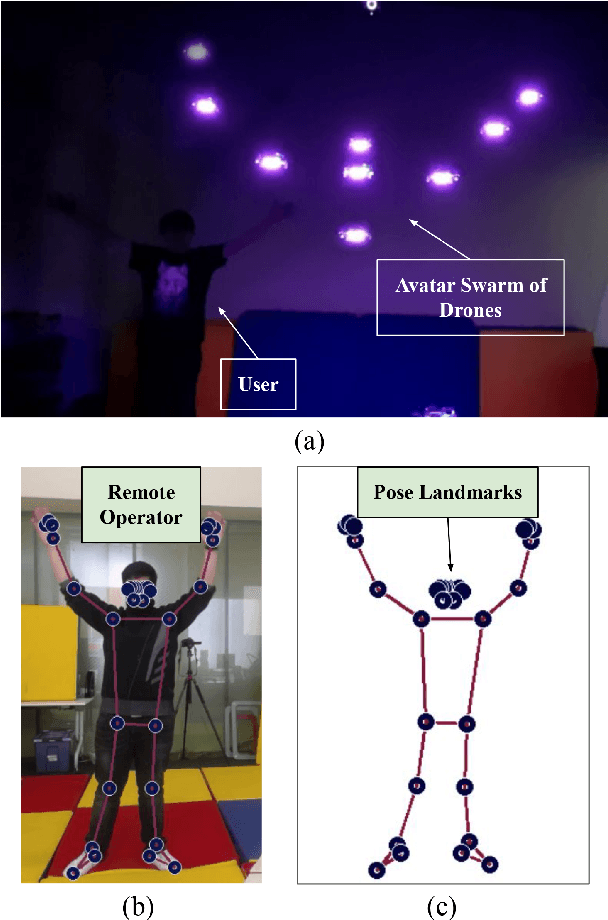
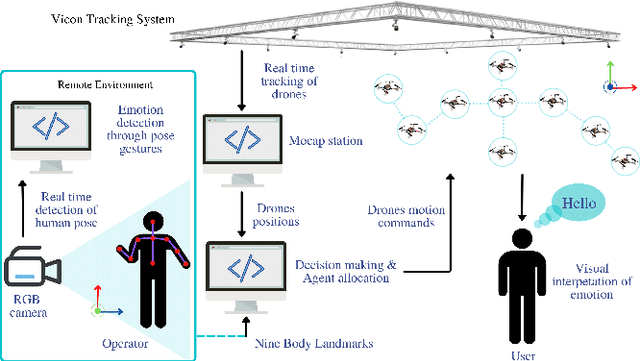
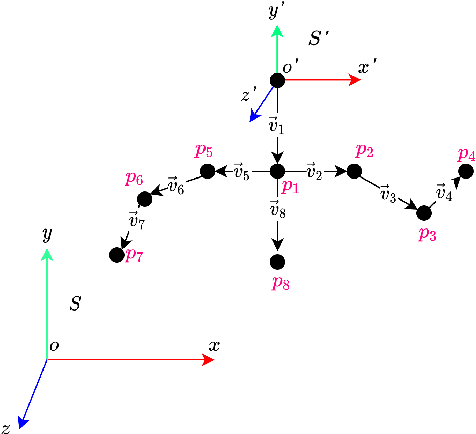
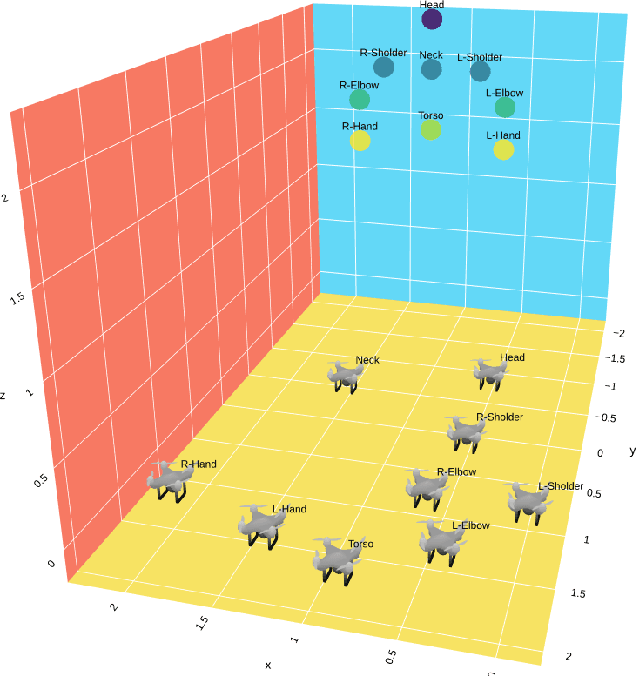
Anthropomorphic robot avatars present a conceptually novel approach to remote affective communication, allowing people across the world a wider specter of emotional and social exchanges over traditional 2D and 3D image data. However, there are several limitations of current telepresence robots, such as the high weight, complexity of the system that prevents its fast deployment, and the limited workspace of the avatars mounted on either static or wheeled mobile platforms. In this paper, we present a novel concept of telecommunication through a robot avatar based on an anthropomorphic swarm of drones; SwarMan. The developed system consists of nine nanocopters controlled remotely by the operator through a gesture recognition interface. SwarMan allows operators to communicate by directly following their motions and by recognizing one of the prerecorded emotional patterns, thus rendering the captured emotion as illumination on the drones. The LSTM MediaPipe network was trained on a collected dataset of 600 short videos with five emotional gestures. The accuracy of achieved emotion recognition was 97% on the test dataset. As communication through the swarm avatar significantly changes the visual appearance of the operator, we investigated the ability of the users to recognize and respond to emotions performed by the swarm of drones. The experimental results revealed a high consistency between the users in rating emotions. Additionally, users indicated low physical demand (2.25 on the Likert scale) and were satisfied with their performance (1.38 on the Likert scale) when communicating by the SwarMan interface.
FaceQgen: Semi-Supervised Deep Learning for Face Image Quality Assessment
Jan 03, 2022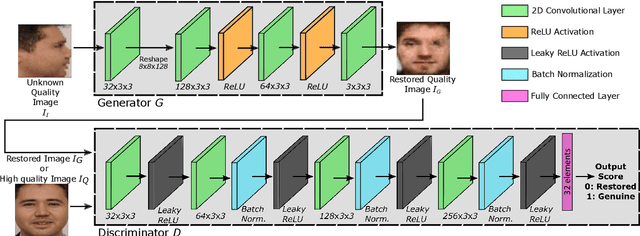
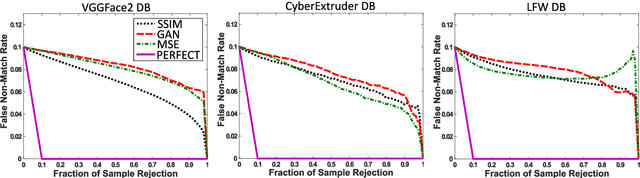
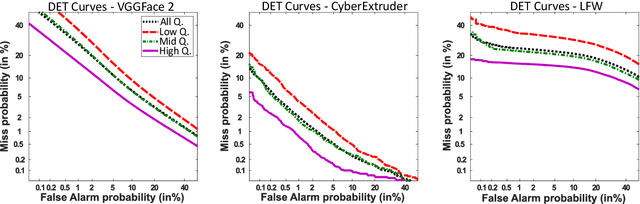
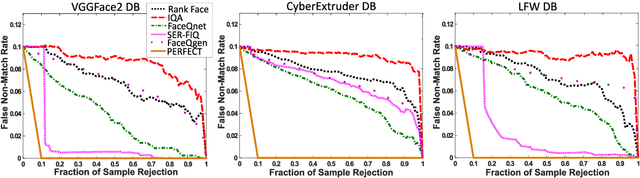
In this paper we develop FaceQgen, a No-Reference Quality Assessment approach for face images based on a Generative Adversarial Network that generates a scalar quality measure related with the face recognition accuracy. FaceQgen does not require labelled quality measures for training. It is trained from scratch using the SCface database. FaceQgen applies image restoration to a face image of unknown quality, transforming it into a canonical high quality image, i.e., frontal pose, homogeneous background, etc. The quality estimation is built as the similarity between the original and the restored images, since low quality images experience bigger changes due to restoration. We compare three different numerical quality measures: a) the MSE between the original and the restored images, b) their SSIM, and c) the output score of the Discriminator of the GAN. The results demonstrate that FaceQgen's quality measures are good estimators of face recognition accuracy. Our experiments include a comparison with other quality assessment methods designed for faces and for general images, in order to position FaceQgen in the state of the art. This comparison shows that, even though FaceQgen does not surpass the best existing face quality assessment methods in terms of face recognition accuracy prediction, it achieves good enough results to demonstrate the potential of semi-supervised learning approaches for quality estimation (in particular, data-driven learning based on a single high quality image per subject), having the capacity to improve its performance in the future with adequate refinement of the model and the significant advantage over competing methods of not needing quality labels for its development. This makes FaceQgen flexible and scalable without expensive data curation.
Dynamic Adaptive Threshold based Learning for Noisy Annotations Robust Facial Expression Recognition
Aug 22, 2022
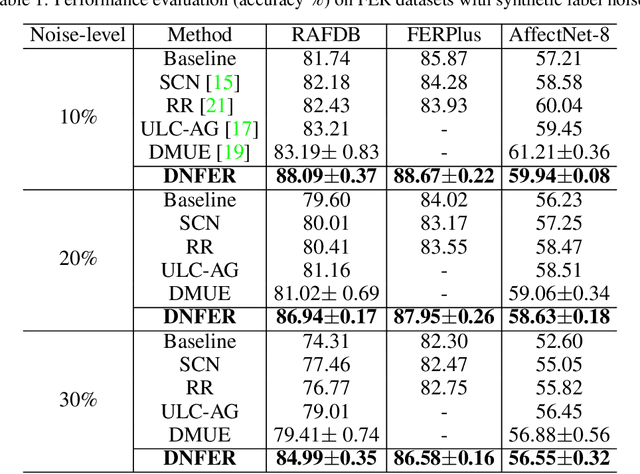
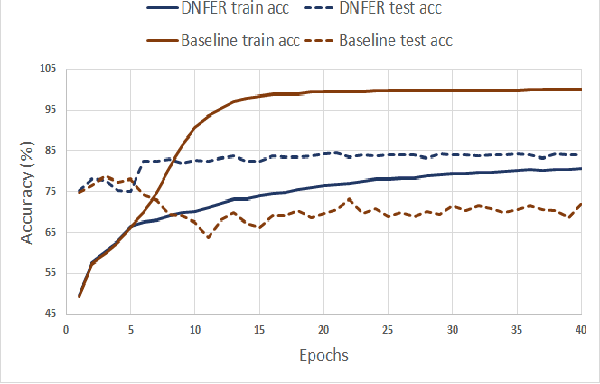
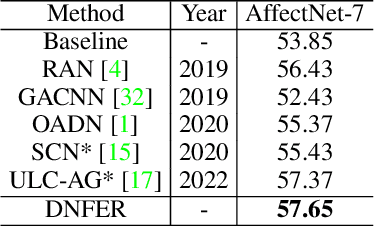
The real-world facial expression recognition (FER) datasets suffer from noisy annotations due to crowd-sourcing, ambiguity in expressions, the subjectivity of annotators and inter-class similarity. However, the recent deep networks have strong capacity to memorize the noisy annotations leading to corrupted feature embedding and poor generalization. To handle noisy annotations, we propose a dynamic FER learning framework (DNFER) in which clean samples are selected based on dynamic class specific threshold during training. Specifically, DNFER is based on supervised training using selected clean samples and unsupervised consistent training using all the samples. During training, the mean posterior class probabilities of each mini-batch is used as dynamic class-specific threshold to select the clean samples for supervised training. This threshold is independent of noise rate and does not need any clean data unlike other methods. In addition, to learn from all samples, the posterior distributions between weakly-augmented image and strongly-augmented image are aligned using an unsupervised consistency loss. We demonstrate the robustness of DNFER on both synthetic as well as on real noisy annotated FER datasets like RAFDB, FERPlus, SFEW and AffectNet.
Neural Contourlet Network for Monocular 360 Depth Estimation
Aug 03, 2022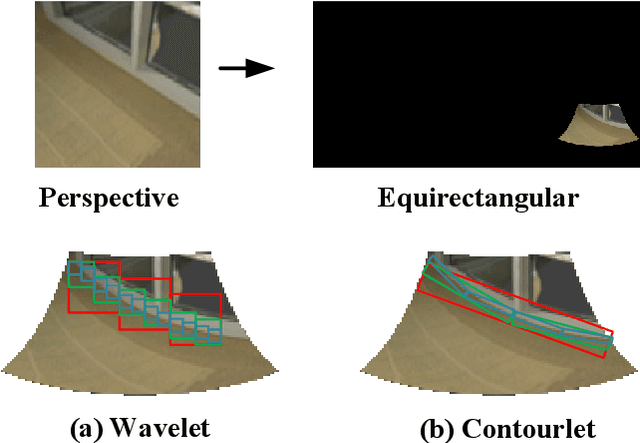


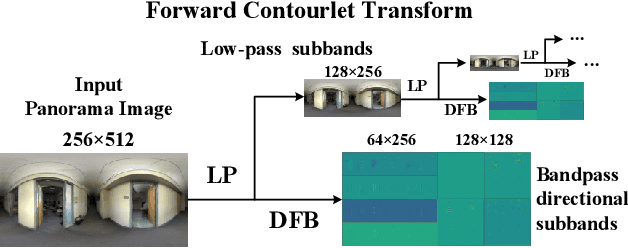
For a monocular 360 image, depth estimation is a challenging because the distortion increases along the latitude. To perceive the distortion, existing methods devote to designing a deep and complex network architecture. In this paper, we provide a new perspective that constructs an interpretable and sparse representation for a 360 image. Considering the importance of the geometric structure in depth estimation, we utilize the contourlet transform to capture an explicit geometric cue in the spectral domain and integrate it with an implicit cue in the spatial domain. Specifically, we propose a neural contourlet network consisting of a convolutional neural network and a contourlet transform branch. In the encoder stage, we design a spatial-spectral fusion module to effectively fuse two types of cues. Contrary to the encoder, we employ the inverse contourlet transform with learned low-pass subbands and band-pass directional subbands to compose the depth in the decoder. Experiments on the three popular panoramic image datasets demonstrate that the proposed approach outperforms the state-of-the-art schemes with faster convergence. Code is available at https://github.com/zhijieshen-bjtu/Neural-Contourlet-Network-for-MODE.
Journalistic Guidelines Aware News Image Captioning
Sep 07, 2021
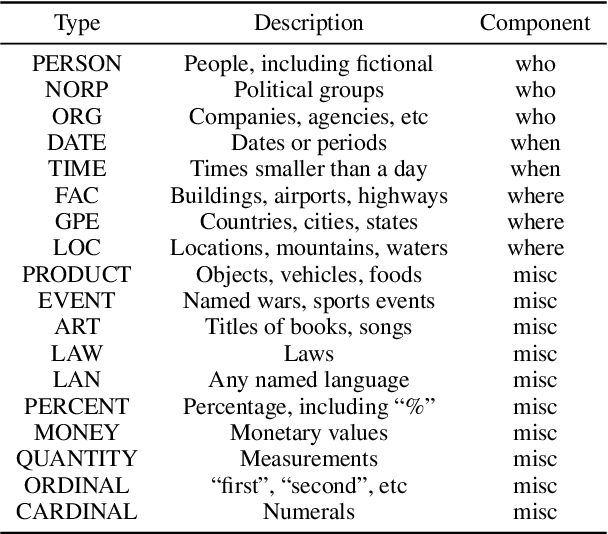

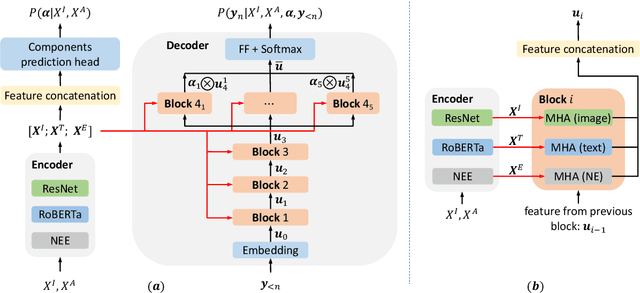
The task of news article image captioning aims to generate descriptive and informative captions for news article images. Unlike conventional image captions that simply describe the content of the image in general terms, news image captions follow journalistic guidelines and rely heavily on named entities to describe the image content, often drawing context from the whole article they are associated with. In this work, we propose a new approach to this task, motivated by caption guidelines that journalists follow. Our approach, Journalistic Guidelines Aware News Image Captioning (JoGANIC), leverages the structure of captions to improve the generation quality and guide our representation design. Experimental results, including detailed ablation studies, on two large-scale publicly available datasets show that JoGANIC substantially outperforms state-of-the-art methods both on caption generation and named entity related metrics.
High-Frequency Space Diffusion Models for Accelerated MRI
Aug 15, 2022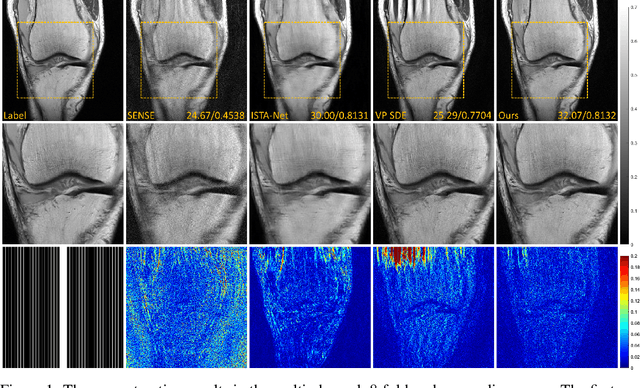
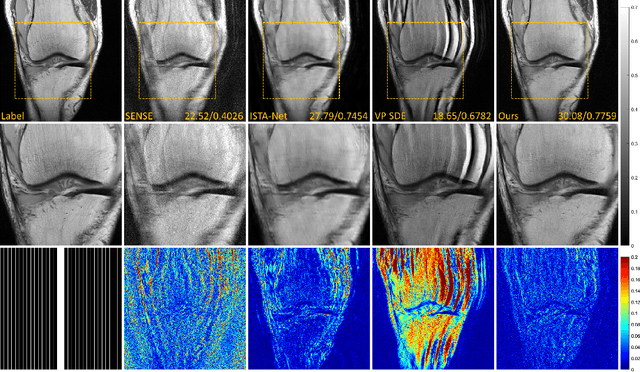
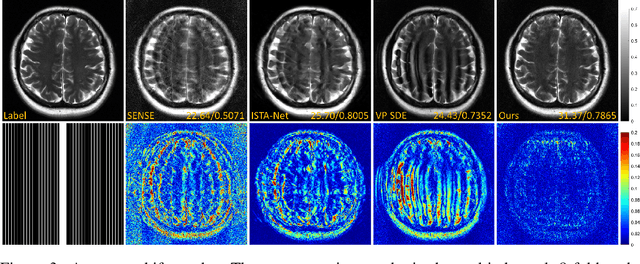
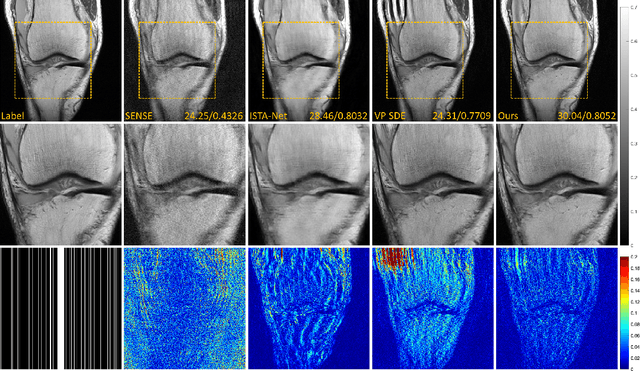
Denoising diffusion probabilistic models (DDPMs) have been shown to have superior performances in MRI reconstruction. From the perspective of continuous stochastic differential equations (SDEs), the reverse process of DDPM can be seen as maximizing the energy of the reconstructed MR image, leading to SDE sequence divergence. For this reason, a modified high-frequency DDPM model is proposed for MRI reconstruction. From its continuous SDE viewpoint, termed high-frequency space SDE (HFS-SDE), the energy concentrated low-frequency part of the MR image is no longer amplified, and the diffusion process focuses more on acquiring high-frequency prior information. It not only improves the stability of the diffusion model but also provides the possibility of better recovery of high-frequency details. Experiments on the publicly fastMRI dataset show that our proposed HFS-SDE outperforms the DDPM-driven VP-SDE, supervised deep learning methods and traditional parallel imaging methods in terms of stability and reconstruction accuracy.
Exploring Cross-Domain Pretrained Model for Hyperspectral Image Classification
Apr 07, 2022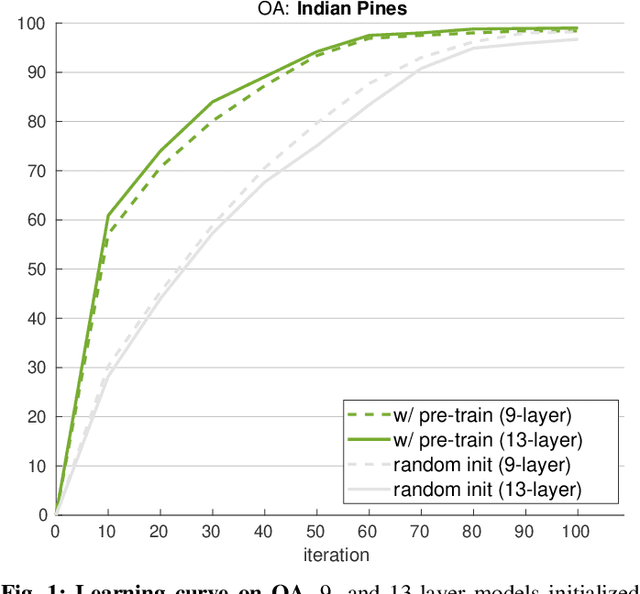
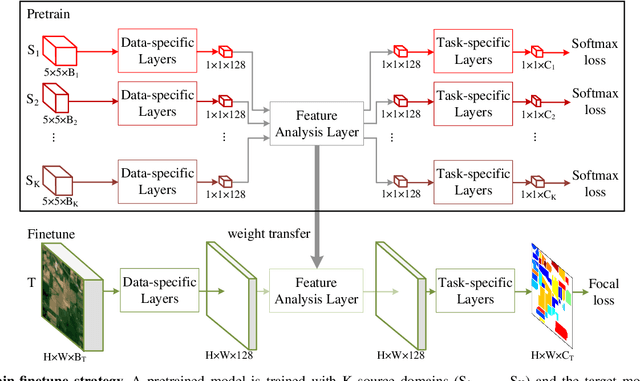
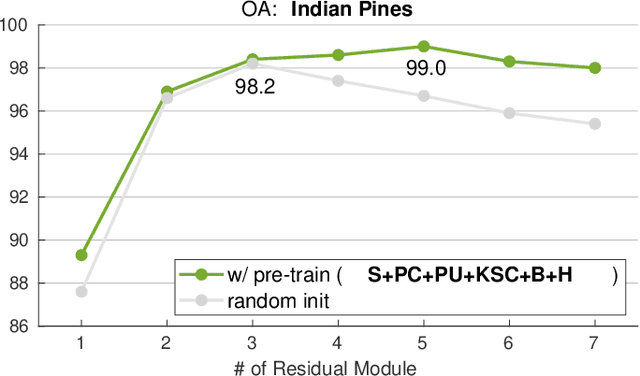
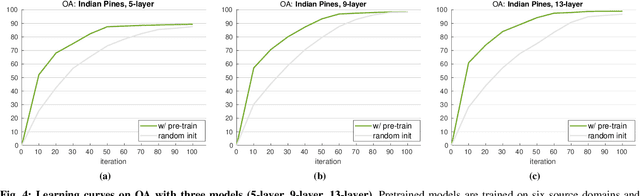
A pretrain-finetune strategy is widely used to reduce the overfitting that can occur when data is insufficient for CNN training. First few layers of a CNN pretrained on a large-scale RGB dataset are capable of acquiring general image characteristics which are remarkably effective in tasks targeted for different RGB datasets. However, when it comes down to hyperspectral domain where each domain has its unique spectral properties, the pretrain-finetune strategy no longer can be deployed in a conventional way while presenting three major issues: 1) inconsistent spectral characteristics among the domains (e.g., frequency range), 2) inconsistent number of data channels among the domains, and 3) absence of large-scale hyperspectral dataset. We seek to train a universal cross-domain model which can later be deployed for various spectral domains. To achieve, we physically furnish multiple inlets to the model while having a universal portion which is designed to handle the inconsistent spectral characteristics among different domains. Note that only the universal portion is used in the finetune process. This approach naturally enables the learning of our model on multiple domains simultaneously which acts as an effective workaround for the issue of the absence of large-scale dataset. We have carried out a study to extensively compare models that were trained using cross-domain approach with ones trained from scratch. Our approach was found to be superior both in accuracy and in training efficiency. In addition, we have verified that our approach effectively reduces the overfitting issue, enabling us to deepen the model up to 13 layers (from 9) without compromising the accuracy.