 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Semi-supervised Deep Learning for Image Classification with Distribution Mismatch: A Survey
Mar 10, 2022

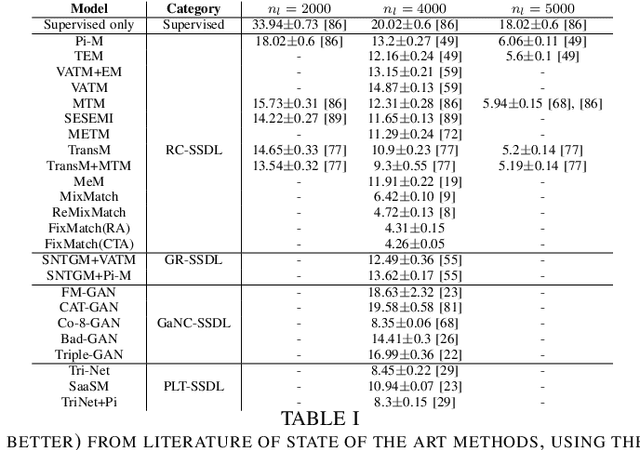
Deep learning methodologies have been employed in several different fields, with an outstanding success in image recognition applications, such as material quality control, medical imaging, autonomous driving, etc. Deep learning models rely on the abundance of labelled observations to train a prospective model. These models are composed of millions of parameters to estimate, increasing the need of more training observations. Frequently it is expensive to gather labelled observations of data, making the usage of deep learning models not ideal, as the model might over-fit data. In a semi-supervised setting, unlabelled data is used to improve the levels of accuracy and generalization of a model with small labelled datasets. Nevertheless, in many situations different unlabelled data sources might be available. This raises the risk of a significant distribution mismatch between the labelled and unlabelled datasets. Such phenomena can cause a considerable performance hit to typical semi-supervised deep learning frameworks, which often assume that both labelled and unlabelled datasets are drawn from similar distributions. Therefore, in this paper we study the latest approaches for semi-supervised deep learning for image recognition. Emphasis is made in semi-supervised deep learning models designed to deal with a distribution mismatch between the labelled and unlabelled datasets. We address open challenges with the aim to encourage the community to tackle them, and overcome the high data demand of traditional deep learning pipelines under real-world usage settings.
DiffusionCLIP: Text-guided Image Manipulation Using Diffusion Models
Oct 06, 2021
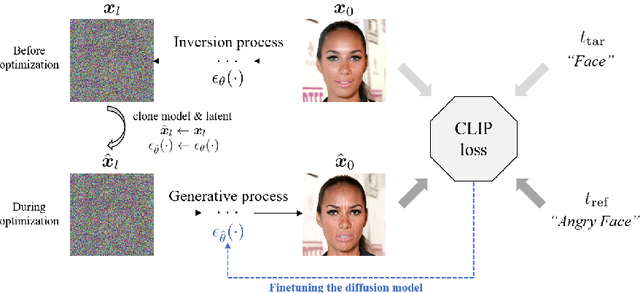

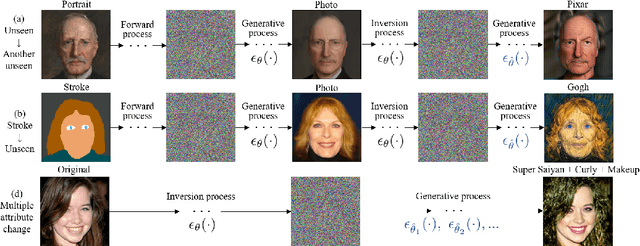
Diffusion models are recent generative models that have shown great success in image generation with the state-of-the-art performance. However, only a few researches have been conducted for image manipulation with diffusion models. Here, we present a novel DiffusionCLIP which performs text-driven image manipulation with diffusion models using Contrastive Language-Image Pre-training (CLIP) loss. Our method has a performance comparable to that of the modern GAN-based image processing methods for in and out-of-domain image processing tasks, with the advantage of almost perfect inversion even without additional encoders or optimization. Furthermore, our method can be easily used for various novel applications, enabling image translation from an unseen domain to another unseen domain or stroke-conditioned image generation in an unseen domain, etc. Finally, we present a novel multiple attribute control with DiffusionCLIPby combining multiple fine-tuned diffusion models.
Visual correspondence-based explanations improve AI robustness and human-AI team accuracy
Aug 02, 2022
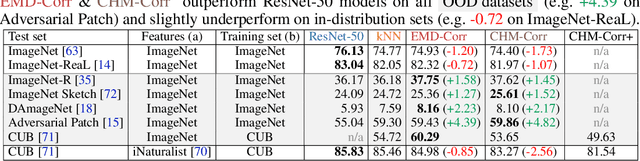

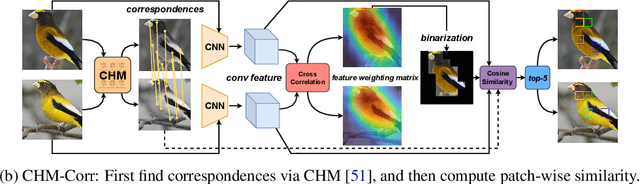
Explaining artificial intelligence (AI) predictions is increasingly important and even imperative in many high-stakes applications where humans are the ultimate decision-makers. In this work, we propose two novel architectures of self-interpretable image classifiers that first explain, and then predict (as opposed to post-hoc explanations) by harnessing the visual correspondences between a query image and exemplars. Our models consistently improve (by 1 to 4 points) on out-of-distribution (OOD) datasets while performing marginally worse (by 1 to 2 points) on in-distribution tests than ResNet-50 and a $k$-nearest neighbor classifier (kNN). Via a large-scale, human study on ImageNet and CUB, our correspondence-based explanations are found to be more useful to users than kNN explanations. Our explanations help users more accurately reject AI's wrong decisions than all other tested methods. Interestingly, for the first time, we show that it is possible to achieve complementary human-AI team accuracy (i.e., that is higher than either AI-alone or human-alone), in ImageNet and CUB image classification tasks.
IOP-FL: Inside-Outside Personalization for Federated Medical Image Segmentation
Apr 16, 2022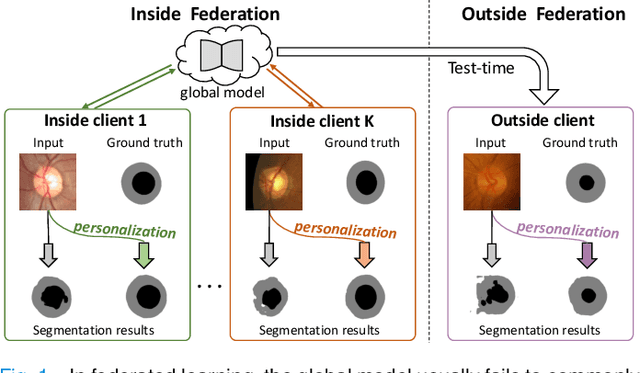
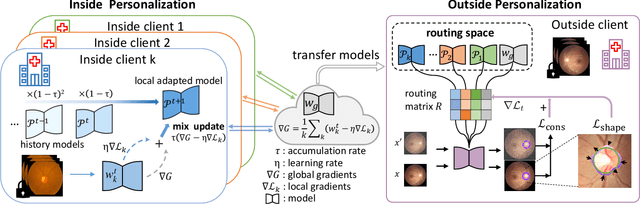
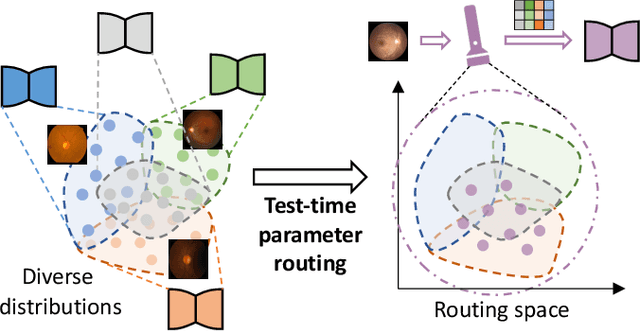
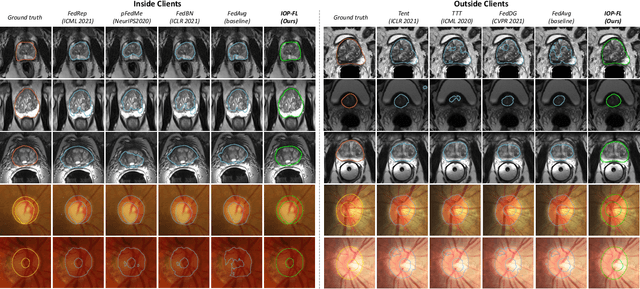
Federated learning (FL) allows multiple medical institutions to collaboratively learn a global model without centralizing all clients data. It is difficult, if possible at all, for such a global model to commonly achieve optimal performance for each individual client, due to the heterogeneity of medical data from various scanners and patient demographics. This problem becomes even more significant when deploying the global model to unseen clients outside the FL with new distributions not presented during federated training. To optimize the prediction accuracy of each individual client for critical medical tasks, we propose a novel unified framework for both Inside and Outside model Personalization in FL (IOP-FL). Our inside personalization is achieved by a lightweight gradient-based approach that exploits the local adapted model for each client, by accumulating both the global gradients for common knowledge and local gradients for client-specific optimization. Moreover, and importantly, the obtained local personalized models and the global model can form a diverse and informative routing space to personalize a new model for outside FL clients. Hence, we design a new test-time routing scheme inspired by the consistency loss with a shape constraint to dynamically incorporate the models, given the distribution information conveyed by the test data. Our extensive experimental results on two medical image segmentation tasks present significant improvements over SOTA methods on both inside and outside personalization, demonstrating the great potential of our IOP-FL scheme for clinical practice. Code will be released at https://github.com/med-air/IOP-FL.
Adverse Weather Image Translation with Asymmetric and Uncertainty-aware GAN
Dec 08, 2021
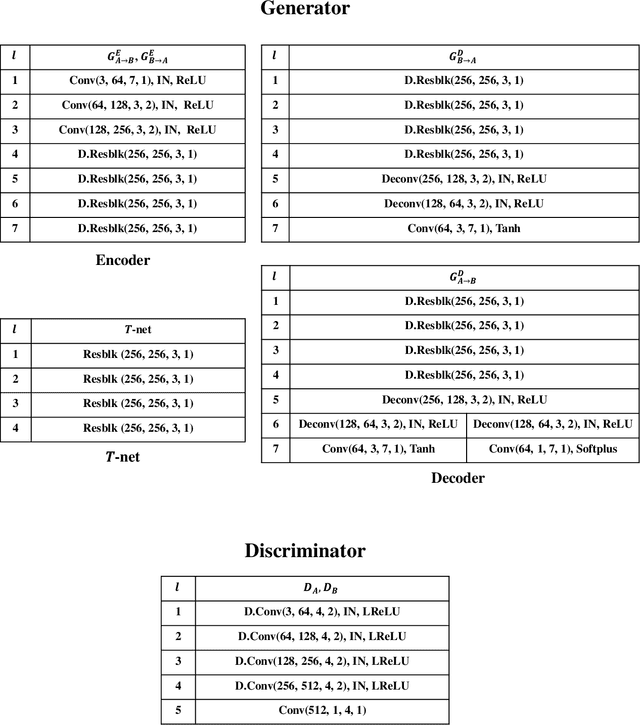


Adverse weather image translation belongs to the unsupervised image-to-image (I2I) translation task which aims to transfer adverse condition domain (eg, rainy night) to standard domain (eg, day). It is a challenging task because images from adverse domains have some artifacts and insufficient information. Recently, many studies employing Generative Adversarial Networks (GANs) have achieved notable success in I2I translation but there are still limitations in applying them to adverse weather enhancement. Symmetric architecture based on bidirectional cycle-consistency loss is adopted as a standard framework for unsupervised domain transfer methods. However, it can lead to inferior translation result if the two domains have imbalanced information. To address this issue, we propose a novel GAN model, i.e., AU-GAN, which has an asymmetric architecture for adverse domain translation. We insert a proposed feature transfer network (${T}$-net) in only a normal domain generator (i.e., rainy night-> day) to enhance encoded features of the adverse domain image. In addition, we introduce asymmetric feature matching for disentanglement of encoded features. Finally, we propose uncertainty-aware cycle-consistency loss to address the regional uncertainty of a cyclic reconstructed image. We demonstrate the effectiveness of our method by qualitative and quantitative comparisons with state-of-the-art models. Codes are available at https://github.com/jgkwak95/AU-GAN.
Content-Aware Differential Privacy with Conditional Invertible Neural Networks
Jul 29, 2022
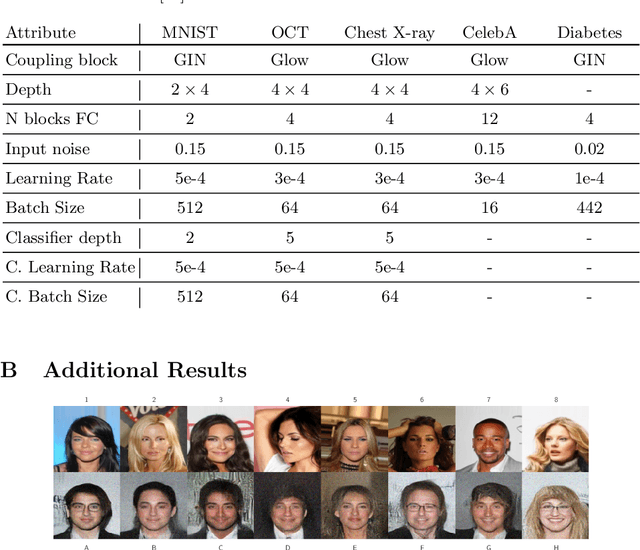
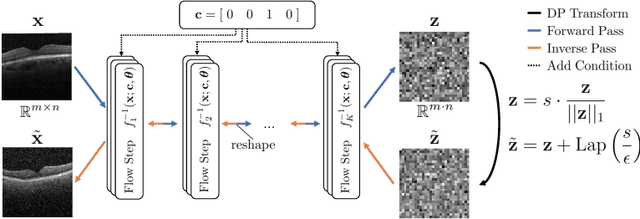

Differential privacy (DP) has arisen as the gold standard in protecting an individual's privacy in datasets by adding calibrated noise to each data sample. While the application to categorical data is straightforward, its usability in the context of images has been limited. Contrary to categorical data the meaning of an image is inherent in the spatial correlation of neighboring pixels making the simple application of noise infeasible. Invertible Neural Networks (INN) have shown excellent generative performance while still providing the ability to quantify the exact likelihood. Their principle is based on transforming a complicated distribution into a simple one e.g. an image into a spherical Gaussian. We hypothesize that adding noise to the latent space of an INN can enable differentially private image modification. Manipulation of the latent space leads to a modified image while preserving important details. Further, by conditioning the INN on meta-data provided with the dataset we aim at leaving dimensions important for downstream tasks like classification untouched while altering other parts that potentially contain identifying information. We term our method content-aware differential privacy (CADP). We conduct experiments on publicly available benchmarking datasets as well as dedicated medical ones. In addition, we show the generalizability of our method to categorical data. The source code is publicly available at https://github.com/Cardio-AI/CADP.
Graph Spatio-Spectral Total Variation Model for Hyperspectral Image Denoising
Jul 22, 2022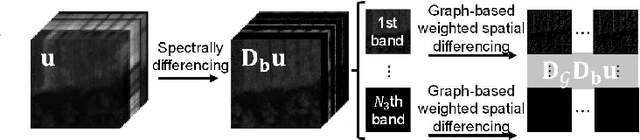


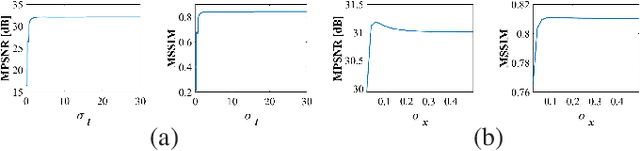
The spatio-spectral total variation (SSTV) model has been widely used as an effective regularization of hyperspectral images (HSI) for various applications such as mixed noise removal. However, since SSTV computes local spatial differences uniformly, it is difficult to remove noise while preserving complex spatial structures with fine edges and textures, especially in situations of high noise intensity. To solve this problem, we propose a new TV-type regularization called Graph-SSTV (GSSTV), which generates a graph explicitly reflecting the spatial structure of the target HSI from noisy HSIs and incorporates a weighted spatial difference operator designed based on this graph. Furthermore, we formulate the mixed noise removal problem as a convex optimization problem involving GSSTV and develop an efficient algorithm based on the primal-dual splitting method to solve this problem. Finally, we demonstrate the effectiveness of GSSTV compared with existing HSI regularization models through experiments on mixed noise removal. The source code will be available at https://www.mdi.c.titech.ac.jp/publications/gsstv.
A Privacy-Preserving Image Retrieval Scheme Using A Codebook Generated From Independent Plain-Image Dataset
Sep 04, 2021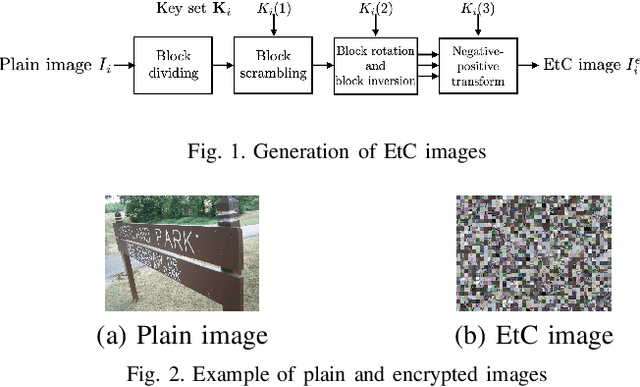
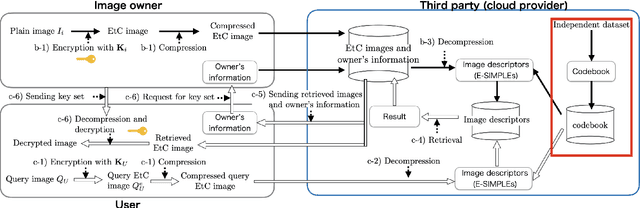

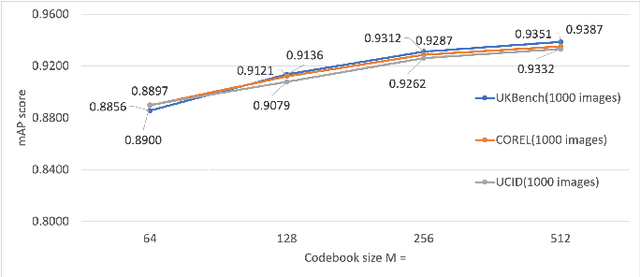
In this paper, we propose a privacy-preserving image-retrieval scheme using a codebook generated by using a plain-image dataset. Encryption-then-compression (EtC) images, which were proposed for EtC systems, have been used in conventional privacy-preserving image-retrieval schemes, in which a codebook is generated from EtC images uploaded by image owners, and extended SIMPLE descriptors are then calculated as image descriptors by using the codebook. In contrast, in the proposed scheme, a codebook is generated from a dataset independent of uploaded images. The use of an independent dataset enables us not only to use a codebook that does not require recalculation but also to constantly provide a high retrieval accuracy. In an experiment, the proposed scheme is demonstrated to maintain a high retrieval performance, even if codebooks are generated from a plain image dataset independent of image owners' encrypted images.
Exploiting Instance-based Mixed Sampling via Auxiliary Source Domain Supervision for Domain-adaptive Action Detection
Oct 06, 2022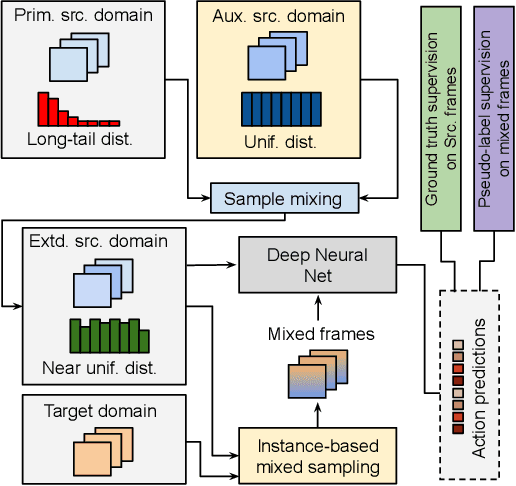
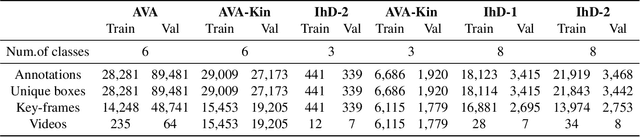
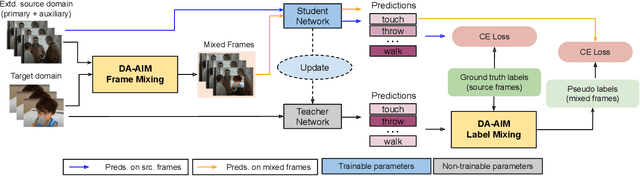
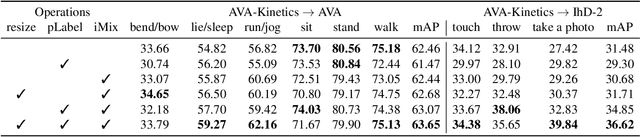
We propose a novel domain adaptive action detection approach and a new adaptation protocol that leverages the recent advancements in image-level unsupervised domain adaptation (UDA) techniques and handle vagaries of instance-level video data. Self-training combined with cross-domain mixed sampling has shown remarkable performance gain in semantic segmentation in UDA (unsupervised domain adaptation) context. Motivated by this fact, we propose an approach for human action detection in videos that transfers knowledge from the source domain (annotated dataset) to the target domain (unannotated dataset) using mixed sampling and pseudo-label-based selftraining. The existing UDA techniques follow a ClassMix algorithm for semantic segmentation. However, simply adopting ClassMix for action detection does not work, mainly because these are two entirely different problems, i.e., pixel-label classification vs. instance-label detection. To tackle this, we propose a novel action instance mixed sampling technique that combines information across domains based on action instances instead of action classes. Moreover, we propose a new UDA training protocol that addresses the long-tail sample distribution and domain shift problem by using supervision from an auxiliary source domain (ASD). For the ASD, we propose a new action detection dataset with dense frame-level annotations. We name our proposed framework as domain-adaptive action instance mixing (DA-AIM). We demonstrate that DA-AIM consistently outperforms prior works on challenging domain adaptation benchmarks. The source code is available at https://github.com/wwwfan628/DA-AIM.
MaPLe: Multi-modal Prompt Learning
Oct 06, 2022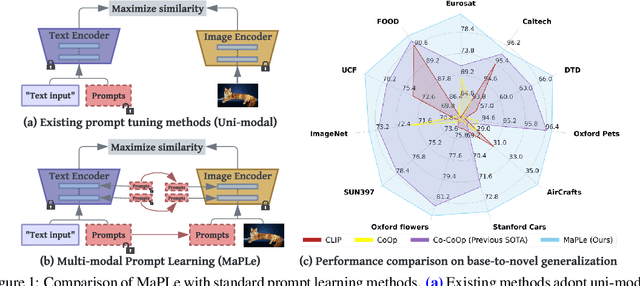
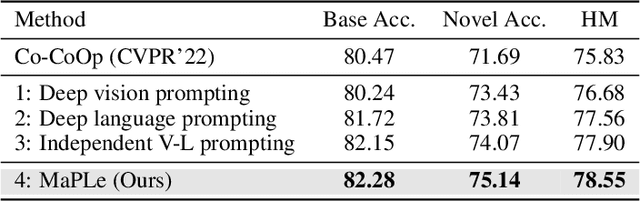
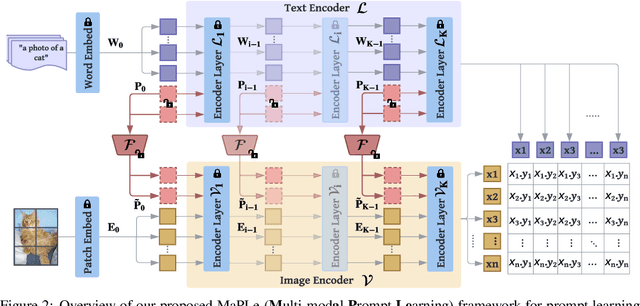
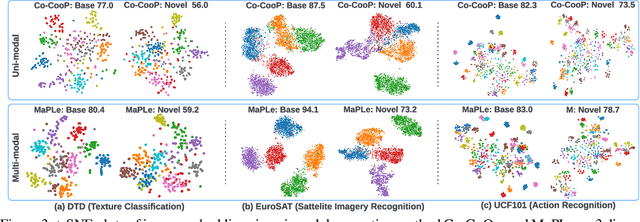
Pre-trained vision-language (V-L) models such as CLIP have shown excellent generalization ability to downstream tasks. However, they are sensitive to the choice of input text prompts and require careful selection of prompt templates to perform well. Inspired by the Natural Language Processing (NLP) literature, recent CLIP adaptation approaches learn prompts as the textual inputs to fine-tune CLIP for downstream tasks. We note that using prompting to adapt representations in a single branch of CLIP (language or vision) is sub-optimal since it does not allow the flexibility to dynamically adjust both representation spaces on a downstream task. In this work, we propose Multi-modal Prompt Learning (MaPLe) for both vision and language branches to improve alignment between the vision and language representations. Our design promotes strong coupling between the vision-language prompts to ensure mutual synergy and discourages learning independent uni-modal solutions. Further, we learn separate prompts across different early stages to progressively model the stage-wise feature relationships to allow rich context learning. We evaluate the effectiveness of our approach on three representative tasks of generalization to novel classes, new target datasets and unseen domain shifts. Compared with the state-of-the-art method Co-CoOp, MaPLe exhibits favorable performance and achieves an absolute gain of 3.45% on novel classes and 2.72% on overall harmonic-mean, averaged over 11 diverse image recognition datasets. Code: https://tinyurl.com/2dzs8f3w.