 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Tunable Image Quality Control of 3-D Ultrasound using Switchable CycleGAN
Dec 06, 2021
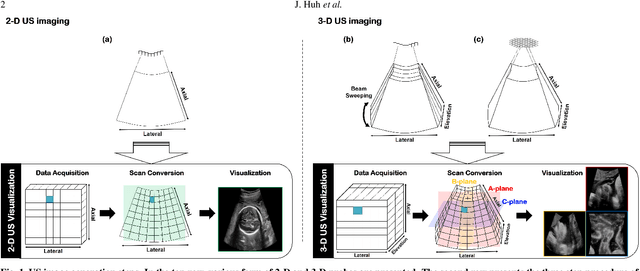
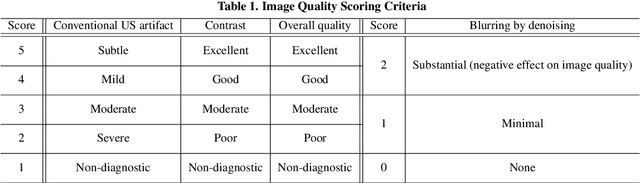
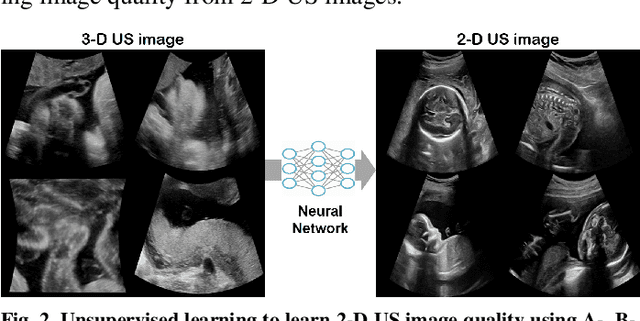
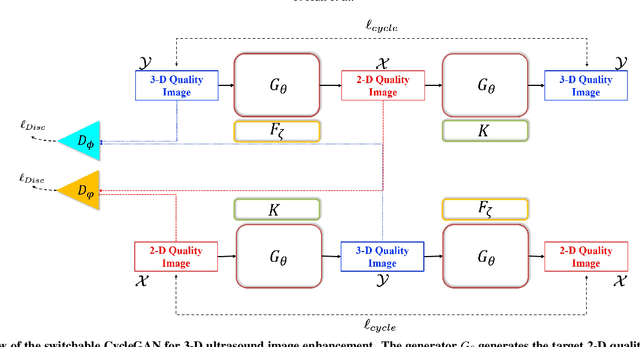
In contrast to 2-D ultrasound (US) for uniaxial plane imaging, a 3-D US imaging system can visualize a volume along three axial planes. This allows for a full view of the anatomy, which is useful for gynecological (GYN) and obstetrical (OB) applications. Unfortunately, the 3-D US has an inherent limitation in resolution compared to the 2-D US. In the case of 3-D US with a 3-D mechanical probe, for example, the image quality is comparable along the beam direction, but significant deterioration in image quality is often observed in the other two axial image planes. To address this, here we propose a novel unsupervised deep learning approach to improve 3-D US image quality. In particular, using {\em unmatched} high-quality 2-D US images as a reference, we trained a recently proposed switchable CycleGAN architecture so that every mapping plane in 3-D US can learn the image quality of 2-D US images. Thanks to the switchable architecture, our network can also provide real-time control of image enhancement level based on user preference, which is ideal for a user-centric scanner setup. Extensive experiments with clinical evaluation confirm that our method offers significantly improved image quality as well user-friendly flexibility.
Maximal Independent Vertex Set applied to Graph Pooling
Aug 02, 2022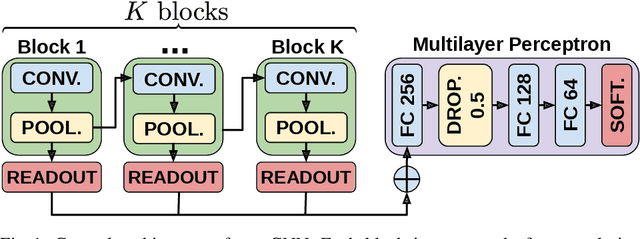
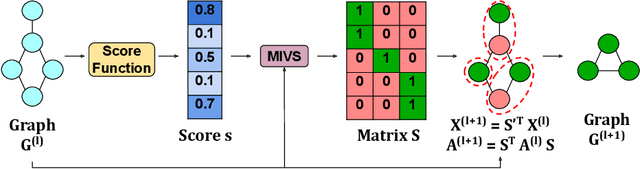

Convolutional neural networks (CNN) have enabled major advances in image classification through convolution and pooling. In particular, image pooling transforms a connected discrete grid into a reduced grid with the same connectivity and allows reduction functions to take into account all the pixels of an image. However, a pooling satisfying such properties does not exist for graphs. Indeed, some methods are based on a vertex selection step which induces an important loss of information. Other methods learn a fuzzy clustering of vertex sets which induces almost complete reduced graphs. We propose to overcome both problems using a new pooling method, named MIVSPool. This method is based on a selection of vertices called surviving vertices using a Maximal Independent Vertex Set (MIVS) and an assignment of the remaining vertices to the survivors. Consequently, our method does not discard any vertex information nor artificially increase the density of the graph. Experimental results show an increase in accuracy for graph classification on various standard datasets.
Generative Steganography Network
Aug 14, 2022
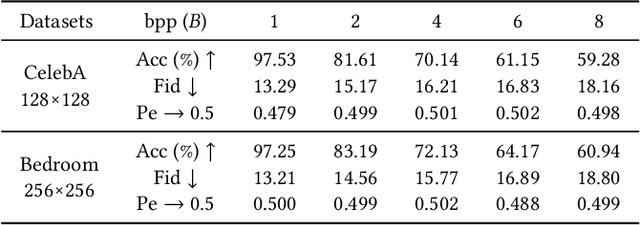
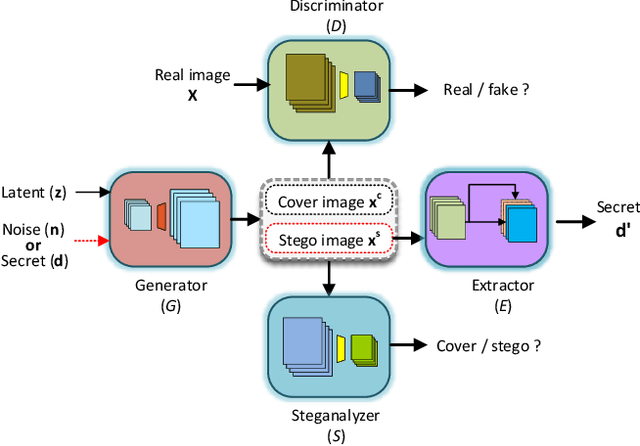
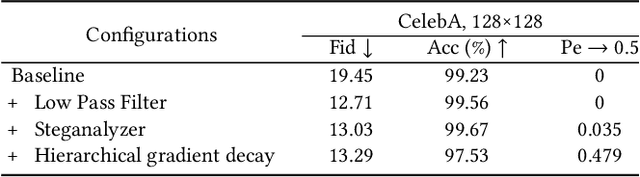
Steganography usually modifies cover media to embed secret data. A new steganographic approach called generative steganography (GS) has emerged recently, in which stego images (images containing secret data) are generated from secret data directly without cover media. However, existing GS schemes are often criticized for their poor performances. In this paper, we propose an advanced generative steganography network (GSN) that can generate realistic stego images without using cover images. We firstly introduce the mutual information mechanism in GS, which helps to achieve high secret extraction accuracy. Our model contains four sub-networks, i.e., an image generator ($G$), a discriminator ($D$), a steganalyzer ($S$), and a data extractor ($E$). $D$ and $S$ act as two adversarial discriminators to ensure the visual quality and security of generated stego images. $E$ is to extract the hidden secret from generated stego images. The generator $G$ is flexibly constructed to synthesize either cover or stego images with different inputs. It facilitates covert communication by concealing the function of generating stego images in a normal generator. A module named secret block is designed to hide secret data in the feature maps during image generation, with which high hiding capacity and image fidelity are achieved. In addition, a novel hierarchical gradient decay (HGD) skill is developed to resist steganalysis detection. Experiments demonstrate the superiority of our work over existing methods.
Underwater Image Enhancement Using Convolutional Neural Network
Sep 18, 2021This work proposes a method for underwater image enhancement using the principle of histogram equalization. Since underwater images have a global strong dominant colour, their colourfulness and contrast are often degraded. Before applying the histogram equalisation technique on the image, the image is converted from coloured image to a gray scale image for further operations. Histogram equalization is a technique for adjusting image intensities to enhance contrast. The colours of the image are retained using a convolutional neural network model which is trained by the datasets of underwater images to give better results.
Im2Oil: Stroke-Based Oil Painting Rendering with Linearly Controllable Fineness Via Adaptive Sampling
Sep 27, 2022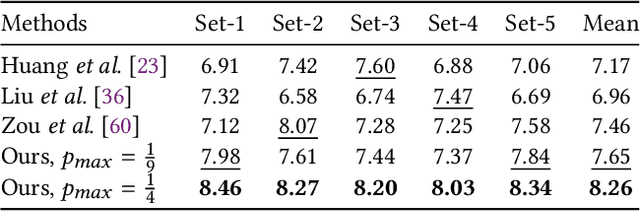



This paper proposes a novel stroke-based rendering (SBR) method that translates images into vivid oil paintings. Previous SBR techniques usually formulate the oil painting problem as pixel-wise approximation. Different from this technique route, we treat oil painting creation as an adaptive sampling problem. Firstly, we compute a probability density map based on the texture complexity of the input image. Then we use the Voronoi algorithm to sample a set of pixels as the stroke anchors. Next, we search and generate an individual oil stroke at each anchor. Finally, we place all the strokes on the canvas to obtain the oil painting. By adjusting the hyper-parameter maximum sampling probability, we can control the oil painting fineness in a linear manner. Comparison with existing state-of-the-art oil painting techniques shows that our results have higher fidelity and more realistic textures. A user opinion test demonstrates that people behave more preference toward our oil paintings than the results of other methods. More interesting results and the code are in https://github.com/TZYSJTU/Im2Oil.
Self-adversarial Multi-scale Contrastive Learning for Semantic Segmentation of Thermal Facial Images
Sep 21, 2022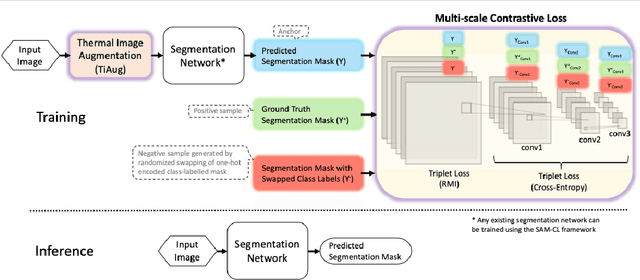
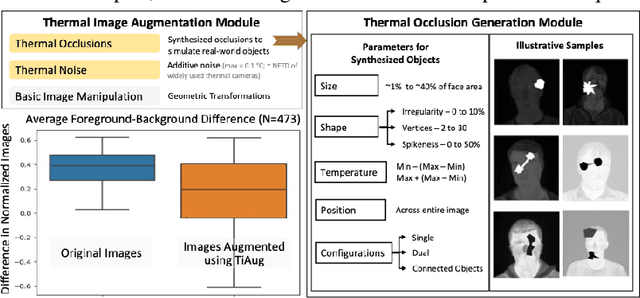
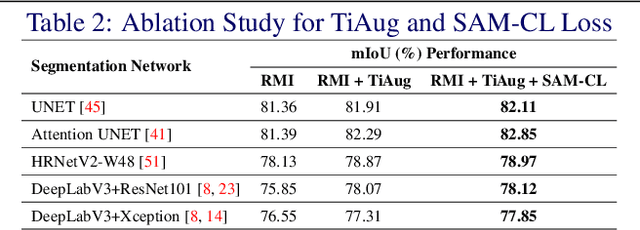
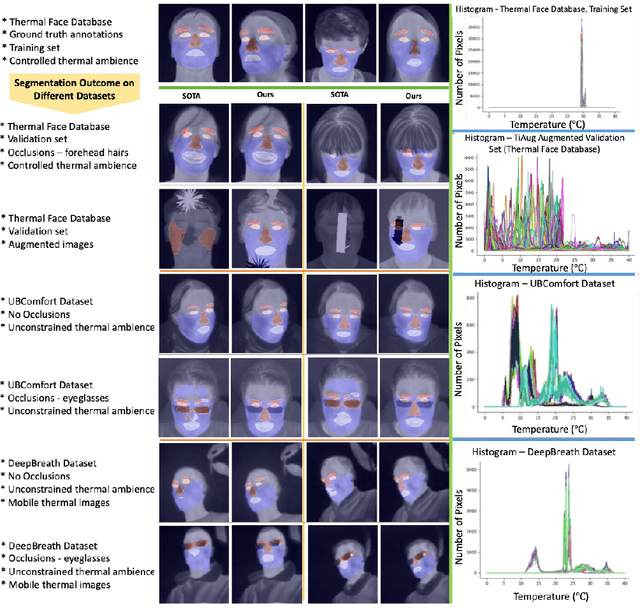
Reliable segmentation of thermal facial images in unconstrained settings such as thermal ambience and occlusions is challenging as facial features lack salience. Limited availability of datasets from such settings further makes it difficult to train segmentation networks. To address the challenge, we propose Self-Adversarial Multi-scale Contrastive Learning (SAM-CL) as a generic learning framework to train segmentation networks. SAM-CL framework constitutes SAM-CL loss function and a thermal image augmentation (TiAug) as a domain-specific augmentation technique to simulate unconstrained settings based upon existing datasets collected from controlled settings. We use the Thermal-Face-Database to demonstrate effectiveness of our approach. Experiments conducted on the existing segmentation networks- UNET, Attention-UNET, DeepLabV3 and HRNetv2 evidence the consistent performance gain from the SAM-CL framework. Further, we present a qualitative analysis with UBComfort and DeepBreath datasets to discuss how our proposed methods perform in handling unconstrained situations.
FETA: Towards Specializing Foundation Models for Expert Task Applications
Sep 08, 2022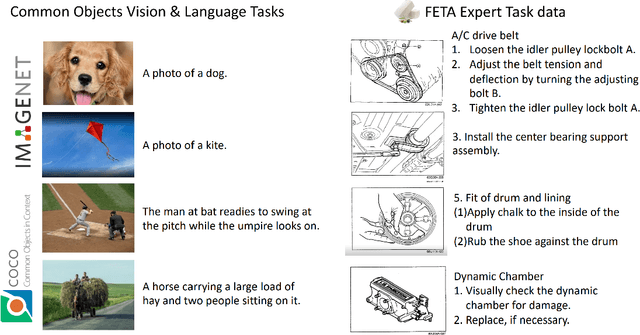

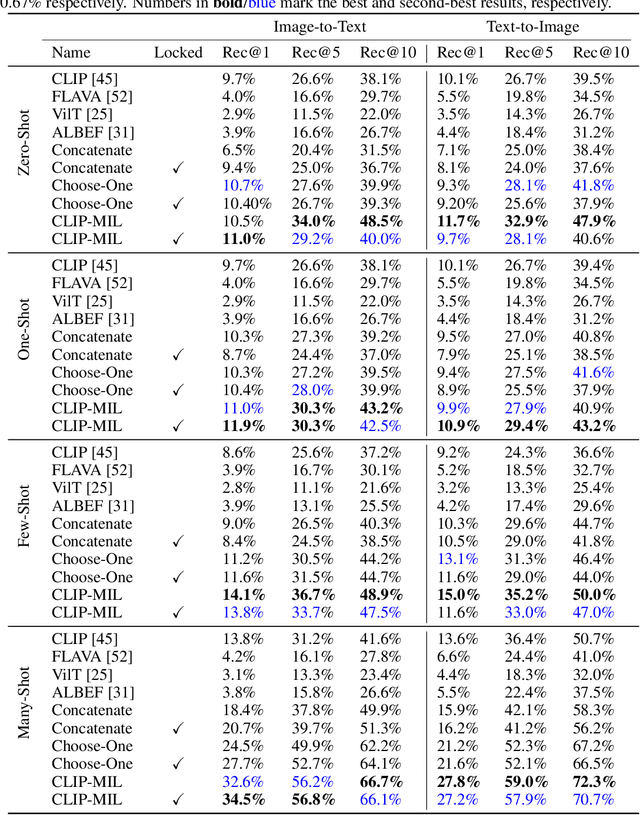
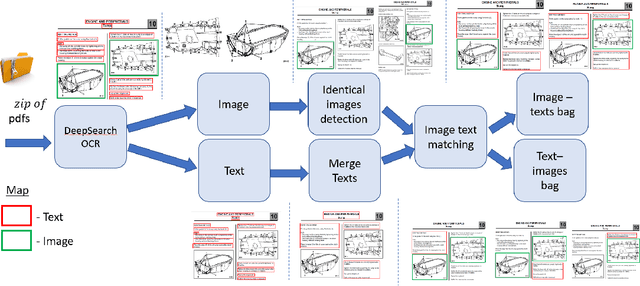
Foundation Models (FMs) have demonstrated unprecedented capabilities including zero-shot learning, high fidelity data synthesis, and out of domain generalization. However, as we show in this paper, FMs still have poor out-of-the-box performance on expert tasks (e.g. retrieval of car manuals technical illustrations from language queries), data for which is either unseen or belonging to a long-tail part of the data distribution of the huge datasets used for FM pre-training. This underlines the necessity to explicitly evaluate and finetune FMs on such expert tasks, arguably ones that appear the most in practical real-world applications. In this paper, we propose a first of its kind FETA benchmark built around the task of teaching FMs to understand technical documentation, via learning to match their graphical illustrations to corresponding language descriptions. Our FETA benchmark focuses on text-to-image and image-to-text retrieval in public car manuals and sales catalogue brochures. FETA is equipped with a procedure for completely automatic annotation extraction (code would be released upon acceptance), allowing easy extension of FETA to more documentation types and application domains in the future. Our automatic annotation leads to an automated performance metric shown to be consistent with metrics computed on human-curated annotations (also released). We provide multiple baselines and analysis of popular FMs on FETA leading to several interesting findings that we believe would be very valuable to the FM community, paving the way towards real-world application of FMs for practical expert tasks currently 'overlooked' by standard benchmarks focusing on common objects.
Deep Cervix Model Development from Heterogeneous and Partially Labeled Image Datasets
Jan 18, 2022Cervical cancer is the fourth most common cancer in women worldwide. The availability of a robust automated cervical image classification system can augment the clinical care provider's limitation in traditional visual inspection with acetic acid (VIA). However, there are a wide variety of cervical inspection objectives which impact the labeling criteria for criteria-specific prediction model development. Moreover, due to the lack of confirmatory test results and inter-rater labeling variation, many images are left unlabeled. Motivated by these challenges, we propose a self-supervised learning (SSL) based approach to produce a pre-trained cervix model from unlabeled cervical images. The developed model is further fine-tuned to produce criteria-specific classification models with the available labeled images. We demonstrate the effectiveness of the proposed approach using two cervical image datasets. Both datasets are partially labeled and labeling criteria are different. The experimental results show that the SSL-based initialization improves classification performance (Accuracy: 2.5% min) and the inclusion of images from both datasets during SSL further improves the performance (Accuracy: 1.5% min). Further, considering data-sharing restrictions, we experimented with the effectiveness of Federated SSL and find that it can improve performance over the SSL model developed with just its images. This justifies the importance of SSL-based cervix model development. We believe that the present research shows a novel direction in developing criteria-specific custom deep models for cervical image classification by combining images from different sources unlabeled and/or labeled with varying criteria, and addressing image access restrictions.
There is a Time and Place for Reasoning Beyond the Image
Mar 01, 2022
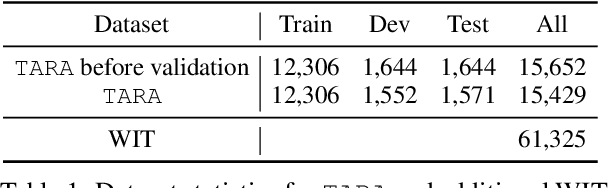

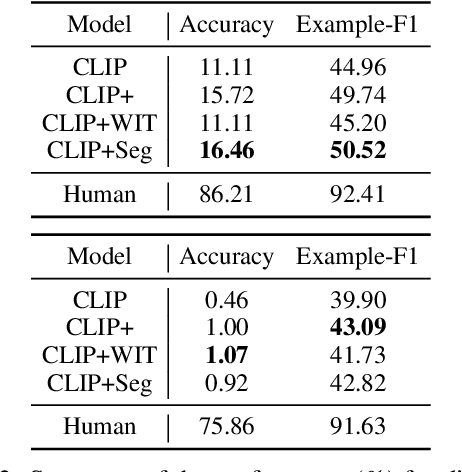
Images are often more significant than only the pixels to human eyes, as we can infer, associate, and reason with contextual information from other sources to establish a more complete picture. For example, in Figure 1, we can find a way to identify the news articles related to the picture through segment-wise understandings on the signs, the buildings, the crowds, and more. This tells us the time when and the location where the image is taken, which will help us in subsequent tasks, such as evidence retrieval for criminal activities, automatic storyline construction, and upper-stream processing such as image clustering. In this work, we formulate this problem and introduce TARA: a dataset with 16k images with their associated news, time and location automatically extracted from New York Times (NYT), and an additional 61k examples as distant supervision from WIT. On top of the extractions, we present a crowdsourced subset in which images are believed to be feasible to find their spatio-temporal information for evaluation purpose. We show that there exists a 70% gap between a state-of-the-art joint model and human performance, which is slightly filled by our proposed model that uses segment-wise reasoning, motivating higher-level vision-language joint models that can conduct open-ended reasoning with world knowledge.
UPB at SemEval-2022 Task 5: Enhancing UNITER with Image Sentiment and Graph Convolutional Networks for Multimedia Automatic Misogyny Identification
May 29, 2022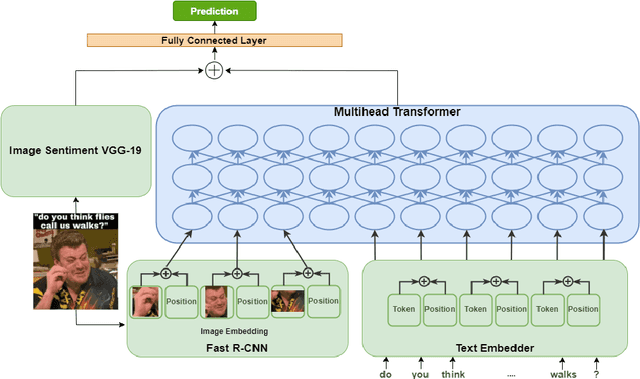
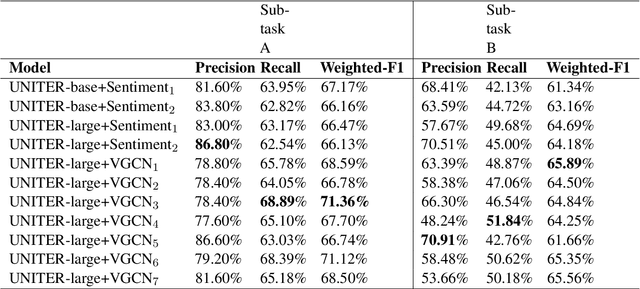
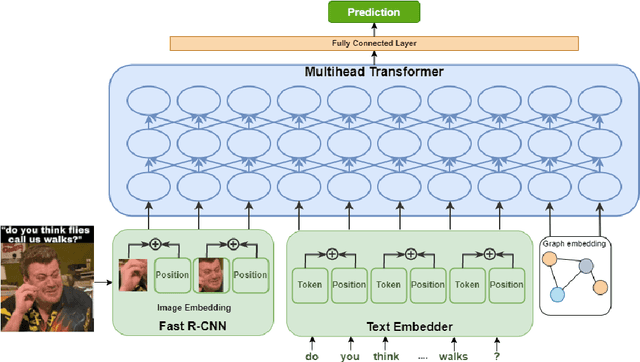

In recent times, the detection of hate-speech, offensive, or abusive language in online media has become an important topic in NLP research due to the exponential growth of social media and the propagation of such messages, as well as their impact. Misogyny detection, even though it plays an important part in hate-speech detection, has not received the same attention. In this paper, we describe our classification systems submitted to the SemEval-2022 Task 5: MAMI - Multimedia Automatic Misogyny Identification. The shared task aimed to identify misogynous content in a multi-modal setting by analysing meme images together with their textual captions. To this end, we propose two models based on the pre-trained UNITER model, one enhanced with an image sentiment classifier, whereas the second leverages a Vocabulary Graph Convolutional Network (VGCN). Additionally, we explore an ensemble using the aforementioned models. Our best model reaches an F1-score of 71.4% in Sub-task A and 67.3% for Sub-task B positioning our team in the upper third of the leaderboard. We release the code and experiments for our models on GitHub