 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
PatchDropout: Economizing Vision Transformers Using Patch Dropout
Aug 10, 2022
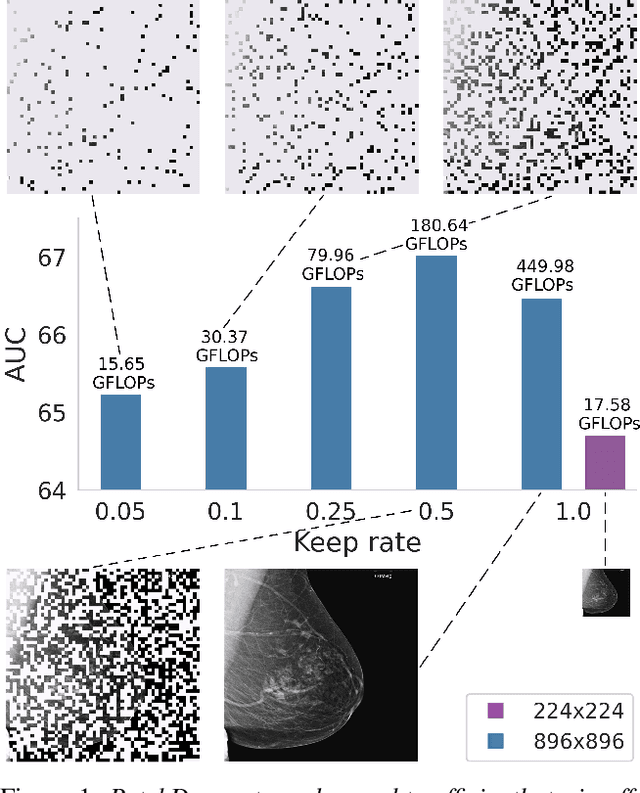
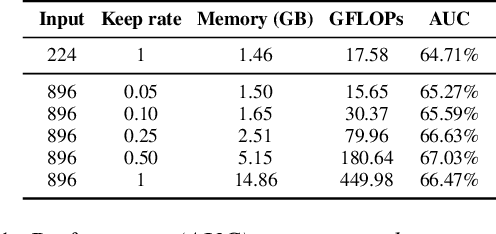
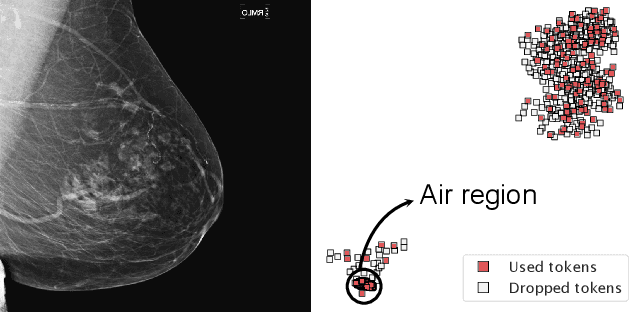
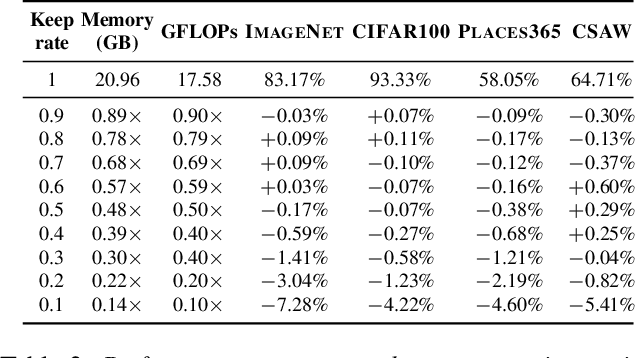
Vision transformers have demonstrated the potential to outperform CNNs in a variety of vision tasks. But the computational and memory requirements of these models prohibit their use in many applications, especially those that depend on high-resolution images, such as medical image classification. Efforts to train ViTs more efficiently are overly complicated, necessitating architectural changes or intricate training schemes. In this work, we show that standard ViT models can be efficiently trained at high resolution by randomly dropping input image patches. This simple approach, PatchDropout, reduces FLOPs and memory by at least 50% in standard natural image datasets such as ImageNet, and those savings only increase with image size. On CSAW, a high-resolution medical dataset, we observe a 5 times savings in computation and memory using PatchDropout, along with a boost in performance. For practitioners with a fixed computational or memory budget, PatchDropout makes it possible to choose image resolution, hyperparameters, or model size to get the most performance out of their model.
Automatic Diagnosis of Myocarditis Disease in Cardiac MRI Modality using Deep Transformers and Explainable Artificial Intelligence
Oct 26, 2022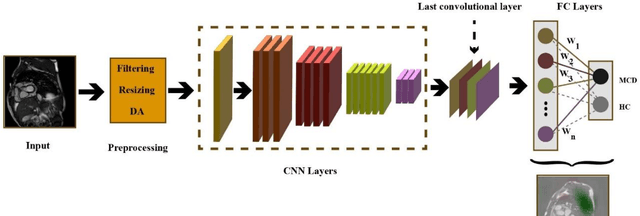
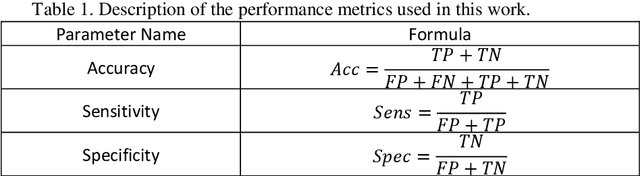
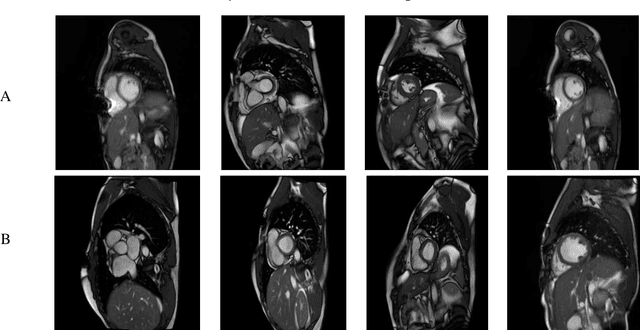
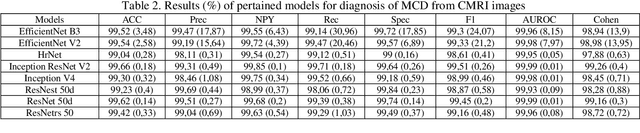
Myocarditis is among the most important cardiovascular diseases (CVDs), endangering the health of many individuals by damaging the myocardium. Microbes and viruses, such as HIV, play a vital role in myocarditis disease (MCD) incidence. Lack of MCD diagnosis in the early stages is associated with irreversible complications. Cardiac magnetic resonance imaging (CMRI) is highly popular among cardiologists to diagnose CVDs. In this paper, a deep learning (DL) based computer-aided diagnosis system (CADS) is presented for the diagnosis of MCD using CMRI images. The proposed CADS includes dataset, preprocessing, feature extraction, classification, and post-processing steps. First, the Z-Alizadeh dataset was selected for the experiments. The preprocessing step included noise removal, image resizing, and data augmentation (DA). In this step, CutMix, and MixUp techniques were used for the DA. Then, the most recent pre-trained and transformers models were used for feature extraction and classification using CMRI images. Our results show high performance for the detection of MCD using transformer models compared with the pre-trained architectures. Among the DL architectures, Turbulence Neural Transformer (TNT) architecture achieved an accuracy of 99.73% with 10-fold cross-validation strategy. Explainable-based Grad Cam method is used to visualize the MCD suspected areas in CMRI images.
S2MS: Self-Supervised Learning Driven Multi-Spectral CT Image Enhancement
Jan 25, 2022
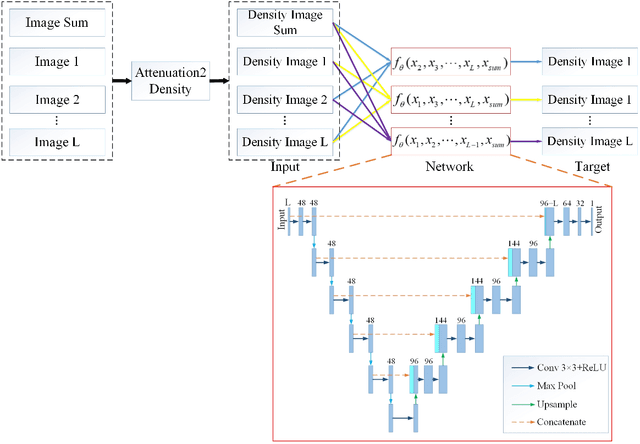
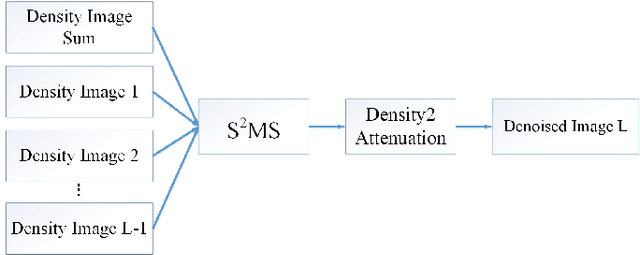
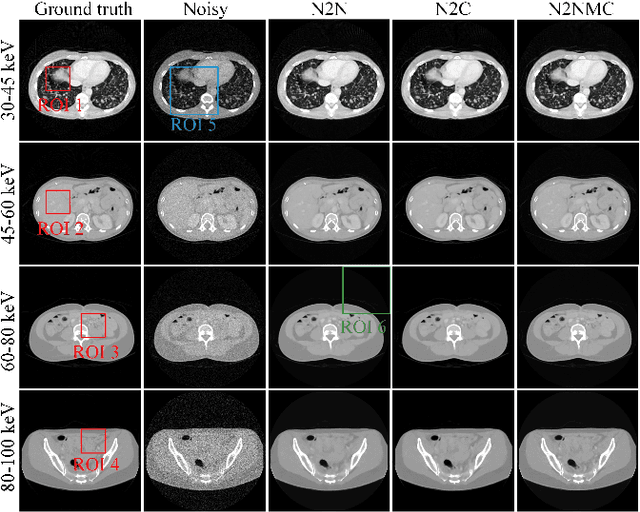
Photon counting spectral CT (PCCT) can produce reconstructed attenuation maps in different energy channels, reflecting energy properties of the scanned object. Due to the limited photon numbers and the non-ideal detector response of each energy channel, the reconstructed images usually contain much noise. With the development of Deep Learning (DL) technique, different kinds of DL-based models have been proposed for noise reduction. However, most of the models require clean data set as the training labels, which are not always available in medical imaging field. Inspiring by the similarities of each channel's reconstructed image, we proposed a self-supervised learning based PCCT image enhancement framework via multi-spectral channels (S2MS). In S2MS framework, both the input and output labels are noisy images. Specifically, one single channel image was used as output while images of other single channels and channel-sum image were used as input to train the network, which can fully use the spectral data information without extra cost. The simulation results based on the AAPM Low-dose CT Challenge database showed that the proposed S2MS model can suppress the noise and preserve details more effectively in comparison with the traditional DL models, which has potential to improve the image quality of PCCT in clinical applications.
Learning from Attacks: Attacking Variational Autoencoder for Improving Image Classification
Mar 11, 2022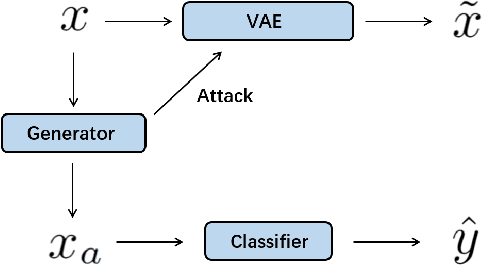
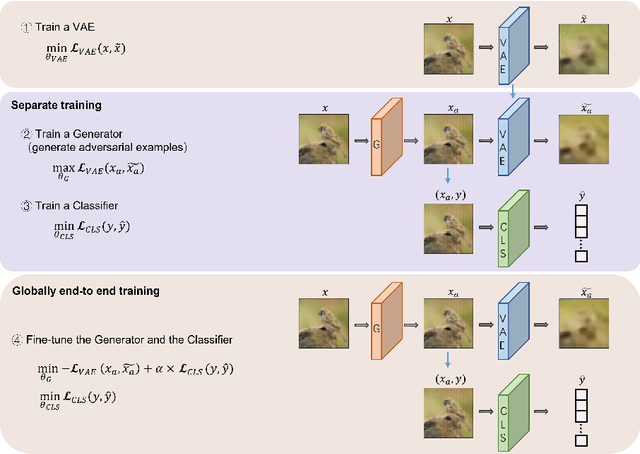
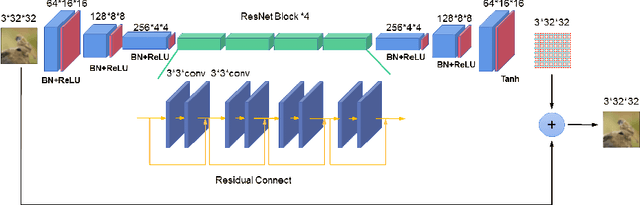
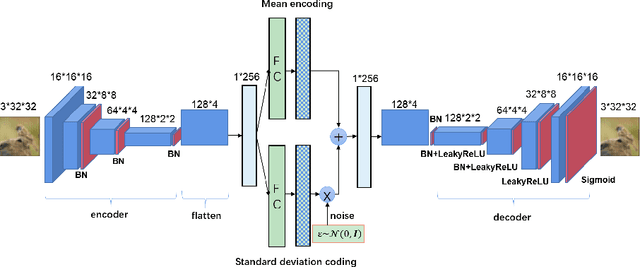
Adversarial attacks are often considered as threats to the robustness of Deep Neural Networks (DNNs). Various defending techniques have been developed to mitigate the potential negative impact of adversarial attacks against task predictions. This work analyzes adversarial attacks from a different perspective. Namely, adversarial examples contain implicit information that is useful to the predictions i.e., image classification, and treat the adversarial attacks against DNNs for data self-expression as extracted abstract representations that are capable of facilitating specific learning tasks. We propose an algorithmic framework that leverages the advantages of the DNNs for data self-expression and task-specific predictions, to improve image classification. The framework jointly learns a DNN for attacking Variational Autoencoder (VAE) networks and a DNN for classification, coined as Attacking VAE for Improve Classification (AVIC). The experiment results show that AVIC can achieve higher accuracy on standard datasets compared to the training with clean examples and the traditional adversarial training.
How to scale hyperparameters for quickshift image segmentation
Jan 23, 2022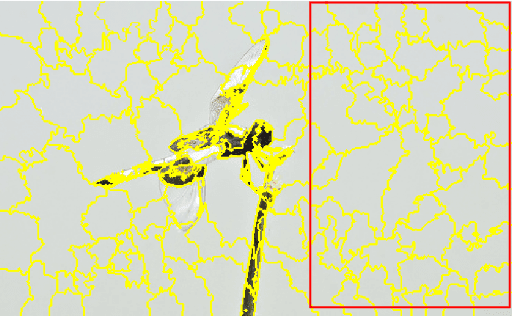

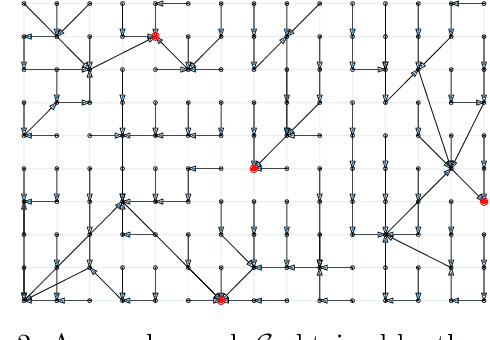
Quickshift is a popular algorithm for image segmentation, used as a preprocessing step in many applications. Unfortunately, it is quite challenging to understand the hyperparameters' influence on the number and shape of superpixels produced by the method. In this paper, we study theoretically a slightly modified version of the quickshift algorithm, with a particular emphasis on homogeneous image patches with i.i.d. pixel noise and sharp boundaries between such patches. Leveraging this analysis, we derive a simple heuristic to scale quickshift hyperparameters when dealing with real images, which we check empirically.
SIMBAR: Single Image-Based Scene Relighting For Effective Data Augmentation For Automated Driving Vision Tasks
Apr 01, 2022
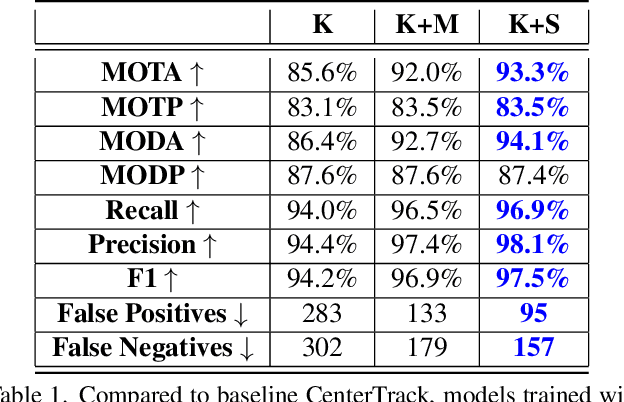
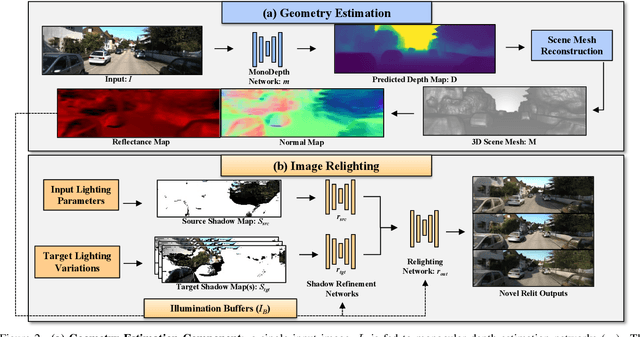
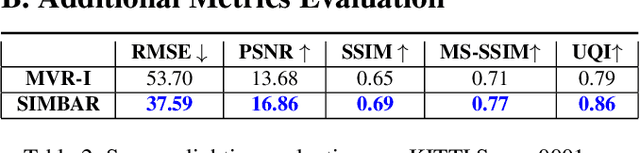
Real-world autonomous driving datasets comprise of images aggregated from different drives on the road. The ability to relight captured scenes to unseen lighting conditions, in a controllable manner, presents an opportunity to augment datasets with a richer variety of lighting conditions, similar to what would be encountered in the real-world. This paper presents a novel image-based relighting pipeline, SIMBAR, that can work with a single image as input. To the best of our knowledge, there is no prior work on scene relighting leveraging explicit geometric representations from a single image. We present qualitative comparisons with prior multi-view scene relighting baselines. To further validate and effectively quantify the benefit of leveraging SIMBAR for data augmentation for automated driving vision tasks, object detection and tracking experiments are conducted with a state-of-the-art method, a Multiple Object Tracking Accuracy (MOTA) of 93.3% is achieved with CenterTrack on SIMBAR-augmented KITTI - an impressive 9.0% relative improvement over the baseline MOTA of 85.6% with CenterTrack on original KITTI, both models trained from scratch and tested on Virtual KITTI. For more details and SIMBAR relit datasets, please visit our project website (https://simbarv1.github.io/).
An efficient algorithm for the $\ell_{p}$ norm based metric nearness problem
Nov 02, 2022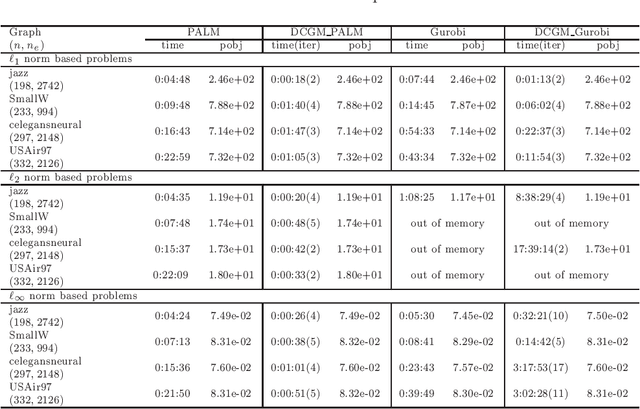

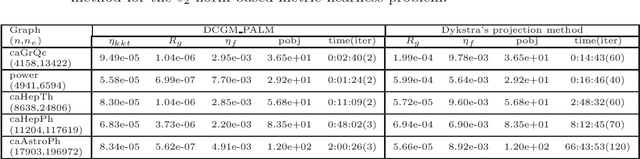

Given a dissimilarity matrix, the metric nearness problem is to find the nearest matrix of distances that satisfy the triangle inequalities. This problem has wide applications, such as sensor networks, image processing, and so on. But it is of great challenge even to obtain a moderately accurate solution due to the $O(n^{3})$ metric constraints and the nonsmooth objective function which is usually a weighted $\ell_{p}$ norm based distance. In this paper, we propose a delayed constraint generation method with each subproblem solved by the semismooth Newton based proximal augmented Lagrangian method (PALM) for the metric nearness problem. Due to the high memory requirement for the storage of the matrix related to the metric constraints, we take advantage of the special structure of the matrix and do not need to store the corresponding constraint matrix. A pleasing aspect of our algorithm is that we can solve these problems involving up to $10^{8}$ variables and $10^{13}$ constraints. Numerical experiments demonstrate the efficiency of our algorithm. In theory, firstly, under a mild condition, we establish a primal-dual error bound condition which is very essential for the analysis of local convergence rate of PALM. Secondly, we prove the equivalence between the dual nondegeneracy condition and nonsingularity of the generalized Jacobian for the inner subproblem of PALM. Thirdly, when $q(\cdot)=\|\cdot\|_{1}$ or $\|\cdot\|_{\infty}$, without the strict complementarity condition, we also prove the equivalence between the the dual nondegeneracy condition and the uniqueness of the primal solution.
High-Resolution Depth Estimation for 360-degree Panoramas through Perspective and Panoramic Depth Images Registration
Oct 20, 2022
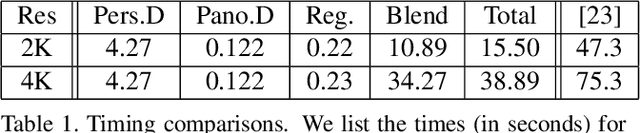
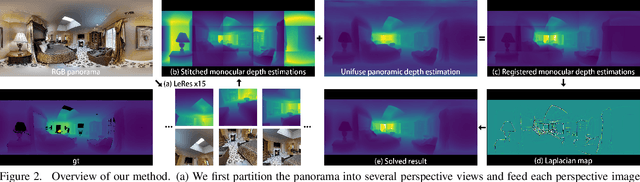
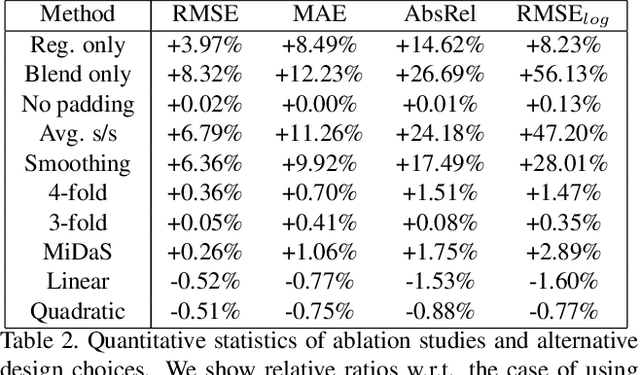
We propose a novel approach to compute high-resolution (2048x1024 and higher) depths for panoramas that is significantly faster and qualitatively and qualitatively more accurate than the current state-of-the-art method (360MonoDepth). As traditional neural network-based methods have limitations in the output image sizes (up to 1024x512) due to GPU memory constraints, both 360MonoDepth and our method rely on stitching multiple perspective disparity or depth images to come out a unified panoramic depth map. However, to achieve globally consistent stitching, 360MonoDepth relied on solving extensive disparity map alignment and Poisson-based blending problems, leading to high computation time. Instead, we propose to use an existing panoramic depth map (computed in real-time by any panorama-based method) as the common target for the individual perspective depth maps to register to. This key idea made producing globally consistent stitching results from a straightforward task. Our experiments show that our method generates qualitatively better results than existing panorama-based methods, and further outperforms them quantitatively on datasets unseen by these methods.
McQueen: a Benchmark for Multimodal Conversational Query Rewrite
Oct 23, 2022
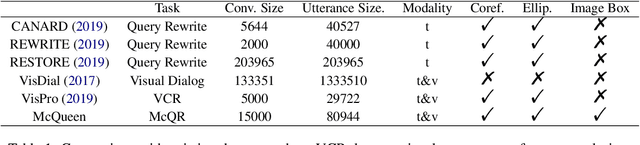

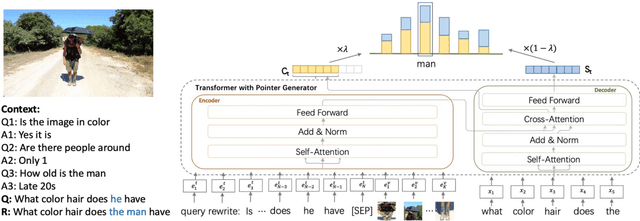
The task of query rewrite aims to convert an in-context query to its fully-specified version where ellipsis and coreference are completed and referred-back according to the history context. Although much progress has been made, less efforts have been paid to real scenario conversations that involve drawing information from more than one modalities. In this paper, we propose the task of multimodal conversational query rewrite (McQR), which performs query rewrite under the multimodal visual conversation setting. We collect a large-scale dataset named McQueen based on manual annotation, which contains 15k visual conversations and over 80k queries where each one is associated with a fully-specified rewrite version. In addition, for entities appearing in the rewrite, we provide the corresponding image box annotation. We then use the McQueen dataset to benchmark a state-of-the-art method for effectively tackling the McQR task, which is based on a multimodal pre-trained model with pointer generator. Extensive experiments are performed to demonstrate the effectiveness of our model on this task\footnote{The dataset and code of this paper are both available in \url{https://github.com/yfyuan01/MQR}
Parallel faceted imaging in radio interferometry via proximal splitting (Faceted HyperSARA): II. Code and real data proof of concept
Sep 15, 2022
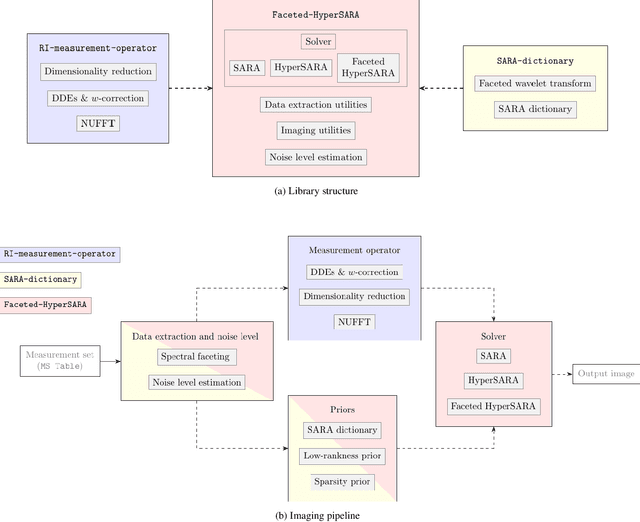
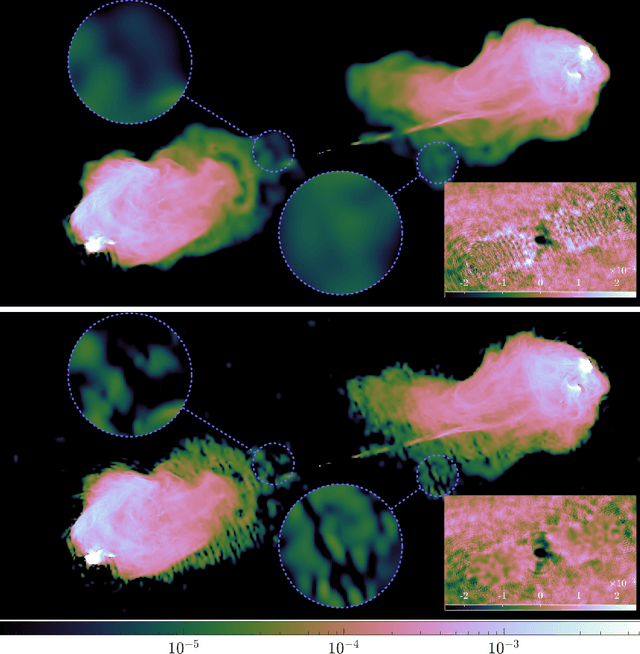
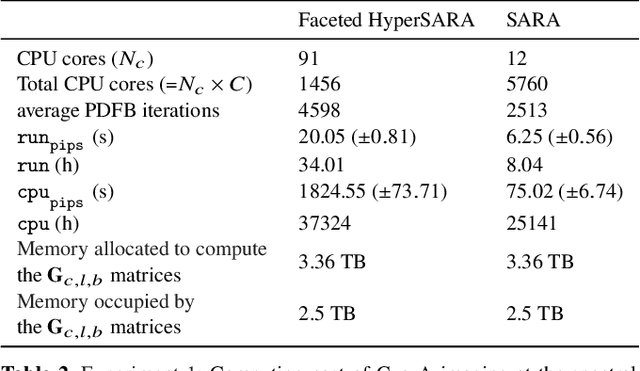
In a companion paper, a faceted wideband imaging technique for radio interferometry, dubbed Faceted HyperSARA, has been introduced and validated on synthetic data. Building on the recent HyperSARA approach, Faceted HyperSARA leverages the splitting functionality inherent to the underlying primal-dual forward-backward algorithm to decompose the image reconstruction over multiple spatio-spectral facets. The approach allows complex regularization to be injected into the imaging process while providing additional parallelization flexibility compared to HyperSARA. The present paper introduces new algorithm functionalities to address real datasets, implemented as part of a fully fledged MATLAB imaging library made available on Github. A large scale proof-of-concept is proposed to validate Faceted HyperSARA in a new data and parameter scale regime, compared to the state-of-the-art. The reconstruction of a 15 GB wideband image of Cyg A from 7.4 GB of VLA data is considered, utilizing 1440 CPU cores on a HPC system for about 9 hours. The conducted experiments illustrate the reconstruction performance of the proposed approach on real data, exploiting new functionalities to set, both an accurate model of the measurement operator accounting for known direction-dependent effects (DDEs), and an effective noise level accounting for imperfect calibration. They also demonstrate that, when combined with a further dimensionality reduction functionality, Faceted HyperSARA enables the recovery of a 3.6 GB image of Cyg A from the same data using only 91 CPU cores for 39 hours. In this setting, the proposed approach is shown to provide a superior reconstruction quality compared to the state-of-the-art wideband CLEAN-based algorithm of the WSClean software.