 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Routine Usage of AI-based Chest X-ray Reading Support in a Multi-site Medical Supply Center
Oct 17, 2022
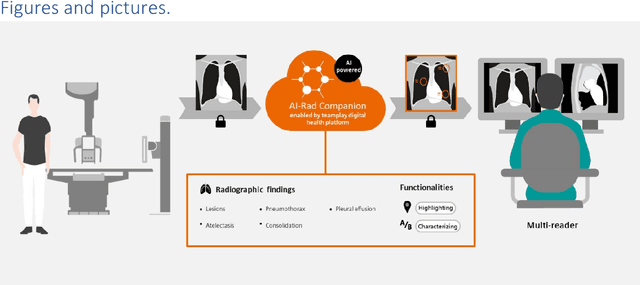
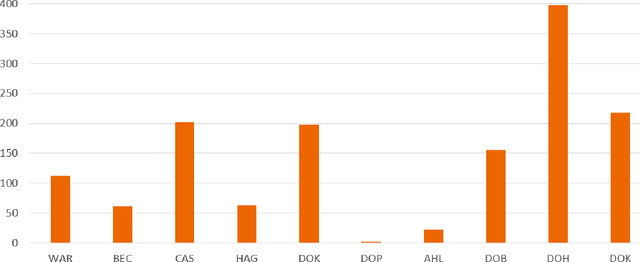
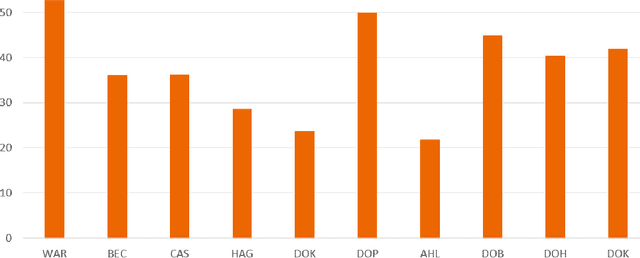
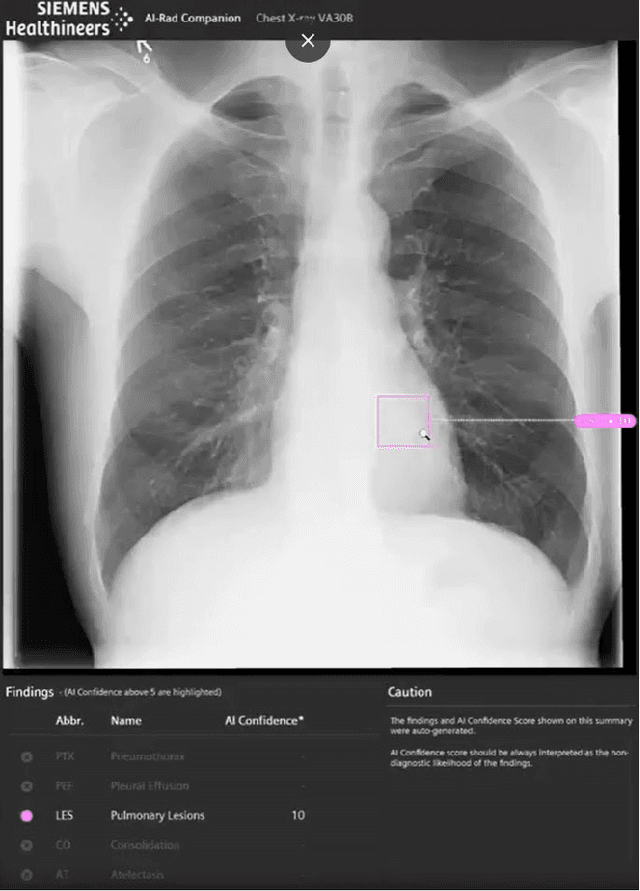
Research question: How can we establish an AI support for reading of chest X-rays in clinical routine and which benefits emerge for the clinicians and radiologists. Can it perform 24/7 support for practicing clinicians? 2. Findings: We installed an AI solution for Chest X-ray in a given structure (MVZ Uhlenbrock & Partner, Germany). We could demonstrate the practicability, performance, and benefits in 10 connected clinical sites. 3. Meaning: A commercially available AI solution for the evaluation of Chest X-ray images is able to help radiologists and clinical colleagues 24/7 in a complex environment. The system performs in a robust manner, supporting radiologists and clinical colleagues in their important decisions, in practises and hospitals regardless of the user and X-ray system type producing the image-data.
Image quality assessment for machine learning tasks using meta-reinforcement learning
Mar 27, 2022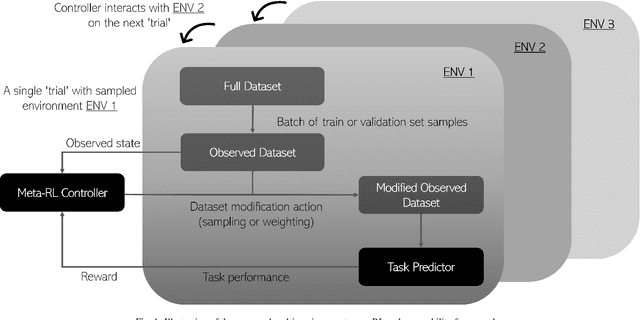
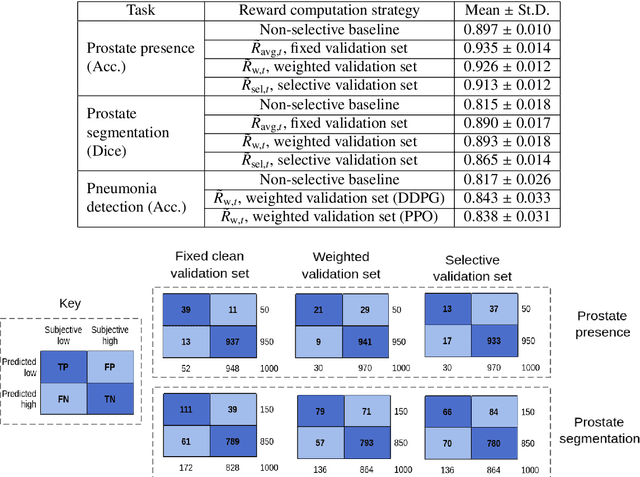
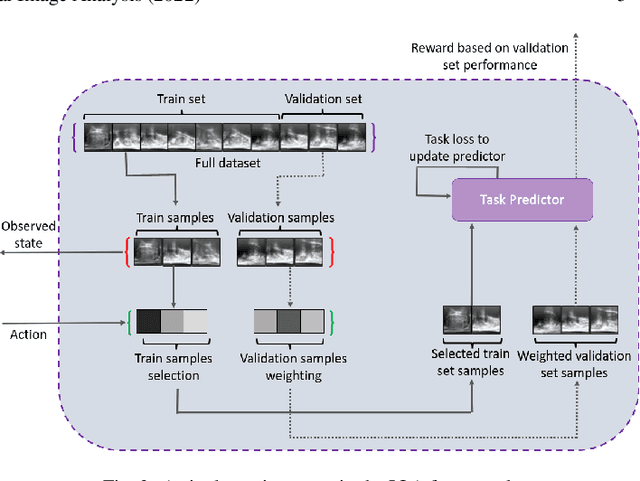
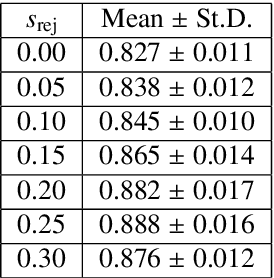
In this paper, we consider image quality assessment (IQA) as a measure of how images are amenable with respect to a given downstream task, or task amenability. When the task is performed using machine learning algorithms, such as a neural-network-based task predictor for image classification or segmentation, the performance of the task predictor provides an objective estimate of task amenability. In this work, we use an IQA controller to predict the task amenability which, itself being parameterised by neural networks, can be trained simultaneously with the task predictor. We further develop a meta-reinforcement learning framework to improve the adaptability for both IQA controllers and task predictors, such that they can be fine-tuned efficiently on new datasets or meta-tasks. We demonstrate the efficacy of the proposed task-specific, adaptable IQA approach, using two clinical applications for ultrasound-guided prostate intervention and pneumonia detection on X-ray images.
* Accepted to Medical Image Analysis; Final published version available at: https://doi.org/10.1016/j.media.2022.102427
Related Work on Image Quality Assessment
Nov 11, 2021Due to the existence of quality degradations introduced in various stages of visual signal acquisition, compression, transmission and display, image quality assessment (IQA) plays a vital role in image-based applications. According to whether the reference image is complete and available, image quality evaluation can be divided into three categories: Full-Reference(FR), Reduced- Reference(RR), and Non- Reference(NR). This article will review the state-of-the-art image quality assessment algorithms.
UPST-NeRF: Universal Photorealistic Style Transfer of Neural Radiance Fields for 3D Scene
Aug 21, 2022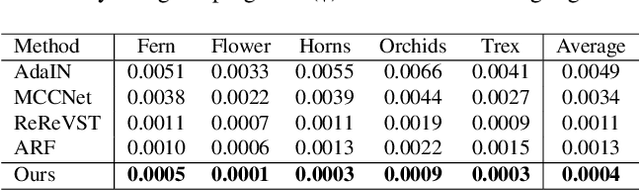
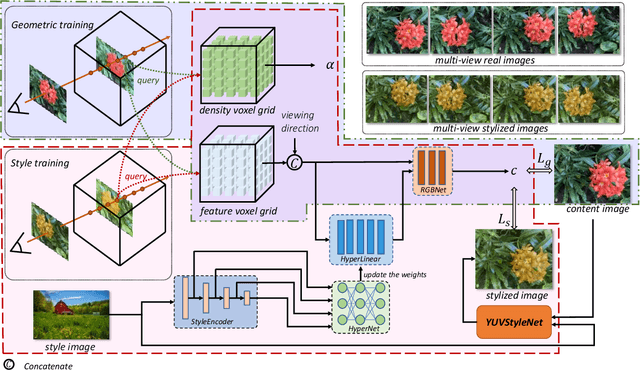
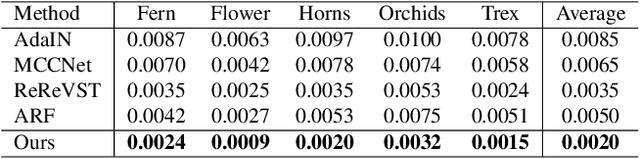
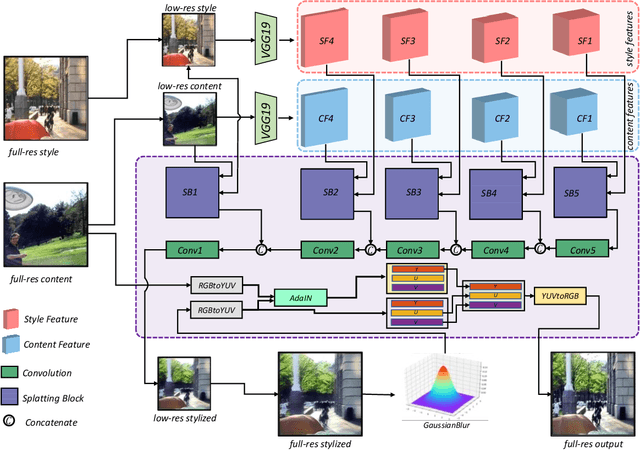
3D scenes photorealistic stylization aims to generate photorealistic images from arbitrary novel views according to a given style image while ensuring consistency when rendering from different viewpoints. Some existing stylization methods with neural radiance fields can effectively predict stylized scenes by combining the features of the style image with multi-view images to train 3D scenes. However, these methods generate novel view images that contain objectionable artifacts. Besides, they cannot achieve universal photorealistic stylization for a 3D scene. Therefore, a styling image must retrain a 3D scene representation network based on a neural radiation field. We propose a novel 3D scene photorealistic style transfer framework to address these issues. It can realize photorealistic 3D scene style transfer with a 2D style image. We first pre-trained a 2D photorealistic style transfer network, which can meet the photorealistic style transfer between any given content image and style image. Then, we use voxel features to optimize a 3D scene and get the geometric representation of the scene. Finally, we jointly optimize a hyper network to realize the scene photorealistic style transfer of arbitrary style images. In the transfer stage, we use a pre-trained 2D photorealistic network to constrain the photorealistic style of different views and different style images in the 3D scene. The experimental results show that our method not only realizes the 3D photorealistic style transfer of arbitrary style images but also outperforms the existing methods in terms of visual quality and consistency. Project page:https://semchan.github.io/UPST_NeRF.
360FusionNeRF: Panoramic Neural Radiance Fields with Joint Guidance
Oct 03, 2022
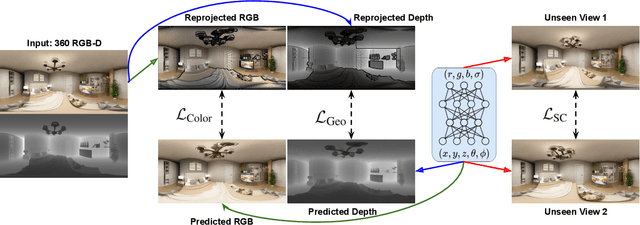

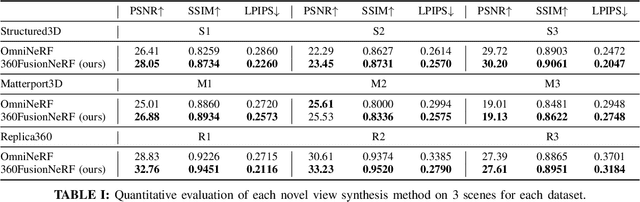
We present a method to synthesize novel views from a single $360^\circ$ panorama image based on the neural radiance field (NeRF). Prior studies in a similar setting rely on the neighborhood interpolation capability of multi-layer perceptions to complete missing regions caused by occlusion, which leads to artifacts in their predictions. We propose 360FusionNeRF, a semi-supervised learning framework where we introduce geometric supervision and semantic consistency to guide the progressive training process. Firstly, the input image is re-projected to $360^\circ$ images, and auxiliary depth maps are extracted at other camera positions. The depth supervision, in addition to the NeRF color guidance, improves the geometry of the synthesized views. Additionally, we introduce a semantic consistency loss that encourages realistic renderings of novel views. We extract these semantic features using a pre-trained visual encoder such as CLIP, a Vision Transformer trained on hundreds of millions of diverse 2D photographs mined from the web with natural language supervision. Experiments indicate that our proposed method can produce plausible completions of unobserved regions while preserving the features of the scene. When trained across various scenes, 360FusionNeRF consistently achieves the state-of-the-art performance when transferring to synthetic Structured3D dataset (PSNR~5%, SSIM~3% LPIPS~13%), real-world Matterport3D dataset (PSNR~3%, SSIM~3% LPIPS~9%) and Replica360 dataset (PSNR~8%, SSIM~2% LPIPS~18%).
Improving Convolutional Neural Networks for Fault Diagnosis by Assimilating Global Features
Oct 03, 2022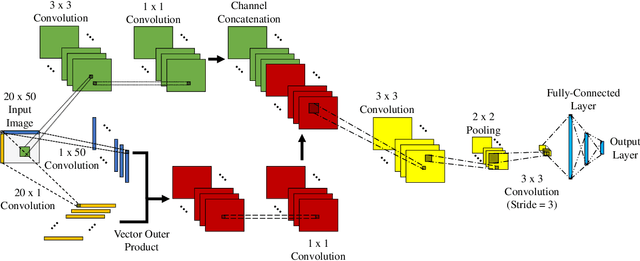
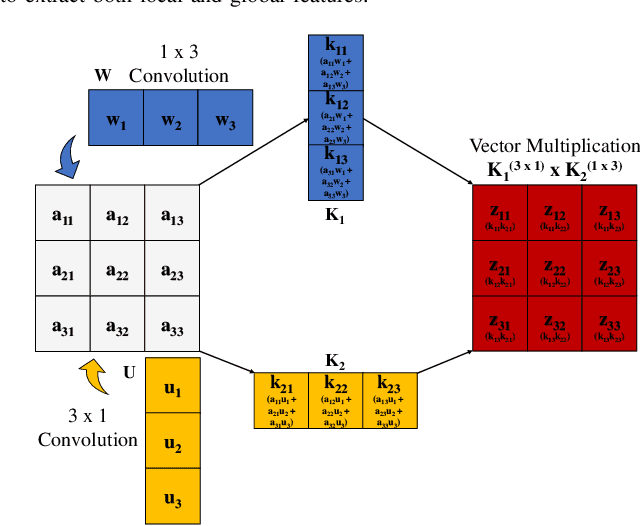
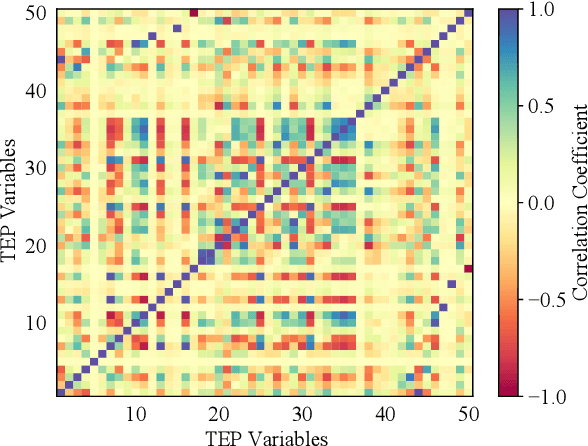
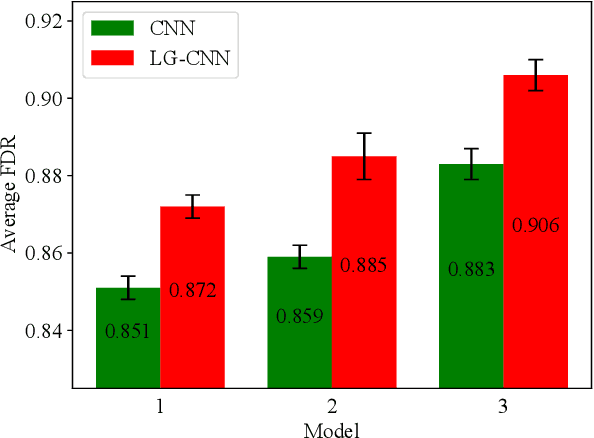
Deep learning techniques have become prominent in modern fault diagnosis for complex processes. In particular, convolutional neural networks (CNNs) have shown an appealing capacity to deal with multivariate time-series data by converting them into images. However, existing CNN techniques mainly focus on capturing local or multi-scale features from input images. A deep CNN is often required to indirectly extract global features, which are critical to describe the images converted from multivariate dynamical data. This paper proposes a novel local-global CNN (LG-CNN) architecture that directly accounts for both local and global features for fault diagnosis. Specifically, the local features are acquired by traditional local kernels whereas global features are extracted by using 1D tall and fat kernels that span the entire height and width of the image. Both local and global features are then merged for classification using fully-connected layers. The proposed LG-CNN is validated on the benchmark Tennessee Eastman process (TEP) dataset. Comparison with traditional CNN shows that the proposed LG-CNN can greatly improve the fault diagnosis performance without significantly increasing the model complexity. This is attributed to the much wider local receptive field created by the LG-CNN than that by CNN. The proposed LG-CNN architecture can be easily extended to other image processing and computer vision tasks.
GedankenNet: Self-supervised learning of hologram reconstruction using physics consistency
Sep 17, 2022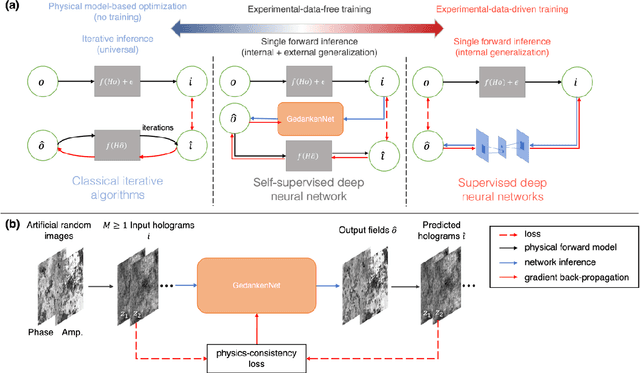
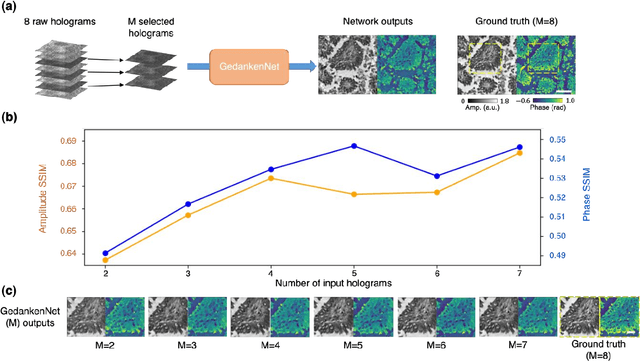

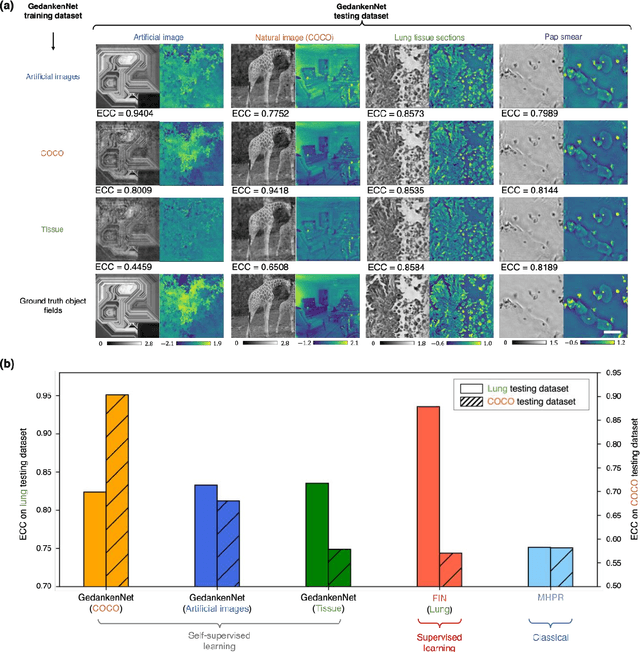
The past decade has witnessed transformative applications of deep learning in various computational imaging, sensing and microscopy tasks. Due to the supervised learning schemes employed, most of these methods depend on large-scale, diverse, and labeled training data. The acquisition and preparation of such training image datasets are often laborious and costly, also leading to biased estimation and limited generalization to new types of samples. Here, we report a self-supervised learning model, termed GedankenNet, that eliminates the need for labeled or experimental training data, and demonstrate its effectiveness and superior generalization on hologram reconstruction tasks. Without prior knowledge about the sample types to be imaged, the self-supervised learning model was trained using a physics-consistency loss and artificial random images that are synthetically generated without any experiments or resemblance to real-world samples. After its self-supervised training, GedankenNet successfully generalized to experimental holograms of various unseen biological samples, reconstructing the phase and amplitude images of different types of objects using experimentally acquired test holograms. Without access to experimental data or the knowledge of real samples of interest or their spatial features, GedankenNet's self-supervised learning achieved complex-valued image reconstructions that are consistent with the Maxwell's equations, meaning that its output inference and object solutions accurately represent the wave propagation in free-space. This self-supervised learning of image reconstruction tasks opens up new opportunities for various inverse problems in holography, microscopy and computational imaging fields.
ACORT: A Compact Object Relation Transformer for Parameter Efficient Image Captioning
Feb 11, 2022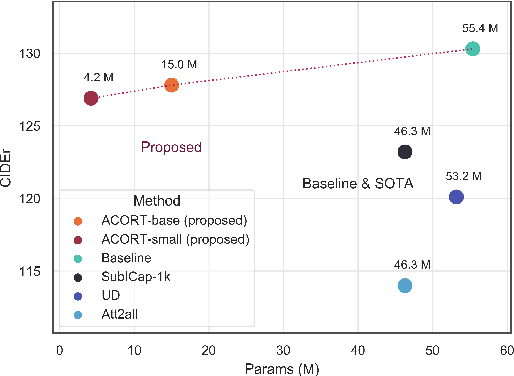
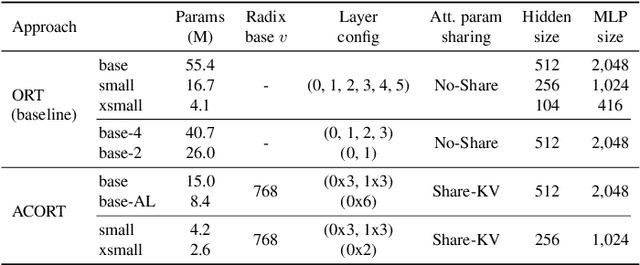
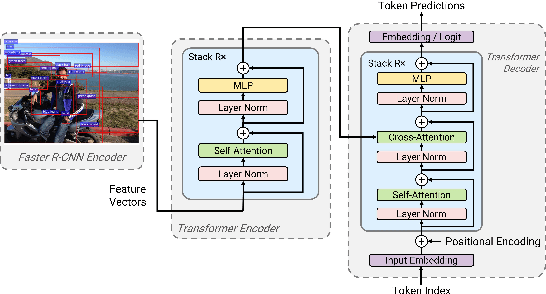
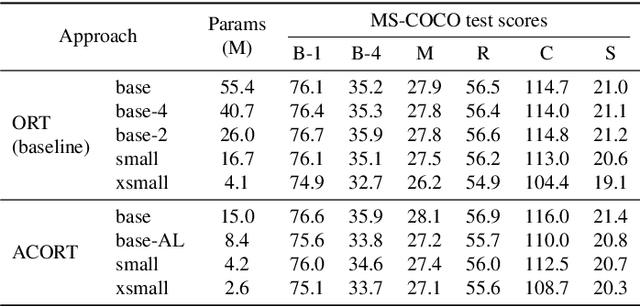
Recent research that applies Transformer-based architectures to image captioning has resulted in state-of-the-art image captioning performance, capitalising on the success of Transformers on natural language tasks. Unfortunately, though these models work well, one major flaw is their large model sizes. To this end, we present three parameter reduction methods for image captioning Transformers: Radix Encoding, cross-layer parameter sharing, and attention parameter sharing. By combining these methods, our proposed ACORT models have 3.7x to 21.6x fewer parameters than the baseline model without compromising test performance. Results on the MS-COCO dataset demonstrate that our ACORT models are competitive against baselines and SOTA approaches, with CIDEr score >=126. Finally, we present qualitative results and ablation studies to demonstrate the efficacy of the proposed changes further. Code and pre-trained models are publicly available at https://github.com/jiahuei/sparse-image-captioning.
Image Reconstruction from Events. Why learn it?
Dec 12, 2021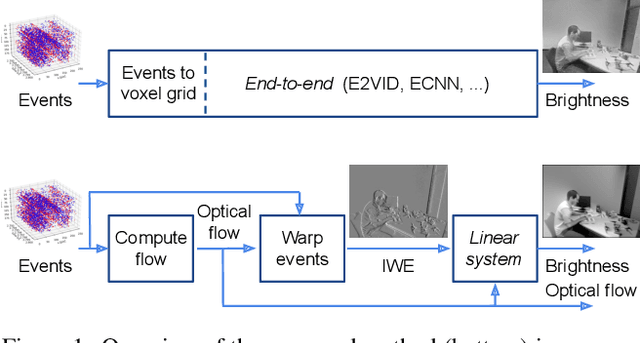
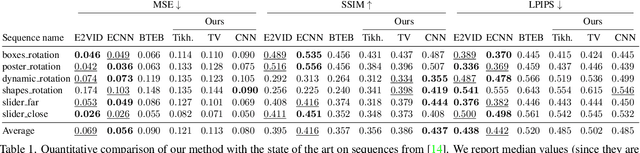

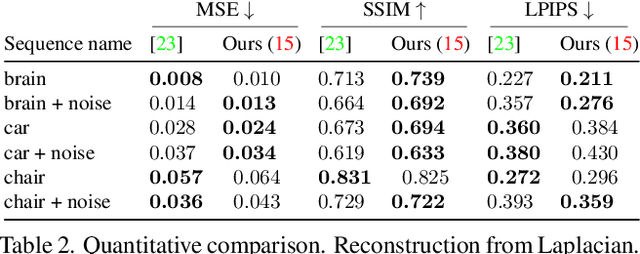
Traditional cameras measure image intensity. Event cameras, by contrast, measure per-pixel temporal intensity changes asynchronously. Recovering intensity from events is a popular research topic since the reconstructed images inherit the high dynamic range (HDR) and high-speed properties of events; hence they can be used in many robotic vision applications and to generate slow-motion HDR videos. However, state-of-the-art methods tackle this problem by training an event-to-image recurrent neural network (RNN), which lacks explainability and is difficult to tune. In this work we show, for the first time, how tackling the joint problem of motion and intensity estimation leads us to model event-based image reconstruction as a linear inverse problem that can be solved without training an image reconstruction RNN. Instead, classical and learning-based image priors can be used to solve the problem and remove artifacts from the reconstructed images. The experiments show that the proposed approach generates images with visual quality on par with state-of-the-art methods despite only using data from a short time interval (i.e., without recurrent connections). Our method can also be used to improve the quality of images reconstructed by approaches that first estimate the image Laplacian; here our method can be interpreted as Poisson reconstruction guided by image priors.
Three-Stream Joint Network for Zero-Shot Sketch-Based Image Retrieval
Apr 12, 2022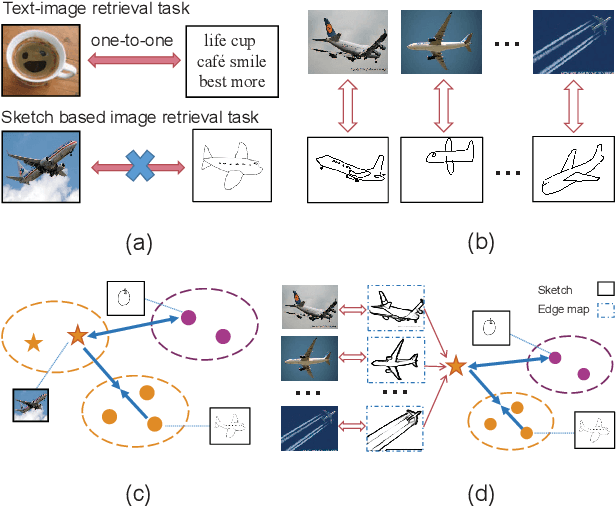
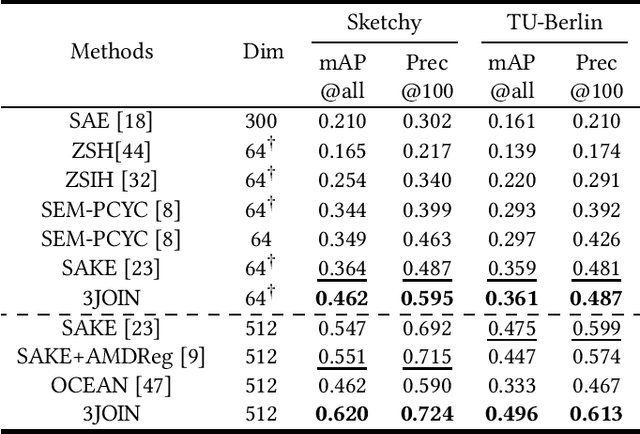
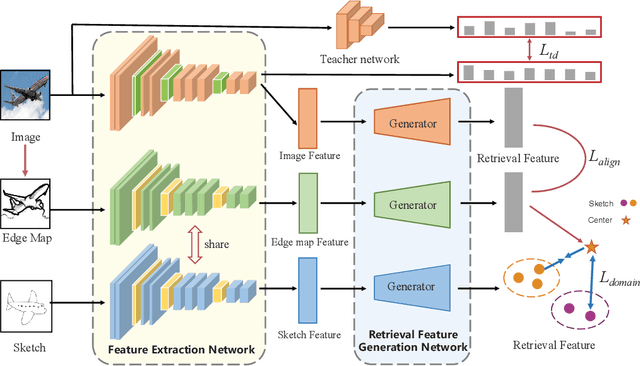
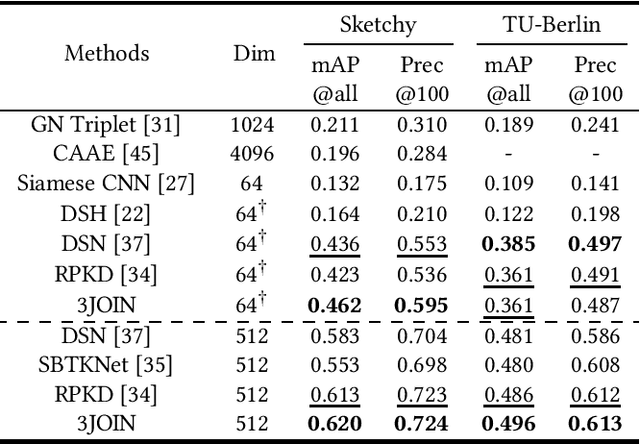
The Zero-Shot Sketch-based Image Retrieval (ZS-SBIR) is a challenging task because of the large domain gap between sketches and natural images as well as the semantic inconsistency between seen and unseen categories. Previous literature bridges seen and unseen categories by semantic embedding, which requires prior knowledge of the exact class names and additional extraction efforts. And most works reduce domain gap by mapping sketches and natural images into a common high-level space using constructed sketch-image pairs, which ignore the unpaired information between images and sketches. To address these issues, in this paper, we propose a novel Three-Stream Joint Training Network (3JOIN) for the ZS-SBIR task. To narrow the domain differences between sketches and images, we extract edge maps for natural images and treat them as a bridge between images and sketches, which have similar content to images and similar style to sketches. For exploiting a sufficient combination of sketches, natural images, and edge maps, a novel three-stream joint training network is proposed. In addition, we use a teacher network to extract the implicit semantics of the samples without the aid of other semantics and transfer the learned knowledge to unseen classes. Extensive experiments conducted on two real-world datasets demonstrate the superiority of our proposed method.