 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Face Pasting Attack
Oct 19, 2022

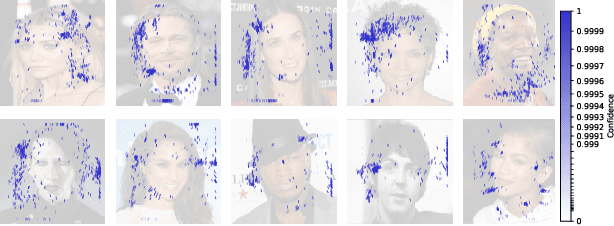

Cujo AI and Adversa AI hosted the MLSec face recognition challenge. The goal was to attack a black box face recognition model with targeted attacks. The model returned the confidence of the target class and a stealthiness score. For an attack to be considered successful the target class has to have the highest confidence among all classes and the stealthiness has to be at least 0.5. In our approach we paste the face of a target into a source image. By utilizing position, scaling, rotation and transparency attributes we reached 3rd place. Our approach took approximately 200 queries per attack for the final highest score and about ~7.7 queries minimum for a successful attack. The code is available at https://github.com/bunni90/FacePastingAttack .
Deep tensor networks with matrix product operators
Sep 16, 2022We introduce deep tensor networks, which are exponentially wide neural networks based on the tensor network representation of the weight matrices. We evaluate the proposed method on the image classification (MNIST, FashionMNIST) and sequence prediction (cellular automata) tasks. In the image classification case, deep tensor networks improve our matrix product state baselines and achieve 0.49% error rate on MNIST and 8.3% error rate on FashionMNIST. In the sequence prediction case, we demonstrate an exponential improvement in the number of parameters compared to the one-layer tensor network methods. In both cases, we discuss the non-uniform and the uniform tensor network models and show that the latter generalizes well to different input sizes.
* 9+2 pages, 8 figures
Detection of Strongly Lensed Arcs in Galaxy Clusters with Transformers
Nov 11, 2022
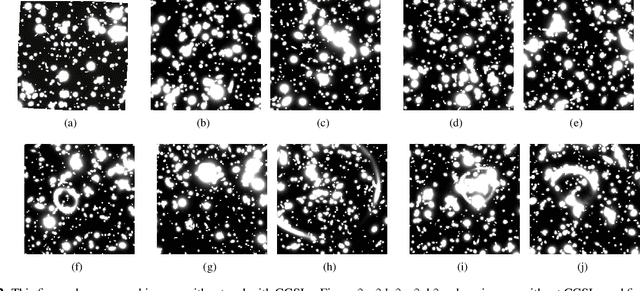
Strong lensing in galaxy clusters probes properties of dense cores of dark matter halos in mass, studies the distant universe at flux levels and spatial resolutions otherwise unavailable, and constrains cosmological models independently. The next-generation large scale sky imaging surveys are expected to discover thousands of cluster-scale strong lenses, which would lead to unprecedented opportunities for applying cluster-scale strong lenses to solve astrophysical and cosmological problems. However, the large dataset challenges astronomers to identify and extract strong lensing signals, particularly strongly lensed arcs, because of their complexity and variety. Hence, we propose a framework to detect cluster-scale strongly lensed arcs, which contains a transformer-based detection algorithm and an image simulation algorithm. We embed prior information of strongly lensed arcs at cluster-scale into the training data through simulation and then train the detection algorithm with simulated images. We use the trained transformer to detect strongly lensed arcs from simulated and real data. Results show that our approach could achieve 99.63 % accuracy rate, 90.32 % recall rate, 85.37 % precision rate and 0.23 % false positive rate in detection of strongly lensed arcs from simulated images and could detect almost all strongly lensed arcs in real observation images. Besides, with an interpretation method, we have shown that our method could identify important information embedded in simulated data. Next step, to test the reliability and usability of our approach, we will apply it to available observations (e.g., DESI Legacy Imaging Surveys) and simulated data of upcoming large-scale sky surveys, such as the Euclid and the CSST.
Domain Adaptive Video Semantic Segmentation via Cross-Domain Moving Object Mixing
Nov 04, 2022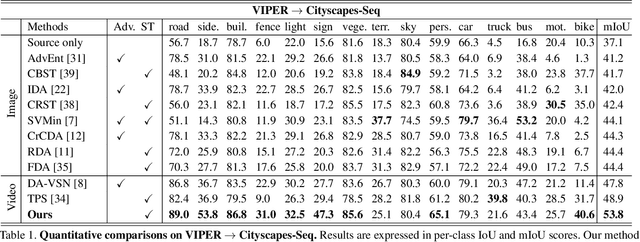
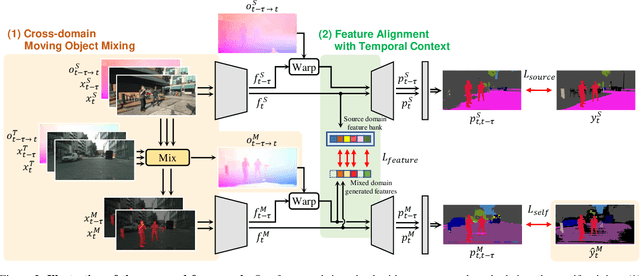
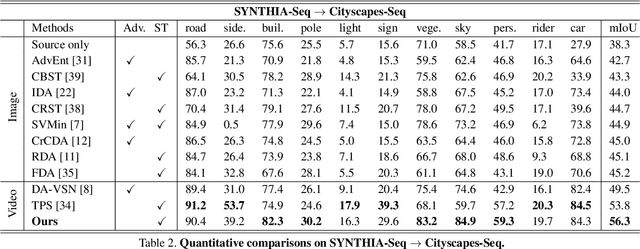
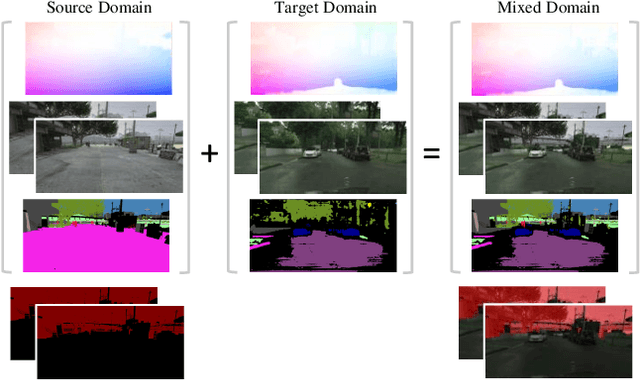
The network trained for domain adaptation is prone to bias toward the easy-to-transfer classes. Since the ground truth label on the target domain is unavailable during training, the bias problem leads to skewed predictions, forgetting to predict hard-to-transfer classes. To address this problem, we propose Cross-domain Moving Object Mixing (CMOM) that cuts several objects, including hard-to-transfer classes, in the source domain video clip and pastes them into the target domain video clip. Unlike image-level domain adaptation, the temporal context should be maintained to mix moving objects in two different videos. Therefore, we design CMOM to mix with consecutive video frames, so that unrealistic movements are not occurring. We additionally propose Feature Alignment with Temporal Context (FATC) to enhance target domain feature discriminability. FATC exploits the robust source domain features, which are trained with ground truth labels, to learn discriminative target domain features in an unsupervised manner by filtering unreliable predictions with temporal consensus. We demonstrate the effectiveness of the proposed approaches through extensive experiments. In particular, our model reaches mIoU of 53.81% on VIPER to Cityscapes-Seq benchmark and mIoU of 56.31% on SYNTHIA-Seq to Cityscapes-Seq benchmark, surpassing the state-of-the-art methods by large margins.
Evaluating and Improving Factuality in Multimodal Abstractive Summarization
Nov 04, 2022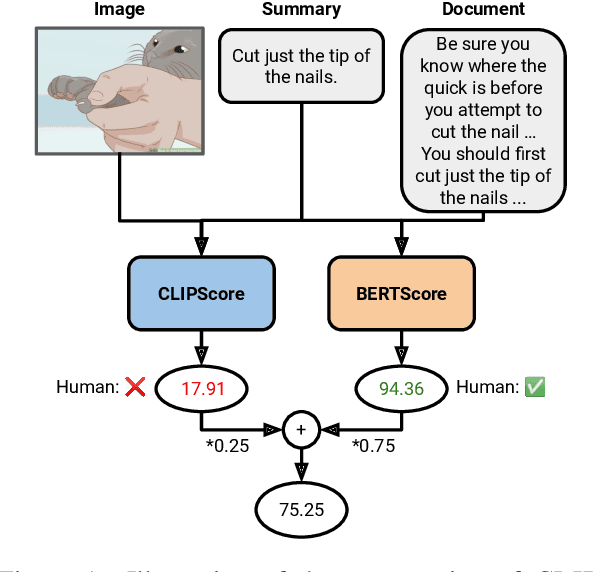
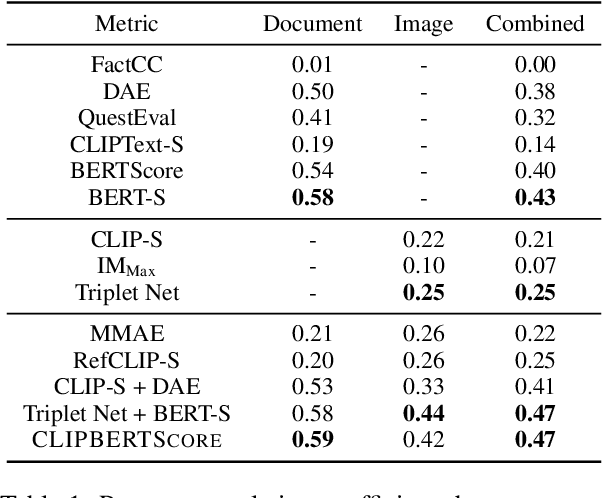
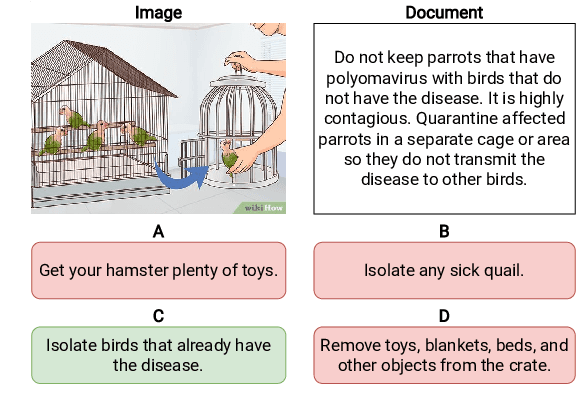

Current metrics for evaluating factuality for abstractive document summarization have achieved high correlations with human judgment, but they do not account for the vision modality and thus are not adequate for vision-and-language summarization. We propose CLIPBERTScore, a simple weighted combination of CLIPScore and BERTScore to leverage the robustness and strong factuality detection performance between image-summary and document-summary, respectively. Next, due to the lack of meta-evaluation benchmarks to evaluate the quality of multimodal factuality metrics, we collect human judgments of factuality with respect to documents and images. We show that this simple combination of two metrics in the zero-shot setting achieves higher correlations than existing factuality metrics for document summarization, outperforms an existing multimodal summarization metric, and performs competitively with strong multimodal factuality metrics specifically fine-tuned for the task. Our thorough analysis demonstrates the robustness and high correlation of CLIPBERTScore and its components on four factuality metric-evaluation benchmarks. Finally, we demonstrate two practical downstream applications of our CLIPBERTScore metric: for selecting important images to focus on during training, and as a reward for reinforcement learning to improve factuality of multimodal summary generation w.r.t automatic and human evaluation. Our data and code are publicly available at https://github.com/meetdavidwan/faithful-multimodal-summ
Studying Bias in GANs through the Lens of Race
Sep 06, 2022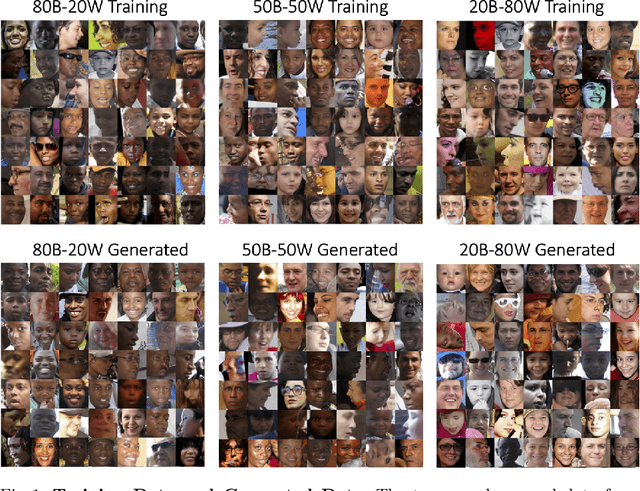



In this work, we study how the performance and evaluation of generative image models are impacted by the racial composition of their training datasets. By examining and controlling the racial distributions in various training datasets, we are able to observe the impacts of different training distributions on generated image quality and the racial distributions of the generated images. Our results show that the racial compositions of generated images successfully preserve that of the training data. However, we observe that truncation, a technique used to generate higher quality images during inference, exacerbates racial imbalances in the data. Lastly, when examining the relationship between image quality and race, we find that the highest perceived visual quality images of a given race come from a distribution where that race is well-represented, and that annotators consistently prefer generated images of white people over those of Black people.
Latency-aware Spatial-wise Dynamic Networks
Oct 12, 2022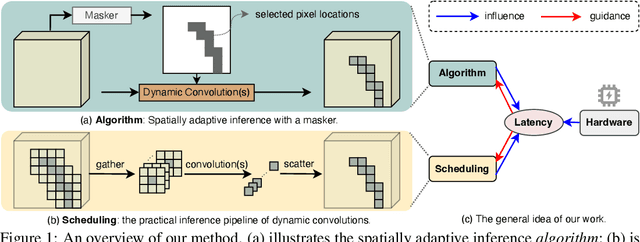
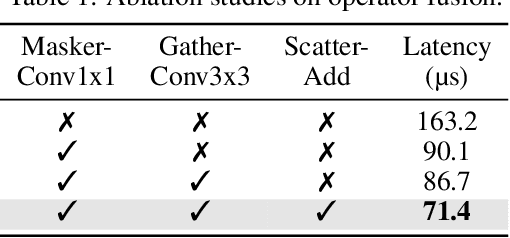
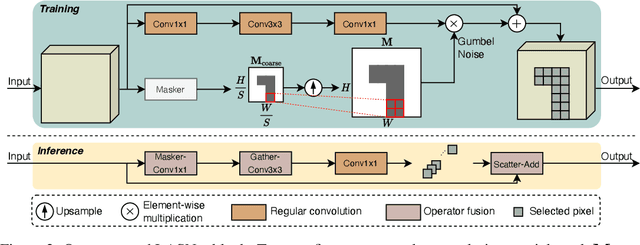
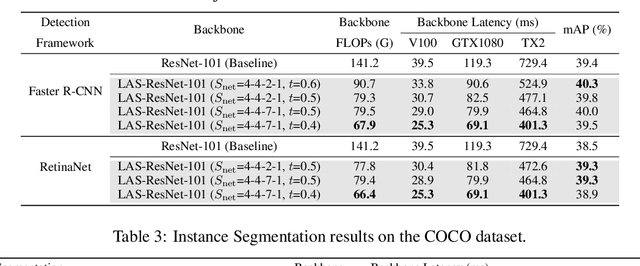
Spatial-wise dynamic convolution has become a promising approach to improving the inference efficiency of deep networks. By allocating more computation to the most informative pixels, such an adaptive inference paradigm reduces the spatial redundancy in image features and saves a considerable amount of unnecessary computation. However, the theoretical efficiency achieved by previous methods can hardly translate into a realistic speedup, especially on the multi-core processors (e.g. GPUs). The key challenge is that the existing literature has only focused on designing algorithms with minimal computation, ignoring the fact that the practical latency can also be influenced by scheduling strategies and hardware properties. To bridge the gap between theoretical computation and practical efficiency, we propose a latency-aware spatial-wise dynamic network (LASNet), which performs coarse-grained spatially adaptive inference under the guidance of a novel latency prediction model. The latency prediction model can efficiently estimate the inference latency of dynamic networks by simultaneously considering algorithms, scheduling strategies, and hardware properties. We use the latency predictor to guide both the algorithm design and the scheduling optimization on various hardware platforms. Experiments on image classification, object detection and instance segmentation demonstrate that the proposed framework significantly improves the practical inference efficiency of deep networks. For example, the average latency of a ResNet-101 on the ImageNet validation set could be reduced by 36% and 46% on a server GPU (Nvidia Tesla-V100) and an edge device (Nvidia Jetson TX2 GPU) respectively without sacrificing the accuracy. Code is available at https://github.com/LeapLabTHU/LASNet.
ImageSig: A signature transform for ultra-lightweight image recognition
May 13, 2022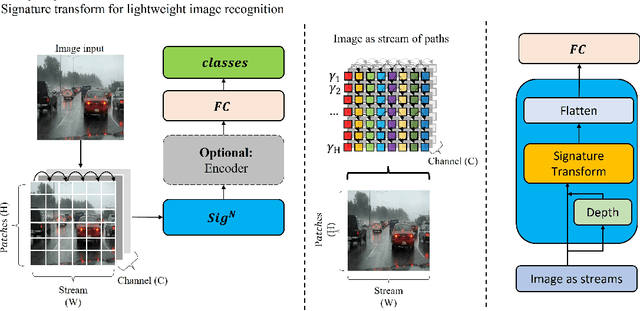
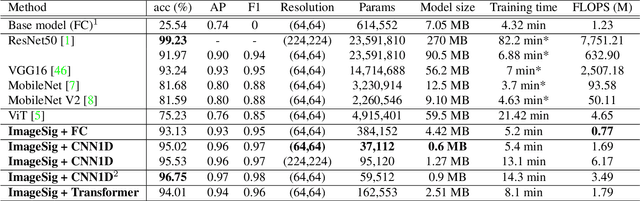


This paper introduces a new lightweight method for image recognition. ImageSig is based on computing signatures and does not require a convolutional structure or an attention-based encoder. It is striking to the authors that it achieves: a) an accuracy for 64 X 64 RGB images that exceeds many of the state-of-the-art methods and simultaneously b) requires orders of magnitude less FLOPS, power and memory footprint. The pretrained model can be as small as 44.2 KB in size. ImageSig shows unprecedented performance on hardware such as Raspberry Pi and Jetson-nano. ImageSig treats images as streams with multiple channels. These streams are parameterized by spatial directions. We contribute to the functionality of signature and rough path theory to stream-like data and vision tasks on static images beyond temporal streams. With very few parameters and small size models, the key advantage is that one could have many of these "detectors" assembled on the same chip; moreover, the feature acquisition can be performed once and shared between different models of different tasks - further accelerating the process. This contributes to energy efficiency and the advancements of embedded AI at the edge.
Plug-and-Play Regularization using Linear Solvers
Sep 16, 2022


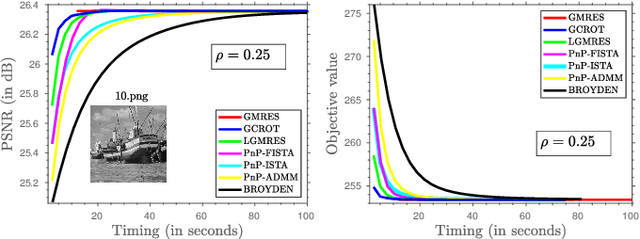
There has been tremendous research on the design of image regularizers over the years, from simple Tikhonov and Laplacian to sophisticated sparsity and CNN-based regularizers. Coupled with a model-based loss function, these are typically used for image reconstruction within an optimization framework. The technical challenge is to develop a regularizer that can accurately model realistic images and be optimized efficiently along with the loss function. Motivated by the recent plug-and-play paradigm for image regularization, we construct a quadratic regularizer whose reconstruction capability is competitive with state-of-the-art regularizers. The novelty of the regularizer is that, unlike classical regularizers, the quadratic objective function is derived from the observed data. Since the regularizer is quadratic, we can reduce the optimization to solving a linear system for applications such as superresolution, deblurring, inpainting, etc. In particular, we show that using iterative Krylov solvers, we can converge to the solution in a few iterations, where each iteration requires an application of the forward operator and a linear denoiser. The surprising finding is that we can get close to deep learning methods in terms of reconstruction quality. To the best of our knowledge, the possibility of achieving near state-of-the-art performance using a linear solver is novel.
PERGAMO: Personalized 3D Garments from Monocular Video
Oct 26, 2022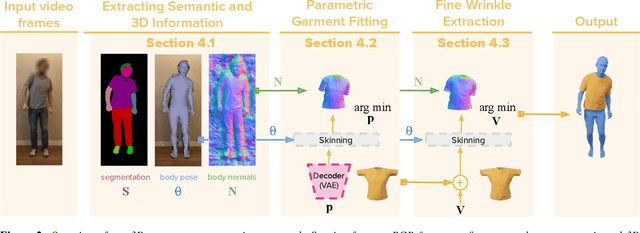


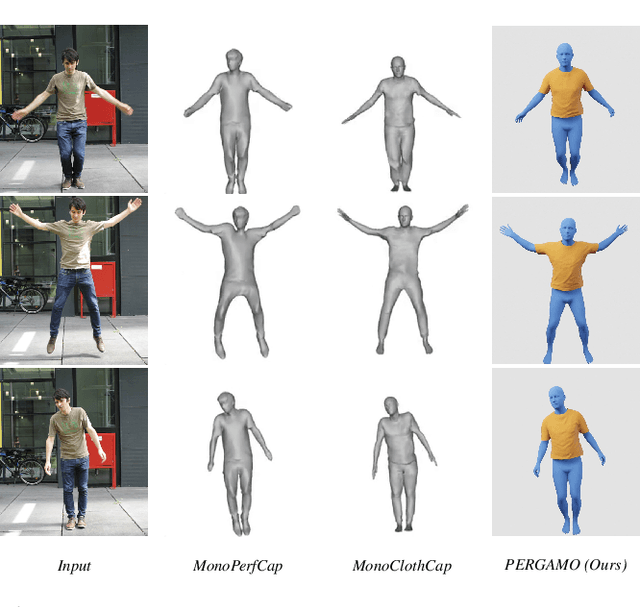
Clothing plays a fundamental role in digital humans. Current approaches to animate 3D garments are mostly based on realistic physics simulation, however, they typically suffer from two main issues: high computational run-time cost, which hinders their development; and simulation-to-real gap, which impedes the synthesis of specific real-world cloth samples. To circumvent both issues we propose PERGAMO, a data-driven approach to learn a deformable model for 3D garments from monocular images. To this end, we first introduce a novel method to reconstruct the 3D geometry of garments from a single image, and use it to build a dataset of clothing from monocular videos. We use these 3D reconstructions to train a regression model that accurately predicts how the garment deforms as a function of the underlying body pose. We show that our method is capable of producing garment animations that match the real-world behaviour, and generalizes to unseen body motions extracted from motion capture dataset.