 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Deep Appearance Prefiltering
Nov 08, 2022



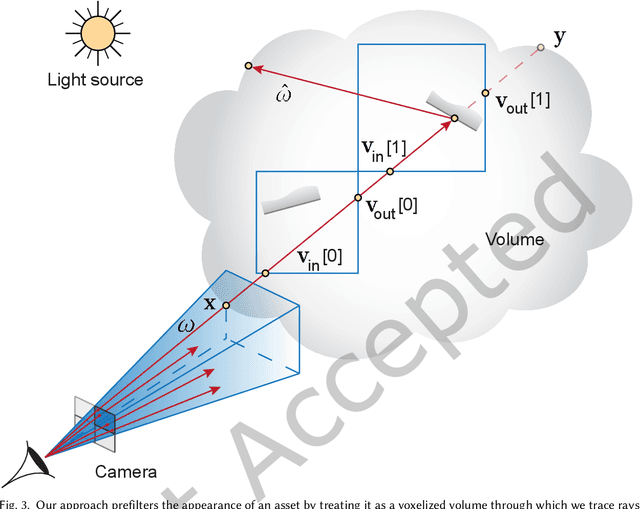
Physically based rendering of complex scenes can be prohibitively costly with a potentially unbounded and uneven distribution of complexity across the rendered image. The goal of an ideal level of detail (LoD) method is to make rendering costs independent of the 3D scene complexity, while preserving the appearance of the scene. However, current prefiltering LoD methods are limited in the appearances they can support due to their reliance of approximate models and other heuristics. We propose the first comprehensive multi-scale LoD framework for prefiltering 3D environments with complex geometry and materials (e.g., the Disney BRDF), while maintaining the appearance with respect to the ray-traced reference. Using a multi-scale hierarchy of the scene, we perform a data-driven prefiltering step to obtain an appearance phase function and directional coverage mask at each scale. At the heart of our approach is a novel neural representation that encodes this information into a compact latent form that is easy to decode inside a physically based renderer. Once a scene is baked out, our method requires no original geometry, materials, or textures at render time. We demonstrate that our approach compares favorably to state-of-the-art prefiltering methods and achieves considerable savings in memory for complex scenes.
Oracle-MNIST: a Realistic Image Dataset for Benchmarking Machine Learning Algorithms
May 19, 2022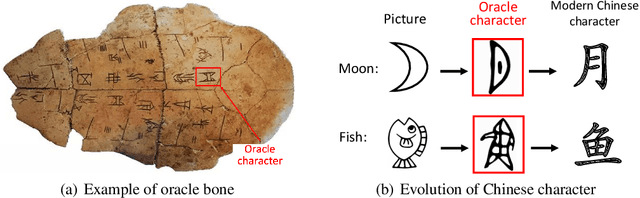
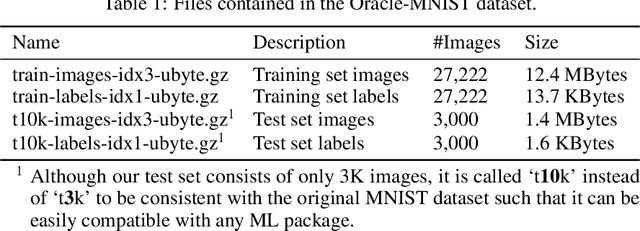


We introduce the Oracle-MNIST dataset, comprising of 28$\times $28 grayscale images of 30,222 ancient characters from 10 categories, for benchmarking pattern classification, with particular challenges on image noise and distortion. The training set totally consists of 27,222 images, and the test set contains 300 images per class. Oracle-MNIST shares the same data format with the original MNIST dataset, allowing for direct compatibility with all existing classifiers and systems, but it constitutes a more challenging classification task than MNIST. The images of ancient characters suffer from 1) extremely serious and unique noises caused by three-thousand years of burial and aging and 2) dramatically variant writing styles by ancient Chinese, which all make them realistic for machine learning research. The dataset is freely available at https://github.com/wm-bupt/oracle-mnist.
End-to-End Transformer Based Model for Image Captioning
Mar 29, 2022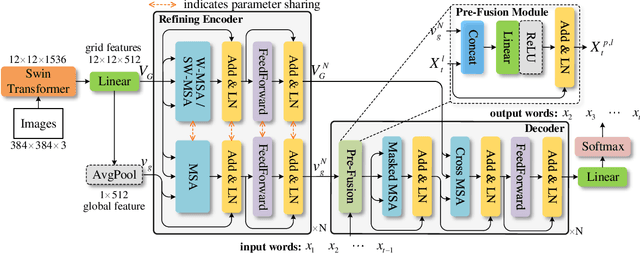
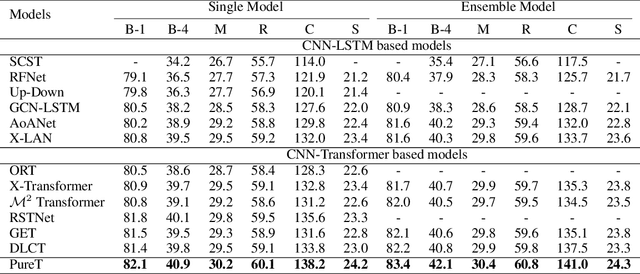
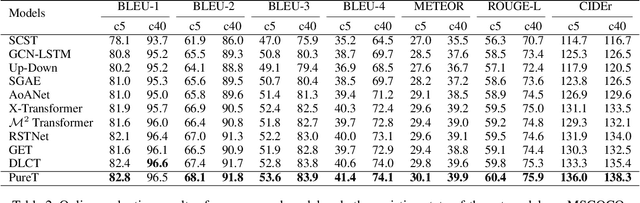
CNN-LSTM based architectures have played an important role in image captioning, but limited by the training efficiency and expression ability, researchers began to explore the CNN-Transformer based models and achieved great success. Meanwhile, almost all recent works adopt Faster R-CNN as the backbone encoder to extract region-level features from given images. However, Faster R-CNN needs a pre-training on an additional dataset, which divides the image captioning task into two stages and limits its potential applications. In this paper, we build a pure Transformer-based model, which integrates image captioning into one stage and realizes end-to-end training. Firstly, we adopt SwinTransformer to replace Faster R-CNN as the backbone encoder to extract grid-level features from given images; Then, referring to Transformer, we build a refining encoder and a decoder. The refining encoder refines the grid features by capturing the intra-relationship between them, and the decoder decodes the refined features into captions word by word. Furthermore, in order to increase the interaction between multi-modal (vision and language) features to enhance the modeling capability, we calculate the mean pooling of grid features as the global feature, then introduce it into refining encoder to refine with grid features together, and add a pre-fusion process of refined global feature and generated words in decoder. To validate the effectiveness of our proposed model, we conduct experiments on MSCOCO dataset. The experimental results compared to existing published works demonstrate that our model achieves new state-of-the-art performances of 138.2% (single model) and 141.0% (ensemble of 4 models) CIDEr scores on `Karpathy' offline test split and 136.0% (c5) and 138.3% (c40) CIDEr scores on the official online test server. Trained models and source code will be released.
Prune and distill: similar reformatting of image information along rat visual cortex and deep neural networks
May 27, 2022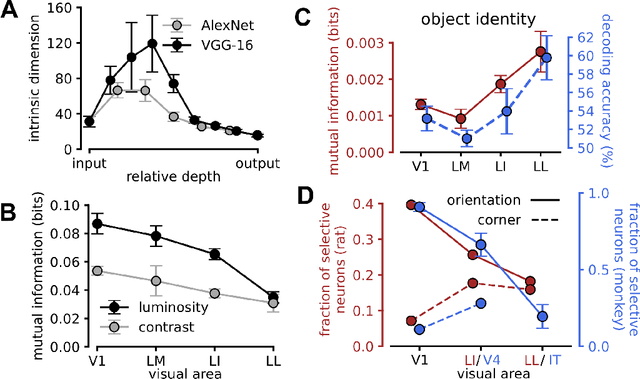
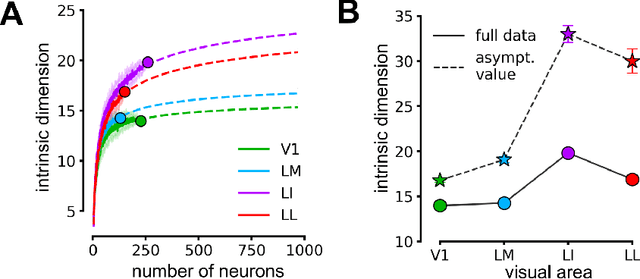
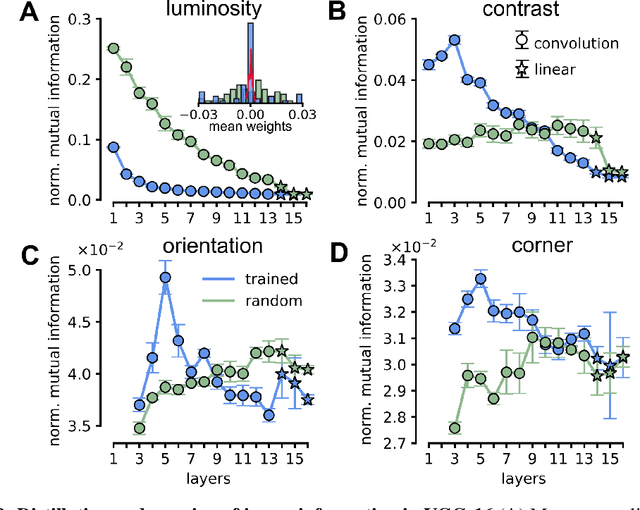
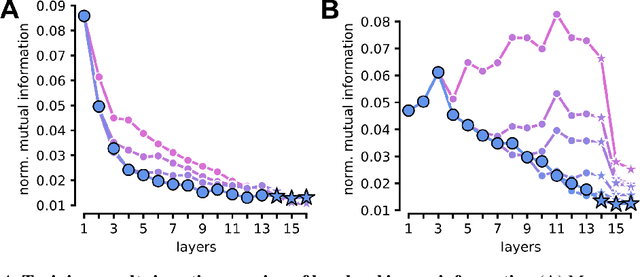
Visual object recognition has been extensively studied in both neuroscience and computer vision. Recently, the most popular class of artificial systems for this task, deep convolutional neural networks (CNNs), has been shown to provide excellent models for its functional analogue in the brain, the ventral stream in visual cortex. This has prompted questions on what, if any, are the common principles underlying the reformatting of visual information as it flows through a CNN or the ventral stream. Here we consider some prominent statistical patterns that are known to exist in the internal representations of either CNNs or the visual cortex and look for them in the other system. We show that intrinsic dimensionality (ID) of object representations along the rat homologue of the ventral stream presents two distinct expansion-contraction phases, as previously shown for CNNs. Conversely, in CNNs, we show that training results in both distillation and active pruning (mirroring the increase in ID) of low- to middle-level image information in single units, as representations gain the ability to support invariant discrimination, in agreement with previous observations in rat visual cortex. Taken together, our findings suggest that CNNs and visual cortex share a similarly tight relationship between dimensionality expansion/reduction of object representations and reformatting of image information.
Fusing Global and Local Features for Generalized AI-Synthesized Image Detection
Mar 26, 2022
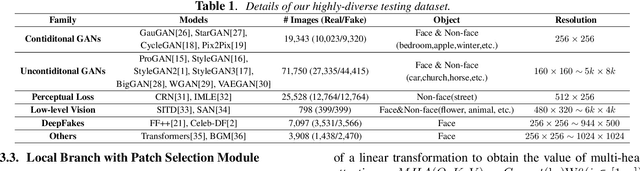
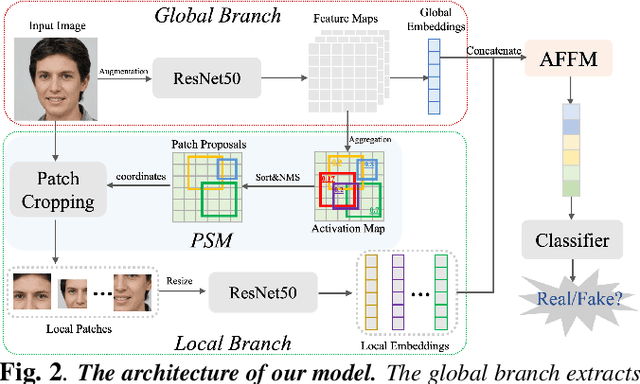
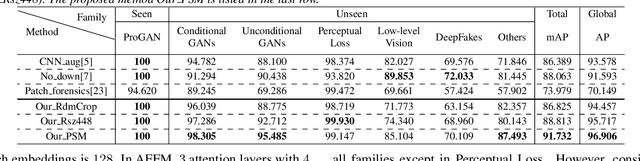
With the development of the Generative Adversarial Networks (GANs) and DeepFakes, AI-synthesized images are now of such high quality that humans can hardly distinguish them from real images. It is imperative for media forensics to develop detectors to expose them accurately. Existing detection methods have shown high performance in generated images detection, but they tend to generalize poorly in the real-world scenarios, where the synthetic images are usually generated with unseen models using unknown source data. In this work, we emphasize the importance of combining information from the whole image and informative patches in improving the generalization ability of AI-synthesized image detection. Specifically, we design a two-branch model to combine global spatial information from the whole image and local informative features from multiple patches selected by a novel patch selection module. Multi-head attention mechanism is further utilized to fuse the global and local features. We collect a highly diverse dataset synthesized by 19 models with various objects and resolutions to evaluate our model. Experimental results demonstrate the high accuracy and good generalization ability of our method in detecting generated images.
Satellite Image Time Series Analysis for Big Earth Observation Data
Apr 24, 2022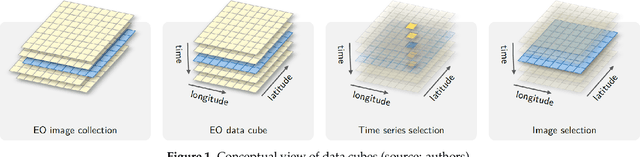
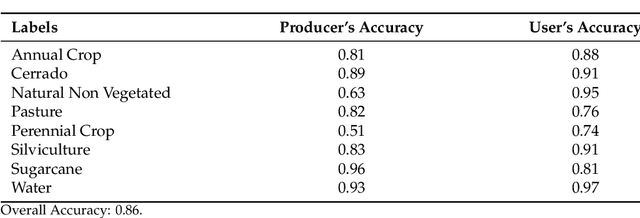

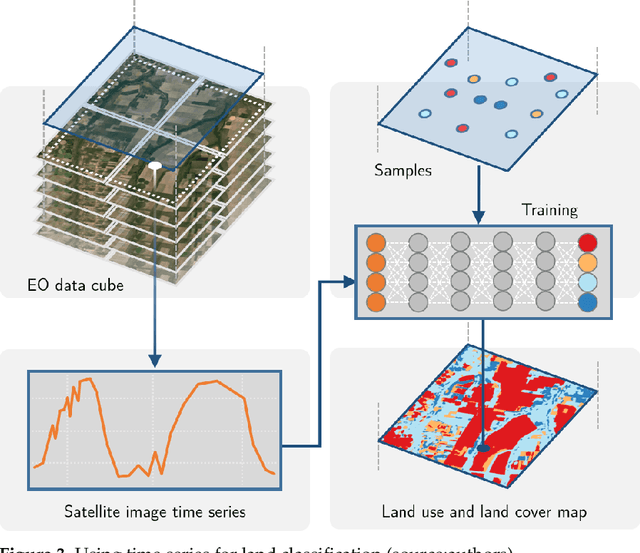
The development of analytical software for big Earth observation data faces several challenges. Designers need to balance between conflicting factors. Solutions that are efficient for specific hardware architectures can not be used in other environments. Packages that work on generic hardware and open standards will not have the same performance as dedicated solutions. Software that assumes that its users are computer programmers are flexible but may be difficult to learn for a wide audience. This paper describes sits, an open-source R package for satellite image time series analysis using machine learning. To allow experts to use satellite imagery to the fullest extent, sits adopts a time-first, space-later approach. It supports the complete cycle of data analysis for land classification. Its API provides a simple but powerful set of functions. The software works in different cloud computing environments. Satellite image time series are input to machine learning classifiers, and the results are post-processed using spatial smoothing. Since machine learning methods need accurate training data, sits includes methods for quality assessment of training samples. The software also provides methods for validation and accuracy measurement. The package thus comprises a production environment for big EO data analysis. We show that this approach produces high accuracy for land use and land cover maps through a case study in the Cerrado biome, one of the world's fast moving agricultural frontiers for the year 2018.
Oscillatory Neural Network as Hetero-Associative Memory for Image Edge Detection
Feb 25, 2022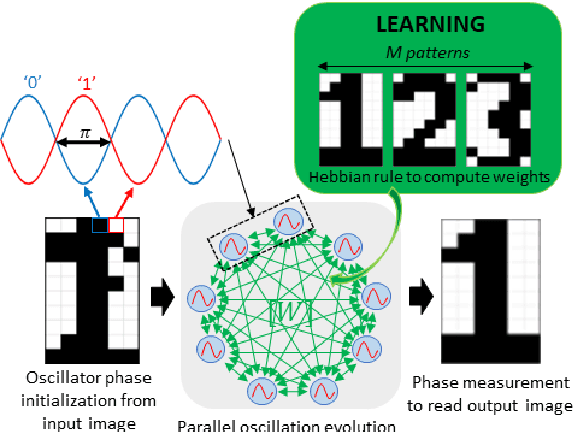

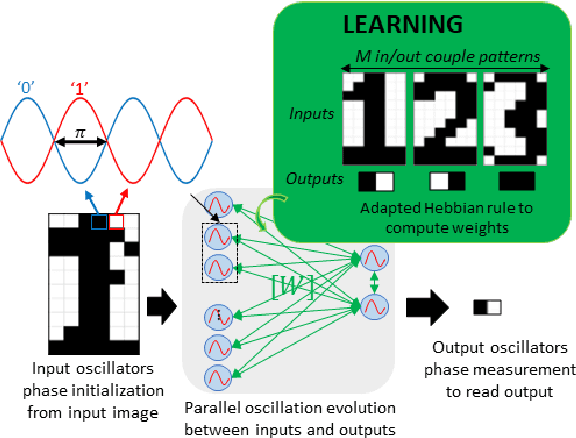
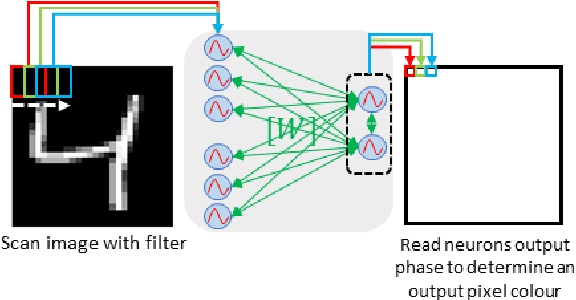
The increasing amount of data to be processed on edge devices, such as cameras, has motivated Artificial Intelligence (AI) integration at the edge. Typical image processing methods performed at the edge, such as feature extraction or edge detection, use convolutional filters that are energy, computation, and memory hungry algorithms. But edge devices and cameras have scarce computational resources, bandwidth, and power and are limited due to privacy constraints to send data over to the cloud. Thus, there is a need to process image data at the edge. Over the years, this need has incited a lot of interest in implementing neuromorphic computing at the edge. Neuromorphic systems aim to emulate the biological neural functions to achieve energy-efficient computing. Recently, Oscillatory Neural Networks (ONN) present a novel brain-inspired computing approach by emulating brain oscillations to perform autoassociative memory types of applications. To speed up image edge detection and reduce its power consumption, we perform an in-depth investigation with ONNs. We propose a novel image processing method by using ONNs as a hetero-associative memory (HAM) for image edge detection. We simulate our ONN-HAM solution using first, a Matlab emulator, and then a fully digital ONN design. We show results on gray scale square evaluation maps, also on black and white and gray scale 28x28 MNIST images and finally on black and white 512x512 standard test images. We compare our solution with standard edge detection filters such as Sobel and Canny. Finally, using the fully digital design simulation results, we report on timing and resource characteristics, and evaluate its feasibility for real-time image processing applications. Our digital ONN-HAM solution can process images with up to 120x120 pixels (166 MHz system frequency) respecting real-time camera constraints. This work is the first to explore ONNs as hetero-associative memory for image processing applications.
Unsupervised Learning of Structured Representations via Closed-Loop Transcription
Oct 30, 2022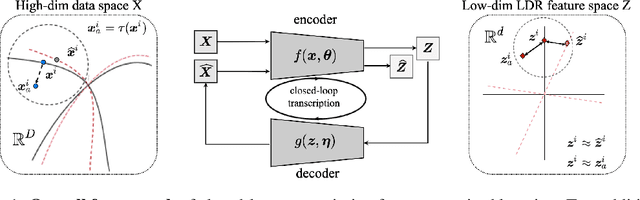

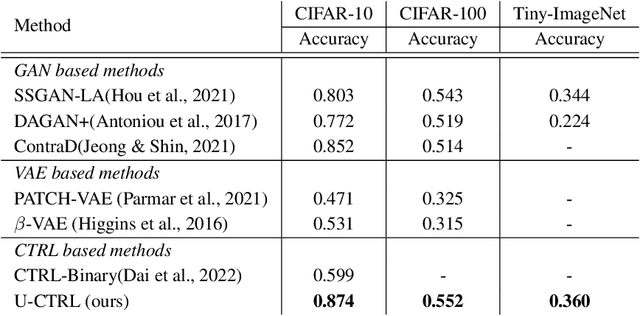
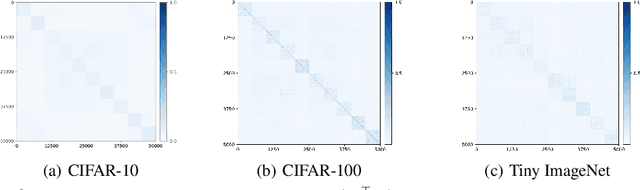
This paper proposes an unsupervised method for learning a unified representation that serves both discriminative and generative purposes. While most existing unsupervised learning approaches focus on a representation for only one of these two goals, we show that a unified representation can enjoy the mutual benefits of having both. Such a representation is attainable by generalizing the recently proposed \textit{closed-loop transcription} framework, known as CTRL, to the unsupervised setting. This entails solving a constrained maximin game over a rate reduction objective that expands features of all samples while compressing features of augmentations of each sample. Through this process, we see discriminative low-dimensional structures emerge in the resulting representations. Under comparable experimental conditions and network complexities, we demonstrate that these structured representations enable classification performance close to state-of-the-art unsupervised discriminative representations, and conditionally generated image quality significantly higher than that of state-of-the-art unsupervised generative models. Source code can be found at https://github.com/Delay-Xili/uCTRL.
Time-rEversed diffusioN tEnsor Transformer: A new TENET of Few-Shot Object Detection
Oct 30, 2022In this paper, we tackle the challenging problem of Few-shot Object Detection. Existing FSOD pipelines (i) use average-pooled representations that result in information loss; and/or (ii) discard position information that can help detect object instances. Consequently, such pipelines are sensitive to large intra-class appearance and geometric variations between support and query images. To address these drawbacks, we propose a Time-rEversed diffusioN tEnsor Transformer (TENET), which i) forms high-order tensor representations that capture multi-way feature occurrences that are highly discriminative, and ii) uses a transformer that dynamically extracts correlations between the query image and the entire support set, instead of a single average-pooled support embedding. We also propose a Transformer Relation Head (TRH), equipped with higher-order representations, which encodes correlations between query regions and the entire support set, while being sensitive to the positional variability of object instances. Our model achieves state-of-the-art results on PASCAL VOC, FSOD, and COCO.
Combining Attention Module and Pixel Shuffle for License Plate Super-Resolution
Oct 30, 2022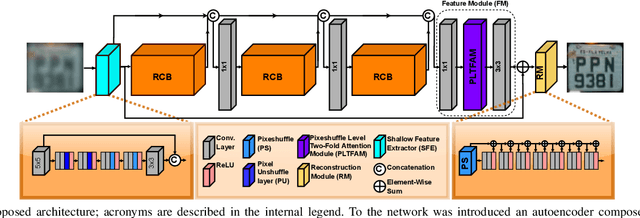
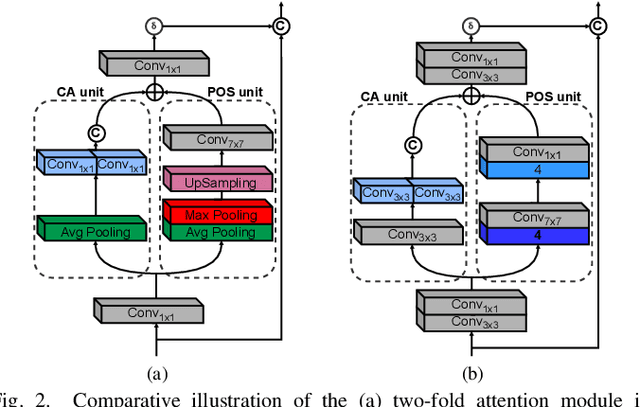


The License Plate Recognition (LPR) field has made impressive advances in the last decade due to novel deep learning approaches combined with the increased availability of training data. However, it still has some open issues, especially when the data come from low-resolution (LR) and low-quality images/videos, as in surveillance systems. This work focuses on license plate (LP) reconstruction in LR and low-quality images. We present a Single-Image Super-Resolution (SISR) approach that extends the attention/transformer module concept by exploiting the capabilities of PixelShuffle layers and that has an improved loss function based on LPR predictions. For training the proposed architecture, we use synthetic images generated by applying heavy Gaussian noise in terms of Structural Similarity Index Measure (SSIM) to the original high-resolution (HR) images. In our experiments, the proposed method outperformed the baselines both quantitatively and qualitatively. The datasets we created for this work are publicly available to the research community at https://github.com/valfride/lpr-rsr/