 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Visual Semantic Parsing: From Images to Abstract Meaning Representation
Oct 27, 2022
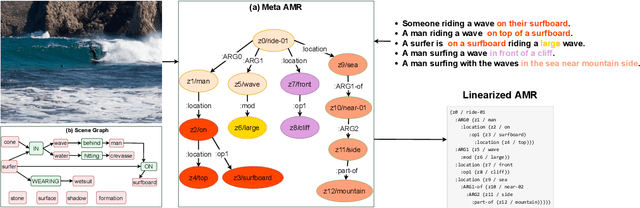
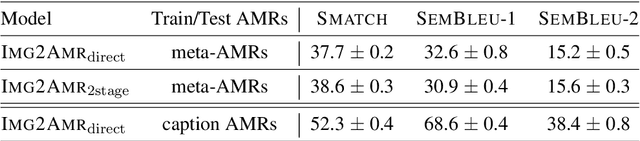
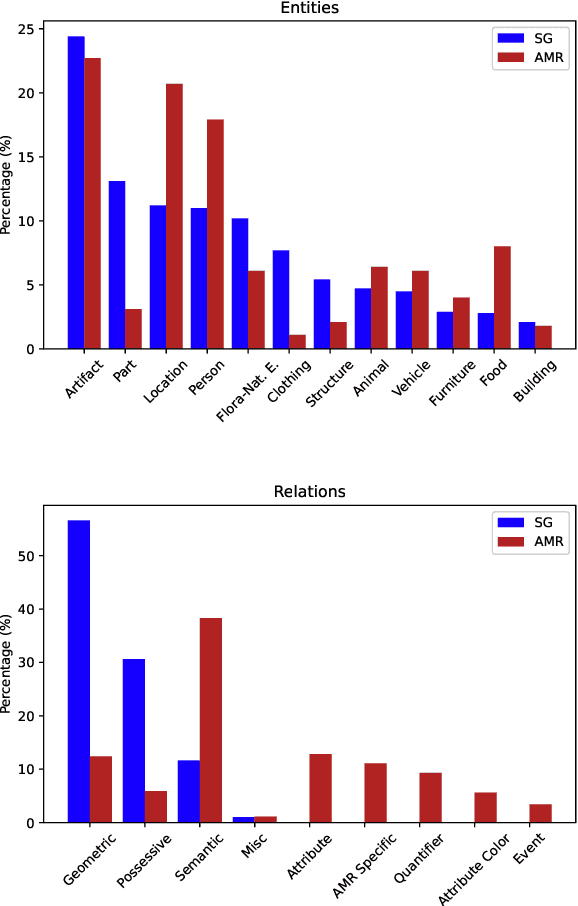

The success of scene graphs for visual scene understanding has brought attention to the benefits of abstracting a visual input (e.g., image) into a structured representation, where entities (people and objects) are nodes connected by edges specifying their relations. Building these representations, however, requires expensive manual annotation in the form of images paired with their scene graphs or frames. These formalisms remain limited in the nature of entities and relations they can capture. In this paper, we propose to leverage a widely-used meaning representation in the field of natural language processing, the Abstract Meaning Representation (AMR), to address these shortcomings. Compared to scene graphs, which largely emphasize spatial relationships, our visual AMR graphs are more linguistically informed, with a focus on higher-level semantic concepts extrapolated from visual input. Moreover, they allow us to generate meta-AMR graphs to unify information contained in multiple image descriptions under one representation. Through extensive experimentation and analysis, we demonstrate that we can re-purpose an existing text-to-AMR parser to parse images into AMRs. Our findings point to important future research directions for improved scene understanding.
Boosting Point Clouds Rendering via Radiance Mapping
Oct 27, 2022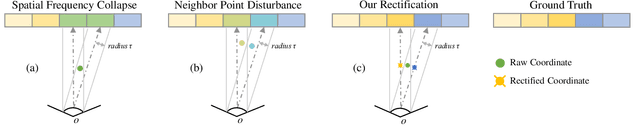



Recent years we have witnessed rapid development in NeRF-based image rendering due to its high quality. However, point clouds rendering is somehow less explored. Compared to NeRF-based rendering which suffers from dense spatial sampling, point clouds rendering is naturally less computation intensive, which enables its deployment in mobile computing device. In this work, we focus on boosting the image quality of point clouds rendering with a compact model design. We first analyze the adaption of the volume rendering formulation on point clouds. Based on the analysis, we simplify the NeRF representation to a spatial mapping function which only requires single evaluation per pixel. Further, motivated by ray marching, we rectify the the noisy raw point clouds to the estimated intersection between rays and surfaces as queried coordinates, which could avoid spatial frequency collapse and neighbor point disturbance. Composed of rasterization, spatial mapping and the refinement stages, our method achieves the state-of-the-art performance on point clouds rendering, outperforming prior works by notable margins, with a smaller model size. We obtain a PSNR of 31.74 on NeRF-Synthetic, 25.88 on ScanNet and 30.81 on DTU. Code and data would be released soon.
MSF3DDETR: Multi-Sensor Fusion 3D Detection Transformer for Autonomous Driving
Oct 27, 2022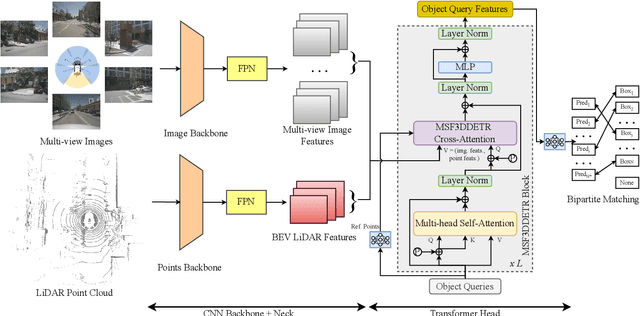
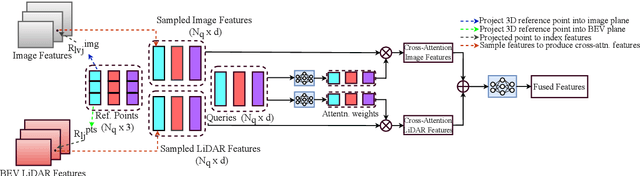

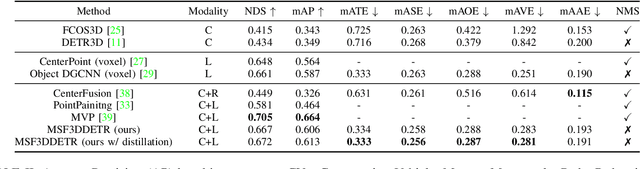
3D object detection is a significant task for autonomous driving. Recently with the progress of vision transformers, the 2D object detection problem is being treated with the set-to-set loss. Inspired by these approaches on 2D object detection and an approach for multi-view 3D object detection DETR3D, we propose MSF3DDETR: Multi-Sensor Fusion 3D Detection Transformer architecture to fuse image and LiDAR features to improve the detection accuracy. Our end-to-end single-stage, anchor-free and NMS-free network takes in multi-view images and LiDAR point clouds and predicts 3D bounding boxes. Firstly, we link the object queries learnt from data to the image and LiDAR features using a novel MSF3DDETR cross-attention block. Secondly, the object queries interacts with each other in multi-head self-attention block. Finally, MSF3DDETR block is repeated for $L$ number of times to refine the object queries. The MSF3DDETR network is trained end-to-end on the nuScenes dataset using Hungarian algorithm based bipartite matching and set-to-set loss inspired by DETR. We present both quantitative and qualitative results which are competitive to the state-of-the-art approaches.
Diagnostics for Deep Neural Networks with Automated Copy/Paste Attacks
Nov 22, 2022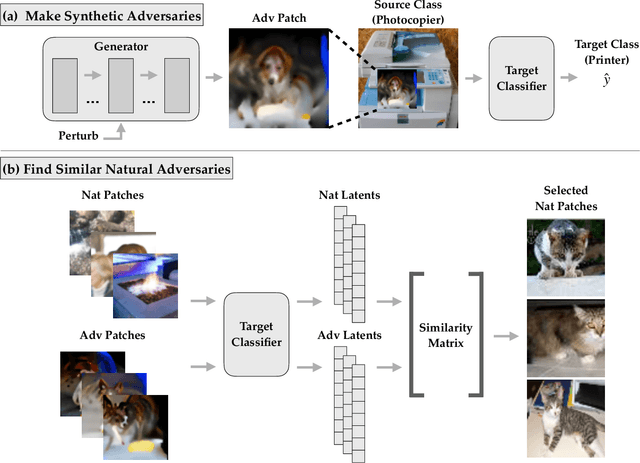

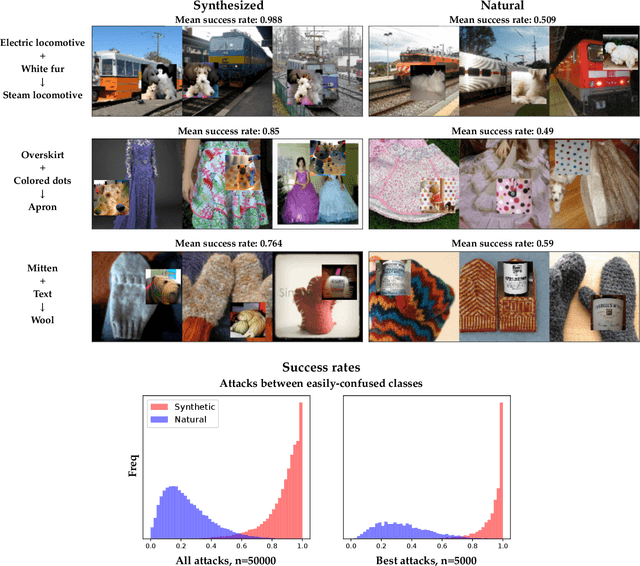
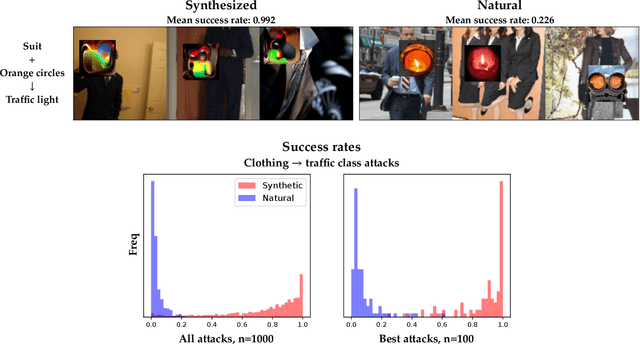
Deep neural networks (DNNs) are powerful, but they can make mistakes that pose significant risks. A model performing well on a test set does not imply safety in deployment, so it is important to have additional tools to understand its flaws. Adversarial examples can help reveal weaknesses, but they are often difficult for a human to interpret or draw generalizable, actionable conclusions from. Some previous works have addressed this by studying human-interpretable attacks. We build on these with three contributions. First, we introduce a method termed Search for Natural Adversarial Features Using Embeddings (SNAFUE) which offers a fully-automated method for finding "copy/paste" attacks in which one natural image can be pasted into another in order to induce an unrelated misclassification. Second, we use this to red team an ImageNet classifier and identify hundreds of easily-describable sets of vulnerabilities. Third, we compare this approach with other interpretability tools by attempting to rediscover trojans. Our results suggest that SNAFUE can be useful for interpreting DNNs and generating adversarial data for them. Code is available at https://github.com/thestephencasper/snafue
MagicPony: Learning Articulated 3D Animals in the Wild
Nov 22, 2022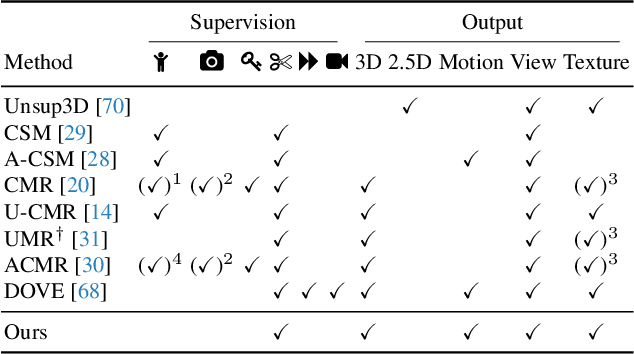
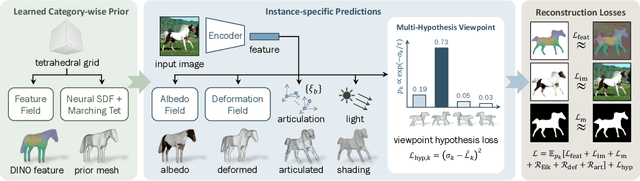
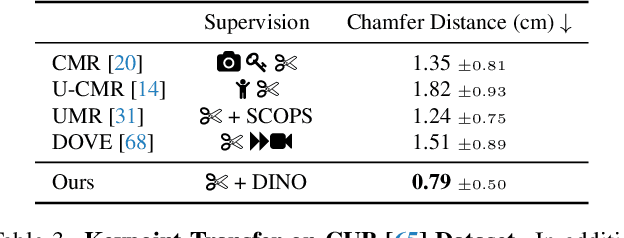
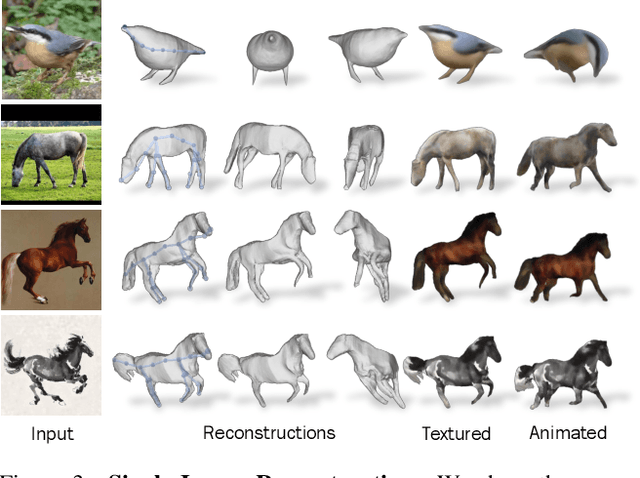
We consider the problem of learning a function that can estimate the 3D shape, articulation, viewpoint, texture, and lighting of an articulated animal like a horse, given a single test image. We present a new method, dubbed MagicPony, that learns this function purely from in-the-wild single-view images of the object category, with minimal assumptions about the topology of deformation. At its core is an implicit-explicit representation of articulated shape and appearance, combining the strengths of neural fields and meshes. In order to help the model understand an object's shape and pose, we distil the knowledge captured by an off-the-shelf self-supervised vision transformer and fuse it into the 3D model. To overcome common local optima in viewpoint estimation, we further introduce a new viewpoint sampling scheme that comes at no added training cost. Compared to prior works, we show significant quantitative and qualitative improvements on this challenging task. The model also demonstrates excellent generalisation in reconstructing abstract drawings and artefacts, despite the fact that it is only trained on real images.
SuperTran: Reference Based Video Transformer for Enhancing Low Bitrate Streams in Real Time
Nov 22, 2022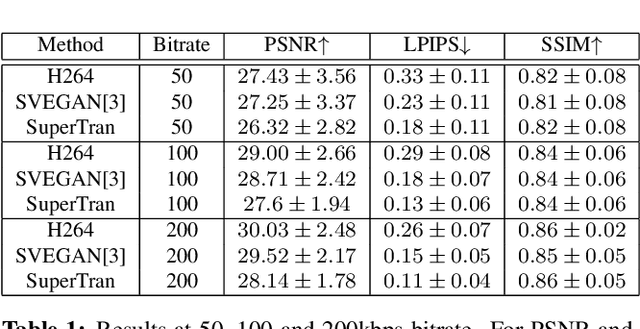
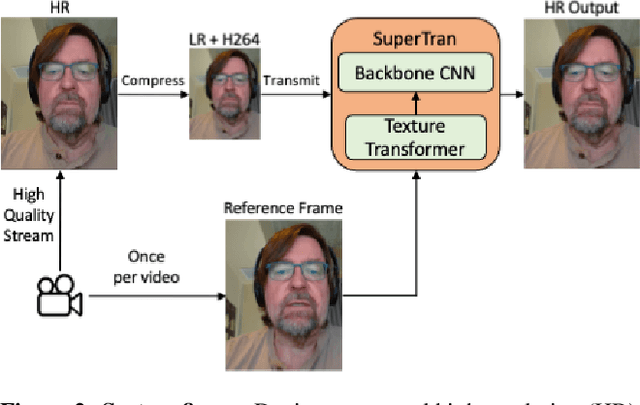
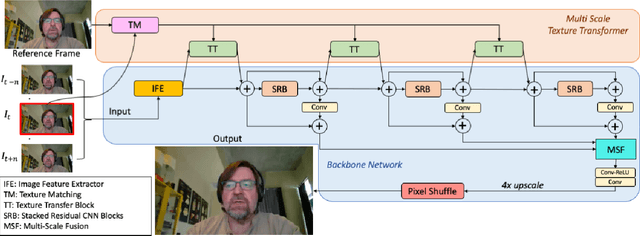
This work focuses on low bitrate video streaming scenarios (e.g. 50 - 200Kbps) where the video quality is severely compromised. We present a family of novel deep generative models for enhancing perceptual video quality of such streams by performing super-resolution while also removing compression artifacts. Our model, which we call SuperTran, consumes as input a single high-quality, high-resolution reference images in addition to the low-quality, low-resolution video stream. The model thus learns how to borrow or copy visual elements like textures from the reference image and fill in the remaining details from the low resolution stream in order to produce perceptually enhanced output video. The reference frame can be sent once at the start of the video session or be retrieved from a gallery. Importantly, the resulting output has substantially better detail than what has been otherwise possible with methods that only use a low resolution input such as the SuperVEGAN method. SuperTran works in real-time (up to 30 frames/sec) on the cloud alongside standard pipelines.
Sparse Probabilistic Circuits via Pruning and Growing
Nov 22, 2022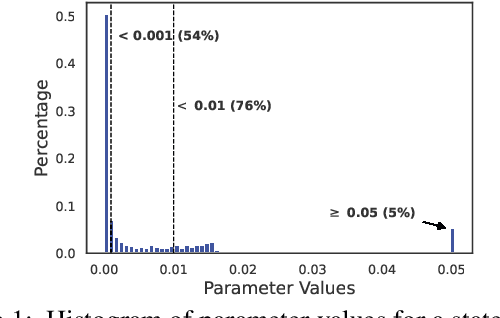
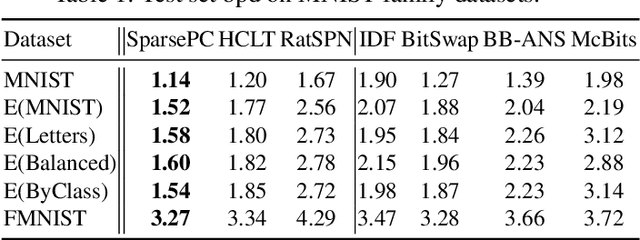

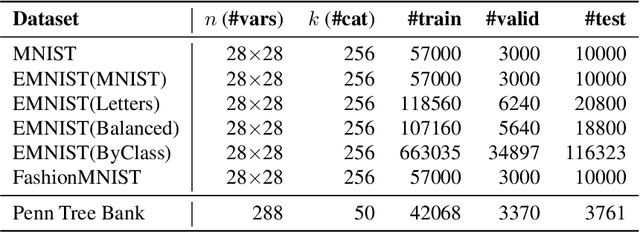
Probabilistic circuits (PCs) are a tractable representation of probability distributions allowing for exact and efficient computation of likelihoods and marginals. There has been significant recent progress on improving the scale and expressiveness of PCs. However, PC training performance plateaus as model size increases. We discover that most capacity in existing large PC structures is wasted: fully-connected parameter layers are only sparsely used. We propose two operations: pruning and growing, that exploit the sparsity of PC structures. Specifically, the pruning operation removes unimportant sub-networks of the PC for model compression and comes with theoretical guarantees. The growing operation increases model capacity by increasing the size of the latent space. By alternatingly applying pruning and growing, we increase the capacity that is meaningfully used, allowing us to significantly scale up PC learning. Empirically, our learner achieves state-of-the-art likelihoods on MNIST-family image datasets and on Penn Tree Bank language data compared to other PC learners and less tractable deep generative models such as flow-based models and variational autoencoders (VAEs).
NIO: Lightweight neural operator-based architecture for video frame interpolation
Nov 19, 2022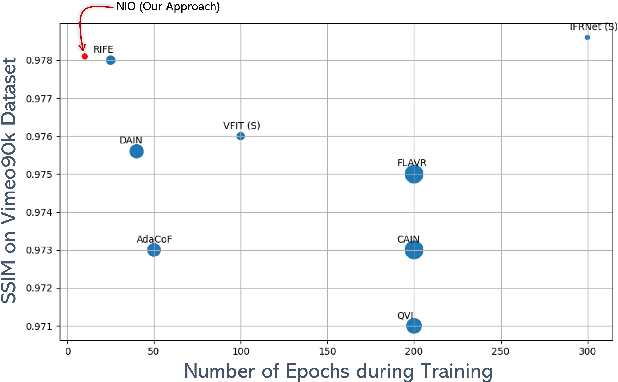
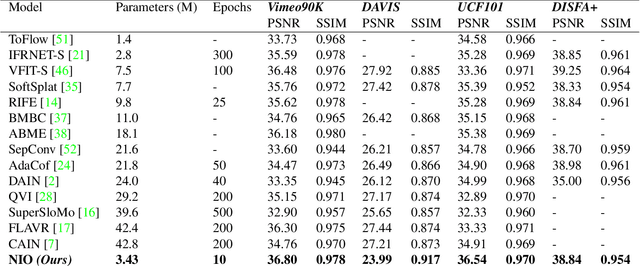
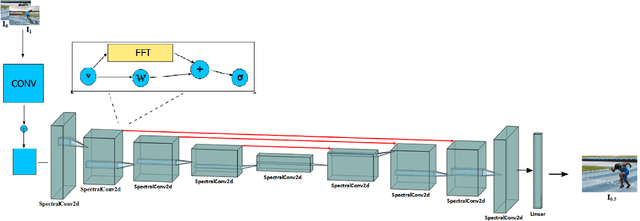

We present, NIO - Neural Interpolation Operator, a lightweight efficient neural operator-based architecture to perform video frame interpolation. Current deep learning based methods rely on local convolutions for feature learning and require a large amount of training on comprehensive datasets. Furthermore, transformer-based architectures are large and need dedicated GPUs for training. On the other hand, NIO, our neural operator-based approach learns the features in the frames by translating the image matrix into the Fourier space by using Fast Fourier Transform (FFT). The model performs global convolution, making it discretization invariant. We show that NIO can produce visually-smooth and accurate results and converges in fewer epochs than state-of-the-art approaches. To evaluate the visual quality of our interpolated frames, we calculate the structural similarity index (SSIM) and Peak Signal to Noise Ratio (PSNR) between the generated frame and the ground truth frame. We provide the quantitative performance of our model on Vimeo-90K dataset, DAVIS, UCF101 and DISFA+ dataset.
FSOINet: Feature-Space Optimization-Inspired Network for Image Compressive Sensing
Apr 12, 2022
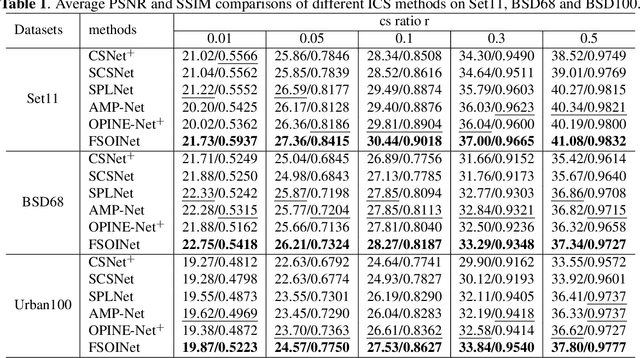
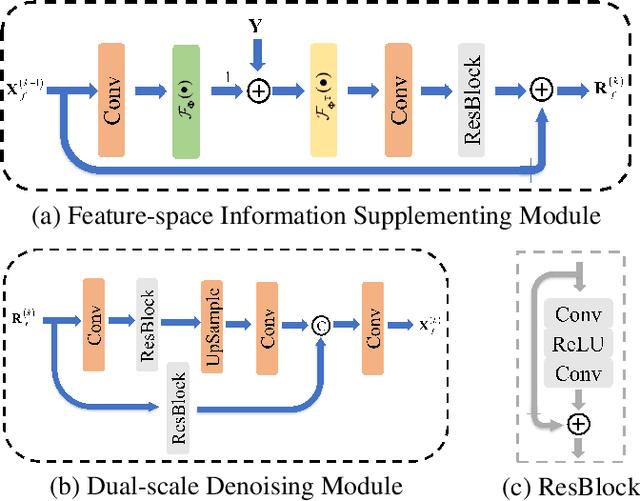

In recent years, deep learning-based image compressive sensing (ICS) methods have achieved brilliant success. Many optimization-inspired networks have been proposed to bring the insights of optimization algorithms into the network structure design and have achieved excellent reconstruction quality with low computational complexity. But they keep the information flow in pixel space as traditional algorithms by updating and transferring the image in pixel space, which does not fully use the information in the image features. In this paper, we propose the idea of achieving information flow phase by phase in feature space and design a Feature-Space Optimization-Inspired Network (dubbed FSOINet) to implement it by mapping both steps of proximal gradient descent algorithm from pixel space to feature space. Moreover, the sampling matrix is learned end-to-end with other network parameters. Experiments show that the proposed FSOINet outperforms the existing state-of-the-art methods by a large margin both quantitatively and qualitatively. The source code is available on https://github.com/cwjjun/FSOINet.
Provably Learning Diverse Features in Multi-View Data with Midpoint Mixup
Oct 24, 2022
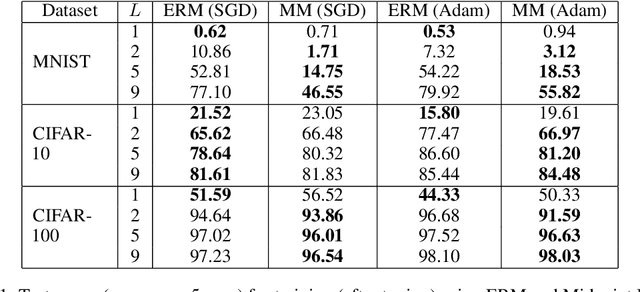
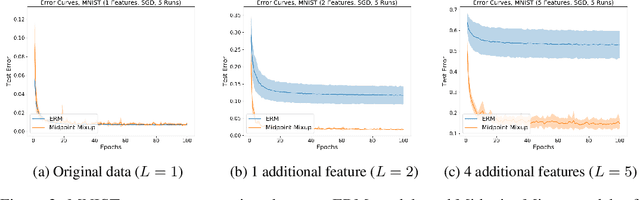
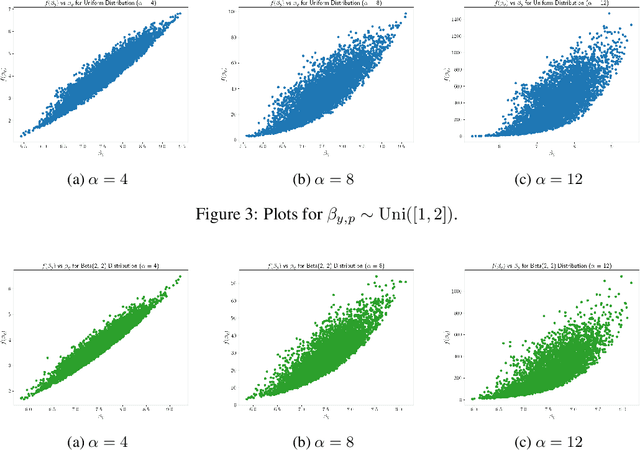
Mixup is a data augmentation technique that relies on training using random convex combinations of data points and their labels. In recent years, Mixup has become a standard primitive used in the training of state-of-the-art image classification models due to its demonstrated benefits over empirical risk minimization with regards to generalization and robustness. In this work, we try to explain some of this success from a feature learning perspective. We focus our attention on classification problems in which each class may have multiple associated features (or views) that can be used to predict the class correctly. Our main theoretical results demonstrate that, for a non-trivial class of data distributions with two features per class, training a 2-layer convolutional network using empirical risk minimization can lead to learning only one feature for almost all classes while training with a specific instantiation of Mixup succeeds in learning both features for every class. We also show empirically that these theoretical insights extend to the practical settings of image benchmarks modified to have additional synthetic features.