 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Patch DCT vs LeNet
Nov 04, 2022

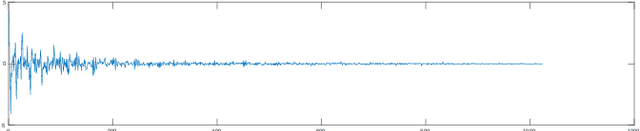

This paper compares the performance of a NN taking the output of a DCT (Discrete Cosine Transform) of an image patch with leNet for classifying MNIST hand written digits. The basis functions underlying the DCT bear a passing resemblance to some of the learned basis function of the Visual Transformer but are an order of magnitude faster to apply.
Portmanteauing Features for Scene Text Recognition
Nov 09, 2022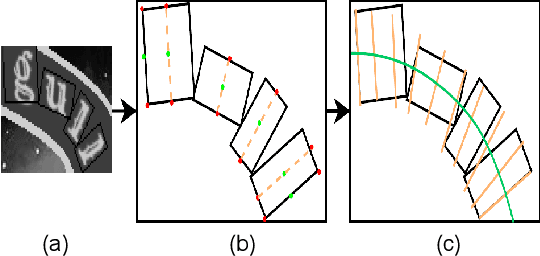
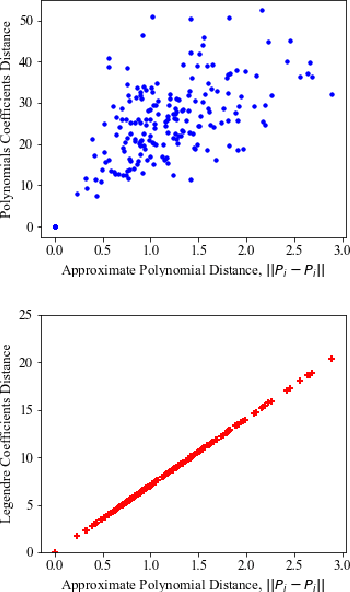


Scene text images have different shapes and are subjected to various distortions, e.g. perspective distortions. To handle these challenges, the state-of-the-art methods rely on a rectification network, which is connected to the text recognition network. They form a linear pipeline which uses text rectification on all input images, even for images that can be recognized without it. Undoubtedly, the rectification network improves the overall text recognition performance. However, in some cases, the rectification network generates unnecessary distortions on images, resulting in incorrect predictions in images that would have otherwise been correct without it. In order to alleviate the unnecessary distortions, the portmanteauing of features is proposed. The portmanteau feature, inspired by the portmanteau word, is a feature containing information from both the original text image and the rectified image. To generate the portmanteau feature, a non-linear input pipeline with a block matrix initialization is presented. In this work, the transformer is chosen as the recognition network due to its utilization of attention and inherent parallelism, which can effectively handle the portmanteau feature. The proposed method is examined on 6 benchmarks and compared with 13 state-of-the-art methods. The experimental results show that the proposed method outperforms the state-of-the-art methods on various of the benchmarks.
Collaborative Quantization Embeddings for Intra-Subject Prostate MR Image Registration
Jul 14, 2022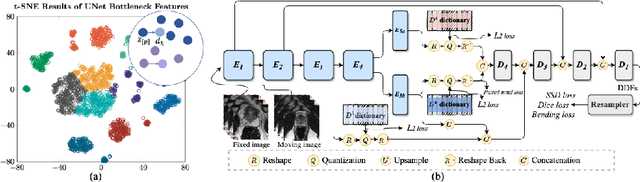
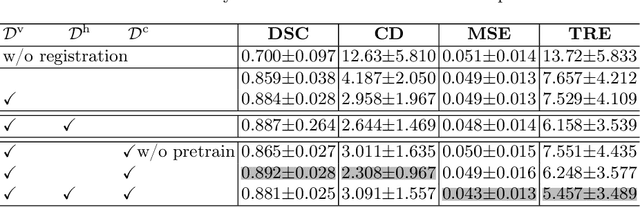
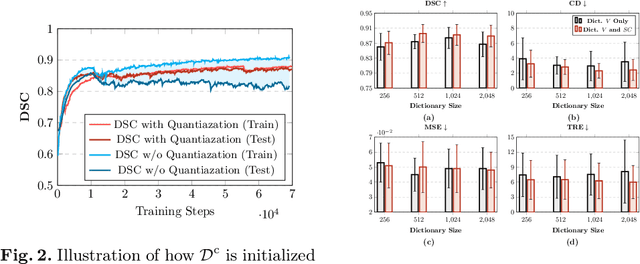
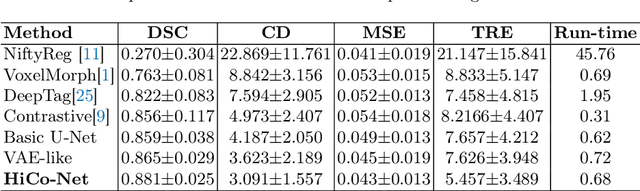
Image registration is useful for quantifying morphological changes in longitudinal MR images from prostate cancer patients. This paper describes a development in improving the learning-based registration algorithms, for this challenging clinical application often with highly variable yet limited training data. First, we report that the latent space can be clustered into a much lower dimensional space than that commonly found as bottleneck features at the deep layer of a trained registration network. Based on this observation, we propose a hierarchical quantization method, discretizing the learned feature vectors using a jointly-trained dictionary with a constrained size, in order to improve the generalisation of the registration networks. Furthermore, a novel collaborative dictionary is independently optimised to incorporate additional prior information, such as the segmentation of the gland or other regions of interest, in the latent quantized space. Based on 216 real clinical images from 86 prostate cancer patients, we show the efficacy of both the designed components. Improved registration accuracy was obtained with statistical significance, in terms of both Dice on gland and target registration error on corresponding landmarks, the latter of which achieved 5.46 mm, an improvement of 28.7\% from the baseline without quantization. Experimental results also show that the difference in performance was indeed minimised between training and testing data.
Towards Unifying Reference Expression Generation and Comprehension
Oct 24, 2022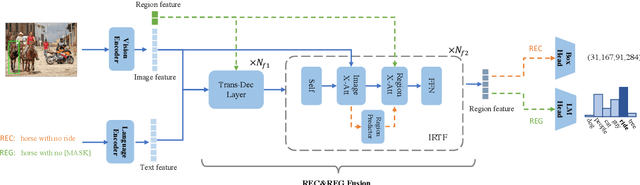

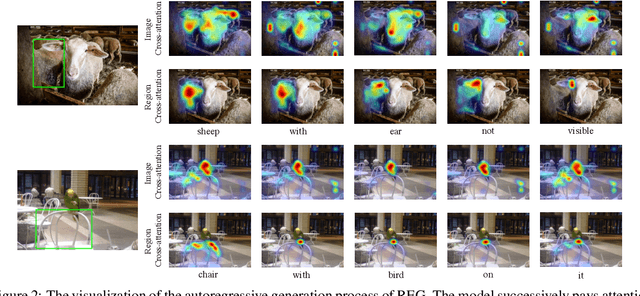
Reference Expression Generation (REG) and Comprehension (REC) are two highly correlated tasks. Modeling REG and REC simultaneously for utilizing the relation between them is a promising way to improve both. However, the problem of distinct inputs, as well as building connections between them in a single model, brings challenges to the design and training of the joint model. To address the problems, we propose a unified model for REG and REC, named UniRef. It unifies these two tasks with the carefully-designed Image-Region-Text Fusion layer (IRTF), which fuses the image, region and text via the image cross-attention and region cross-attention. Additionally, IRTF could generate pseudo input regions for the REC task to enable a uniform way for sharing the identical representation space across the REC and REG. We further propose Vision-conditioned Masked Language Modeling (VMLM) and Text-Conditioned Region Prediction (TRP) to pre-train UniRef model on multi-granular corpora. The VMLM and TRP are directly related to REG and REC, respectively, but could help each other. We conduct extensive experiments on three benchmark datasets, RefCOCO, RefCOCO+ and RefCOCOg. Experimental results show that our model outperforms previous state-of-the-art methods on both REG and REC.
Iris super-resolution using CNNs: is photo-realism important to iris recognition?
Oct 24, 2022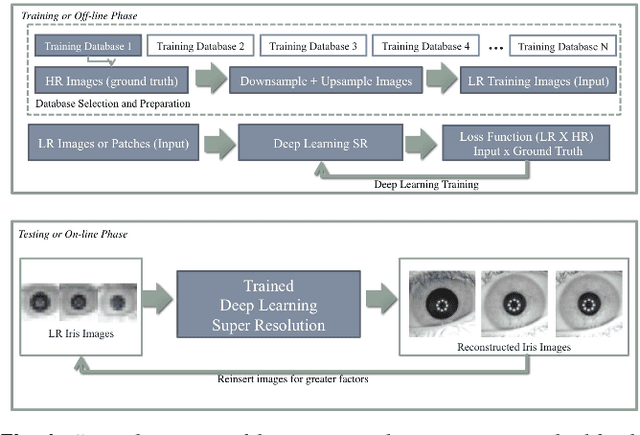

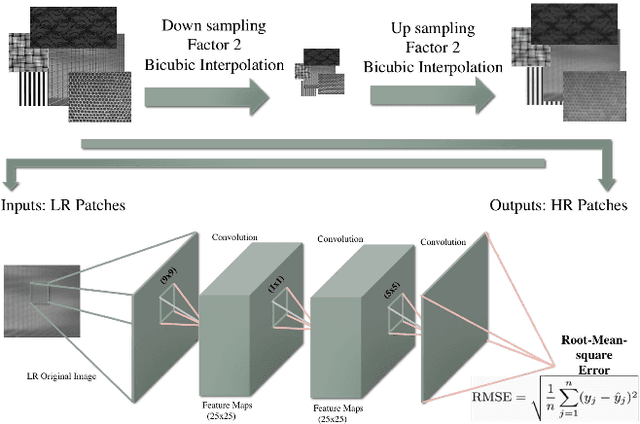
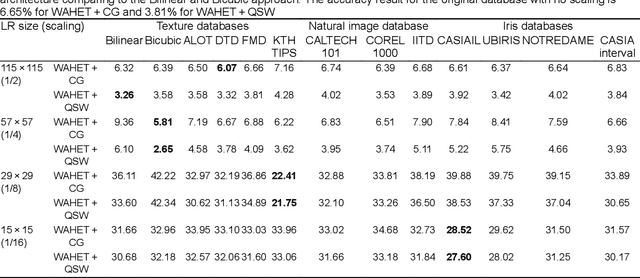
The use of low-resolution images adopting more relaxed acquisition conditions such as mobile phones and surveillance videos is becoming increasingly common in iris recognition nowadays. Concurrently, a great variety of single image super-resolution techniques are emerging, especially with the use of convolutional neural networks (CNNs). The main objective of these methods is to try to recover finer texture details generating more photo-realistic images based on the optimisation of an objective function depending basically on the CNN architecture and training approach. In this work, the authors explore single image super-resolution using CNNs for iris recognition. For this, they test different CNN architectures and use different training databases, validating their approach on a database of 1.872 near infrared iris images and on a mobile phone image database. They also use quality assessment, visual results and recognition experiments to verify if the photo-realism provided by the CNNs which have already proven to be effective for natural images can reflect in a better recognition rate for iris recognition. The results show that using deeper architectures trained with texture databases that provide a balance between edge preservation and the smoothness of the method can lead to good results in the iris recognition process.
Interpretable ML for Imbalanced Data
Dec 15, 2022
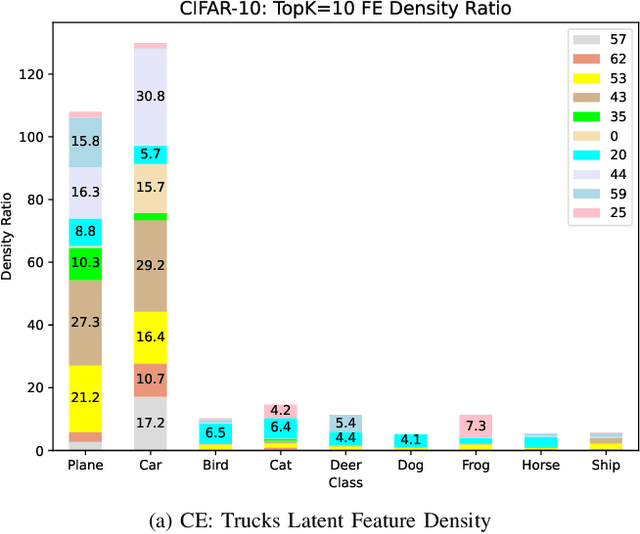


Deep learning models are being increasingly applied to imbalanced data in high stakes fields such as medicine, autonomous driving, and intelligence analysis. Imbalanced data compounds the black-box nature of deep networks because the relationships between classes may be highly skewed and unclear. This can reduce trust by model users and hamper the progress of developers of imbalanced learning algorithms. Existing methods that investigate imbalanced data complexity are geared toward binary classification, shallow learning models and low dimensional data. In addition, current eXplainable Artificial Intelligence (XAI) techniques mainly focus on converting opaque deep learning models into simpler models (e.g., decision trees) or mapping predictions for specific instances to inputs, instead of examining global data properties and complexities. Therefore, there is a need for a framework that is tailored to modern deep networks, that incorporates large, high dimensional, multi-class datasets, and uncovers data complexities commonly found in imbalanced data (e.g., class overlap, sub-concepts, and outlier instances). We propose a set of techniques that can be used by both deep learning model users to identify, visualize and understand class prototypes, sub-concepts and outlier instances; and by imbalanced learning algorithm developers to detect features and class exemplars that are key to model performance. Our framework also identifies instances that reside on the border of class decision boundaries, which can carry highly discriminative information. Unlike many existing XAI techniques which map model decisions to gray-scale pixel locations, we use saliency through back-propagation to identify and aggregate image color bands across entire classes. Our framework is publicly available at \url{https://github.com/dd1github/XAI_for_Imbalanced_Learning}
Saliency Can Be All You Need In Contrastive Self-Supervised Learning
Oct 30, 2022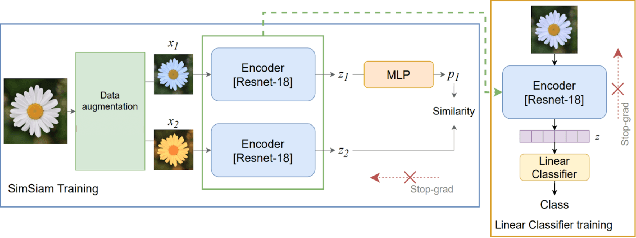


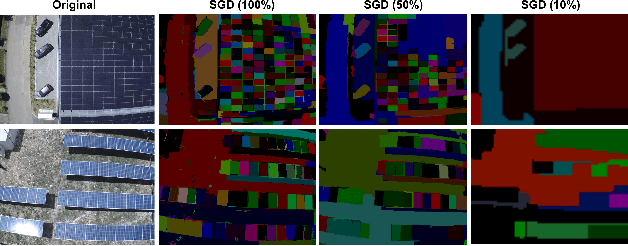
We propose an augmentation policy for Contrastive Self-Supervised Learning (SSL) in the form of an already established Salient Image Segmentation technique entitled Global Contrast based Salient Region Detection. This detection technique, which had been devised for unrelated Computer Vision tasks, was empirically observed to play the role of an augmentation facilitator within the SSL protocol. This observation is rooted in our practical attempts to learn, by SSL-fashion, aerial imagery of solar panels, which exhibit challenging boundary patterns. Upon the successful integration of this technique on our problem domain, we formulated a generalized procedure and conducted a comprehensive, systematic performance assessment with various Contrastive SSL algorithms subject to standard augmentation techniques. This evaluation, which was conducted across multiple datasets, indicated that the proposed technique indeed contributes to SSL. We hypothesize whether salient image segmentation may suffice as the only augmentation policy in Contrastive SSL when treating downstream segmentation tasks.
Vector-Valued Least-Squares Regression under Output Regularity Assumptions
Nov 16, 2022
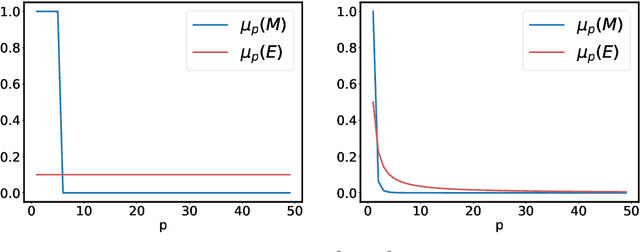
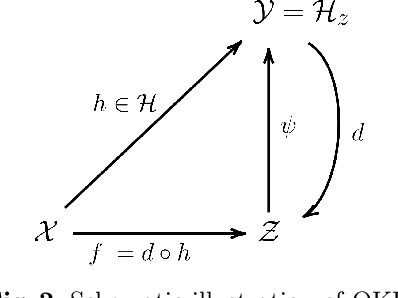

We propose and analyse a reduced-rank method for solving least-squares regression problems with infinite dimensional output. We derive learning bounds for our method, and study under which setting statistical performance is improved in comparison to full-rank method. Our analysis extends the interest of reduced-rank regression beyond the standard low-rank setting to more general output regularity assumptions. We illustrate our theoretical insights on synthetic least-squares problems. Then, we propose a surrogate structured prediction method derived from this reduced-rank method. We assess its benefits on three different problems: image reconstruction, multi-label classification, and metabolite identification.
Neural Data-Dependent Transform for Learned Image Compression
Mar 30, 2022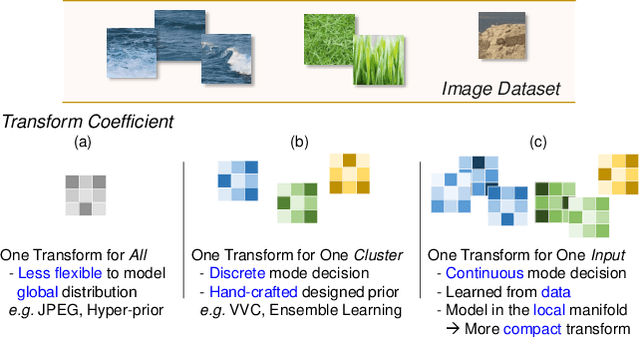
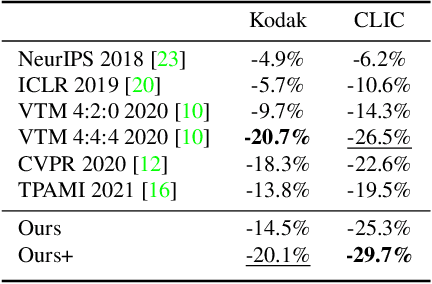
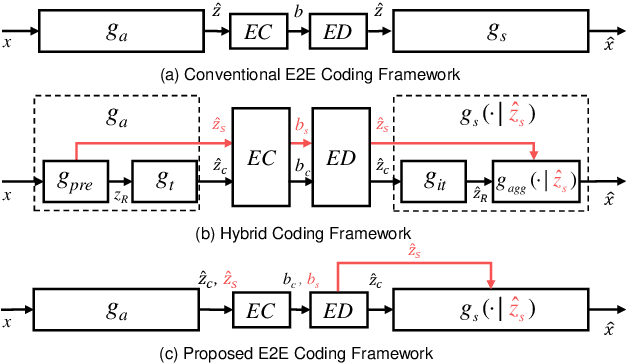
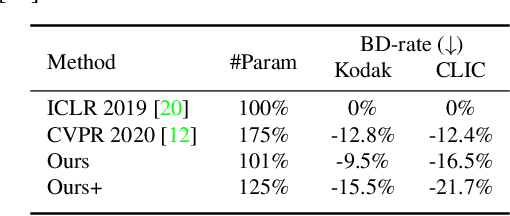
Learned image compression has achieved great success due to its excellent modeling capacity, but seldom further considers the Rate-Distortion Optimization (RDO) of each input image. To explore this potential in the learned codec, we make the first attempt to build a neural data-dependent transform and introduce a continuous online mode decision mechanism to jointly optimize the coding efficiency for each individual image. Specifically, apart from the image content stream, we employ an additional model stream to generate the transform parameters at the decoder side. The presence of a model stream enables our model to learn more abstract neural-syntax, which helps cluster the latent representations of images more compactly. Beyond the transform stage, we also adopt neural-syntax based post-processing for the scenarios that require higher quality reconstructions regardless of extra decoding overhead. Moreover, the involvement of the model stream further makes it possible to optimize both the representation and the decoder in an online way, i.e. RDO at the testing time. It is equivalent to a continuous online mode decision, like coding modes in the traditional codecs, to improve the coding efficiency based on the individual input image. The experimental results show the effectiveness of the proposed neural-syntax design and the continuous online mode decision mechanism, demonstrating the superiority of our method in coding efficiency compared to the latest conventional standard Versatile Video Coding (VVC) and other state-of-the-art learning-based methods.
GRelPose: Generalizable End-to-End Relative Camera Pose Regression
Nov 27, 2022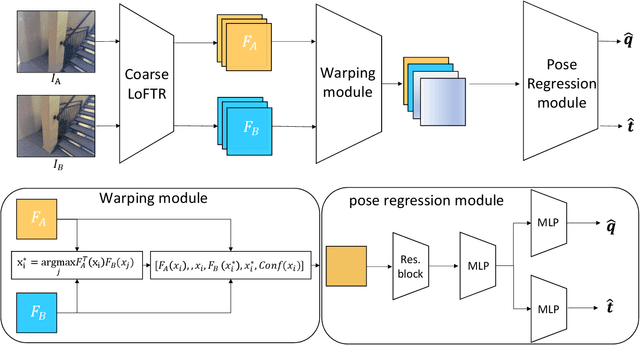



This paper proposes a generalizable, end-to-end deep learning-based method for relative pose regression between two images. Given two images of the same scene captured from different viewpoints, our algorithm predicts the relative rotation and translation between the two respective cameras. Despite recent progress in the field, current deep-based methods exhibit only limited generalization to scenes not seen in training. Our approach introduces a network architecture that extracts a grid of coarse features for each input image using the pre-trained LoFTR network. It subsequently relates corresponding features in the two images, and finally uses a convolutional network to recover the relative rotation and translation between the respective cameras. Our experiments indicate that the proposed architecture can generalize to novel scenes, obtaining higher accuracy than existing deep-learning-based methods in various settings and datasets, in particular with limited training data.